 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo as Natural Augmentation: Towards Unified AI-Generated Image and Video Detection
May 21, 2026AI-generated content (AIGC) is rapidly improving, creating an urgent need for detectors that generalize across data sources, deployment pipelines, and visual modalities. A strongly generalizable detector should remain robust under distributional variations. However, we identify a consistent failure mode: SOTA AI-generated image detectors often collapse when applied to frames extracted from videos. Through systematic analysis, we show that this cross-modal gap arises from both entangled synthesis-agnostic video processing shifts, including color conversion, codec compression, resizing, and blur, and model-specific fingerprints introduced by modern video generators. Motivated by these findings, we propose VINA (Video as Natural Augmentation), a unified AIGC detection framework that jointly trains on image and video data. VINA uses video frames as physically grounded natural augmentations and further introduces a cross-modal supervised contrastive objective to align image and video representations under a shared real/fake decision boundary. Extensive experiments on 14 image, video, and in-the-wild benchmarks show that VINA delivers bidirectional gains, improves robustness and transferability, and achieves state-of-the-art performance across nearly all evaluated settings without complex augmentation or dataset-specific tuning.
Preserving Forgery Artifacts: AI-Generated Video Detection at Native Scale
Apr 06, 2026The rapid advancement of video generation models has enabled the creation of highly realistic synthetic media, raising significant societal concerns regarding the spread of misinformation. However, current detection methods suffer from critical limitations. They rely on preprocessing operations like fixed-resolution resizing and cropping. These operations not only discard subtle, high-frequency forgery traces but also cause spatial distortion and significant information loss. Furthermore, existing methods are often trained and evaluated on outdated datasets that fail to capture the sophistication of modern generative models. To address these challenges, we introduce a comprehensive dataset and a novel detection framework. First, we curate a large-scale dataset of over 140K videos from 15 state-of-the-art open-source and commercial generators, along with Magic Videos benchmark designed specifically for evaluating ultra-realistic synthetic content. In addition, we propose a novel detection framework built on the Qwen2.5-VL Vision Transformer, which operates natively at variable spatial resolutions and temporal durations. This native-scale approach effectively preserves the high-frequency artifacts and spatiotemporal inconsistencies typically lost during conventional preprocessing. Extensive experiments demonstrate that our method achieves superior performance across multiple benchmarks, underscoring the critical importance of native-scale processing and establishing a robust new baseline for AI-generated video detection.
Skeleton-based Group Activity Recognition via Spatial-Temporal Panoramic Graph
Jul 28, 2024



Group Activity Recognition aims to understand collective activities from videos. Existing solutions primarily rely on the RGB modality, which encounters challenges such as background variations, occlusions, motion blurs, and significant computational overhead. Meanwhile, current keypoint-based methods offer a lightweight and informative representation of human motions but necessitate accurate individual annotations and specialized interaction reasoning modules. To address these limitations, we design a panoramic graph that incorporates multi-person skeletons and objects to encapsulate group activity, offering an effective alternative to RGB video. This panoramic graph enables Graph Convolutional Network (GCN) to unify intra-person, inter-person, and person-object interactive modeling through spatial-temporal graph convolutions. In practice, we develop a novel pipeline that extracts skeleton coordinates using pose estimation and tracking algorithms and employ Multi-person Panoramic GCN (MP-GCN) to predict group activities. Extensive experiments on Volleyball and NBA datasets demonstrate that the MP-GCN achieves state-of-the-art performance in both accuracy and efficiency. Notably, our method outperforms RGB-based approaches by using only estimated 2D keypoints as input. Code is available at https://github.com/mgiant/MP-GCN
Two-person Graph Convolutional Network for Skeleton-based Human Interaction Recognition
Aug 12, 2022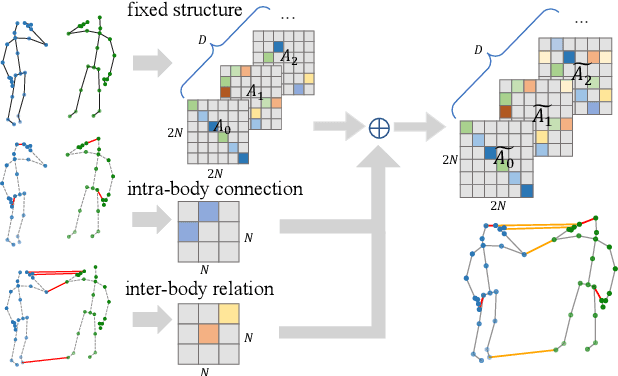
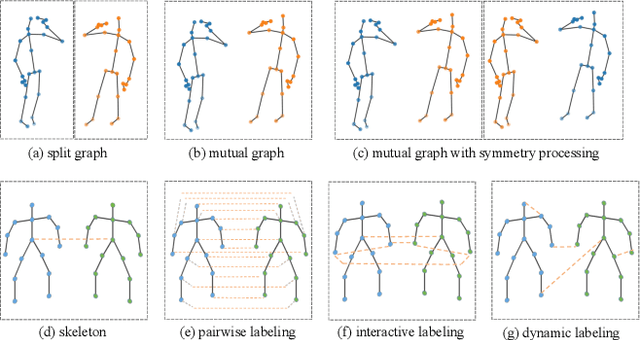
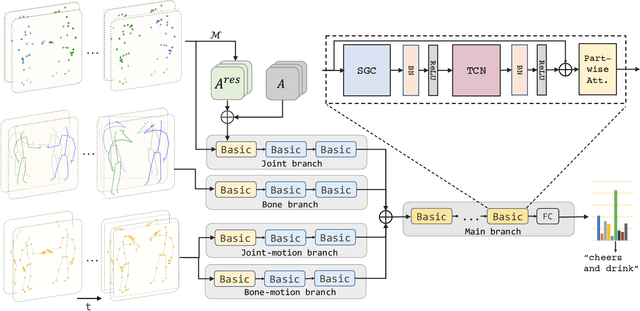
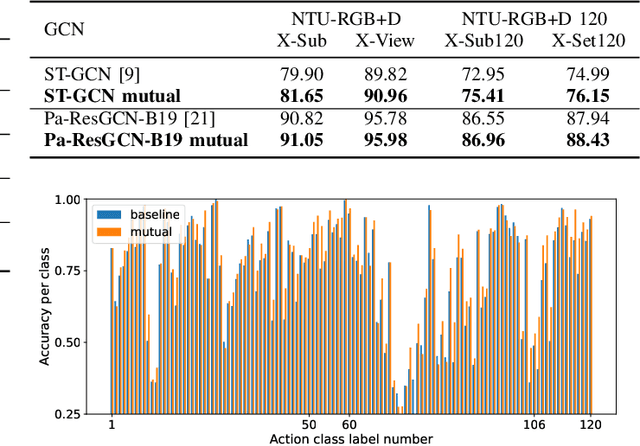
Graph Convolutional Network (GCN) outperforms previous methods in the skeleton-based human action recognition area, including human-human interaction recognition task. However, when dealing with interaction sequences, current GCN-based methods simply split the two-person skeleton into two discrete sequences and perform graph convolution separately in the manner of single-person action classification. Such operation ignores rich interactive information and hinders effective spatial relationship modeling for semantic pattern learning. To overcome the above shortcoming, we introduce a novel unified two-person graph representing spatial interaction correlations between joints. Also, a properly designed graph labeling strategy is proposed to let our GCN model learn discriminant spatial-temporal interactive features. Experiments show accuracy improvements in both interactions and individual actions when utilizing the proposed two-person graph topology. Finally, we propose a Two-person Graph Convolutional Network (2P-GCN). The proposed 2P-GCN achieves state-of-the-art results on four benchmarks of three interaction datasets, SBU, NTU-RGB+D, and NTU-RGB+D 120.