 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZR-2021VG: Zero-Resource Speech Challenge, Visually-Grounded Language Modelling track, 2021 edition
Jul 14, 2021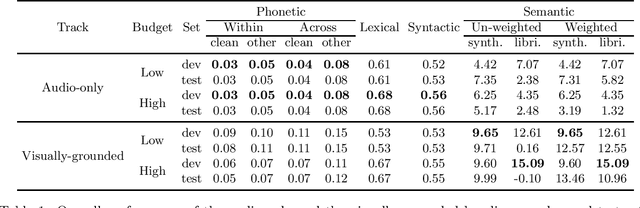
We present the visually-grounded language modelling track that was introduced in the Zero-Resource Speech challenge, 2021 edition, 2nd round. We motivate the new track and discuss participation rules in detail. We also present the two baseline systems that were developed for this track.
Reverse-engineer the Distributional Structure of Infant Egocentric Views for Training Generalizable Image Classifiers
Jun 12, 2021
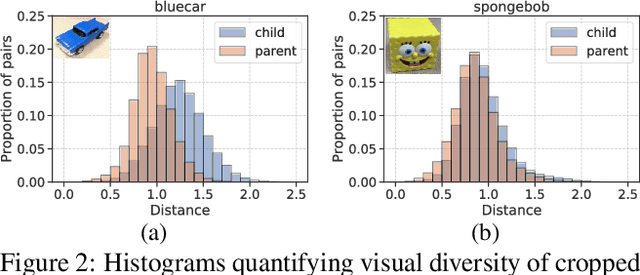
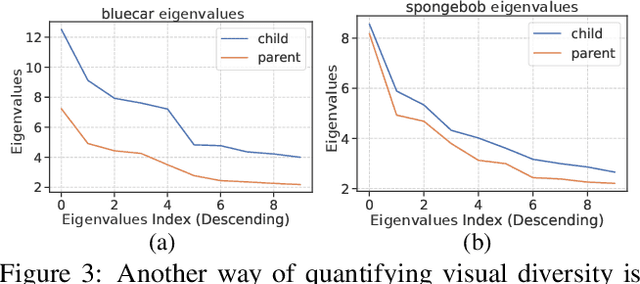
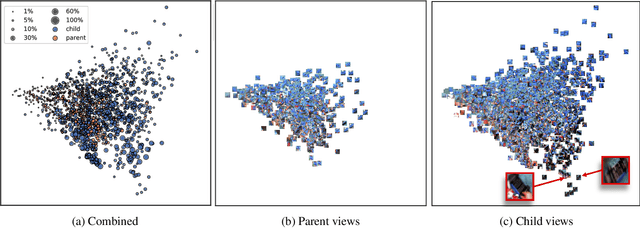
We analyze egocentric views of attended objects from infants. This paper shows 1) empirical evidence that children's egocentric views have more diverse distributions compared to adults' views, 2) we can computationally simulate the infants' distribution, and 3) the distribution is beneficial for training more generalized image classifiers not only for infant egocentric vision but for third-person computer vision.
Sparse online relative similarity learning
Apr 15, 2021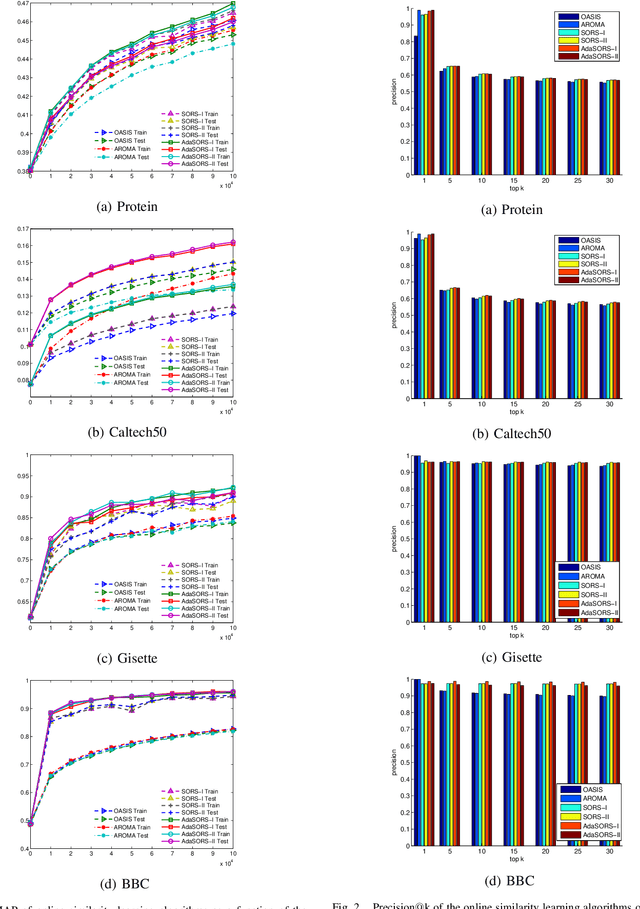
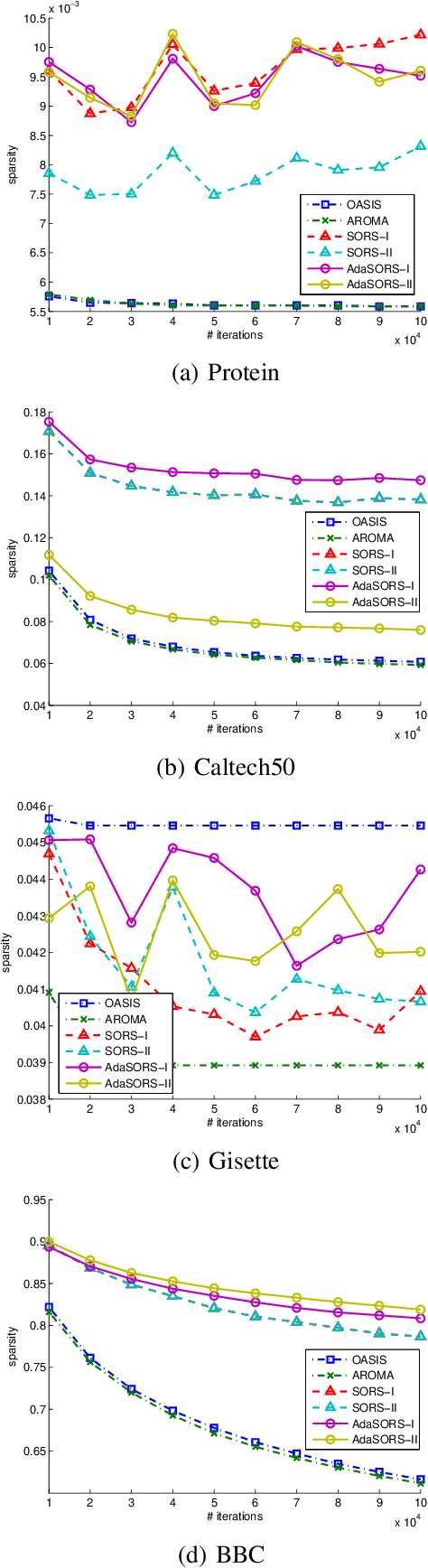
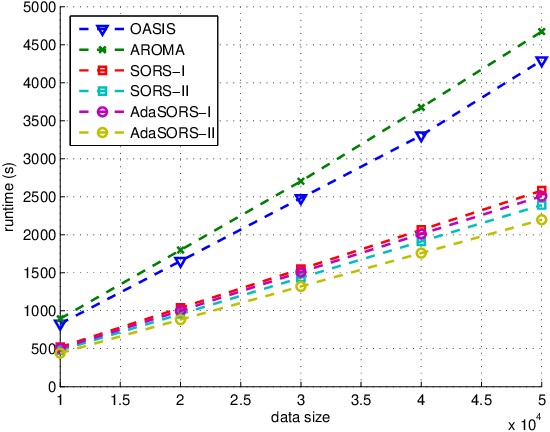
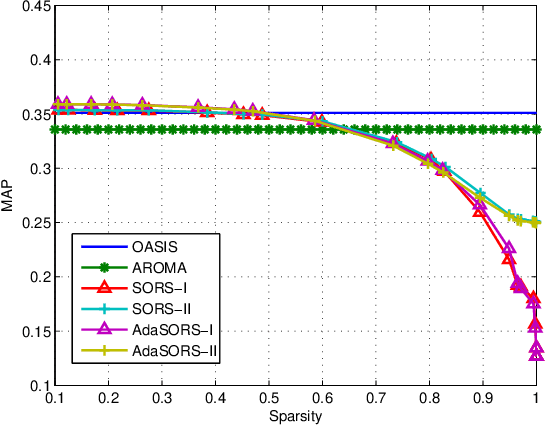
For many data mining and machine learning tasks, the quality of a similarity measure is the key for their performance. To automatically find a good similarity measure from datasets, metric learning and similarity learning are proposed and studied extensively. Metric learning will learn a Mahalanobis distance based on positive semi-definite (PSD) matrix, to measure the distances between objectives, while similarity learning aims to directly learn a similarity function without PSD constraint so that it is more attractive. Most of the existing similarity learning algorithms are online similarity learning method, since online learning is more scalable than offline learning. However, most existing online similarity learning algorithms learn a full matrix with d 2 parameters, where d is the dimension of the instances. This is clearly inefficient for high dimensional tasks due to its high memory and computational complexity. To solve this issue, we introduce several Sparse Online Relative Similarity (SORS) learning algorithms, which learn a sparse model during the learning process, so that the memory and computational cost can be significantly reduced. We theoretically analyze the proposed algorithms, and evaluate them on some real-world high dimensional datasets. Encouraging empirical results demonstrate the advantages of our approach in terms of efficiency and efficacy.
A Computational Model of Early Word Learning from the Infant's Point of View
Jun 04, 2020
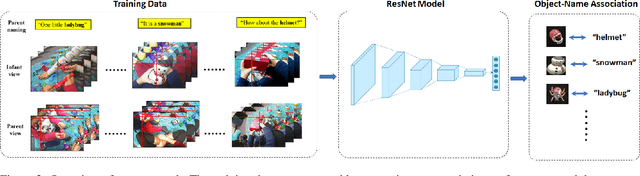


Human infants have the remarkable ability to learn the associations between object names and visual objects from inherently ambiguous experiences. Researchers in cognitive science and developmental psychology have built formal models that implement in-principle learning algorithms, and then used pre-selected and pre-cleaned datasets to test the abilities of the models to find statistical regularities in the input data. In contrast to previous modeling approaches, the present study used egocentric video and gaze data collected from infant learners during natural toy play with their parents. This allowed us to capture the learning environment from the perspective of the learner's own point of view. We then used a Convolutional Neural Network (CNN) model to process sensory data from the infant's point of view and learn name-object associations from scratch. As the first model that takes raw egocentric video to simulate infant word learning, the present study provides a proof of principle that the problem of early word learning can be solved, using actual visual data perceived by infant learners. Moreover, we conducted simulation experiments to systematically determine how visual, perceptual, and attentional properties of infants' sensory experiences may affect word learning.
A Self Validation Network for Object-Level Human Attention Estimation
Oct 31, 2019
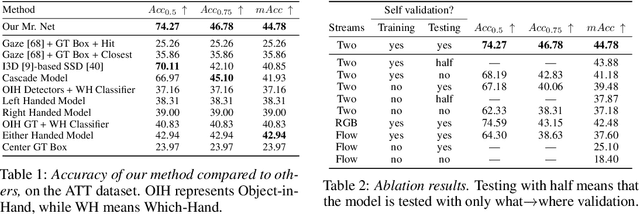
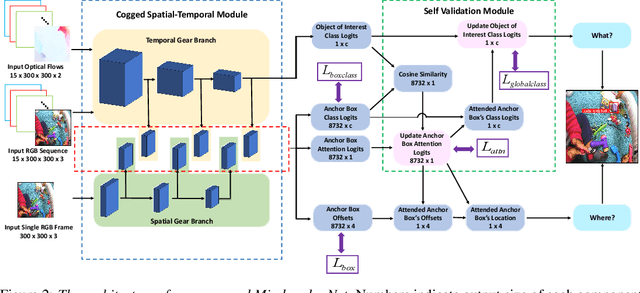

Due to the foveated nature of the human vision system, people can focus their visual attention on a small region of their visual field at a time, which usually contains only a single object. Estimating this object of attention in first-person (egocentric) videos is useful for many human-centered real-world applications such as augmented reality applications and driver assistance systems. A straightforward solution for this problem is to pick the object whose bounding box is hit by the gaze, where eye gaze point estimation is obtained from a traditional eye gaze estimator and object candidates are generated from an off-the-shelf object detector. However, such an approach can fail because it addresses the where and the what problems separately, despite that they are highly related, chicken-and-egg problems. In this paper, we propose a novel unified model that incorporates both spatial and temporal evidence in identifying as well as locating the attended object in firstperson videos. It introduces a novel Self Validation Module that enforces and leverages consistency of the where and the what concepts. We evaluate on two public datasets, demonstrating that Self Validation Module significantly benefits both training and testing and that our model outperforms the state-of-the-art.
Active Object Manipulation Facilitates Visual Object Learning: An Egocentric Vision Study
Jun 04, 2019Inspired by the remarkable ability of the infant visual learning system, a recent study collected first-person images from children to analyze the `training data' that they receive. We conduct a follow-up study that investigates two additional directions. First, given that infants can quickly learn to recognize a new object without much supervision (i.e. few-shot learning), we limit the number of training images. Second, we investigate how children control the supervision signals they receive during learning based on hand manipulation of objects. Our experimental results suggest that supervision with hand manipulation is better than without hands, and the trend is consistent even when a small number of images is available.
Decentralized Online Learning: Take Benefits from Others' Data without Sharing Your Own to Track Global Trend
Mar 28, 2019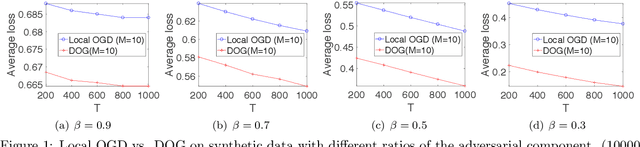
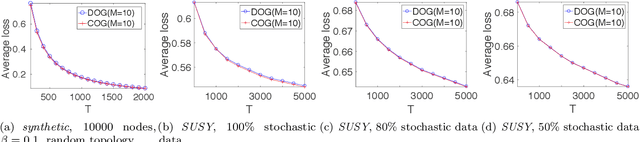
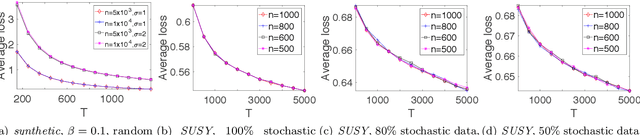
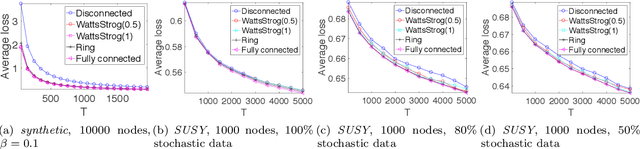
Decentralized Online Learning (online learning in decentralized networks) attracts more and more attention, since it is believed that Decentralized Online Learning can help the data providers cooperatively better solve their online problems without sharing their private data to a third party or other providers. Typically, the cooperation is achieved by letting the data providers exchange their models between neighbors, e.g., recommendation model. However, the best regret bound for a decentralized online learning algorithm is $\Ocal{n\sqrt{T}}$, where $n$ is the number of nodes (or users) and $T$ is the number of iterations. This is clearly insignificant since this bound can be achieved \emph{without} any communication in the networks. This reminds us to ask a fundamental question: \emph{Can people really get benefit from the decentralized online learning by exchanging information?} In this paper, we studied when and why the communication can help the decentralized online learning to reduce the regret. Specifically, each loss function is characterized by two components: the adversarial component and the stochastic component. Under this characterization, we show that decentralized online gradient (DOG) enjoys a regret bound $\Ocal{n\sqrt{T}G + \sqrt{nT}\sigma}$, where $G$ measures the magnitude of the adversarial component in the private data (or equivalently the local loss function) and $\sigma$ measures the randomness within the private data. This regret suggests that people can get benefits from the randomness in the private data by exchanging private information. Another important contribution of this paper is to consider the dynamic regret -- a more practical regret to track users' interest dynamics. Empirical studies are also conducted to validate our analysis.
Adversarially Trained Model Compression: When Robustness Meets Efficiency
Feb 10, 2019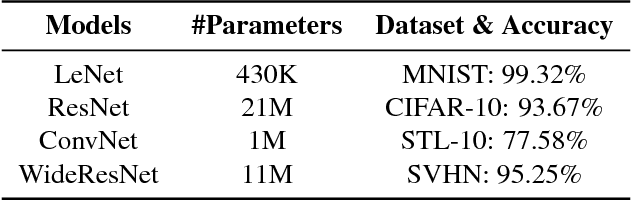
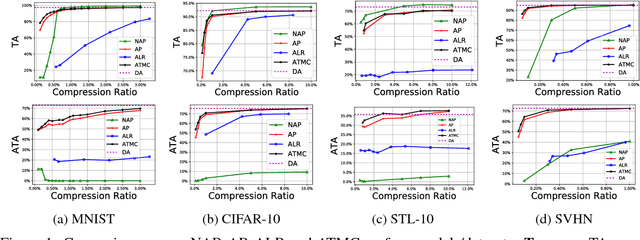
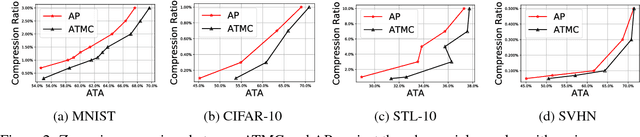
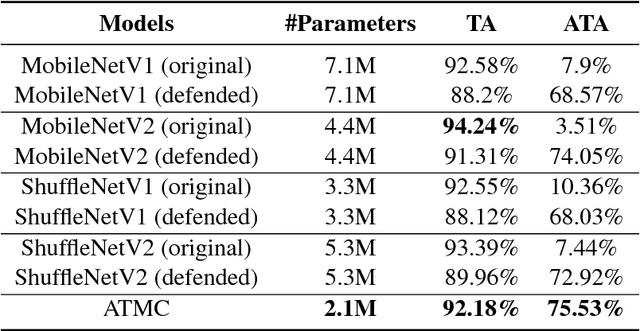
The robustness of deep models to adversarial attacks has gained significant attention in recent years, so has the model compactness and efficiency: yet the two have been mostly studied separately, with few relationships drawn between each other. This paper is concerned with: how can we combine the best of both worlds, obtaining a robust and compact network? The answer is not as straightforward as it may seem, since the two goals of model robustness and compactness may contradict from time to time. We formally study this new question, by proposing a novel Adversarially Trained Model Compression (ATMC) framework. A unified constrained optimization formulation is designed, with an efficient algorithm developed. An extensive group of experiments are then carefully designed and presented, demonstrating that ATMC obtains remarkably more favorable trade-off among model size, accuracy and robustness, over currently available alternatives in various settings.
P-MCGS: Parallel Monte Carlo Acyclic Graph Search
Oct 28, 2018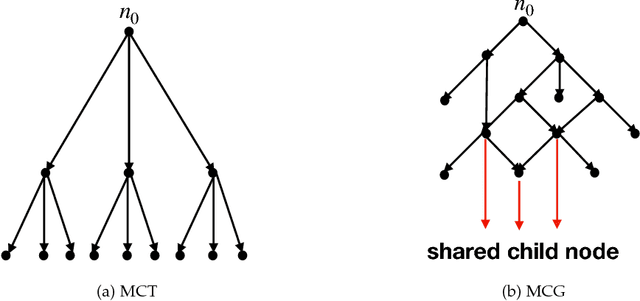
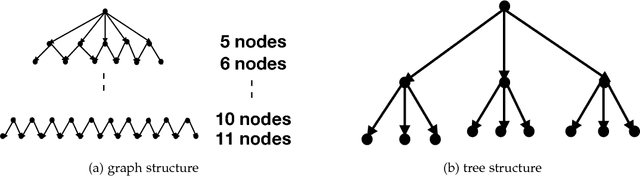
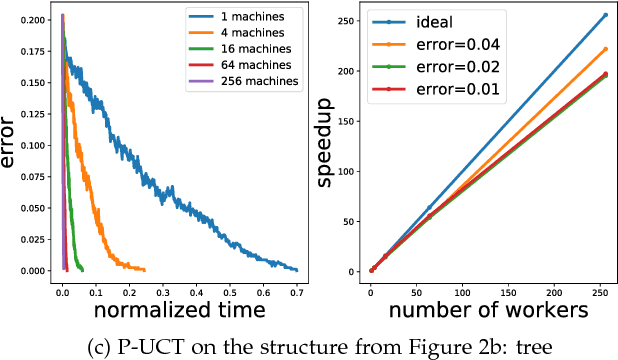
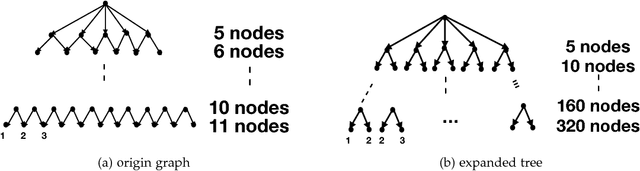
Recently, there have been great interests in Monte Carlo Tree Search (MCTS) in AI research. Although the sequential version of MCTS has been studied widely, its parallel counterpart still lacks systematic study. This leads us to the following questions: \emph{how to design efficient parallel MCTS (or more general cases) algorithms with rigorous theoretical guarantee? Is it possible to achieve linear speedup?} In this paper, we consider the search problem on a more general acyclic one-root graph (namely, Monte Carlo Graph Search (MCGS)), which generalizes MCTS. We develop a parallel algorithm (P-MCGS) to assign multiple workers to investigate appropriate leaf nodes simultaneously. Our analysis shows that P-MCGS algorithm achieves linear speedup and that the sample complexity is comparable to its sequential counterpart.
AutoML from Service Provider's Perspective: Multi-device, Multi-tenant Model Selection with GP-EI
Oct 28, 2018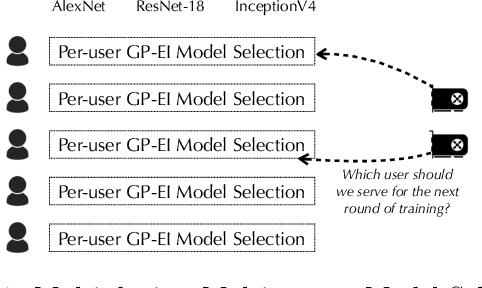
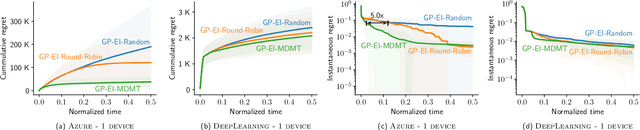
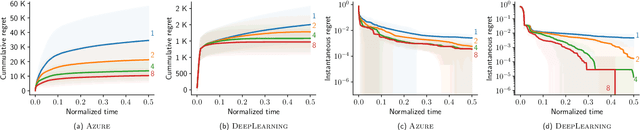
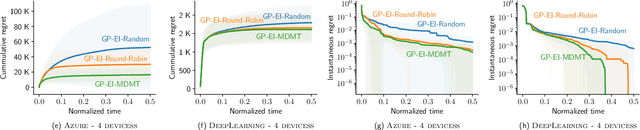
AutoML has become a popular service that is provided by most leading cloud service providers today. In this paper, we focus on the AutoML problem from the \emph{service provider's perspective}, motivated by the following practical consideration: When an AutoML service needs to serve {\em multiple users} with {\em multiple devices} at the same time, how can we allocate these devices to users in an efficient way? We focus on GP-EI, one of the most popular algorithms for automatic model selection and hyperparameter tuning, used by systems such as Google Vizer. The technical contribution of this paper is the first multi-device, multi-tenant algorithm for GP-EI that is aware of \emph{multiple} computation devices and multiple users sharing the same set of computation devices. Theoretically, given $N$ users and $M$ devices, we obtain a regret bound of $O((\text{\bf {MIU}}(T,K) + M)\frac{N^2}{M})$, where $\text{\bf {MIU}}(T,K)$ refers to the maximal incremental uncertainty up to time $T$ for the covariance matrix $K$. Empirically, we evaluate our algorithm on two applications of automatic model selection, and show that our algorithm significantly outperforms the strategy of serving users independently. Moreover, when multiple computation devices are available, we achieve near-linear speedup when the number of users is much larger than the number of devices.