 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Factual" or "Emotional": Stylized Image Captioning with Adaptive Learning and Attention
Jul 29, 2018
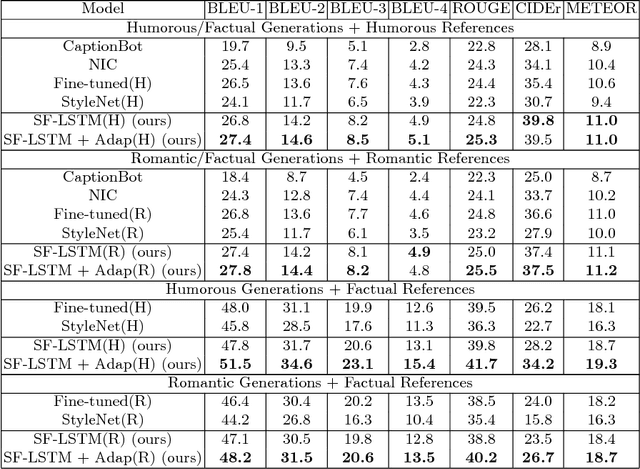
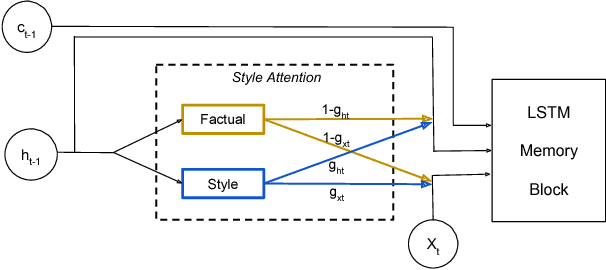
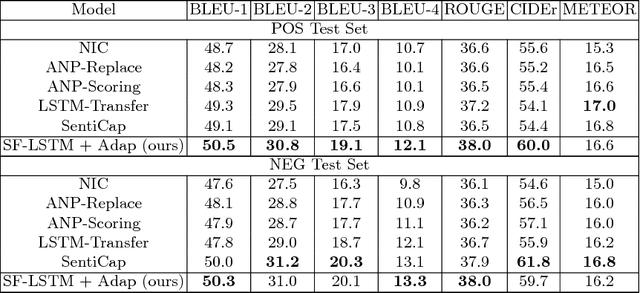
Generating stylized captions for an image is an emerging topic in image captioning. Given an image as input, it requires the system to generate a caption that has a specific style (e.g., humorous, romantic, positive, and negative) while describing the image content semantically accurately. In this paper, we propose a novel stylized image captioning model that effectively takes both requirements into consideration. To this end, we first devise a new variant of LSTM, named style-factual LSTM, as the building block of our model. It uses two groups of matrices to capture the factual and stylized knowledge, respectively, and automatically learns the word-level weights of the two groups based on previous context. In addition, when we train the model to capture stylized elements, we propose an adaptive learning approach based on a reference factual model, it provides factual knowledge to the model as the model learns from stylized caption labels, and can adaptively compute how much information to supply at each time step. We evaluate our model on two stylized image captioning datasets, which contain humorous/romantic captions and positive/negative captions, respectively. Experiments shows that our proposed model outperforms the state-of-the-art approaches, without using extra ground truth supervision.
Visual to Sound: Generating Natural Sound for Videos in the Wild
Jun 01, 2018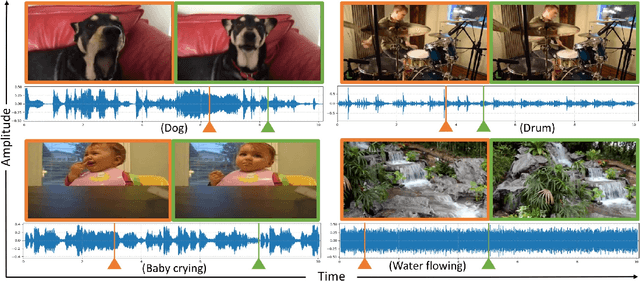

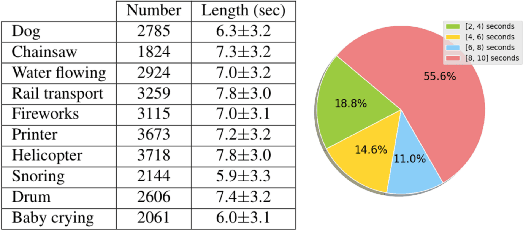
As two of the five traditional human senses (sight, hearing, taste, smell, and touch), vision and sound are basic sources through which humans understand the world. Often correlated during natural events, these two modalities combine to jointly affect human perception. In this paper, we pose the task of generating sound given visual input. Such capabilities could help enable applications in virtual reality (generating sound for virtual scenes automatically) or provide additional accessibility to images or videos for people with visual impairments. As a first step in this direction, we apply learning-based methods to generate raw waveform samples given input video frames. We evaluate our models on a dataset of videos containing a variety of sounds (such as ambient sounds and sounds from people/animals). Our experiments show that the generated sounds are fairly realistic and have good temporal synchronization with the visual inputs.
Speeding up Context-based Sentence Representation Learning with Non-autoregressive Convolutional Decoding
Jun 01, 2018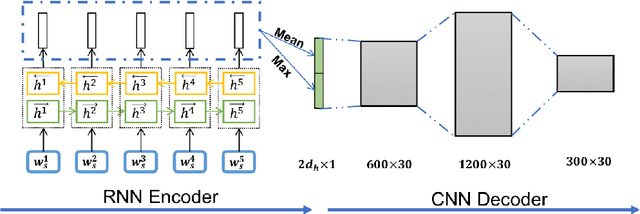
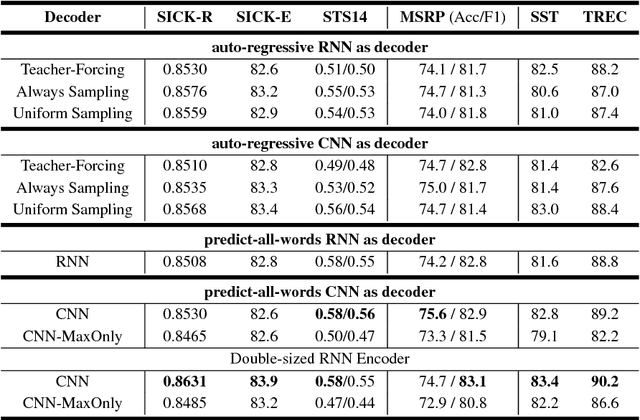
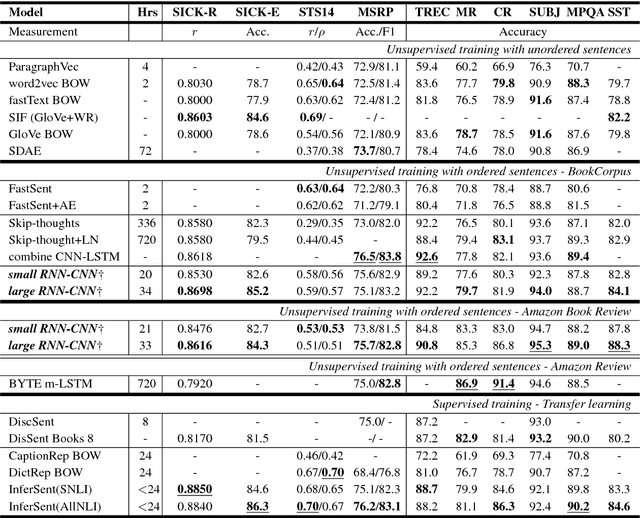
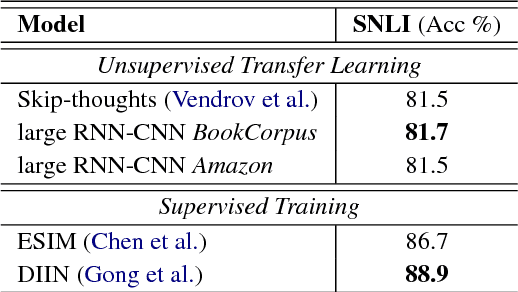
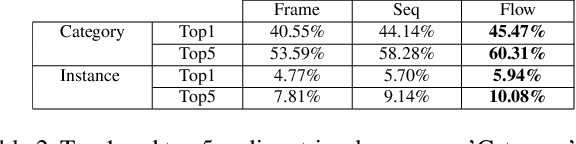
Context plays an important role in human language understanding, thus it may also be useful for machines learning vector representations of language. In this paper, we explore an asymmetric encoder-decoder structure for unsupervised context-based sentence representation learning. We carefully designed experiments to show that neither an autoregressive decoder nor an RNN decoder is required. After that, we designed a model which still keeps an RNN as the encoder, while using a non-autoregressive convolutional decoder. We further combine a suite of effective designs to significantly improve model efficiency while also achieving better performance. Our model is trained on two different large unlabelled corpora, and in both cases the transferability is evaluated on a set of downstream NLP tasks. We empirically show that our model is simple and fast while producing rich sentence representations that excel in downstream tasks.
Beyond Textures: Learning from Multi-domain Artistic Images for Arbitrary Style Transfer
May 25, 2018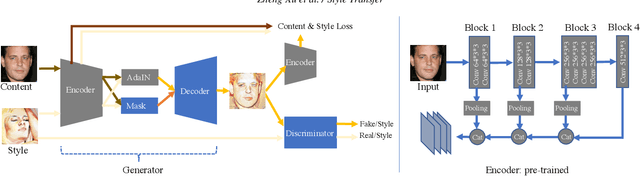



We propose a fast feed-forward network for arbitrary style transfer, which can generate stylized image for previously unseen content and style image pairs. Besides the traditional content and style representation based on deep features and statistics for textures, we use adversarial networks to regularize the generation of stylized images. Our adversarial network learns the intrinsic property of image styles from large-scale multi-domain artistic images. The adversarial training is challenging because both the input and output of our generator are diverse multi-domain images. We use a conditional generator that stylized content by shifting the statistics of deep features, and a conditional discriminator based on the coarse category of styles. Moreover, we propose a mask module to spatially decide the stylization level and stabilize adversarial training by avoiding mode collapse. As a side effect, our trained discriminator can be applied to rank and select representative stylized images. We qualitatively and quantitatively evaluate the proposed method, and compare with recent style transfer methods.
TextureGAN: Controlling Deep Image Synthesis with Texture Patches
Apr 14, 2018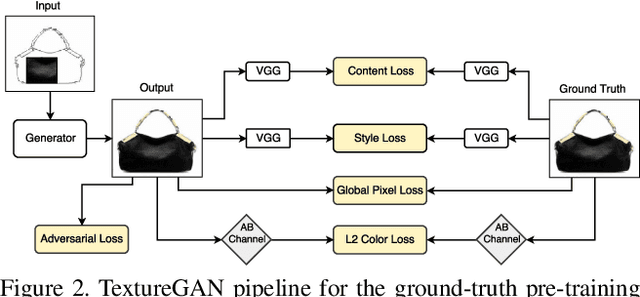
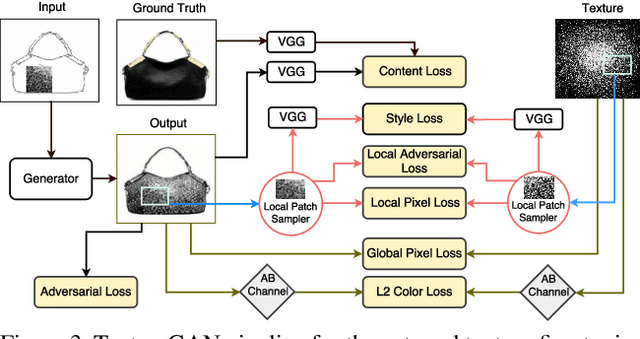


In this paper, we investigate deep image synthesis guided by sketch, color, and texture. Previous image synthesis methods can be controlled by sketch and color strokes but we are the first to examine texture control. We allow a user to place a texture patch on a sketch at arbitrary locations and scales to control the desired output texture. Our generative network learns to synthesize objects consistent with these texture suggestions. To achieve this, we develop a local texture loss in addition to adversarial and content loss to train the generative network. We conduct experiments using sketches generated from real images and textures sampled from a separate texture database and results show that our proposed algorithm is able to generate plausible images that are faithful to user controls. Ablation studies show that our proposed pipeline can generate more realistic images than adapting existing methods directly.
A global feature extraction model for the effective computer aided diagnosis of mild cognitive impairment using structural MRI images
Dec 02, 2017
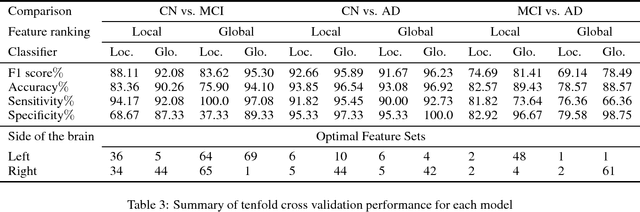


Multiple modalities of biomarkers have been proved to be very sensitive in assessing the progression of Alzheimer's disease (AD), and using these modalities and machine learning algorithms, several approaches have been proposed to assist in the early diagnosis of AD. Among the recent investigated state-of-the-art approaches, Gaussian discriminant analysis (GDA)-based approaches have been demonstrated to be more effective and accurate in the classification of AD, especially for delineating its prodromal stage of mild cognitive impairment (MCI). Moreover, among those binary classification investigations, the local feature extraction methods were mostly used, which made them hardly be applied to a practical computer aided diagnosis system. Therefore, this study presents a novel global feature extraction model taking advantage of the recent proposed GDA-based dual high-dimensional decision spaces, which can significantly improve the early diagnosis performance comparing to those local feature extraction methods. In the true test using 20% held-out data, for discriminating the most challenging MCI group from the cognitively normal control (CN) group, an F1 score of 91.06%, an accuracy of 88.78%, a sensitivity of 91.80%, and a specificity of 83.78% were achieved that can be considered as the best performance obtained so far.
The Cultural Evolution of National Constitutions
Nov 18, 2017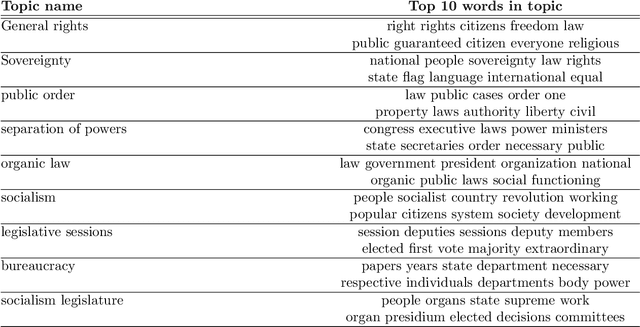
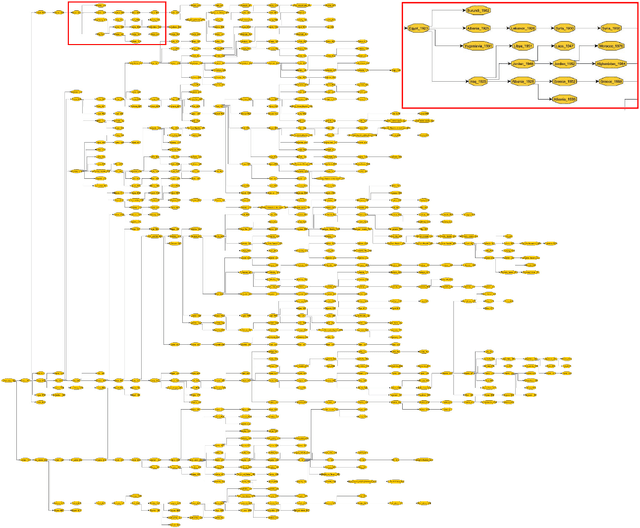
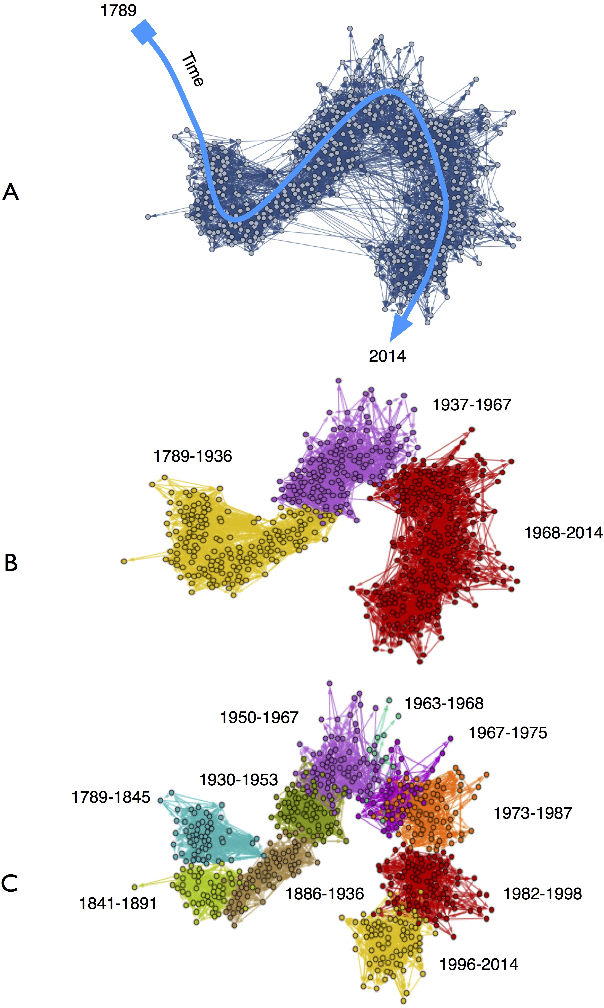
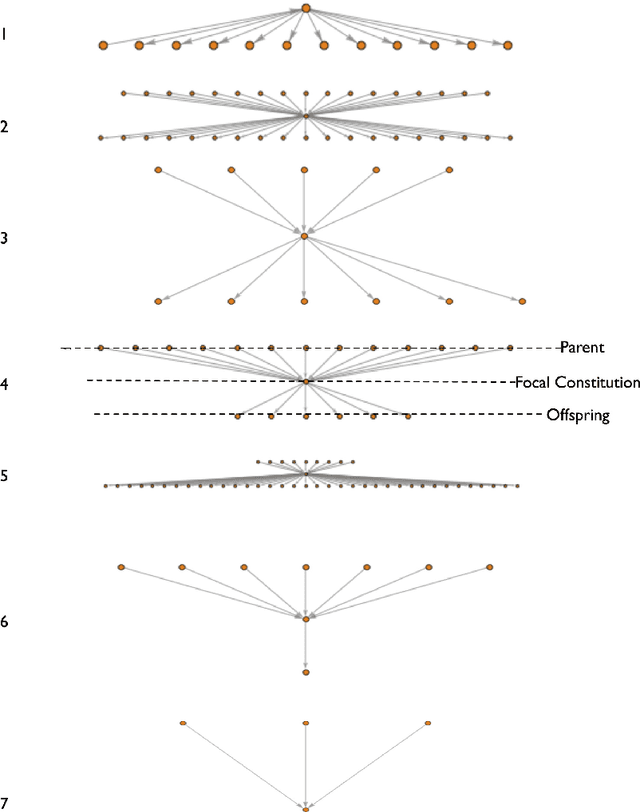
We explore how ideas from infectious disease and genetics can be used to uncover patterns of cultural inheritance and innovation in a corpus of 591 national constitutions spanning 1789 - 2008. Legal "Ideas" are encoded as "topics" - words statistically linked in documents - derived from topic modeling the corpus of constitutions. Using these topics we derive a diffusion network for borrowing from ancestral constitutions back to the US Constitution of 1789 and reveal that constitutions are complex cultural recombinants. We find systematic variation in patterns of borrowing from ancestral texts and "biological"-like behavior in patterns of inheritance with the distribution of "offspring" arising through a bounded preferential-attachment process. This process leads to a small number of highly innovative (influential) constitutions some of which have yet to have been identified as so in the current literature. Our findings thus shed new light on the critical nodes of the constitution-making network. The constitutional network structure reflects periods of intense constitution creation, and systematic patterns of variation in constitutional life-span and temporal influence.
Universal Style Transfer via Feature Transforms
Nov 17, 2017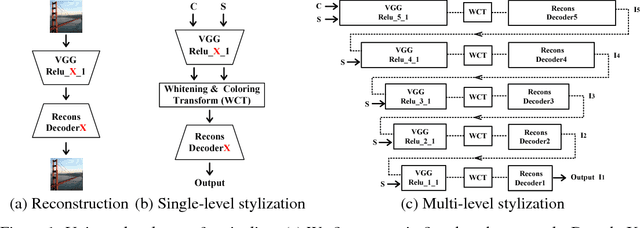



Universal style transfer aims to transfer arbitrary visual styles to content images. Existing feed-forward based methods, while enjoying the inference efficiency, are mainly limited by inability of generalizing to unseen styles or compromised visual quality. In this paper, we present a simple yet effective method that tackles these limitations without training on any pre-defined styles. The key ingredient of our method is a pair of feature transforms, whitening and coloring, that are embedded to an image reconstruction network. The whitening and coloring transforms reflect a direct matching of feature covariance of the content image to a given style image, which shares similar spirits with the optimization of Gram matrix based cost in neural style transfer. We demonstrate the effectiveness of our algorithm by generating high-quality stylized images with comparisons to a number of recent methods. We also analyze our method by visualizing the whitened features and synthesizing textures via simple feature coloring.
Visually-Aware Fashion Recommendation and Design with Generative Image Models
Nov 07, 2017
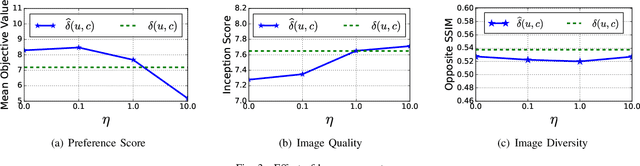

Building effective recommender systems for domains like fashion is challenging due to the high level of subjectivity and the semantic complexity of the features involved (i.e., fashion styles). Recent work has shown that approaches to `visual' recommendation (e.g.~clothing, art, etc.) can be made more accurate by incorporating visual signals directly into the recommendation objective, using `off-the-shelf' feature representations derived from deep networks. Here, we seek to extend this contribution by showing that recommendation performance can be significantly improved by learning `fashion aware' image representations directly, i.e., by training the image representation (from the pixel level) and the recommender system jointly; this contribution is related to recent work using Siamese CNNs, though we are able to show improvements over state-of-the-art recommendation techniques such as BPR and variants that make use of pre-trained visual features. Furthermore, we show that our model can be used \emph{generatively}, i.e., given a user and a product category, we can generate new images (i.e., clothing items) that are most consistent with their personal taste. This represents a first step towards building systems that go beyond recommending existing items from a product corpus, but which can be used to suggest styles and aid the design of new products.
BAM! The Behance Artistic Media Dataset for Recognition Beyond Photography
Jul 09, 2017
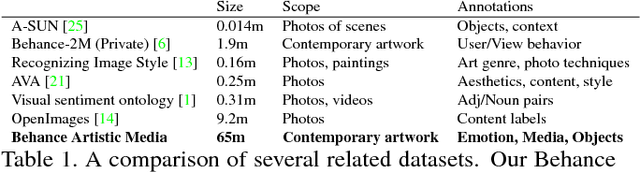

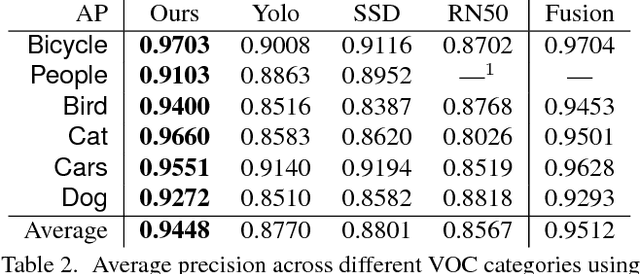
Computer vision systems are designed to work well within the context of everyday photography. However, artists often render the world around them in ways that do not resemble photographs. Artwork produced by people is not constrained to mimic the physical world, making it more challenging for machines to recognize. This work is a step toward teaching machines how to categorize images in ways that are valuable to humans. First, we collect a large-scale dataset of contemporary artwork from Behance, a website containing millions of portfolios from professional and commercial artists. We annotate Behance imagery with rich attribute labels for content, emotions, and artistic media. Furthermore, we carry out baseline experiments to show the value of this dataset for artistic style prediction, for improving the generality of existing object classifiers, and for the study of visual domain adaptation. We believe our Behance Artistic Media dataset will be a good starting point for researchers wishing to study artistic imagery and relevant problems.