 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorldMemArena: Evaluating Multimodal Agent Memory Through Action-World Interaction
May 28, 2026Multimodal large language models are increasingly deployed as long-horizon agents, where memory must do more than recall: it must track an evolving world, revise what has gone stale, and surface the right evidence at decision time. Existing benchmarks measure recall over static dialogue, collapse memory into a single end-of-task accuracy, and reduce visual observations to captions, leaving us unable to localize failures to writing, maintenance, retrieval, or use. The rise of agent harnesses that author their own memory sharpens this gap, since we have no principled way to compare hand-designed pipelines with self-managing alternatives. To close these gaps, we formulate multimodal agent memory as an Action-World Interaction Loop with an observable four-stage lifecycle, and instantiate it in WorldMemArena: 400 multi-session multimodal tasks spanning Lifelong Evolution (evolving personal and task states) and Agentic Execution (memory from real observations, actions, and feedback), annotated with gold memory points, updates, distractors, and evidence chains for stage-level diagnosis. This enables the first head-to-head comparison of long-context, manually designed (RAG and external memory systems), and harness-based memory agents. Results show that: (1) better memory writing and storage do not guarantee better performance; (2) multimodal memory still struggles to fully use visual evidence; (3) systems are unstable across domains and degrade on realistic agentic trajectories; and (4) harness memory is more flexible but remains costly and less reliable.
Deep FinResearch Bench: Evaluating AI's Ability to Conduct Professional Financial Investment Research
Apr 22, 2026We introduce Deep FinResearch Bench, a practical and comprehensive evaluation framework for deep research (DR) agents in financial investment research. The benchmark assesses three dimensions of report quality: qualitative rigor, quantitative forecasting and valuation accuracy, and claim credibility and verifiability. Particularly, we define corresponding qualitative and quantitative evaluation metrics and implement an automated scoring procedure to enable scalable assessment. Applying the benchmark to financial reports from frontier DR agents and comparing them with reports authored by financial professionals, we find that AI-generated reports still fall short across these dimensions. These findings underscore the need for domain-specialized DR agents tailored to finance, and we hope the work establishes a foundation for standardized benchmarking of DR agents in financial research.
A Variational Approach for Mitigating Entity Bias in Relation Extraction
Jun 13, 2025Mitigating entity bias is a critical challenge in Relation Extraction (RE), where models often rely excessively on entities, resulting in poor generalization. This paper presents a novel approach to address this issue by adapting a Variational Information Bottleneck (VIB) framework. Our method compresses entity-specific information while preserving task-relevant features. It achieves state-of-the-art performance on relation extraction datasets across general, financial, and biomedical domains, in both indomain (original test sets) and out-of-domain (modified test sets with type-constrained entity replacements) settings. Our approach offers a robust, interpretable, and theoretically grounded methodology.
GenPlanX. Generation of Plans and Execution
Jun 12, 2025Classical AI Planning techniques generate sequences of actions for complex tasks. However, they lack the ability to understand planning tasks when provided using natural language. The advent of Large Language Models (LLMs) has introduced novel capabilities in human-computer interaction. In the context of planning tasks, LLMs have shown to be particularly good in interpreting human intents among other uses. This paper introduces GenPlanX that integrates LLMs for natural language-based description of planning tasks, with a classical AI planning engine, alongside an execution and monitoring framework. We demonstrate the efficacy of GenPlanX in assisting users with office-related tasks, highlighting its potential to streamline workflows and enhance productivity through seamless human-AI collaboration.
Conservative Bias in Large Language Models: Measuring Relation Predictions
Jun 09, 2025Large language models (LLMs) exhibit pronounced conservative bias in relation extraction tasks, frequently defaulting to No_Relation label when an appropriate option is unavailable. While this behavior helps prevent incorrect relation assignments, our analysis reveals that it also leads to significant information loss when reasoning is not explicitly included in the output. We systematically evaluate this trade-off across multiple prompts, datasets, and relation types, introducing the concept of Hobson's choice to capture scenarios where models opt for safe but uninformative labels over hallucinated ones. Our findings suggest that conservative bias occurs twice as often as hallucination. To quantify this effect, we use SBERT and LLM prompts to capture the semantic similarity between conservative bias behaviors in constrained prompts and labels generated from semi-constrained and open-ended prompts.
Grounding LLM Reasoning with Knowledge Graphs
Feb 18, 2025Knowledge Graphs (KGs) are valuable tools for representing relationships between entities in a structured format. Traditionally, these knowledge bases are queried to extract specific information. However, question-answering (QA) over such KGs poses a challenge due to the intrinsic complexity of natural language compared to the structured format and the size of these graphs. Despite these challenges, the structured nature of KGs can provide a solid foundation for grounding the outputs of Large Language Models (LLMs), offering organizations increased reliability and control. Recent advancements in LLMs have introduced reasoning methods at inference time to improve their performance and maximize their capabilities. In this work, we propose integrating these reasoning strategies with KGs to anchor every step or "thought" of the reasoning chains in KG data. Specifically, we evaluate both agentic and automated search methods across several reasoning strategies, including Chain-of-Thought (CoT), Tree-of-Thought (ToT), and Graph-of-Thought (GoT), using GRBench, a benchmark dataset for graph reasoning with domain-specific graphs. Our experiments demonstrate that this approach consistently outperforms baseline models, highlighting the benefits of grounding LLM reasoning processes in structured KG data.
FinQAPT: Empowering Financial Decisions with End-to-End LLM-driven Question Answering Pipeline
Oct 17, 2024Financial decision-making hinges on the analysis of relevant information embedded in the enormous volume of documents in the financial domain. To address this challenge, we developed FinQAPT, an end-to-end pipeline that streamlines the identification of relevant financial reports based on a query, extracts pertinent context, and leverages Large Language Models (LLMs) to perform downstream tasks. To evaluate the pipeline, we experimented with various techniques to optimize the performance of each module using the FinQA dataset. We introduced a novel clustering-based negative sampling technique to enhance context extraction and a novel prompting method called Dynamic N-shot Prompting to boost the numerical question-answering capabilities of LLMs. At the module level, we achieved state-of-the-art accuracy on FinQA, attaining an accuracy of 80.6\%. However, at the pipeline level, we observed decreased performance due to challenges in extracting relevant context from financial reports. We conducted a detailed error analysis of each module and the end-to-end pipeline, pinpointing specific challenges that must be addressed to develop a robust solution for handling complex financial tasks.
Large Language Models as Financial Data Annotators: A Study on Effectiveness and Efficiency
Mar 26, 2024Collecting labeled datasets in finance is challenging due to scarcity of domain experts and higher cost of employing them. While Large Language Models (LLMs) have demonstrated remarkable performance in data annotation tasks on general domain datasets, their effectiveness on domain specific datasets remains underexplored. To address this gap, we investigate the potential of LLMs as efficient data annotators for extracting relations in financial documents. We compare the annotations produced by three LLMs (GPT-4, PaLM 2, and MPT Instruct) against expert annotators and crowdworkers. We demonstrate that the current state-of-the-art LLMs can be sufficient alternatives to non-expert crowdworkers. We analyze models using various prompts and parameter settings and find that customizing the prompts for each relation group by providing specific examples belonging to those groups is paramount. Furthermore, we introduce a reliability index (LLM-RelIndex) used to identify outputs that may require expert attention. Finally, we perform an extensive time, cost and error analysis and provide recommendations for the collection and usage of automated annotations in domain-specific settings.
WHEN FLUE MEETS FLANG: Benchmarks and Large Pre-trained Language Model for Financial Domain
Oct 31, 2022



Pre-trained language models have shown impressive performance on a variety of tasks and domains. Previous research on financial language models usually employs a generic training scheme to train standard model architectures, without completely leveraging the richness of the financial data. We propose a novel domain specific Financial LANGuage model (FLANG) which uses financial keywords and phrases for better masking, together with span boundary objective and in-filing objective. Additionally, the evaluation benchmarks in the field have been limited. To this end, we contribute the Financial Language Understanding Evaluation (FLUE), an open-source comprehensive suite of benchmarks for the financial domain. These include new benchmarks across 5 NLP tasks in financial domain as well as common benchmarks used in the previous research. Experiments on these benchmarks suggest that our model outperforms those in prior literature on a variety of NLP tasks. Our models, code and benchmark data are publicly available on Github and Huggingface.
ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering
Oct 07, 2022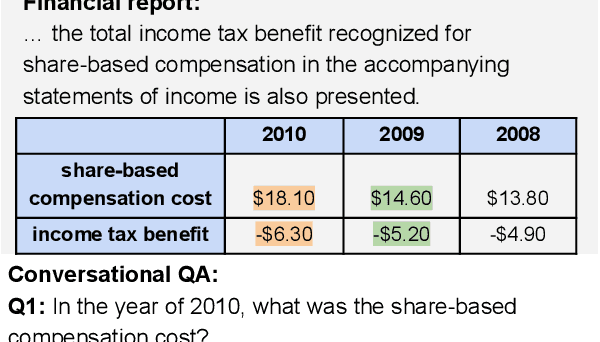

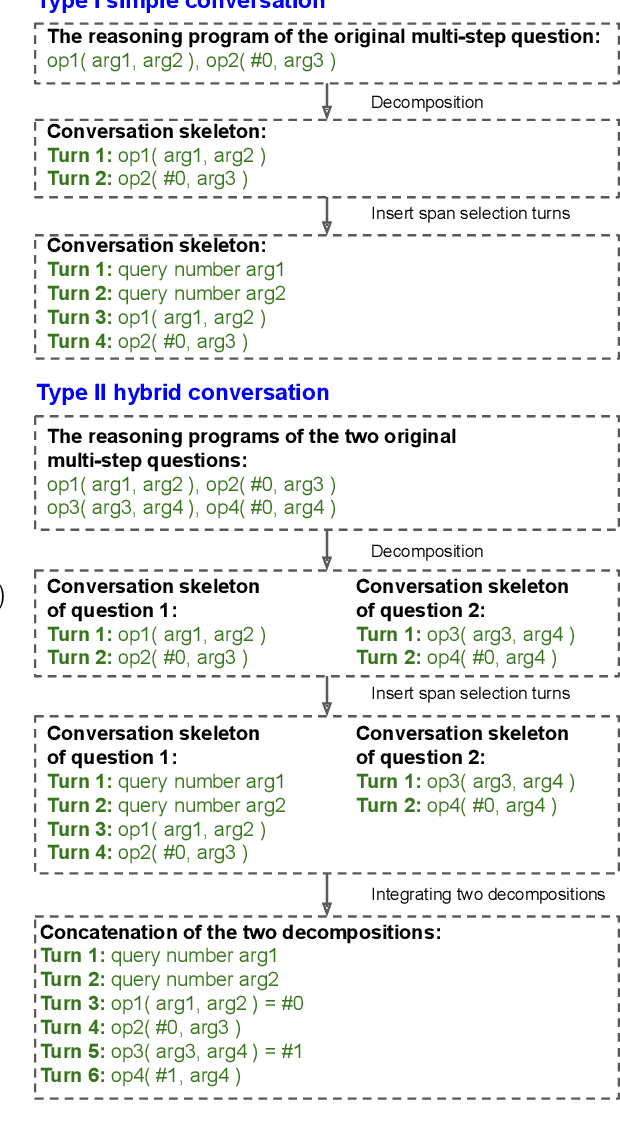

With the recent advance in large pre-trained language models, researchers have achieved record performances in NLP tasks that mostly focus on language pattern matching. The community is experiencing the shift of the challenge from how to model language to the imitation of complex reasoning abilities like human beings. In this work, we investigate the application domain of finance that involves real-world, complex numerical reasoning. We propose a new large-scale dataset, ConvFinQA, aiming to study the chain of numerical reasoning in conversational question answering. Our dataset poses great challenge in modeling long-range, complex numerical reasoning paths in real-world conversations. We conduct comprehensive experiments and analyses with both the neural symbolic methods and the prompting-based methods, to provide insights into the reasoning mechanisms of these two divisions. We believe our new dataset should serve as a valuable resource to push forward the exploration of real-world, complex reasoning tasks as the next research focus. Our dataset and code is publicly available at https://github.com/czyssrs/ConvFinQA.