 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Holistic Visual Quality Assessment of AI-Generated Videos: A LLM-Based Multi-Dimensional Evaluation Model
Jun 05, 2025



The development of AI-Generated Video (AIGV) technology has been remarkable in recent years, significantly transforming the paradigm of video content production. However, AIGVs still suffer from noticeable visual quality defects, such as noise, blurriness, frame jitter and low dynamic degree, which severely impact the user's viewing experience. Therefore, an effective automatic visual quality assessment is of great importance for AIGV content regulation and generative model improvement. In this work, we decompose the visual quality of AIGVs into three dimensions: technical quality, motion quality, and video semantics. For each dimension, we design corresponding encoder to achieve effective feature representation. Moreover, considering the outstanding performance of large language models (LLMs) in various vision and language tasks, we introduce a LLM as the quality regression module. To better enable the LLM to establish reasoning associations between multi-dimensional features and visual quality, we propose a specially designed multi-modal prompt engineering framework. Additionally, we incorporate LoRA fine-tuning technology during the training phase, allowing the LLM to better adapt to specific tasks. Our proposed method achieved \textbf{second place} in the NTIRE 2025 Quality Assessment of AI-Generated Content Challenge: Track 2 AI Generated video, demonstrating its effectiveness. Codes can be obtained at https://github.com/QiZelu/AIGVEval.
Comprehensive Subjective and Objective Evaluation Method for Text-generated Video
Jan 15, 2025



Recent text-to-video (T2V) technology advancements, as demonstrated by models such as Gen3, Pika, and Sora, have significantly broadened its applicability and popularity. This progress has created a growing demand for accurate quality assessment metrics to evaluate the perceptual quality of text-generated videos and optimize video generation models. However, assessing the quality of text-generated videos remains challenging due to the presence of highly complex distortions, such as unnatural actions and phenomena that defy human cognition. To address these challenges, we constructed a large-scale benchmark dataset for \textbf{T}ext-generated \textbf{V}ideo \textbf{eval}uation, \textbf{T2VEval-Bench}, comprising 148 textual words and 1,783 videos generated by 12 models. During the subjective evaluation, we collected five key scores: overall impression, video quality, aesthetic quality, realness, and text-video consistency. For objective evaluation, we developed the \textbf{T2VEval} model, which assesses videos across three branches: quality, authenticity, and consistency. Using an attention-based fusion module, T2VEval effectively integrates features from each branch and predicts scores with the aid of a large oracle model. Additionally, we implemented a progressive training strategy, enabling each branch to learn targeted knowledge while maintaining synergy with the others. Experimental results demonstrate that T2VEval achieves state-of-the-art performance across multiple metrics. The dataset and code will be open-sourced upon completion of the follow-up work.
Blind Predicting Similar Quality Map for Image Quality Assessment
May 22, 2018
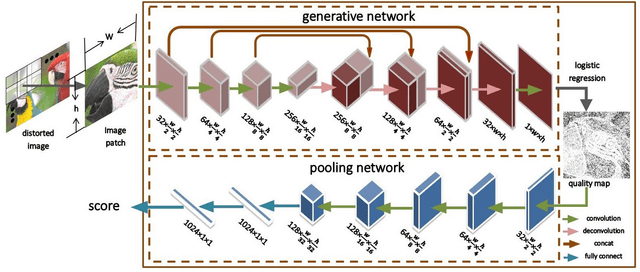
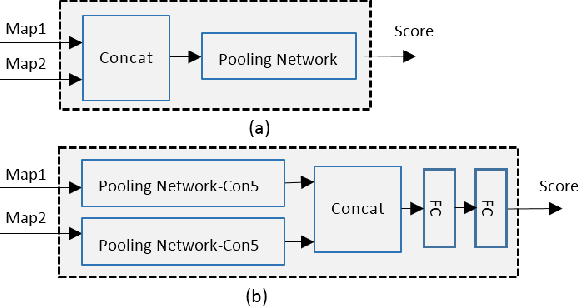

A key problem in blind image quality assessment (BIQA) is how to effectively model the properties of human visual system in a data-driven manner. In this paper, we propose a simple and efficient BIQA model based on a novel framework which consists of a fully convolutional neural network (FCNN) and a pooling network to solve this problem. In principle, FCNN is capable of predicting a pixel-by-pixel similar quality map only from a distorted image by using the intermediate similarity maps derived from conventional full-reference image quality assessment methods. The predicted pixel-by-pixel quality maps have good consistency with the distortion correlations between the reference and distorted images. Finally, a deep pooling network regresses the quality map into a score. Experiments have demonstrated that our predictions outperform many state-of-the-art BIQA methods.