 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePF-DAformer: Proximal Femur Segmentation via Domain Adaptive Transformer for Dual-Center QCT
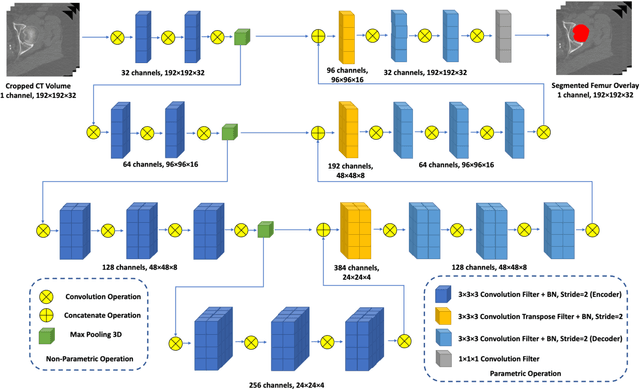
Oct 30, 2025Quantitative computed tomography (QCT) plays a crucial role in assessing bone strength and fracture risk by enabling volumetric analysis of bone density distribution in the proximal femur. However, deploying automated segmentation models in practice remains difficult because deep networks trained on one dataset often fail when applied to another. This failure stems from domain shift, where scanners, reconstruction settings, and patient demographics vary across institutions, leading to unstable predictions and unreliable quantitative metrics. Overcoming this barrier is essential for multi-center osteoporosis research and for ensuring that radiomics and structural finite element analysis results remain reproducible across sites. In this work, we developed a domain-adaptive transformer segmentation framework tailored for multi-institutional QCT. Our model is trained and validated on one of the largest hip fracture related research cohorts to date, comprising 1,024 QCT images scans from Tulane University and 384 scans from Rochester, Minnesota for proximal femur segmentation. To address domain shift, we integrate two complementary strategies within a 3D TransUNet backbone: adversarial alignment via Gradient Reversal Layer (GRL), which discourages the network from encoding site-specific cues, and statistical alignment via Maximum Mean Discrepancy (MMD), which explicitly reduces distributional mismatches between institutions. This dual mechanism balances invariance and fine-grained alignment, enabling scanner-agnostic feature learning while preserving anatomical detail.
A Deep Learning-Based Method for Automatic Segmentation of Proximal Femur from Quantitative Computed Tomography Images
Jul 01, 2020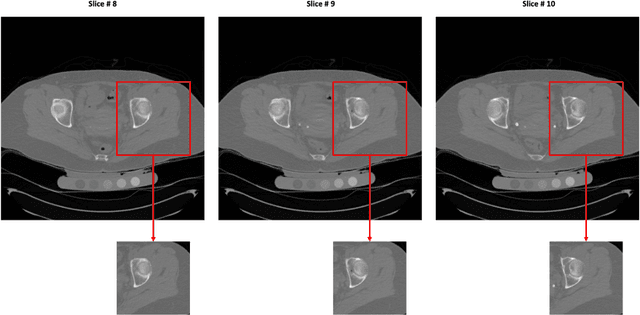
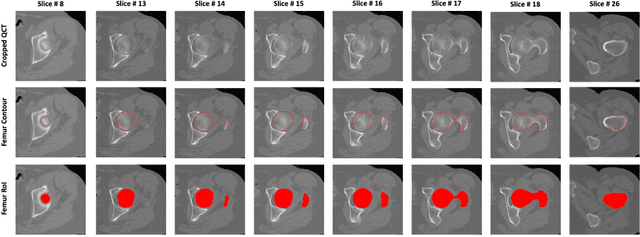

Purpose: Proximal femur image analyses based on quantitative computed tomography (QCT) provide a method to quantify the bone density and evaluate osteoporosis and risk of fracture. We aim to develop a deep-learning-based method for automatic proximal femur segmentation. Methods and Materials: We developed a 3D image segmentation method based on V-Net, an end-to-end fully convolutional neural network (CNN), to extract the proximal femur QCT images automatically. The proposed V-net methodology adopts a compound loss function, which includes a Dice loss and a L2 regularizer. We performed experiments to evaluate the effectiveness of the proposed segmentation method. In the experiments, a QCT dataset which included 397 QCT subjects was used. For the QCT image of each subject, the ground truth for the proximal femur was delineated by a well-trained scientist. During the experiments for the entire cohort then for male and female subjects separately, 90% of the subjects were used in 10-fold cross-validation for training and internal validation, and to select the optimal parameters of the proposed models; the rest of the subjects were used to evaluate the performance of models. Results: Visual comparison demonstrated high agreement between the model prediction and ground truth contours of the proximal femur portion of the QCT images. In the entire cohort, the proposed model achieved a Dice score of 0.9815, a sensitivity of 0.9852 and a specificity of 0.9992. In addition, an R2 score of 0.9956 (p<0.001) was obtained when comparing the volumes measured by our model prediction with the ground truth. Conclusion: This method shows a great promise for clinical application to QCT and QCT-based finite element analysis of the proximal femur for evaluating osteoporosis and hip fracture risk.