 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised Cycle-GAN for face photo-sketch translation in the wild
Jul 18, 2023The performance of face photo-sketch translation has improved a lot thanks to deep neural networks. GAN based methods trained on paired images can produce high-quality results under laboratory settings. Such paired datasets are, however, often very small and lack diversity. Meanwhile, Cycle-GANs trained with unpaired photo-sketch datasets suffer from the \emph{steganography} phenomenon, which makes them not effective to face photos in the wild. In this paper, we introduce a semi-supervised approach with a noise-injection strategy, named Semi-Cycle-GAN (SCG), to tackle these problems. For the first problem, we propose a {\em pseudo sketch feature} representation for each input photo composed from a small reference set of photo-sketch pairs, and use the resulting {\em pseudo pairs} to supervise a photo-to-sketch generator $G_{p2s}$. The outputs of $G_{p2s}$ can in turn help to train a sketch-to-photo generator $G_{s2p}$ in a self-supervised manner. This allows us to train $G_{p2s}$ and $G_{s2p}$ using a small reference set of photo-sketch pairs together with a large face photo dataset (without ground-truth sketches). For the second problem, we show that the simple noise-injection strategy works well to alleviate the \emph{steganography} effect in SCG and helps to produce more reasonable sketch-to-photo results with less overfitting than fully supervised approaches. Experiments show that SCG achieves competitive performance on public benchmarks and superior results on photos in the wild.
Towards Explainable In-the-Wild Video Quality Assessment: a Database and a Language-Prompted Approach
May 22, 2023



The proliferation of in-the-wild videos has greatly expanded the Video Quality Assessment (VQA) problem. Unlike early definitions that usually focus on limited distortion types, VQA on in-the-wild videos is especially challenging as it could be affected by complicated factors, including various distortions and diverse contents. Though subjective studies have collected overall quality scores for these videos, how the abstract quality scores relate with specific factors is still obscure, hindering VQA methods from more concrete quality evaluations (e.g. sharpness of a video). To solve this problem, we collect over two million opinions on 4,543 in-the-wild videos on 13 dimensions of quality-related factors, including in-capture authentic distortions (e.g. motion blur, noise, flicker), errors introduced by compression and transmission, and higher-level experiences on semantic contents and aesthetic issues (e.g. composition, camera trajectory), to establish the multi-dimensional Maxwell database. Specifically, we ask the subjects to label among a positive, a negative, and a neural choice for each dimension. These explanation-level opinions allow us to measure the relationships between specific quality factors and abstract subjective quality ratings, and to benchmark different categories of VQA algorithms on each dimension, so as to more comprehensively analyze their strengths and weaknesses. Furthermore, we propose the MaxVQA, a language-prompted VQA approach that modifies vision-language foundation model CLIP to better capture important quality issues as observed in our analyses. The MaxVQA can jointly evaluate various specific quality factors and final quality scores with state-of-the-art accuracy on all dimensions, and superb generalization ability on existing datasets. Code and data available at \url{https://github.com/VQAssessment/MaxVQA}.
Towards Robust Text-Prompted Semantic Criterion for In-the-Wild Video Quality Assessment
Apr 28, 2023



The proliferation of videos collected during in-the-wild natural settings has pushed the development of effective Video Quality Assessment (VQA) methodologies. Contemporary supervised opinion-driven VQA strategies predominantly hinge on training from expensive human annotations for quality scores, which limited the scale and distribution of VQA datasets and consequently led to unsatisfactory generalization capacity of methods driven by these data. On the other hand, although several handcrafted zero-shot quality indices do not require training from human opinions, they are unable to account for the semantics of videos, rendering them ineffective in comprehending complex authentic distortions (e.g., white balance, exposure) and assessing the quality of semantic content within videos. To address these challenges, we introduce the text-prompted Semantic Affinity Quality Index (SAQI) and its localized version (SAQI-Local) using Contrastive Language-Image Pre-training (CLIP) to ascertain the affinity between textual prompts and visual features, facilitating a comprehensive examination of semantic quality concerns without the reliance on human quality annotations. By amalgamating SAQI with existing low-level metrics, we propose the unified Blind Video Quality Index (BVQI) and its improved version, BVQI-Local, which demonstrates unprecedented performance, surpassing existing zero-shot indices by at least 24\% on all datasets. Moreover, we devise an efficient fine-tuning scheme for BVQI-Local that jointly optimizes text prompts and final fusion weights, resulting in state-of-the-art performance and superior generalization ability in comparison to prevalent opinion-driven VQA methods. We conduct comprehensive analyses to investigate different quality concerns of distinct indices, demonstrating the effectiveness and rationality of our design.
Exploring Opinion-unaware Video Quality Assessment with Semantic Affinity Criterion
Feb 26, 2023



Recent learning-based video quality assessment (VQA) algorithms are expensive to implement due to the cost of data collection of human quality opinions, and are less robust across various scenarios due to the biases of these opinions. This motivates our exploration on opinion-unaware (a.k.a zero-shot) VQA approaches. Existing approaches only considers low-level naturalness in spatial or temporal domain, without considering impacts from high-level semantics. In this work, we introduce an explicit semantic affinity index for opinion-unaware VQA using text-prompts in the contrastive language-image pre-training (CLIP) model. We also aggregate it with different traditional low-level naturalness indexes through gaussian normalization and sigmoid rescaling strategies. Composed of aggregated semantic and technical metrics, the proposed Blind Unified Opinion-Unaware Video Quality Index via Semantic and Technical Metric Aggregation (BUONA-VISTA) outperforms existing opinion-unaware VQA methods by at least 20% improvements, and is more robust than opinion-aware approaches.
MIMO Is All You Need : A Strong Multi-In-Multi-Out Baseline for Video Prediction
Dec 09, 2022



The mainstream of the existing approaches for video prediction builds up their models based on a Single-In-Single-Out (SISO) architecture, which takes the current frame as input to predict the next frame in a recursive manner. This way often leads to severe performance degradation when they try to extrapolate a longer period of future, thus limiting the practical use of the prediction model. Alternatively, a Multi-In-Multi-Out (MIMO) architecture that outputs all the future frames at one shot naturally breaks the recursive manner and therefore prevents error accumulation. However, only a few MIMO models for video prediction are proposed and they only achieve inferior performance due to the date. The real strength of the MIMO model in this area is not well noticed and is largely under-explored. Motivated by that, we conduct a comprehensive investigation in this paper to thoroughly exploit how far a simple MIMO architecture can go. Surprisingly, our empirical studies reveal that a simple MIMO model can outperform the state-of-the-art work with a large margin much more than expected, especially in dealing with longterm error accumulation. After exploring a number of ways and designs, we propose a new MIMO architecture based on extending the pure Transformer with local spatio-temporal blocks and a new multi-output decoder, namely MIMO-VP, to establish a new standard in video prediction. We evaluate our model in four highly competitive benchmarks (Moving MNIST, Human3.6M, Weather, KITTI). Extensive experiments show that our model wins 1st place on all the benchmarks with remarkable performance gains and surpasses the best SISO model in all aspects including efficiency, quantity, and quality. We believe our model can serve as a new baseline to facilitate the future research of video prediction tasks. The code will be released.
Disentangling Aesthetic and Technical Effects for Video Quality Assessment of User Generated Content
Nov 16, 2022User-generated-content (UGC) videos have dominated the Internet during recent years. While it is well-recognized that the perceptual quality of these videos can be affected by diverse factors, few existing methods explicitly explore the effects of different factors in video quality assessment (VQA) for UGC videos, i.e. the UGC-VQA problem. In this work, we make the first attempt to disentangle the effects of aesthetic quality issues and technical quality issues risen by the complicated video generation processes in the UGC-VQA problem. To overcome the absence of respective supervisions during disentanglement, we propose the Limited View Biased Supervisions (LVBS) scheme where two separate evaluators are trained with decomposed views specifically designed for each issue. Composed of an Aesthetic Quality Evaluator (AQE) and a Technical Quality Evaluator (TQE) under the LVBS scheme, the proposed Disentangled Objective Video Quality Evaluator (DOVER) reach excellent performance (0.91 SRCC for KoNViD-1k, 0.89 SRCC for LSVQ, 0.88 SRCC for YouTube-UGC) in the UGC-VQA problem. More importantly, our blind subjective studies prove that the separate evaluators in DOVER can effectively match human perception on respective disentangled quality issues. Codes and demos are released in https://github.com/teowu/dover.
S$^3$-NeRF: Neural Reflectance Field from Shading and Shadow under a Single Viewpoint
Oct 17, 2022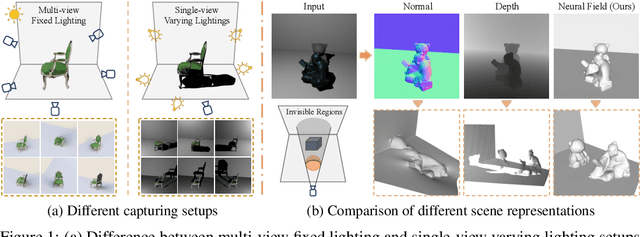
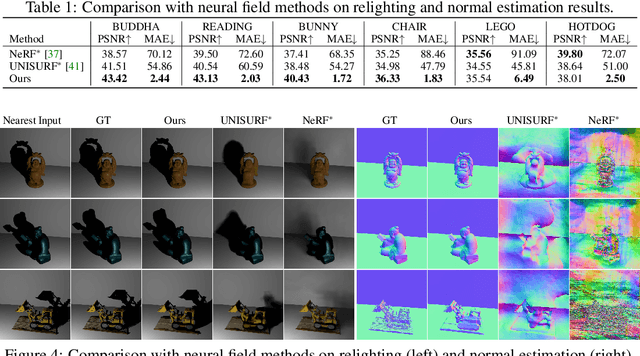
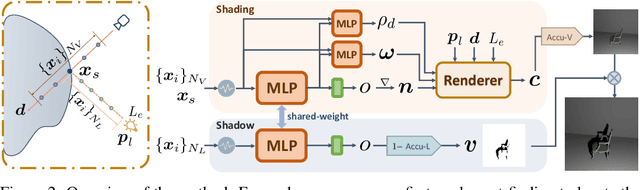
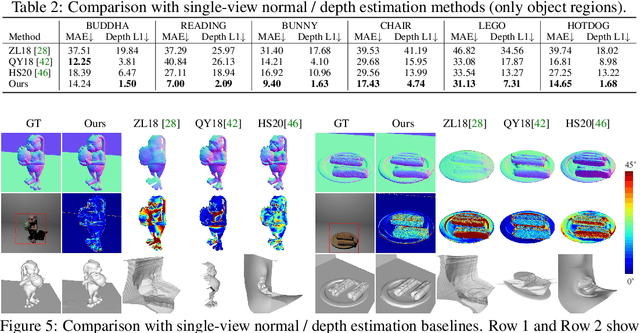
In this paper, we address the "dual problem" of multi-view scene reconstruction in which we utilize single-view images captured under different point lights to learn a neural scene representation. Different from existing single-view methods which can only recover a 2.5D scene representation (i.e., a normal / depth map for the visible surface), our method learns a neural reflectance field to represent the 3D geometry and BRDFs of a scene. Instead of relying on multi-view photo-consistency, our method exploits two information-rich monocular cues, namely shading and shadow, to infer scene geometry. Experiments on multiple challenging datasets show that our method is capable of recovering 3D geometry, including both visible and invisible parts, of a scene from single-view images. Thanks to the neural reflectance field representation, our method is robust to depth discontinuities. It supports applications like novel-view synthesis and relighting. Our code and model can be found at https://ywq.github.io/s3nerf.
Neighbourhood Representative Sampling for Efficient End-to-end Video Quality Assessment
Oct 11, 2022
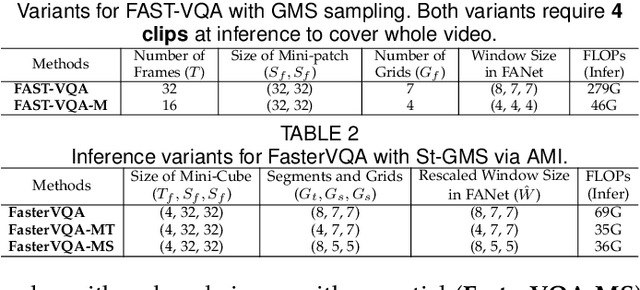
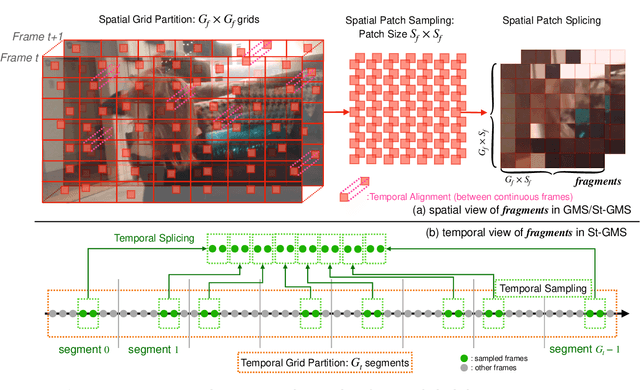
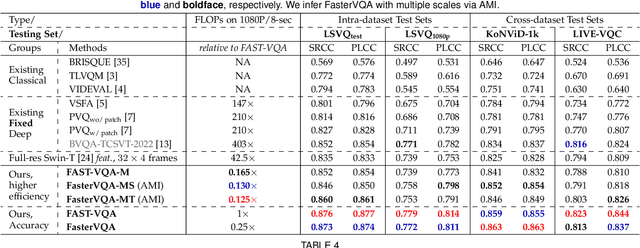
The increased resolution of real-world videos presents a dilemma between efficiency and accuracy for deep Video Quality Assessment (VQA). On the one hand, keeping the original resolution will lead to unacceptable computational costs. On the other hand, existing practices, such as resizing and cropping, will change the quality of original videos due to the loss of details and contents, and are therefore harmful to quality assessment. With the obtained insight from the study of spatial-temporal redundancy in the human visual system and visual coding theory, we observe that quality information around a neighbourhood is typically similar, motivating us to investigate an effective quality-sensitive neighbourhood representatives scheme for VQA. In this work, we propose a unified scheme, spatial-temporal grid mini-cube sampling (St-GMS) to get a novel type of sample, named fragments. Full-resolution videos are first divided into mini-cubes with preset spatial-temporal grids, then the temporal-aligned quality representatives are sampled to compose the fragments that serve as inputs for VQA. In addition, we design the Fragment Attention Network (FANet), a network architecture tailored specifically for fragments. With fragments and FANet, the proposed efficient end-to-end FAST-VQA and FasterVQA achieve significantly better performance than existing approaches on all VQA benchmarks while requiring only 1/1612 FLOPs compared to the current state-of-the-art. Codes, models and demos are available at https://github.com/timothyhtimothy/FAST-VQA-and-FasterVQA.
From Face to Natural Image: Learning Real Degradation for Blind Image Super-Resolution
Oct 03, 2022
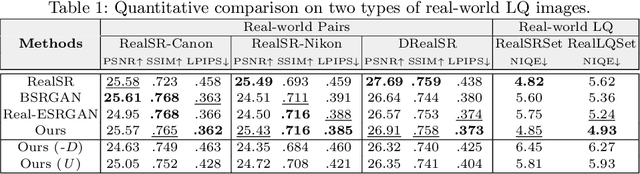
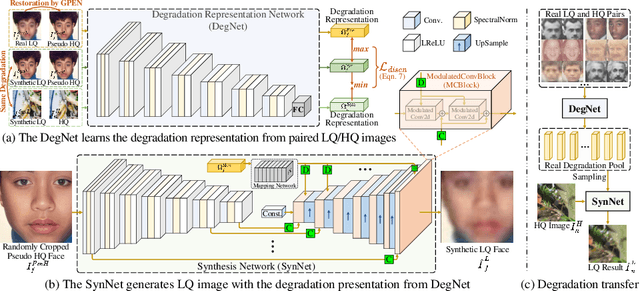

Designing proper training pairs is critical for super-resolving the real-world low-quality (LQ) images, yet suffers from the difficulties in either acquiring paired ground-truth HQ images or synthesizing photo-realistic degraded observations. Recent works mainly circumvent this by simulating the degradation with handcrafted or estimated degradation parameters. However, existing synthetic degradation models are incapable to model complicated real degradation types, resulting in limited improvement on these scenarios, \eg, old photos. Notably, face images, which have the same degradation process with the natural images, can be robustly restored with photo-realistic textures by exploiting their specific structure priors. In this work, we use these real-world LQ face images and their restored HQ counterparts to model the complex real degradation (namely ReDegNet), and then transfer it to HQ natural images to synthesize their realistic LQ ones. Specifically, we take these paired HQ and LQ face images as inputs to explicitly predict the degradation-aware and content-independent representations, which control the degraded image generation. Subsequently, we transfer these real degradation representations from face to natural images to synthesize the degraded LQ natural images. Experiments show that our ReDegNet can well learn the real degradation process from face images, and the restoration network trained with our synthetic pairs performs favorably against SOTAs. More importantly, our method provides a new manner to handle the unsynthesizable real-world scenarios by learning their degradation representations through face images within them, which can be used for specifically fine-tuning. The source code is available at https://github.com/csxmli2016/ReDegNet.
PS-NeRF: Neural Inverse Rendering for Multi-view Photometric Stereo
Jul 23, 2022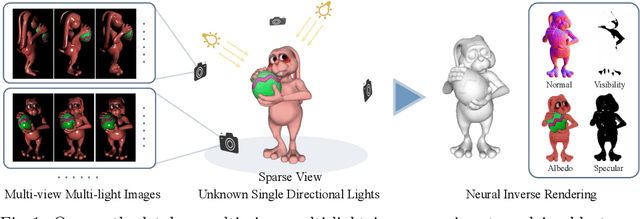
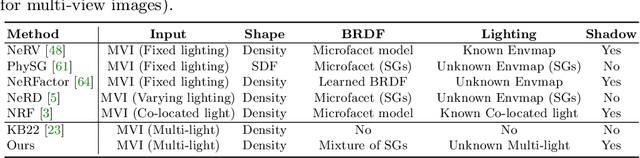
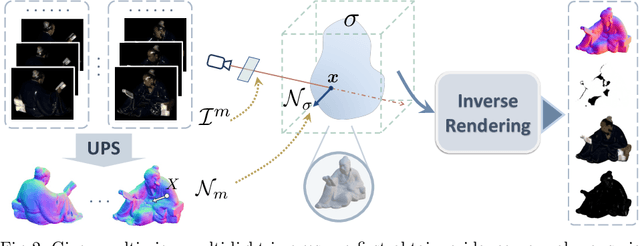

Traditional multi-view photometric stereo (MVPS) methods are often composed of multiple disjoint stages, resulting in noticeable accumulated errors. In this paper, we present a neural inverse rendering method for MVPS based on implicit representation. Given multi-view images of a non-Lambertian object illuminated by multiple unknown directional lights, our method jointly estimates the geometry, materials, and lights. Our method first employs multi-light images to estimate per-view surface normal maps, which are used to regularize the normals derived from the neural radiance field. It then jointly optimizes the surface normals, spatially-varying BRDFs, and lights based on a shadow-aware differentiable rendering layer. After optimization, the reconstructed object can be used for novel-view rendering, relighting, and material editing. Experiments on both synthetic and real datasets demonstrate that our method achieves far more accurate shape reconstruction than existing MVPS and neural rendering methods. Our code and model can be found at https://ywq.github.io/psnerf.