 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCIR: A Self-Correcting Iterative Refinement Framework for Enhanced Information Extraction Based on Schema
Dec 13, 2025Although Large language Model (LLM)-powered information extraction (IE) systems have shown impressive capabilities, current fine-tuning paradigms face two major limitations: high training costs and difficulties in aligning with LLM preferences. To address these issues, we propose a novel universal IE paradigm, the Self-Correcting Iterative Refinement (SCIR) framework, along with a Multi-task Bilingual (Chinese-English) Self-Correcting (MBSC) dataset containing over 100,000 entries. The SCIR framework achieves plug-and-play compatibility with existing LLMs and IE systems through its Dual-Path Self-Correcting module and feedback-driven optimization, thereby significantly reducing training costs. Concurrently, the MBSC dataset tackles the challenge of preference alignment by indirectly distilling GPT-4's capabilities into IE result detection models. Experimental results demonstrate that SCIR outperforms state-of-the-art IE methods across three key tasks: named entity recognition, relation extraction, and event extraction, achieving a 5.27 percent average improvement in span-based Micro-F1 while reducing training costs by 87 percent compared to baseline approaches. These advancements not only enhance the flexibility and accuracy of IE systems but also pave the way for lightweight and efficient IE paradigms.
S$^3$-NeRF: Neural Reflectance Field from Shading and Shadow under a Single Viewpoint
Oct 17, 2022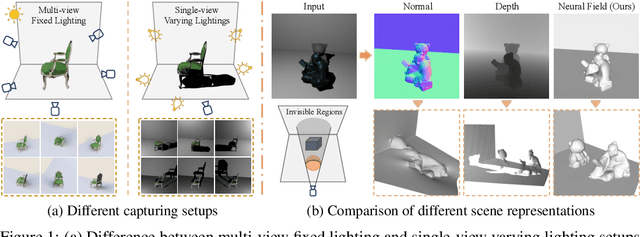
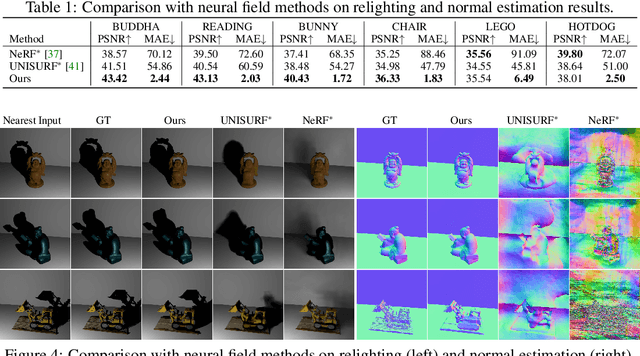
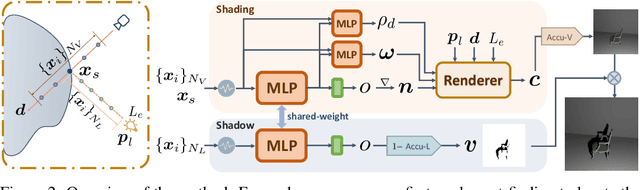
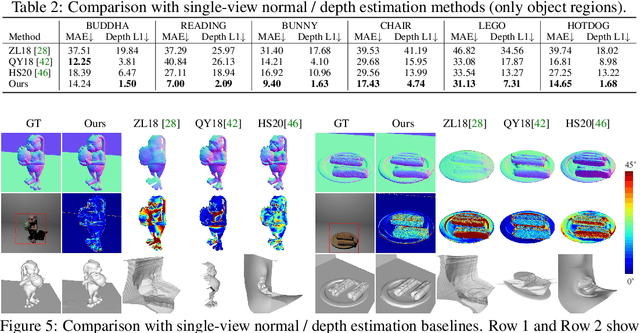
In this paper, we address the "dual problem" of multi-view scene reconstruction in which we utilize single-view images captured under different point lights to learn a neural scene representation. Different from existing single-view methods which can only recover a 2.5D scene representation (i.e., a normal / depth map for the visible surface), our method learns a neural reflectance field to represent the 3D geometry and BRDFs of a scene. Instead of relying on multi-view photo-consistency, our method exploits two information-rich monocular cues, namely shading and shadow, to infer scene geometry. Experiments on multiple challenging datasets show that our method is capable of recovering 3D geometry, including both visible and invisible parts, of a scene from single-view images. Thanks to the neural reflectance field representation, our method is robust to depth discontinuities. It supports applications like novel-view synthesis and relighting. Our code and model can be found at https://ywq.github.io/s3nerf.
PS-NeRF: Neural Inverse Rendering for Multi-view Photometric Stereo
Jul 23, 2022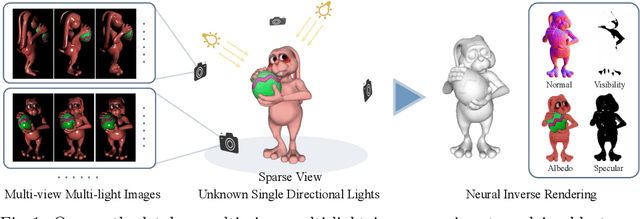
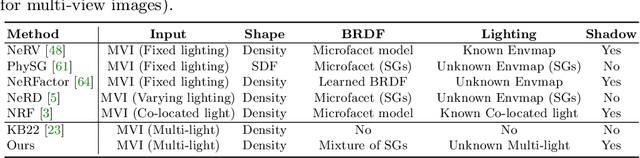
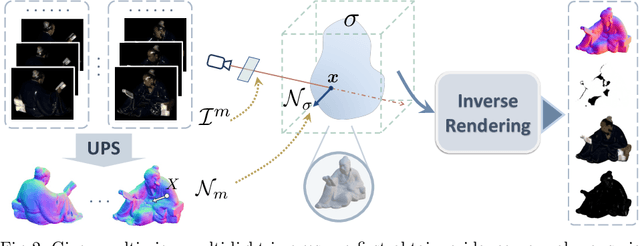

Traditional multi-view photometric stereo (MVPS) methods are often composed of multiple disjoint stages, resulting in noticeable accumulated errors. In this paper, we present a neural inverse rendering method for MVPS based on implicit representation. Given multi-view images of a non-Lambertian object illuminated by multiple unknown directional lights, our method jointly estimates the geometry, materials, and lights. Our method first employs multi-light images to estimate per-view surface normal maps, which are used to regularize the normals derived from the neural radiance field. It then jointly optimizes the surface normals, spatially-varying BRDFs, and lights based on a shadow-aware differentiable rendering layer. After optimization, the reconstructed object can be used for novel-view rendering, relighting, and material editing. Experiments on both synthetic and real datasets demonstrate that our method achieves far more accurate shape reconstruction than existing MVPS and neural rendering methods. Our code and model can be found at https://ywq.github.io/psnerf.
JIFF: Jointly-aligned Implicit Face Function for High Quality Single View Clothed Human Reconstruction
Apr 22, 2022


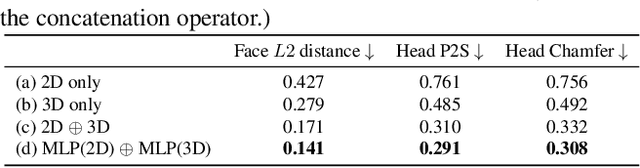
This paper addresses the problem of single view 3D human reconstruction. Recent implicit function based methods have shown impressive results, but they fail to recover fine face details in their reconstructions. This largely degrades user experience in applications like 3D telepresence. In this paper, we focus on improving the quality of face in the reconstruction and propose a novel Jointly-aligned Implicit Face Function (JIFF) that combines the merits of the implicit function based approach and model based approach. We employ a 3D morphable face model as our shape prior and compute space-aligned 3D features that capture detailed face geometry information. Such space-aligned 3D features are combined with pixel-aligned 2D features to jointly predict an implicit face function for high quality face reconstruction. We further extend our pipeline and introduce a coarse-to-fine architecture to predict high quality texture for our detailed face model. Extensive evaluations have been carried out on public datasets and our proposed JIFF has demonstrates superior performance (both quantitatively and qualitatively) over existing state-of-the-arts.
Deep Face Video Inpainting via UV Mapping
Sep 02, 2021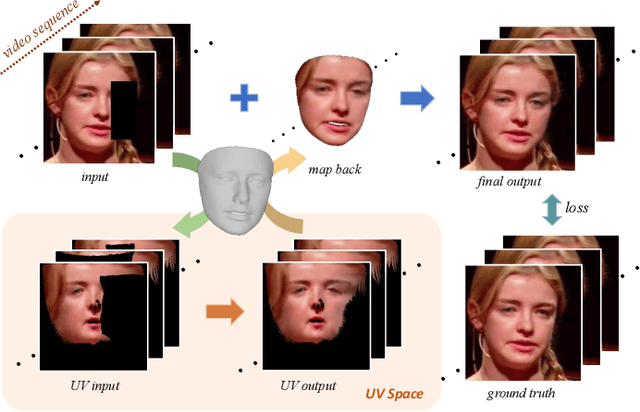
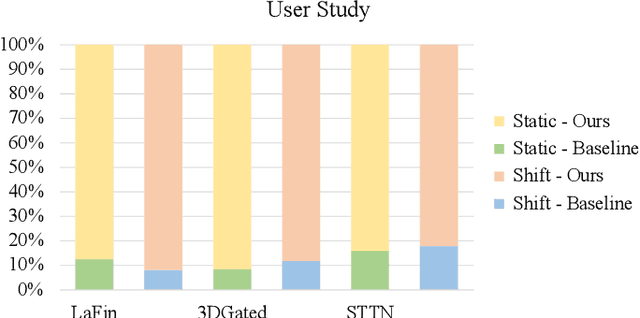


This paper addresses the problem of face video inpainting. Existing video inpainting methods target primarily at natural scenes with repetitive patterns. They do not make use of any prior knowledge of the face to help retrieve correspondences for the corrupted face. They therefore only achieve sub-optimal results, particularly for faces under large pose and expression variations where face components appear very differently across frames. In this paper, we propose a two-stage deep learning method for face video inpainting. We employ 3DMM as our 3D face prior to transform a face between the image space and the UV (texture) space. In Stage I, we perform face inpainting in the UV space. This helps to largely remove the influence of face poses and expressions and makes the learning task much easier with well aligned face features. We introduce a frame-wise attention module to fully exploit correspondences in neighboring frames to assist the inpainting task. In Stage II, we transform the inpainted face regions back to the image space and perform face video refinement that inpaints any background regions not covered in Stage I and also refines the inpainted face regions. Extensive experiments have been carried out which show our method can significantly outperform methods based merely on 2D information, especially for faces under large pose and expression variations.