 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscretized Bottleneck in VAE: Posterior-Collapse-Free Sequence-to-Sequence Learning
Apr 22, 2020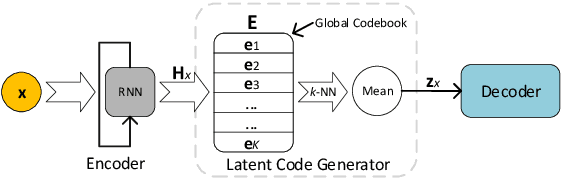
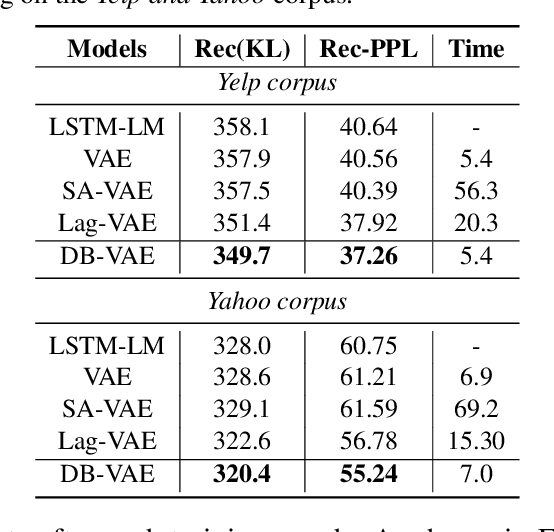
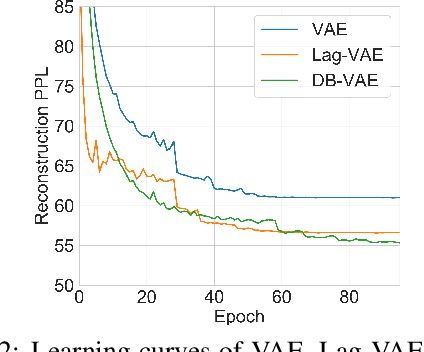

Variational autoencoders (VAEs) are important tools in end-to-end representation learning. VAEs can capture complex data distributions and have been applied extensively in many natural-language-processing (NLP) tasks. However, a common pitfall in sequence-to-sequence learning with VAEs is the posterior-collapse issue in latent space, wherein the model tends to ignore latent variables when a strong auto-regressive decoder is implemented. In this paper, we propose a principled approach to eliminate this issue by applying a discretized bottleneck in the latent space. Specifically, we impose a shared discrete latent space where each input is learned to choose a combination of shared latent atoms as its latent representation. Compared with VAEs employing continuous latent variables, our model endows more promising capability in modeling underlying semantics of discrete sequences and can thus provide more interpretative latent structures. Empirically, we demonstrate the efficiency and effectiveness of our model on a broad range of tasks, including language modeling, unaligned text style transfer, dialog response generation, and neural machine translation.
Decomposed Adversarial Learned Inference
Apr 21, 2020

Effective inference for a generative adversarial model remains an important and challenging problem. We propose a novel approach, Decomposed Adversarial Learned Inference (DALI), which explicitly matches prior and conditional distributions in both data and code spaces, and puts a direct constraint on the dependency structure of the generative model. We derive an equivalent form of the prior and conditional matching objective that can be optimized efficiently without any parametric assumption on the data. We validate the effectiveness of DALI on the MNIST, CIFAR-10, and CelebA datasets by conducting quantitative and qualitative evaluations. Results demonstrate that DALI significantly improves both reconstruction and generation as compared to other adversarial inference models.
Feature Quantization Improves GAN Training
Apr 05, 2020
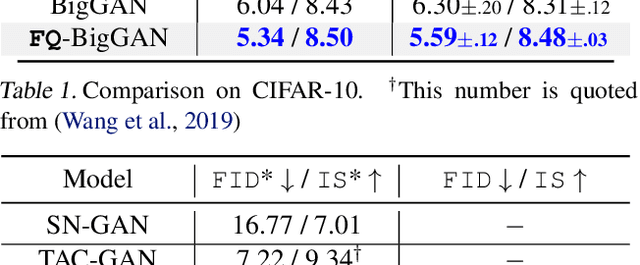
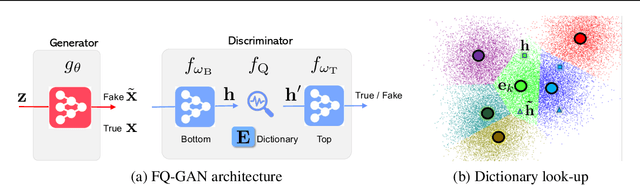
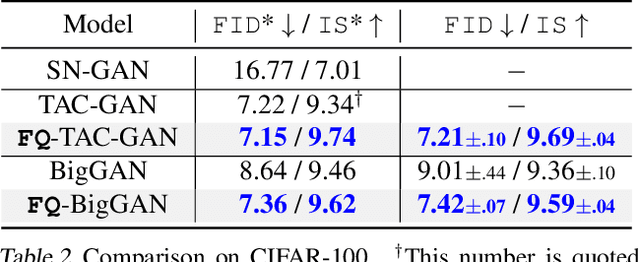
The instability in GAN training has been a long-standing problem despite remarkable research efforts. We identify that instability issues stem from difficulties of performing feature matching with mini-batch statistics, due to a fragile balance between the fixed target distribution and the progressively generated distribution. In this work, we propose Feature Quantization (FQ) for the discriminator, to embed both true and fake data samples into a shared discrete space. The quantized values of FQ are constructed as an evolving dictionary, which is consistent with feature statistics of the recent distribution history. Hence, FQ implicitly enables robust feature matching in a compact space. Our method can be easily plugged into existing GAN models, with little computational overhead in training. We apply FQ to 3 representative GAN models on 9 benchmarks: BigGAN for image generation, StyleGAN for face synthesis, and U-GAT-IT for unsupervised image-to-image translation. Extensive experimental results show that the proposed FQ-GAN can improve the FID scores of baseline methods by a large margin on a variety of tasks, achieving new state-of-the-art performance.
Nested-Wasserstein Self-Imitation Learning for Sequence Generation
Jan 20, 2020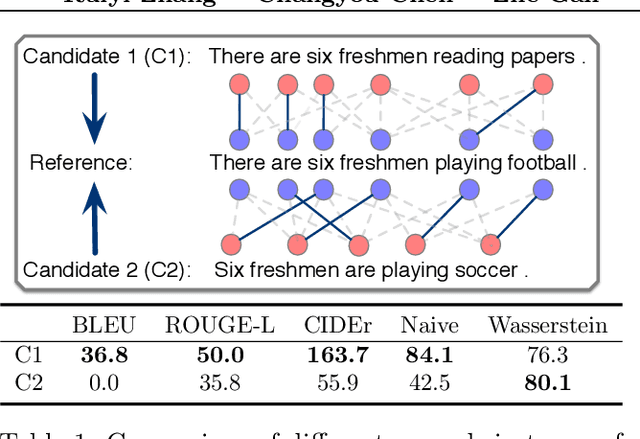
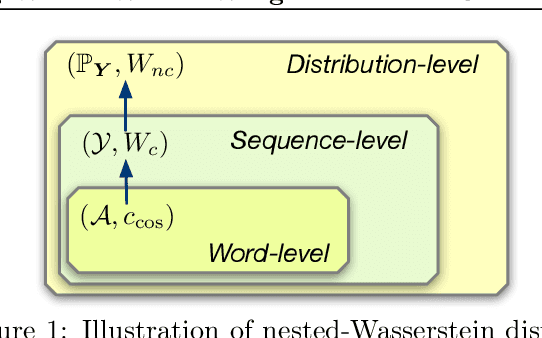
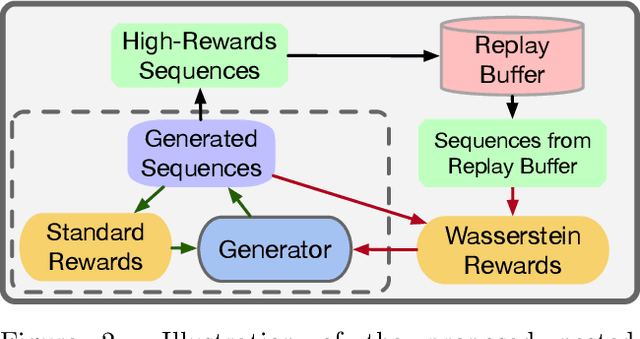
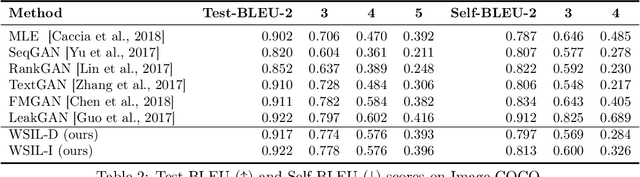
Reinforcement learning (RL) has been widely studied for improving sequence-generation models. However, the conventional rewards used for RL training typically cannot capture sufficient semantic information and therefore render model bias. Further, the sparse and delayed rewards make RL exploration inefficient. To alleviate these issues, we propose the concept of nested-Wasserstein distance for distributional semantic matching. To further exploit it, a novel nested-Wasserstein self-imitation learning framework is developed, encouraging the model to exploit historical high-rewarded sequences for enhanced exploration and better semantic matching. Our solution can be understood as approximately executing proximal policy optimization with Wasserstein trust-regions. Experiments on a variety of unconditional and conditional sequence-generation tasks demonstrate the proposed approach consistently leads to improved performance.
Learning Diverse Stochastic Human-Action Generators by Learning Smooth Latent Transitions
Dec 21, 2019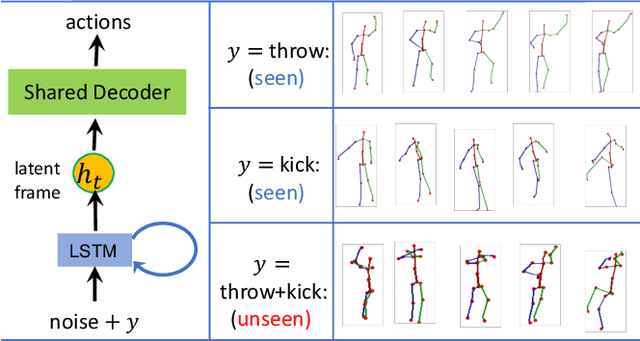

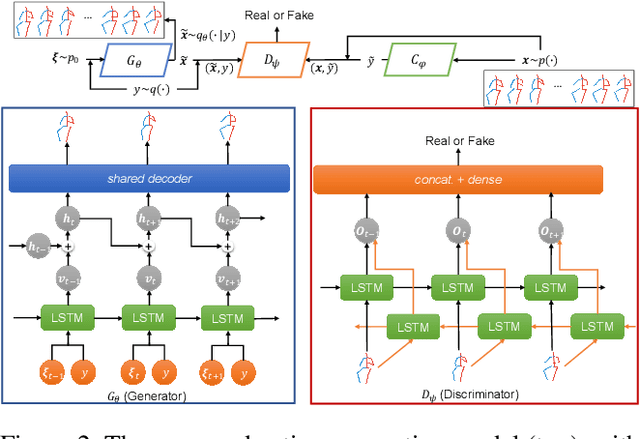

Human-motion generation is a long-standing challenging task due to the requirement of accurately modeling complex and diverse dynamic patterns. Most existing methods adopt sequence models such as RNN to directly model transitions in the original action space. Due to high dimensionality and potential noise, such modeling of action transitions is particularly challenging. In this paper, we focus on skeleton-based action generation and propose to model smooth and diverse transitions on a latent space of action sequences with much lower dimensionality. Conditioned on a latent sequence, actions are generated by a frame-wise decoder shared by all latent action-poses. Specifically, an implicit RNN is defined to model smooth latent sequences, whose randomness (diversity) is controlled by noise from the input. Different from standard action-prediction methods, our model can generate action sequences from pure noise without any conditional action poses. Remarkably, it can also generate unseen actions from mixed classes during training. Our model is learned with a bi-directional generative-adversarial-net framework, which not only can generate diverse action sequences of a particular class or mix classes, but also learns to classify action sequences within the same model. Experimental results show the superiority of our method in both diverse action-sequence generation and classification, relative to existing methods.
KernelNet: A Data-Dependent Kernel Parameterization for Deep Generative Modeling
Dec 02, 2019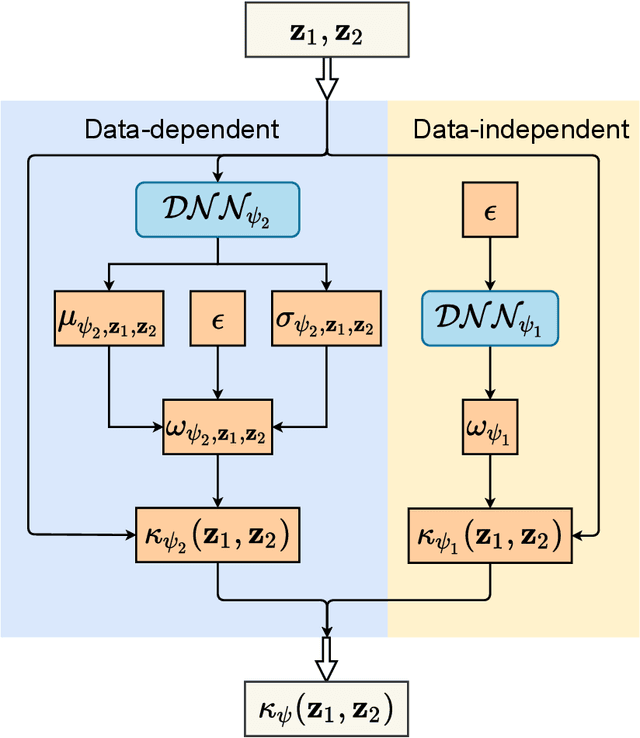


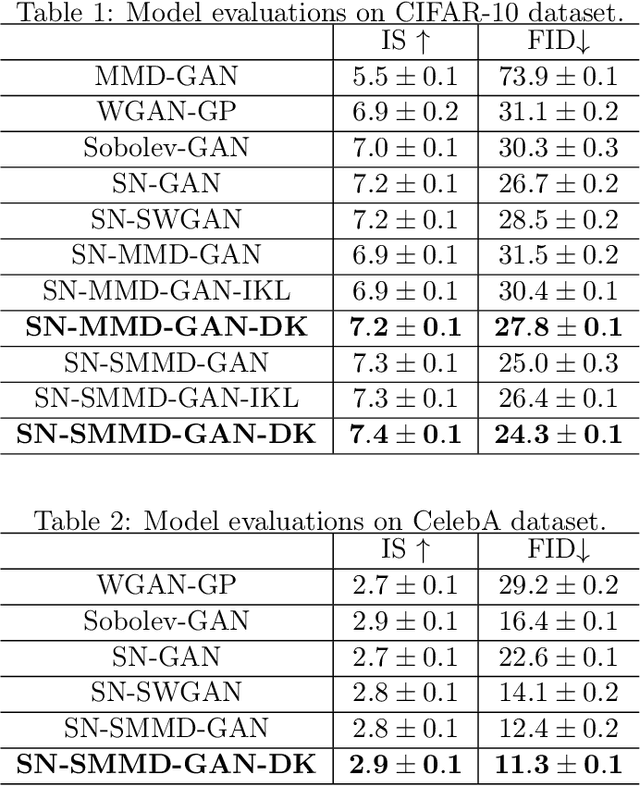
Learning with kernels is an often resorted tool in modern machine learning. Standard approaches for this type of learning use a predefined kernel that requires careful selection of hyperparameters. To mitigate this burden, we propose in this paper a framework to construct and learn a data-dependent kernel based on random features and implicit spectral distributions (Fourier transform of the kernel) parameterized by deep neural networks. We call the constructed network {\em KernelNet}, and apply it for deep generative modeling in various scenarios, including variants of the MMD-GAN and an implicit Variational Autoencoder (VAE), the two popular learning paradigms in deep generative models. Extensive experiments show the advantages of the proposed KernelNet, consistently achieving better performance compared to related methods.
Fine-grained Attention and Feature-sharing Generative Adversarial Networks for Single Image Super-Resolution
Nov 25, 2019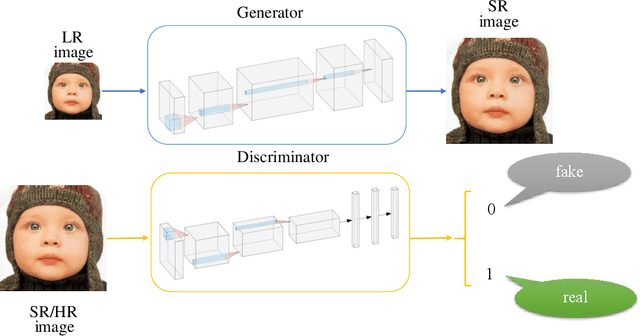
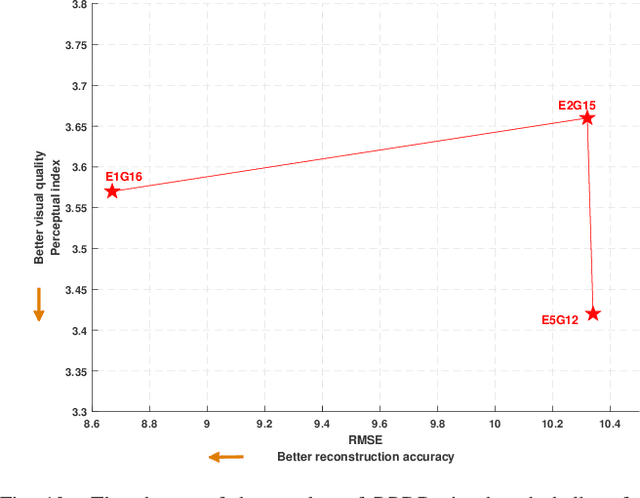
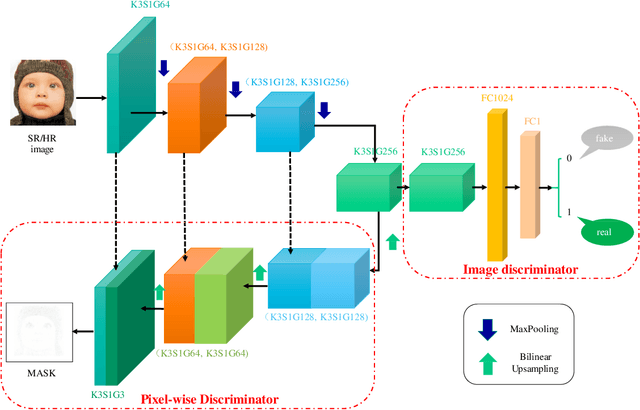
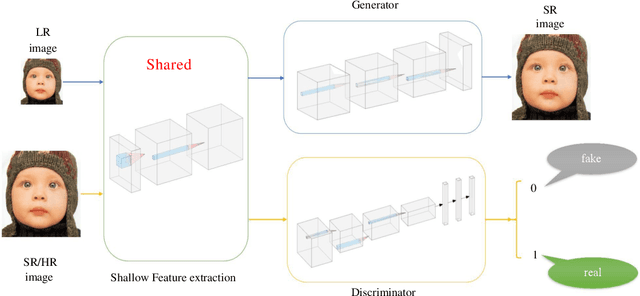
The traditional super-resolution methods that aim to minimize the mean square error usually produce the images with over-smoothed and blurry edges, due to the lose of high-frequency details. In this paper, we propose two novel techniques in the generative adversarial networks to produce photo-realistic images for image super-resolution. Firstly, instead of producing a single score to discriminate images between real and fake, we propose a variant, called Fine-grained Attention Generative Adversarial Network for image super-resolution (FASRGAN), to discriminate each pixel between real and fake. FASRGAN adopts a Unet-like network as the discriminator with two outputs: an image score and an image score map. The score map has the same spatial size as the HR/SR images, serving as the fine-grained attention to represent the degree of reconstruction difficulty for each pixel. Secondly, instead of using different networks for the generator and the discriminator in the SR problem, we use a feature-sharing network (Fs-SRGAN) for both the generator and the discriminator. By network sharing, certain information is shared between the generator and the discriminator, which in turn can improve the ability of producing high-quality images. Quantitative and visual comparisons with the state-of-the-art methods on the benchmark datasets demonstrate the superiority of our methods. The application of super-resolution images to object recognition further proves that the proposed methods endow the power to reconstruction capabilities and the excellent super-resolution effects.
Implicit Deep Latent Variable Models for Text Generation
Sep 18, 2019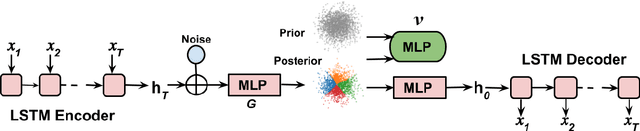
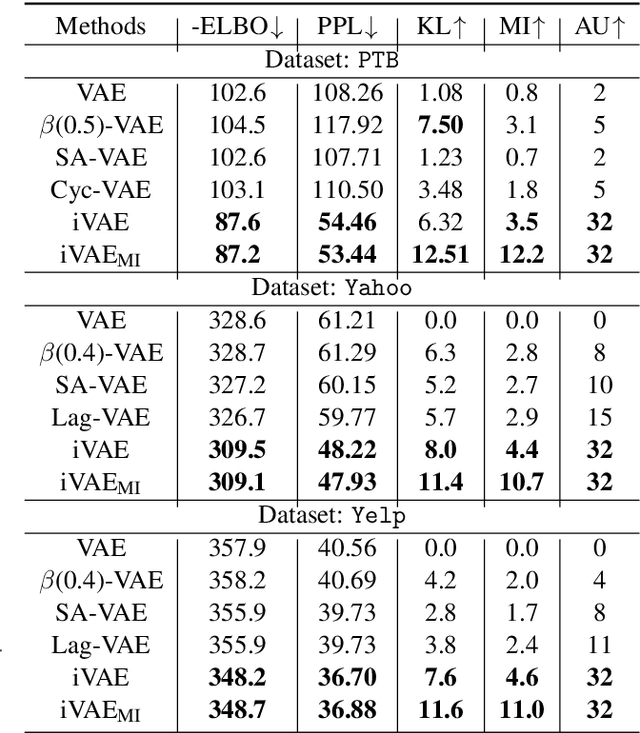
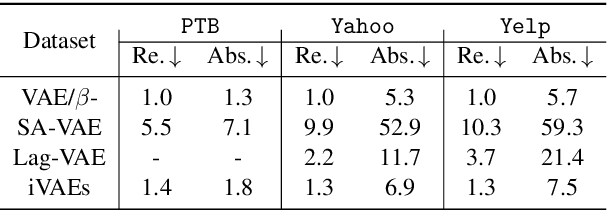
Deep latent variable models (LVM) such as variational auto-encoder (VAE) have recently played an important role in text generation. One key factor is the exploitation of smooth latent structures to guide the generation. However, the representation power of VAEs is limited due to two reasons: (1) the Gaussian assumption is often made on the variational posteriors; and meanwhile (2) a notorious "posterior collapse" issue occurs. In this paper, we advocate sample-based representations of variational distributions for natural language, leading to implicit latent features, which can provide flexible representation power compared with Gaussian-based posteriors. We further develop an LVM to directly match the aggregated posterior to the prior. It can be viewed as a natural extension of VAEs with a regularization of maximizing mutual information, mitigating the "posterior collapse" issue. We demonstrate the effectiveness and versatility of our models in various text generation scenarios, including language modeling, unaligned style transfer, and dialog response generation. The source code to reproduce our experimental results is available on GitHub.
Document Hashing with Mixture-Prior Generative Models
Aug 29, 2019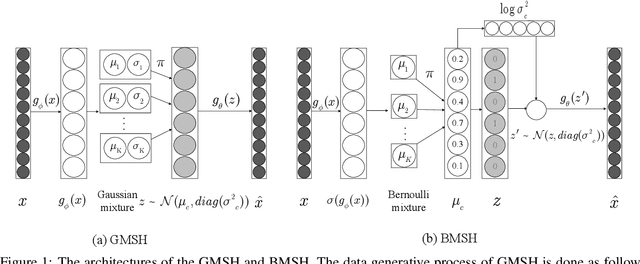
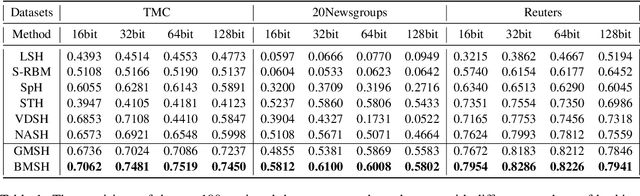
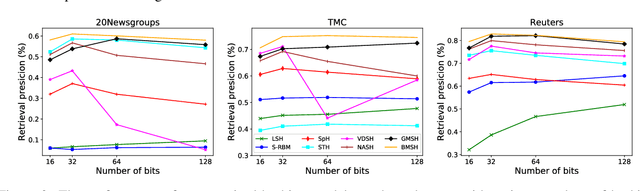
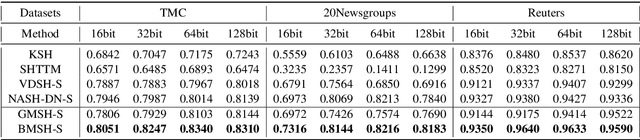
Hashing is promising for large-scale information retrieval tasks thanks to the efficiency of distance evaluation between binary codes. Generative hashing is often used to generate hashing codes in an unsupervised way. However, existing generative hashing methods only considered the use of simple priors, like Gaussian and Bernoulli priors, which limits these methods to further improve their performance. In this paper, two mixture-prior generative models are proposed, under the objective to produce high-quality hashing codes for documents. Specifically, a Gaussian mixture prior is first imposed onto the variational auto-encoder (VAE), followed by a separate step to cast the continuous latent representation of VAE into binary code. To avoid the performance loss caused by the separate casting, a model using a Bernoulli mixture prior is further developed, in which an end-to-end training is admitted by resorting to the straight-through (ST) discrete gradient estimator. Experimental results on several benchmark datasets demonstrate that the proposed methods, especially the one using Bernoulli mixture priors, consistently outperform existing ones by a substantial margin.
Bayesian Uncertainty Matching for Unsupervised Domain Adaptation
Jun 24, 2019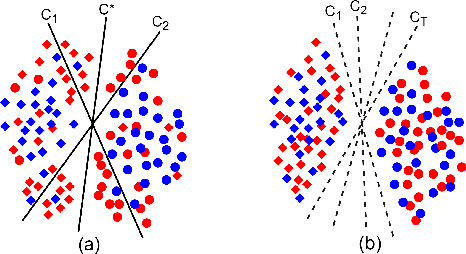
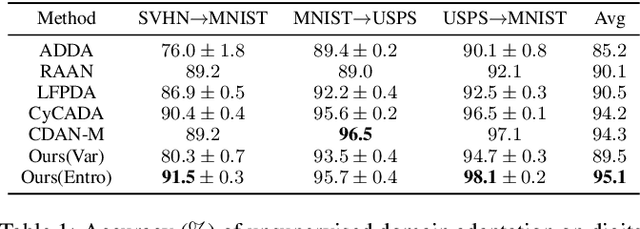
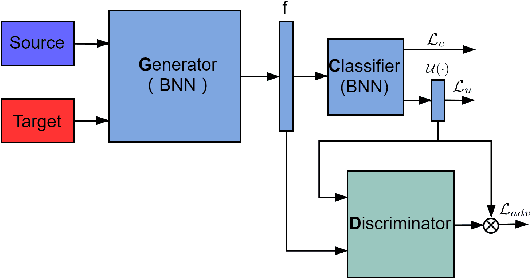
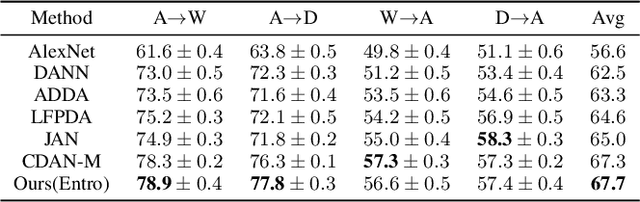
Domain adaptation is an important technique to alleviate performance degradation caused by domain shift, e.g., when training and test data come from different domains. Most existing deep adaptation methods focus on reducing domain shift by matching marginal feature distributions through deep transformations on the input features, due to the unavailability of target domain labels. We show that domain shift may still exist via label distribution shift at the classifier, thus deteriorating model performances. To alleviate this issue, we propose an approximate joint distribution matching scheme by exploiting prediction uncertainty. Specifically, we use a Bayesian neural network to quantify prediction uncertainty of a classifier. By imposing distribution matching on both features and labels (via uncertainty), label distribution mismatching in source and target data is effectively alleviated, encouraging the classifier to produce consistent predictions across domains. We also propose a few techniques to improve our method by adaptively reweighting domain adaptation loss to achieve nontrivial distribution matching and stable training. Comparisons with state of the art unsupervised domain adaptation methods on three popular benchmark datasets demonstrate the superiority of our approach, especially on the effectiveness of alleviating negative transfer.