 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraffic Flow Forecasting Using a Spatio-Temporal Bayesian Network Predictor
Dec 24, 2017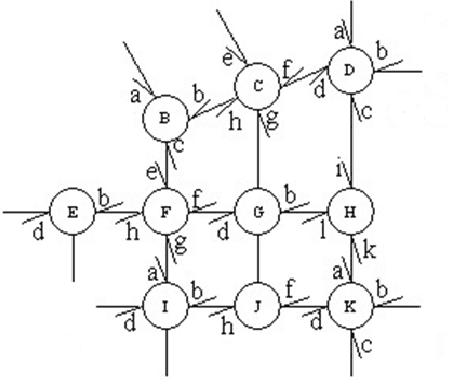
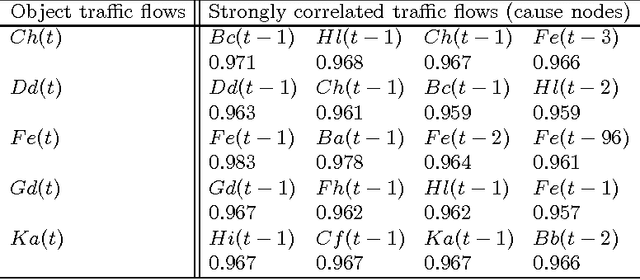

A novel predictor for traffic flow forecasting, namely spatio-temporal Bayesian network predictor, is proposed. Unlike existing methods, our approach incorporates all the spatial and temporal information available in a transportation network to carry our traffic flow forecasting of the current site. The Pearson correlation coefficient is adopted to rank the input variables (traffic flows) for prediction, and the best-first strategy is employed to select a subset as the cause nodes of a Bayesian network. Given the derived cause nodes and the corresponding effect node in the spatio-temporal Bayesian network, a Gaussian Mixture Model is applied to describe the statistical relationship between the input and output. Finally, traffic flow forecasting is performed under the criterion of Minimum Mean Square Error (M.M.S.E.). Experimental results with the urban vehicular flow data of Beijing demonstrate the effectiveness of our presented spatio-temporal Bayesian network predictor.
An In-field Automatic Wheat Disease Diagnosis System
Sep 26, 2017
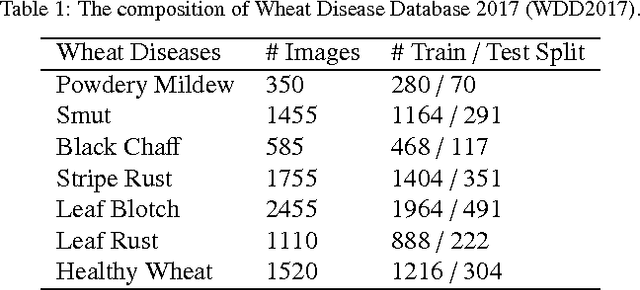
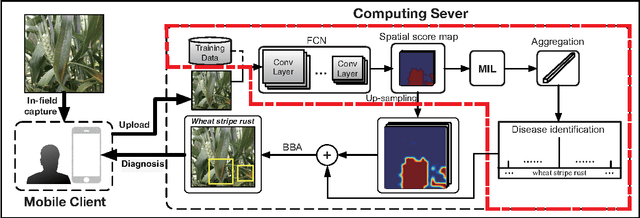
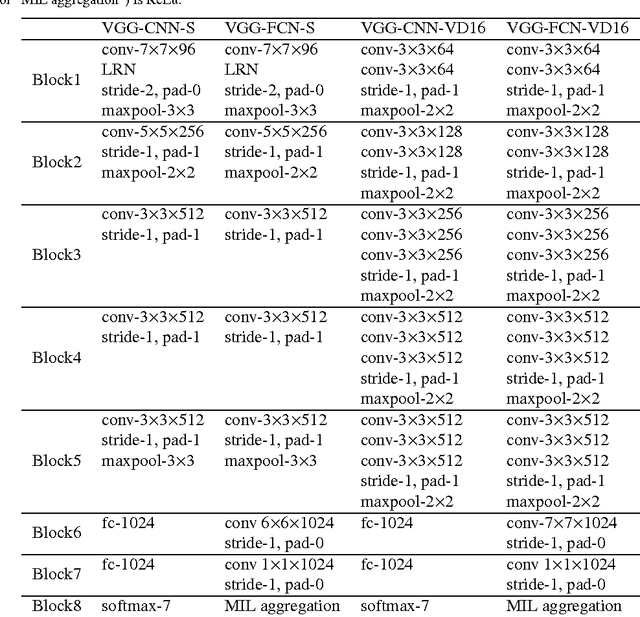
Crop diseases are responsible for the major production reduction and economic losses in agricultural industry world- wide. Monitoring for health status of crops is critical to control the spread of diseases and implement effective management. This paper presents an in-field automatic wheat disease diagnosis system based on a weakly super- vised deep learning framework, i.e. deep multiple instance learning, which achieves an integration of identification for wheat diseases and localization for disease areas with only image-level annotation for training images in wild conditions. Furthermore, a new in-field image dataset for wheat disease, Wheat Disease Database 2017 (WDD2017), is collected to verify the effectiveness of our system. Under two different architectures, i.e. VGG-FCN-VD16 and VGG-FCN-S, our system achieves the mean recognition accuracies of 97.95% and 95.12% respectively over 5-fold cross-validation on WDD2017, exceeding the results of 93.27% and 73.00% by two conventional CNN frameworks, i.e. VGG-CNN-VD16 and VGG-CNN-S. Experimental results demonstrate that the proposed system outperforms conventional CNN architectures on recognition accuracy under the same amount of parameters, meanwhile main- taining accurate localization for corresponding disease areas. Moreover, the proposed system has been packed into a real-time mobile app to provide support for agricultural disease diagnosis.
* 15 pages
Learning Efficient Convolutional Networks through Network Slimming
Aug 22, 2017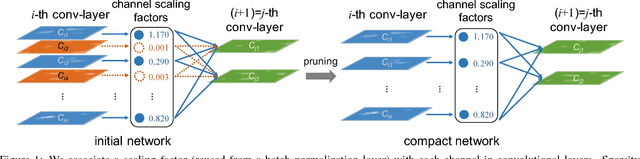
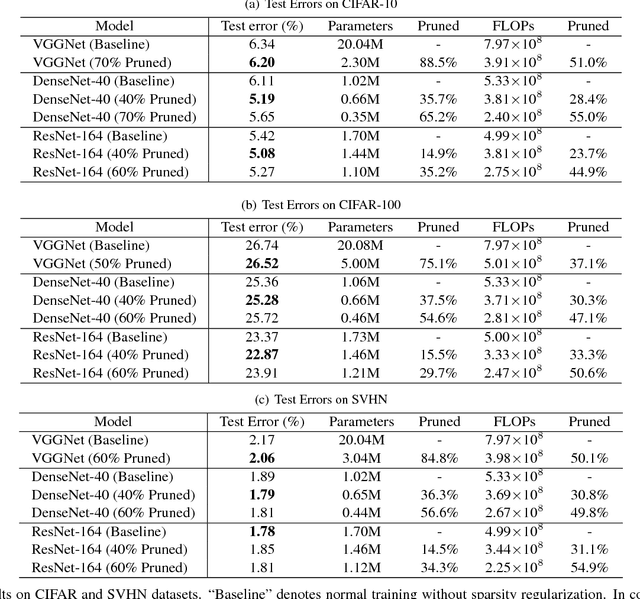
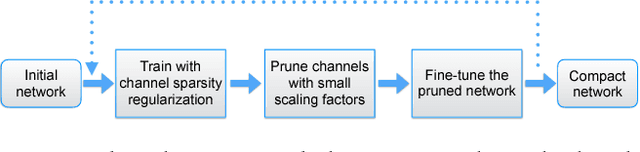
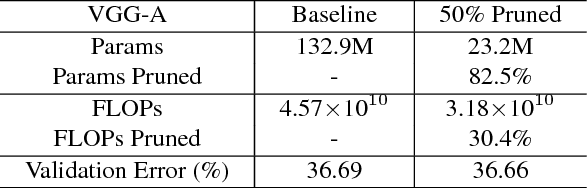
The deployment of deep convolutional neural networks (CNNs) in many real world applications is largely hindered by their high computational cost. In this paper, we propose a novel learning scheme for CNNs to simultaneously 1) reduce the model size; 2) decrease the run-time memory footprint; and 3) lower the number of computing operations, without compromising accuracy. This is achieved by enforcing channel-level sparsity in the network in a simple but effective way. Different from many existing approaches, the proposed method directly applies to modern CNN architectures, introduces minimum overhead to the training process, and requires no special software/hardware accelerators for the resulting models. We call our approach network slimming, which takes wide and large networks as input models, but during training insignificant channels are automatically identified and pruned afterwards, yielding thin and compact models with comparable accuracy. We empirically demonstrate the effectiveness of our approach with several state-of-the-art CNN models, including VGGNet, ResNet and DenseNet, on various image classification datasets. For VGGNet, a multi-pass version of network slimming gives a 20x reduction in model size and a 5x reduction in computing operations.
Zero-Shot Learning by Generating Pseudo Feature Representations
Mar 19, 2017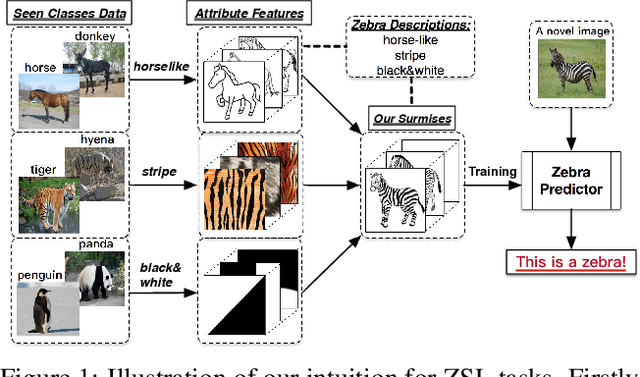
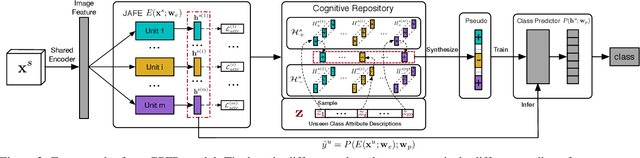
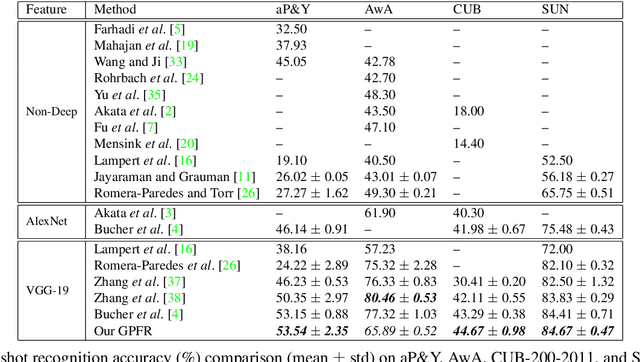
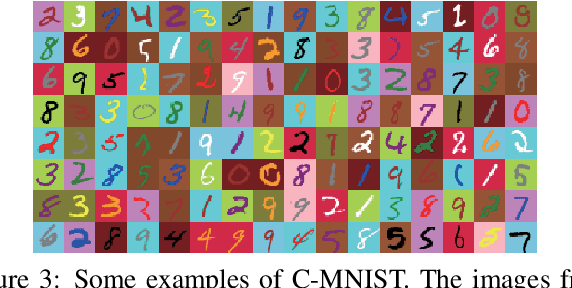
Zero-shot learning (ZSL) is a challenging task aiming at recognizing novel classes without any training instances. In this paper we present a simple but high-performance ZSL approach by generating pseudo feature representations (GPFR). Given the dataset of seen classes and side information of unseen classes (e.g. attributes), we synthesize feature-level pseudo representations for novel concepts, which allows us access to the formulation of unseen class predictor. Firstly we design a Joint Attribute Feature Extractor (JAFE) to acquire understandings about attributes, then construct a cognitive repository of attributes filtered by confidence margins, and finally generate pseudo feature representations using a probability based sampling strategy to facilitate subsequent training process of class predictor. We demonstrate the effectiveness in ZSL settings and the extensibility in supervised recognition scenario of our method on a synthetic colored MNIST dataset (C-MNIST). For several popular ZSL benchmark datasets, our approach also shows compelling results on zero-shot recognition task, especially leading to tremendous improvement to state-of-the-art mAP on zero-shot retrieval task.
* 9 pages
Weakly- and Semi-Supervised Object Detection with Expectation-Maximization Algorithm
Feb 28, 2017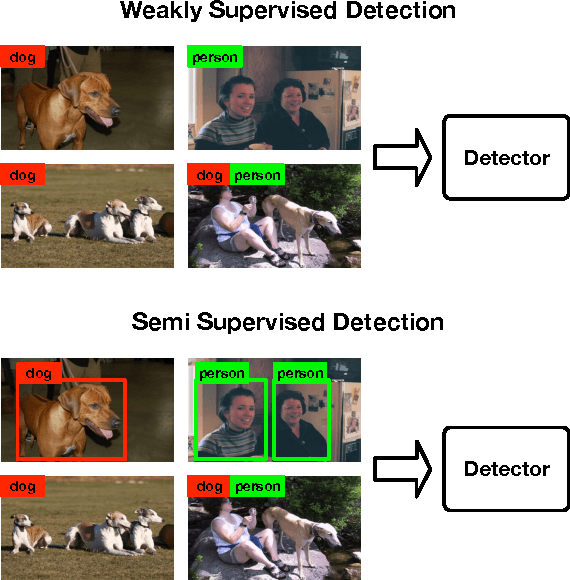
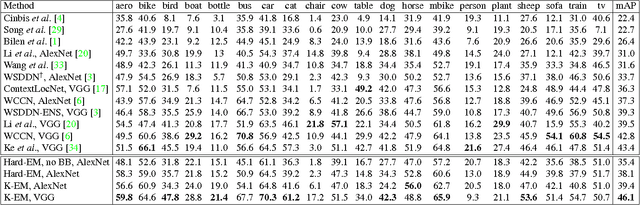
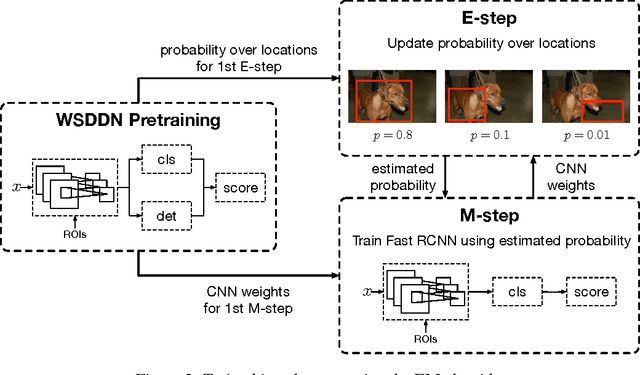
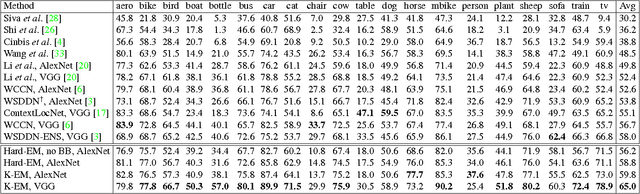
Object detection when provided image-level labels instead of instance-level labels (i.e., bounding boxes) during training is an important problem in computer vision, since large scale image datasets with instance-level labels are extremely costly to obtain. In this paper, we address this challenging problem by developing an Expectation-Maximization (EM) based object detection method using deep convolutional neural networks (CNNs). Our method is applicable to both the weakly-supervised and semi-supervised settings. Extensive experiments on PASCAL VOC 2007 benchmark show that (1) in the weakly supervised setting, our method provides significant detection performance improvement over current state-of-the-art methods, (2) having access to a small number of strongly (instance-level) annotated images, our method can almost match the performace of the fully supervised Fast RCNN. We share our source code at https://github.com/ZiangYan/EM-WSD.
A DNN Framework For Text Image Rectification From Planar Transformations
Nov 14, 2016
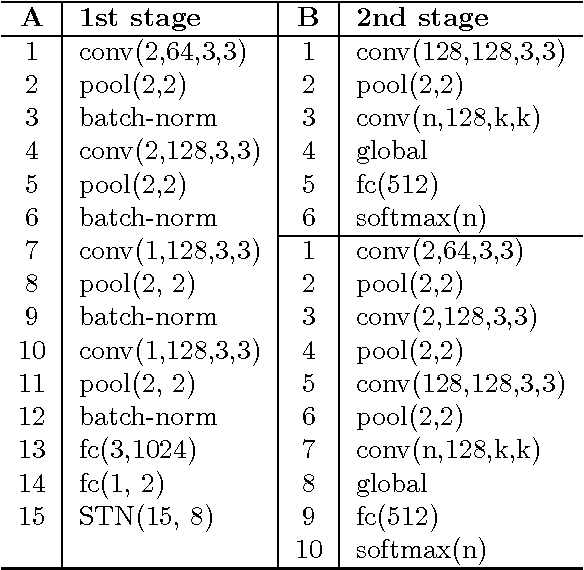
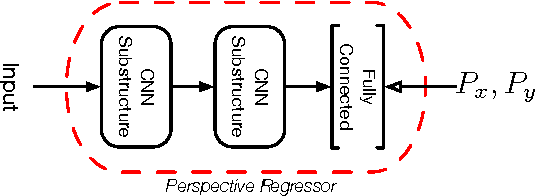
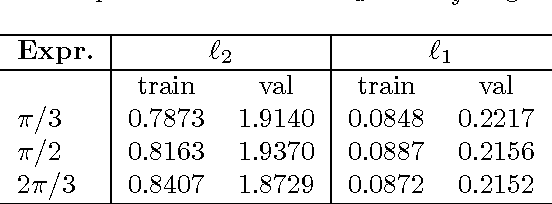
In this paper, a novel neural network architecture is proposed attempting to rectify text images with mild assumptions. A new dataset of text images is collected to verify our model and open to public. We explored the capability of deep neural network in learning geometric transformation and found the model could segment the text image without explicit supervised segmentation information. Experiments show the architecture proposed can restore planar transformations with wonderful robustness and effectiveness.
Audio Classical Composer Identification by Deep Neural Network
Mar 16, 2016Audio Classical Composer Identification (ACC) is an important problem in Music Information Retrieval (MIR) which aims at identifying the composer for audio classical music clips. The famous annual competition, Music Information Retrieval Evaluation eXchange (MIREX), also takes it as one of the four training&testing tasks. We built a hybrid model based on Deep Belief Network (DBN) and Stacked Denoising Autoencoder (SDA) to identify the composer from audio signal. As a matter of copyright, sponsors of MIREX cannot publish their data set. We built a comparable data set to test our model. We got an accuracy of 76.26% in our data set which is better than some pure models and shallow models. We think our method is promising even though we test it in a different data set, since our data set is comparable to that in MIREX by size. We also found that samples from different classes become farther away from each other when transformed by more layers in our model.
Aligning where to see and what to tell: image caption with region-based attention and scene factorization
Jun 20, 2015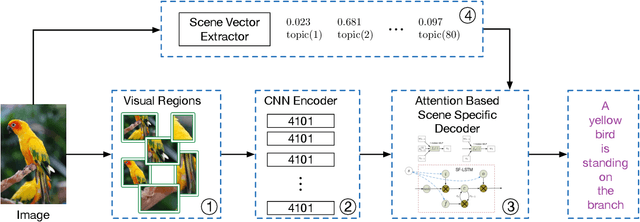
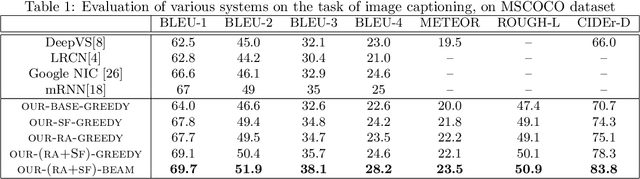
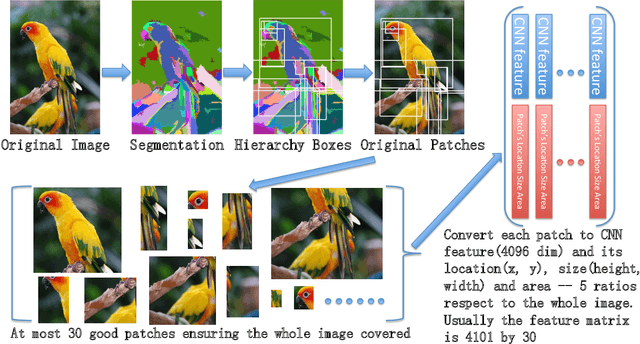
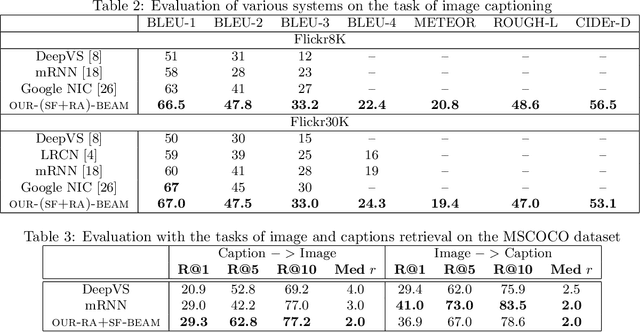
Recent progress on automatic generation of image captions has shown that it is possible to describe the most salient information conveyed by images with accurate and meaningful sentences. In this paper, we propose an image caption system that exploits the parallel structures between images and sentences. In our model, the process of generating the next word, given the previously generated ones, is aligned with the visual perception experience where the attention shifting among the visual regions imposes a thread of visual ordering. This alignment characterizes the flow of "abstract meaning", encoding what is semantically shared by both the visual scene and the text description. Our system also makes another novel modeling contribution by introducing scene-specific contexts that capture higher-level semantic information encoded in an image. The contexts adapt language models for word generation to specific scene types. We benchmark our system and contrast to published results on several popular datasets. We show that using either region-based attention or scene-specific contexts improves systems without those components. Furthermore, combining these two modeling ingredients attains the state-of-the-art performance.
Relaxed Sparse Eigenvalue Conditions for Sparse Estimation via Non-convex Regularized Regression
Feb 12, 2014
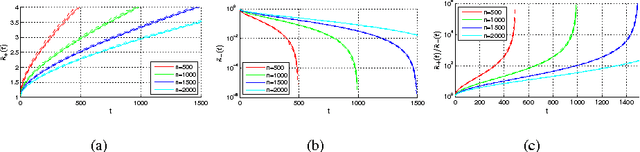
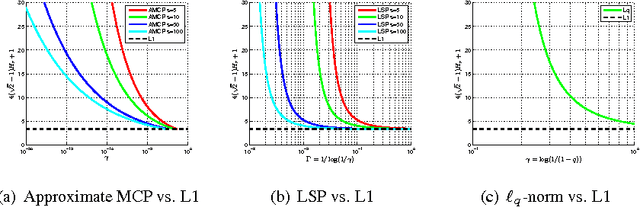
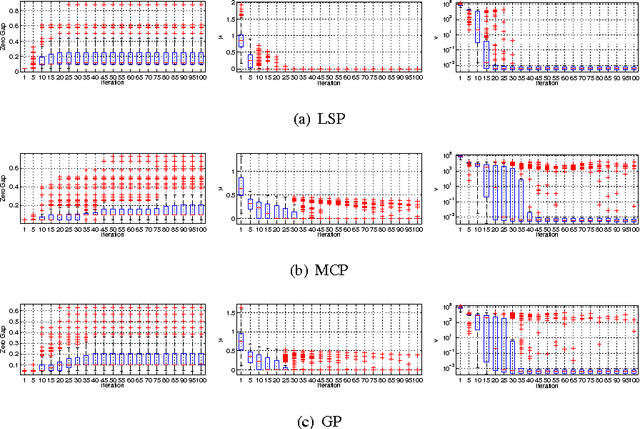
Non-convex regularizers usually improve the performance of sparse estimation in practice. To prove this fact, we study the conditions of sparse estimations for the sharp concave regularizers which are a general family of non-convex regularizers including many existing regularizers. For the global solutions of the regularized regression, our sparse eigenvalue based conditions are weaker than that of L1-regularization for parameter estimation and sparseness estimation. For the approximate global and approximate stationary (AGAS) solutions, almost the same conditions are also enough. We show that the desired AGAS solutions can be obtained by coordinate descent (CD) based methods. Finally, we perform some experiments to show the performance of CD methods on giving AGAS solutions and the degree of weakness of the estimation conditions required by the sharp concave regularizers.
A General Iterative Shrinkage and Thresholding Algorithm for Non-convex Regularized Optimization Problems
Mar 18, 2013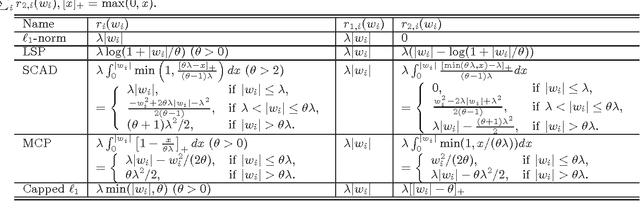
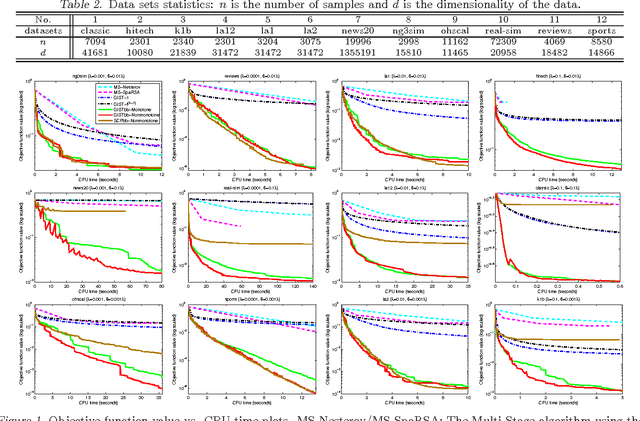
Non-convex sparsity-inducing penalties have recently received considerable attentions in sparse learning. Recent theoretical investigations have demonstrated their superiority over the convex counterparts in several sparse learning settings. However, solving the non-convex optimization problems associated with non-convex penalties remains a big challenge. A commonly used approach is the Multi-Stage (MS) convex relaxation (or DC programming), which relaxes the original non-convex problem to a sequence of convex problems. This approach is usually not very practical for large-scale problems because its computational cost is a multiple of solving a single convex problem. In this paper, we propose a General Iterative Shrinkage and Thresholding (GIST) algorithm to solve the nonconvex optimization problem for a large class of non-convex penalties. The GIST algorithm iteratively solves a proximal operator problem, which in turn has a closed-form solution for many commonly used penalties. At each outer iteration of the algorithm, we use a line search initialized by the Barzilai-Borwein (BB) rule that allows finding an appropriate step size quickly. The paper also presents a detailed convergence analysis of the GIST algorithm. The efficiency of the proposed algorithm is demonstrated by extensive experiments on large-scale data sets.