 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Closer Look at the Self-Verification Abilities of Large Language Models in Logical Reasoning
Nov 14, 2023Logical reasoning has been an ongoing pursuit in the field of AI. Despite significant advancements made by large language models (LLMs), they still struggle with complex logical reasoning problems. To enhance reasoning performance, one promising direction is scalable oversight, which requires LLMs to identify their own errors and then improve by themselves. Various self-verification methods have been proposed in pursuit of this goal. Nevertheless, whether existing models understand their own errors well is still under investigation. In this paper, we take a closer look at the self-verification abilities of LLMs in the context of logical reasoning, focusing on their ability to identify logical fallacies accurately. We introduce a dataset, FALLACIES, containing 232 types of reasoning fallacies categorized in a hierarchical taxonomy. By conducting exhaustive experiments on FALLACIES, we obtain comprehensive and detailed analyses of a series of models on their verification abilities. Our main findings suggest that existing LLMs could struggle to identify fallacious reasoning steps accurately and may fall short of guaranteeing the validity of self-verification methods. Drawing from these observations, we offer suggestions for future research and practical applications of self-verification methods.
From Text to Mask: Localizing Entities Using the Attention of Text-to-Image Diffusion Models
Sep 08, 2023Diffusion models have revolted the field of text-to-image generation recently. The unique way of fusing text and image information contributes to their remarkable capability of generating highly text-related images. From another perspective, these generative models imply clues about the precise correlation between words and pixels. In this work, a simple but effective method is proposed to utilize the attention mechanism in the denoising network of text-to-image diffusion models. Without re-training nor inference-time optimization, the semantic grounding of phrases can be attained directly. We evaluate our method on Pascal VOC 2012 and Microsoft COCO 2014 under weakly-supervised semantic segmentation setting and our method achieves superior performance to prior methods. In addition, the acquired word-pixel correlation is found to be generalizable for the learned text embedding of customized generation methods, requiring only a few modifications. To validate our discovery, we introduce a new practical task called "personalized referring image segmentation" with a new dataset. Experiments in various situations demonstrate the advantages of our method compared to strong baselines on this task. In summary, our work reveals a novel way to extract the rich multi-modal knowledge hidden in diffusion models for segmentation.
Bipartite Ranking Fairness through a Model Agnostic Ordering Adjustment
Jul 27, 2023



Algorithmic fairness has been a serious concern and received lots of interest in machine learning community. In this paper, we focus on the bipartite ranking scenario, where the instances come from either the positive or negative class and the goal is to learn a ranking function that ranks positive instances higher than negative ones. While there could be a trade-off between fairness and performance, we propose a model agnostic post-processing framework xOrder for achieving fairness in bipartite ranking and maintaining the algorithm classification performance. In particular, we optimize a weighted sum of the utility as identifying an optimal warping path across different protected groups and solve it through a dynamic programming process. xOrder is compatible with various classification models and ranking fairness metrics, including supervised and unsupervised fairness metrics. In addition to binary groups, xOrder can be applied to multiple protected groups. We evaluate our proposed algorithm on four benchmark data sets and two real-world patient electronic health record repositories. xOrder consistently achieves a better balance between the algorithm utility and ranking fairness on a variety of datasets with different metrics. From the visualization of the calibrated ranking scores, xOrder mitigates the score distribution shifts of different groups compared with baselines. Moreover, additional analytical results verify that xOrder achieves a robust performance when faced with fewer samples and a bigger difference between training and testing ranking score distributions.
Faithful Question Answering with Monte-Carlo Planning
May 04, 2023



Although large language models demonstrate remarkable question-answering performances, revealing the intermediate reasoning steps that the models faithfully follow remains challenging. In this paper, we propose FAME (FAithful question answering with MontE-carlo planning) to answer questions based on faithful reasoning steps. The reasoning steps are organized as a structured entailment tree, which shows how premises are used to produce intermediate conclusions that can prove the correctness of the answer. We formulate the task as a discrete decision-making problem and solve it through the interaction of a reasoning environment and a controller. The environment is modular and contains several basic task-oriented modules, while the controller proposes actions to assemble the modules. Since the search space could be large, we introduce a Monte-Carlo planning algorithm to do a look-ahead search and select actions that will eventually lead to high-quality steps. FAME achieves state-of-the-art performance on the standard benchmark. It can produce valid and faithful reasoning steps compared with large language models with a much smaller model size.
Automatically Predict Material Properties with Microscopic Image Example Polymer Compatibility
Mar 22, 2023Many material properties are manifested in the morphological appearance and characterized with microscopic image, such as scanning electron microscopy (SEM). Polymer compatibility is a key physical quantity of polymer material and commonly and intuitively judged by SEM images. However, human observation and judgement for the images is time-consuming, labor-intensive and hard to be quantified. Computer image recognition with machine learning method can make up the defects of artificial judging, giving accurate and quantitative judgement. We achieve automatic compatibility recognition utilizing convolution neural network and transfer learning method, and the model obtains up to 94% accuracy. We also put forward a quantitative criterion for polymer compatibility with this model. The proposed method can be widely applied to the quantitative characterization of the microstructure and properties of various materials.
MetaLogic: Logical Reasoning Explanations with Fine-Grained Structure
Oct 22, 2022In this paper, we propose a comprehensive benchmark to investigate models' logical reasoning capabilities in complex real-life scenarios. Current explanation datasets often employ synthetic data with simple reasoning structures. Therefore, it cannot express more complex reasoning processes, such as the rebuttal to a reasoning step and the degree of certainty of the evidence. To this end, we propose a comprehensive logical reasoning explanation form. Based on the multi-hop chain of reasoning, the explanation form includes three main components: (1) The condition of rebuttal that the reasoning node can be challenged; (2) Logical formulae that uncover the internal texture of reasoning nodes; (3) Reasoning strength indicated by degrees of certainty. The fine-grained structure conforms to the real logical reasoning scenario, better fitting the human cognitive process but, simultaneously, is more challenging for the current models. We evaluate the current best models' performance on this new explanation form. The experimental results show that generating reasoning graphs remains a challenging task for current models, even with the help of giant pre-trained language models.
* To appear at the main conference of EMNLP 2022
Rethinking Audio-visual Synchronization for Active Speaker Detection
Jun 21, 2022
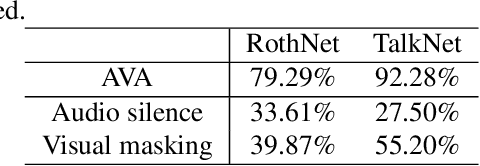

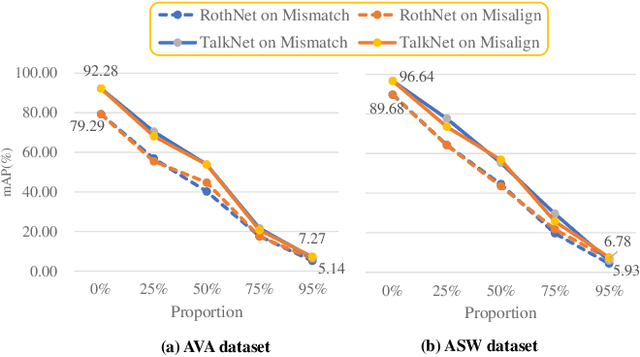
Active speaker detection (ASD) systems are important modules for analyzing multi-talker conversations. They aim to detect which speakers or none are talking in a visual scene at any given time. Existing research on ASD does not agree on the definition of active speakers. We clarify the definition in this work and require synchronization between the audio and visual speaking activities. This clarification of definition is motivated by our extensive experiments, through which we discover that existing ASD methods fail in modeling the audio-visual synchronization and often classify unsynchronized videos as active speaking. To address this problem, we propose a cross-modal contrastive learning strategy and apply positional encoding in attention modules for supervised ASD models to leverage the synchronization cue. Experimental results suggest that our model can successfully detect unsynchronized speaking as not speaking, addressing the limitation of current models.
Joint Spatial-Temporal and Appearance Modeling with Transformer for Multiple Object Tracking
May 31, 2022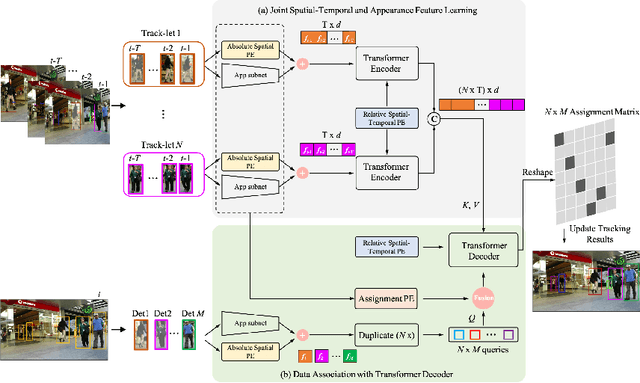

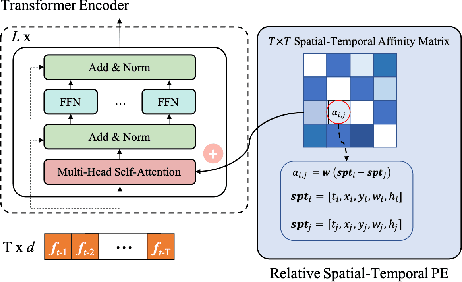
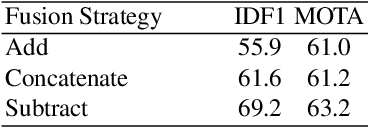
The recent trend in multiple object tracking (MOT) is heading towards leveraging deep learning to boost the tracking performance. In this paper, we propose a novel solution named TransSTAM, which leverages Transformer to effectively model both the appearance features of each object and the spatial-temporal relationships among objects. TransSTAM consists of two major parts: (1) The encoder utilizes the powerful self-attention mechanism of Transformer to learn discriminative features for each tracklet; (2) The decoder adopts the standard cross-attention mechanism to model the affinities between the tracklets and the detections by taking both spatial-temporal and appearance features into account. TransSTAM has two major advantages: (1) It is solely based on the encoder-decoder architecture and enjoys a compact network design, hence being computationally efficient; (2) It can effectively learn spatial-temporal and appearance features within one model, hence achieving better tracking accuracy. The proposed method is evaluated on multiple public benchmarks including MOT16, MOT17, and MOT20, and it achieves a clear performance improvement in both IDF1 and HOTA with respect to previous state-of-the-art approaches on all the benchmarks. Our code is available at \url{https://github.com/icicle4/TranSTAM}.
VD-PCR: Improving Visual Dialog with Pronoun Coreference Resolution
May 29, 2022
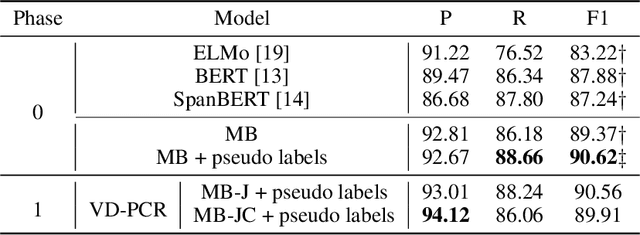
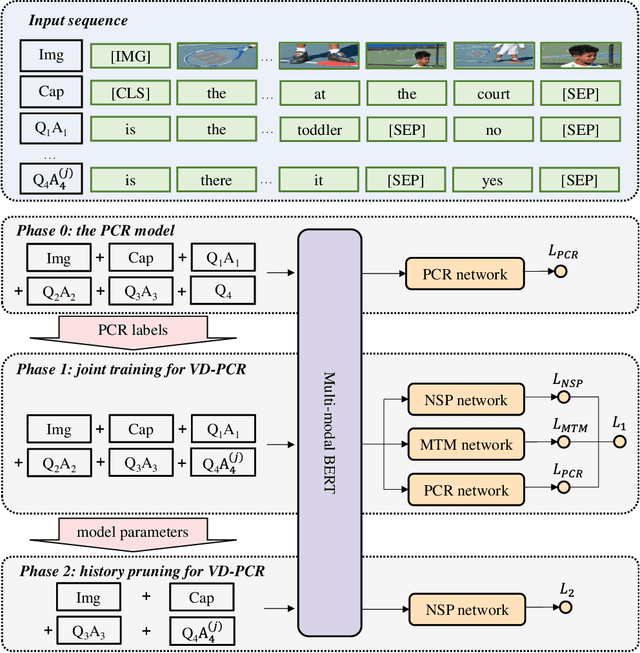
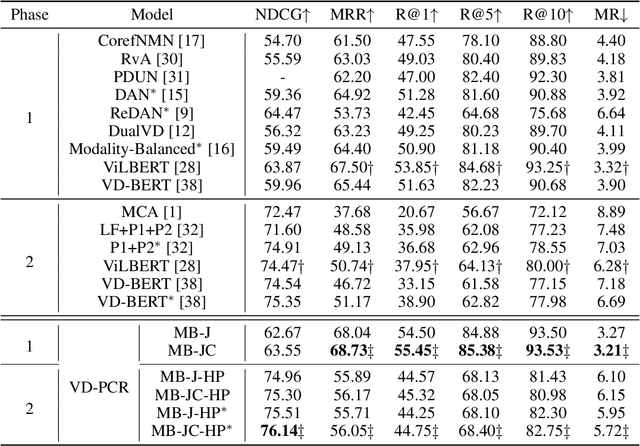
The visual dialog task requires an AI agent to interact with humans in multi-round dialogs based on a visual environment. As a common linguistic phenomenon, pronouns are often used in dialogs to improve the communication efficiency. As a result, resolving pronouns (i.e., grounding pronouns to the noun phrases they refer to) is an essential step towards understanding dialogs. In this paper, we propose VD-PCR, a novel framework to improve Visual Dialog understanding with Pronoun Coreference Resolution in both implicit and explicit ways. First, to implicitly help models understand pronouns, we design novel methods to perform the joint training of the pronoun coreference resolution and visual dialog tasks. Second, after observing that the coreference relationship of pronouns and their referents indicates the relevance between dialog rounds, we propose to explicitly prune the irrelevant history rounds in visual dialog models' input. With pruned input, the models can focus on relevant dialog history and ignore the distraction in the irrelevant one. With the proposed implicit and explicit methods, VD-PCR achieves state-of-the-art experimental results on the VisDial dataset.
* The manuscript version of the paper. The published version is available at https://doi.org/10.1016/j.patcog.2022.108540 . The data, code and models are available at: https://github.com/HKUST- KnowComp/VD-PCR
METGEN: A Module-Based Entailment Tree Generation Framework for Answer Explanation
May 05, 2022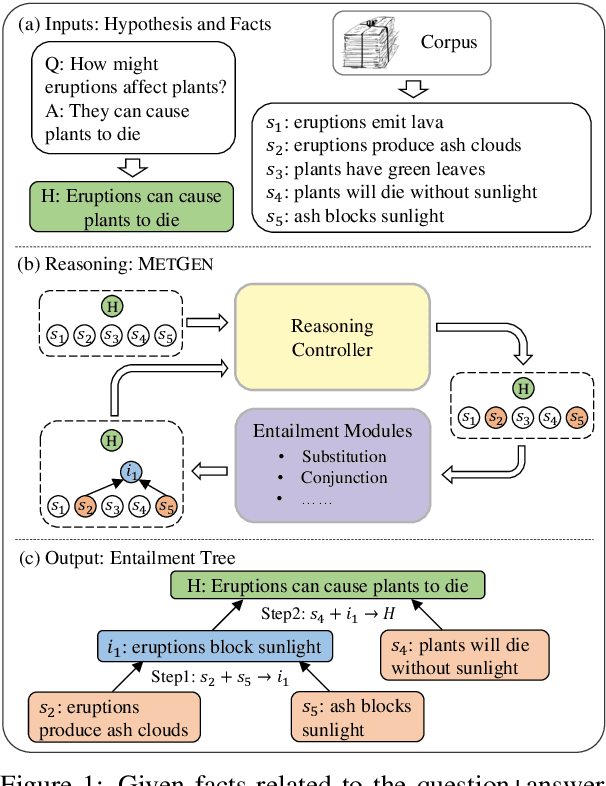

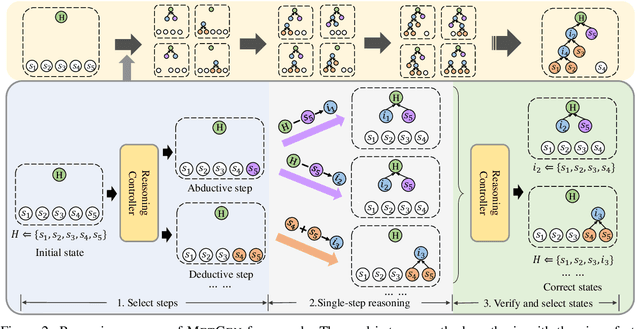
Knowing the reasoning chains from knowledge to the predicted answers can help construct an explainable question answering (QA) system. Advances on QA explanation propose to explain the answers with entailment trees composed of multiple entailment steps. While current work proposes to generate entailment trees with end-to-end generative models, the steps in the generated trees are not constrained and could be unreliable. In this paper, we propose METGEN, a Module-based Entailment Tree GENeration framework that has multiple modules and a reasoning controller. Given a question and several supporting knowledge, METGEN can iteratively generate the entailment tree by conducting single-step entailment with separate modules and selecting the reasoning flow with the controller. As each module is guided to perform a specific type of entailment reasoning, the steps generated by METGEN are more reliable and valid. Experiment results on the standard benchmark show that METGEN can outperform previous state-of-the-art models with only 9% of the parameters.