 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Tube Network for Action Detection in Videos
Jul 03, 2019



We address the problem of spatio-temporal action detection in videos. Existing methods commonly either ignore temporal context in action recognition and localization, or lack the modelling of flexible shapes of action tubes. In this paper, we propose a two-stage action detector called Deformable Tube Network (DTN), which is composed of a Deformation Tube Proposal Network (DTPN) and a Deformable Tube Recognition Network (DTRN) similar to the Faster R-CNN architecture. In DTPN, a fast proposal linking algorithm (FTL) is introduced to connect region proposals across frames to generate multiple deformable action tube proposals. To perform action detection, we design a 3D convolution network with skip connections for tube classification and regression. Modelling action proposals as deformable tubes explicitly considers the shape of action tubes compared to 3D cuboids. Moreover, 3D convolution based recognition network can learn temporal dynamics sufficiently for action detection. Our experimental results show that we significantly outperform the methods with 3D cuboids and obtain the state-of-the-art results on both UCF-Sports and AVA datasets.
A Context-and-Spatial Aware Network for Multi-Person Pose Estimation
May 14, 2019

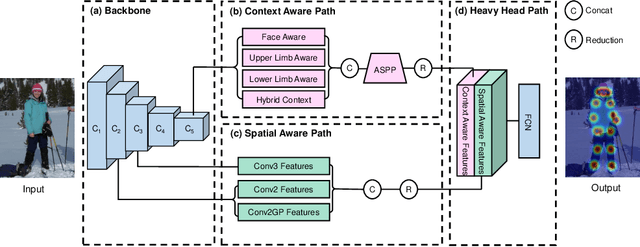

Multi-person pose estimation is a fundamental yet challenging task in computer vision. Both rich context information and spatial information are required to precisely locate the keypoints for all persons in an image. In this paper, a novel Context-and-Spatial Aware Network (CSANet), which integrates both a Context Aware Path and Spatial Aware Path, is proposed to obtain effective features involving both context information and spatial information. Specifically, we design a Context Aware Path with structure supervision strategy and spatial pyramid pooling strategy to enhance the context information. Meanwhile, a Spatial Aware Path is proposed to preserve the spatial information, which also shortens the information propagation path from low-level features to high-level features. On top of these two paths, we employ a Heavy Head Path to further combine and enhance the features effectively. Experimentally, our proposed network outperforms state-of-the-art methods on the COCO keypoint benchmark, which verifies the effectiveness of our method and further corroborates the above proposition.
Multi-Person Pose Estimation with Enhanced Channel-wise and Spatial Information
May 09, 2019
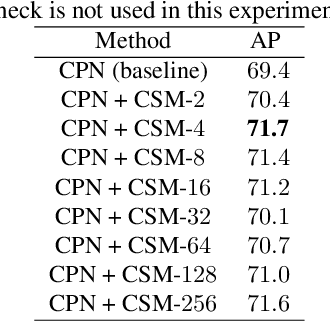
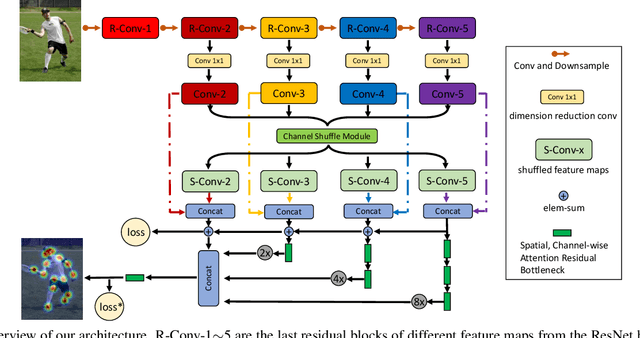
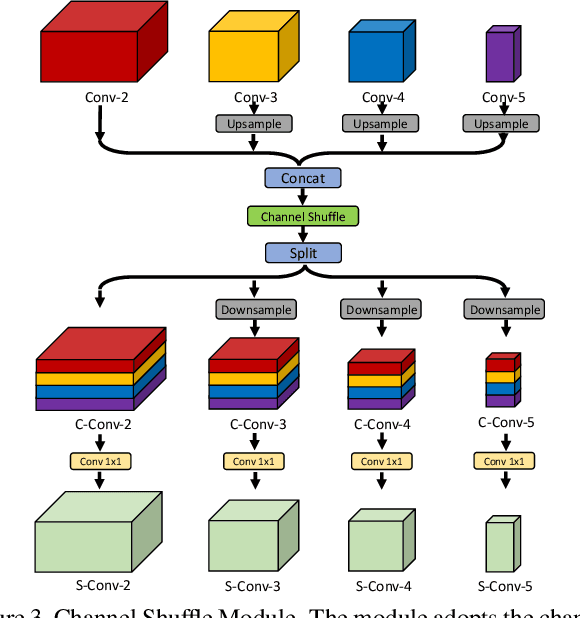
Multi-person pose estimation is an important but challenging problem in computer vision. Although current approaches have achieved significant progress by fusing the multi-scale feature maps, they pay little attention to enhancing the channel-wise and spatial information of the feature maps. In this paper, we propose two novel modules to perform the enhancement of the information for the multi-person pose estimation. First, a Channel Shuffle Module (CSM) is proposed to adopt the channel shuffle operation on the feature maps with different levels, promoting cross-channel information communication among the pyramid feature maps. Second, a Spatial, Channel-wise Attention Residual Bottleneck (SCARB) is designed to boost the original residual unit with attention mechanism, adaptively highlighting the information of the feature maps both in the spatial and channel-wise context. The effectiveness of our proposed modules is evaluated on the COCO keypoint benchmark, and experimental results show that our approach achieves the state-of-the-art results.
Generative Dual Adversarial Network for Generalized Zero-shot Learning
Nov 17, 2018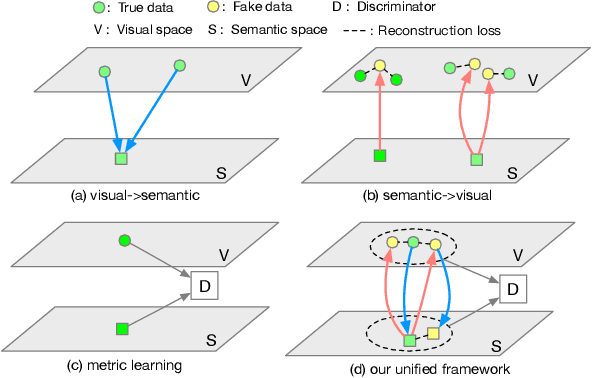
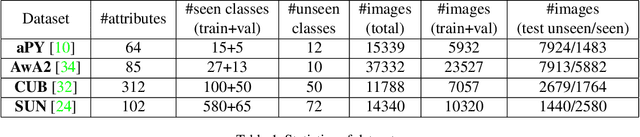
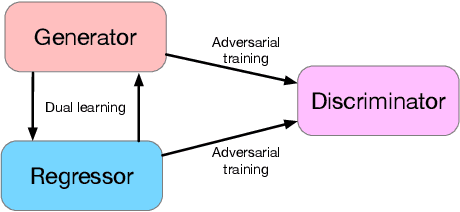
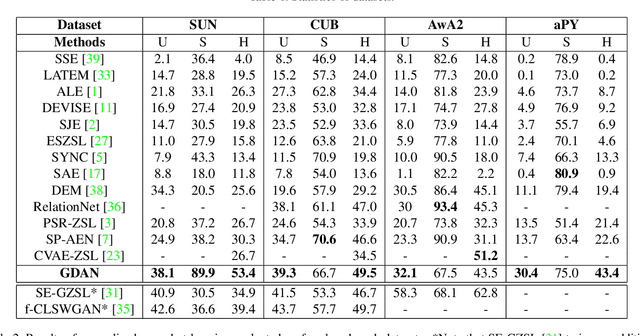
This paper studies the problem of generalized zero-shot learning which requires the model to train on image-label pairs from some seen classes and test on the task of classifying new images from both seen and unseen classes. Most previous models try to learn a fixed one-directional mapping between visual and semantic space, while some recently proposed generative methods try to generate image features for unseen classes so that the zero-shot learning problem becomes a traditional fully-supervised classification problem. In this paper, we propose a novel model that provides a unified framework for three different approaches: visual-> semantic mapping, semantic->visual mapping, and metric learning. Specifically, our proposed model consists of a feature generator that can generate various visual features given class embeddings as input, a regressor that maps each visual feature back to its corresponding class embedding, and a discriminator that learns to evaluate the closeness of an image feature and a class embedding. All three components are trained under the combination of cyclic consistency loss and dual adversarial loss. Experimental results show that our model not only preserves higher accuracy in classifying images from seen classes, but also performs better than existing state-of-the-art models in in classifying images from unseen classes.
Mask Propagation Network for Video Object Segmentation
Oct 24, 2018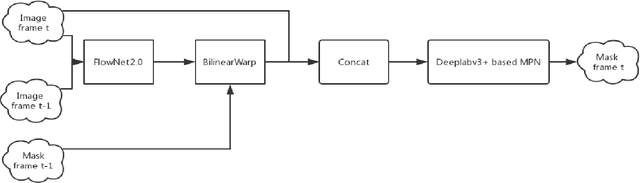
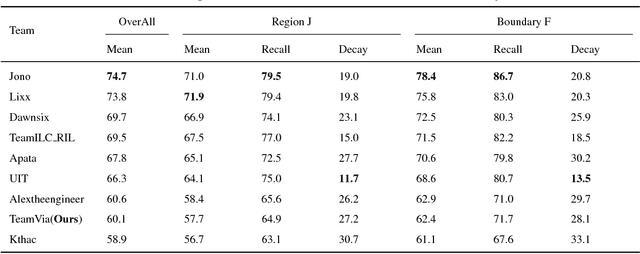

In this work, we propose a mask propagation network to treat the video segmentation problem as a concept of the guided instance segmentation. Similar to most MaskTrack based video segmentation methods, our method takes the mask probability map of previous frame and the appearance of current frame as inputs, and predicts the mask probability map for the current frame. Specifically, we adopt the Xception backbone based DeepLab v3+ model as the probability map predictor in our prediction pipeline. Besides, instead of the full image and the original mask probability, our network takes the region of interest of the instance, and the new mask probability which warped by the optical flow between the previous and current frames as the inputs. We also ensemble the modified One-Shot Video Segmentation Network to make the final predictions in order to retrieve and segment the missing instance.
Knowing Where to Look? Analysis on Attention of Visual Question Answering System
Oct 09, 2018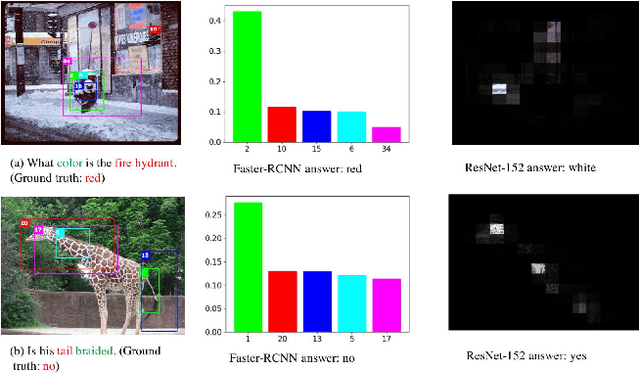
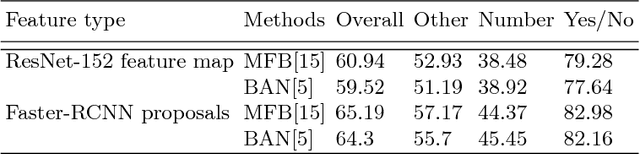
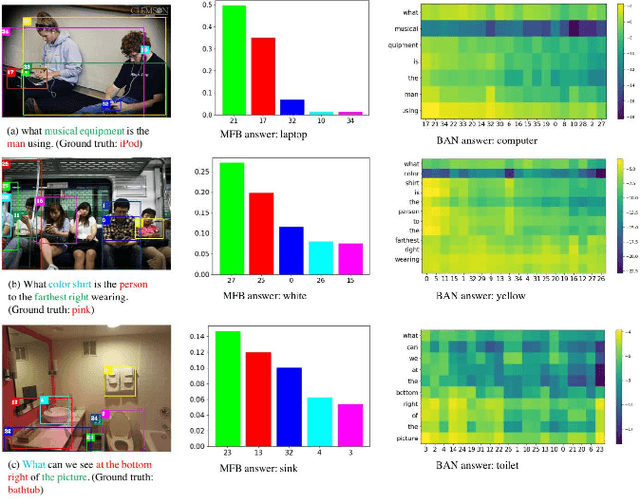
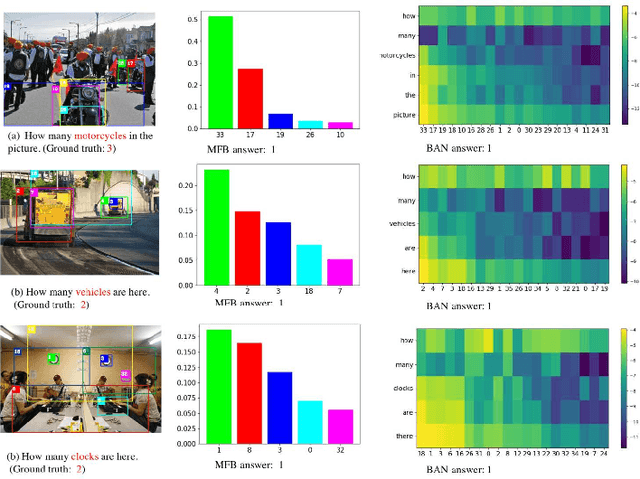
Attention mechanisms have been widely used in Visual Question Answering (VQA) solutions due to their capacity to model deep cross-domain interactions. Analyzing attention maps offers us a perspective to find out limitations of current VQA systems and an opportunity to further improve them. In this paper, we select two state-of-the-art VQA approaches with attention mechanisms to study their robustness and disadvantages by visualizing and analyzing their estimated attention maps. We find that both methods are sensitive to features, and simultaneously, they perform badly for counting and multi-object related questions. We believe that the findings and analytical method will help researchers identify crucial challenges on the way to improve their own VQA systems.
Towards Good Practices for Multi-modal Fusion in Large-scale Video Classification
Sep 28, 2018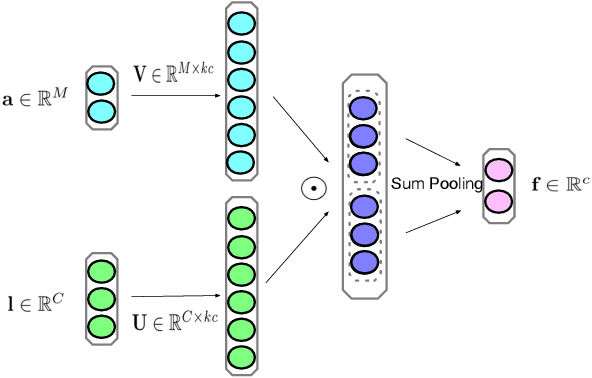

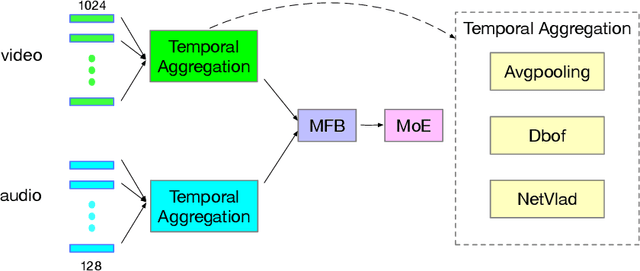

Leveraging both visual frames and audio has been experimentally proven effective to improve large-scale video classification. Previous research on video classification mainly focuses on the analysis of visual content among extracted video frames and their temporal feature aggregation. In contrast, multimodal data fusion is achieved by simple operators like average and concatenation. Inspired by the success of bilinear pooling in the visual and language fusion, we introduce multi-modal factorized bilinear pooling (MFB) to fuse visual and audio representations. We combine MFB with different video-level features and explore its effectiveness in video classification. Experimental results on the challenging Youtube-8M v2 dataset demonstrate that MFB significantly outperforms simple fusion methods in large-scale video classification.
An Introduction to Image Synthesis with Generative Adversarial Nets
Mar 12, 2018There has been a drastic growth of research in Generative Adversarial Nets (GANs) in the past few years. Proposed in 2014, GAN has been applied to various applications such as computer vision and natural language processing, and achieves impressive performance. Among the many applications of GAN, image synthesis is the most well-studied one, and research in this area has already demonstrated the great potential of using GAN in image synthesis. In this paper, we provide a taxonomy of methods used in image synthesis, review different models for text-to-image synthesis and image-to-image translation, and discuss some evaluation metrics as well as possible future research directions in image synthesis with GAN.
MAT: A Multimodal Attentive Translator for Image Captioning
Aug 10, 2017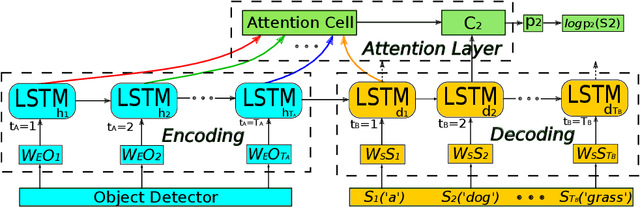

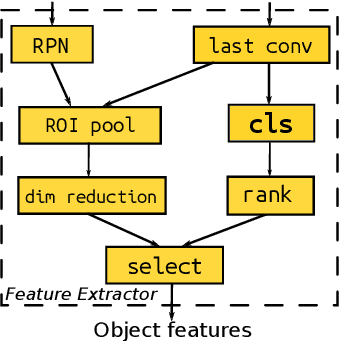
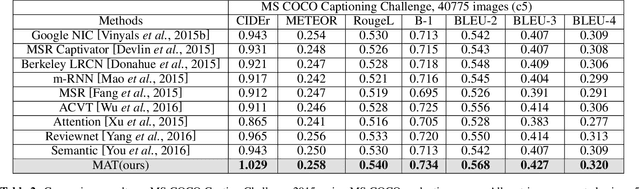
In this work we formulate the problem of image captioning as a multimodal translation task. Analogous to machine translation, we present a sequence-to-sequence recurrent neural networks (RNN) model for image caption generation. Different from most existing work where the whole image is represented by convolutional neural network (CNN) feature, we propose to represent the input image as a sequence of detected objects which feeds as the source sequence of the RNN model. In this way, the sequential representation of an image can be naturally translated to a sequence of words, as the target sequence of the RNN model. To represent the image in a sequential way, we extract the objects features in the image and arrange them in a order using convolutional neural networks. To further leverage the visual information from the encoded objects, a sequential attention layer is introduced to selectively attend to the objects that are related to generate corresponding words in the sentences. Extensive experiments are conducted to validate the proposed approach on popular benchmark dataset, i.e., MS COCO, and the proposed model surpasses the state-of-the-art methods in all metrics following the dataset splits of previous work. The proposed approach is also evaluated by the evaluation server of MS COCO captioning challenge, and achieves very competitive results, e.g., a CIDEr of 1.029 (c5) and 1.064 (c40).
Modularized Morphing of Neural Networks
Jan 12, 2017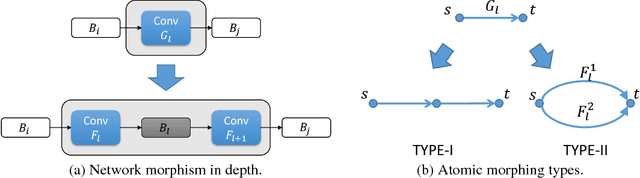
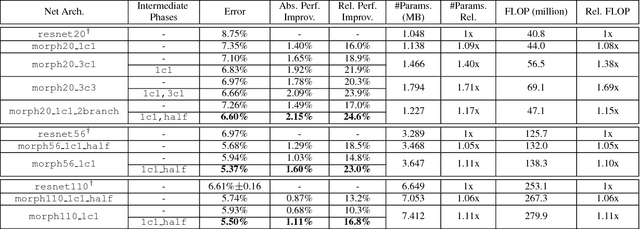
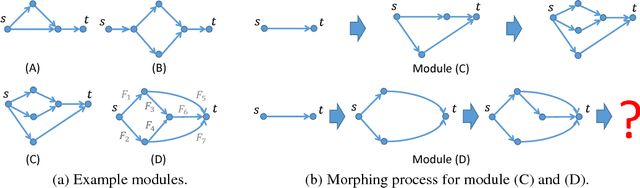
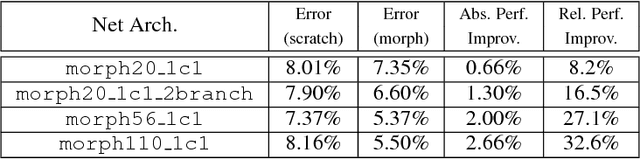
In this work we study the problem of network morphism, an effective learning scheme to morph a well-trained neural network to a new one with the network function completely preserved. Different from existing work where basic morphing types on the layer level were addressed, we target at the central problem of network morphism at a higher level, i.e., how a convolutional layer can be morphed into an arbitrary module of a neural network. To simplify the representation of a network, we abstract a module as a graph with blobs as vertices and convolutional layers as edges, based on which the morphing process is able to be formulated as a graph transformation problem. Two atomic morphing operations are introduced to compose the graphs, based on which modules are classified into two families, i.e., simple morphable modules and complex modules. We present practical morphing solutions for both of these two families, and prove that any reasonable module can be morphed from a single convolutional layer. Extensive experiments have been conducted based on the state-of-the-art ResNet on benchmark datasets, and the effectiveness of the proposed solution has been verified.