 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXray-Visual Models: Scaling Vision models on Industry Scale Data
Feb 18, 2026We present Xray-Visual, a unified vision model architecture for large-scale image and video understanding trained on industry-scale social media data. Our model leverages over 15 billion curated image-text pairs and 10 billion video-hashtag pairs from Facebook and Instagram, employing robust data curation pipelines that incorporate balancing and noise suppression strategies to maximize semantic diversity while minimizing label noise. We introduce a three-stage training pipeline that combines self-supervised MAE, semi-supervised hashtag classification, and CLIP-style contrastive learning to jointly optimize image and video modalities. Our architecture builds on a Vision Transformer backbone enhanced with efficient token reorganization (EViT) for improved computational efficiency. Extensive experiments demonstrate that Xray-Visual achieves state-of-the-art performance across diverse benchmarks, including ImageNet for image classification, Kinetics and HMDB51 for video understanding, and MSCOCO for cross-modal retrieval. The model exhibits strong robustness to domain shift and adversarial perturbations. We further demonstrate that integrating large language models as text encoders (LLM2CLIP) significantly enhances retrieval performance and generalization capabilities, particularly in real-world environments. Xray-Visual establishes new benchmarks for scalable, multimodal vision models, while maintaining superior accuracy and computational efficiency.
Think Then Embed: Generative Context Improves Multimodal Embedding
Oct 06, 2025There is a growing interest in Universal Multimodal Embeddings (UME), where models are required to generate task-specific representations. While recent studies show that Multimodal Large Language Models (MLLMs) perform well on such tasks, they treat MLLMs solely as encoders, overlooking their generative capacity. However, such an encoding paradigm becomes less effective as instructions become more complex and require compositional reasoning. Inspired by the proven effectiveness of chain-of-thought reasoning, we propose a general Think-Then-Embed (TTE) framework for UME, composed of a reasoner and an embedder. The reasoner MLLM first generates reasoning traces that explain complex queries, followed by an embedder that produces representations conditioned on both the original query and the intermediate reasoning. This explicit reasoning step enables more nuanced understanding of complex multimodal instructions. Our contributions are threefold. First, by leveraging a powerful MLLM reasoner, we achieve state-of-the-art performance on the MMEB-V2 benchmark, surpassing proprietary models trained on massive in-house datasets. Second, to reduce the dependency on large MLLM reasoners, we finetune a smaller MLLM reasoner using high-quality embedding-centric reasoning traces, achieving the best performance among open-source models with a 7% absolute gain over recently proposed models. Third, we investigate strategies for integrating the reasoner and embedder into a unified model for improved efficiency without sacrificing performance.
A Comprehensive Review of Data-Driven Co-Speech Gesture Generation
Jan 13, 2023Gestures that accompany speech are an essential part of natural and efficient embodied human communication. The automatic generation of such co-speech gestures is a long-standing problem in computer animation and is considered an enabling technology in film, games, virtual social spaces, and for interaction with social robots. The problem is made challenging by the idiosyncratic and non-periodic nature of human co-speech gesture motion, and by the great diversity of communicative functions that gestures encompass. Gesture generation has seen surging interest recently, owing to the emergence of more and larger datasets of human gesture motion, combined with strides in deep-learning-based generative models, that benefit from the growing availability of data. This review article summarizes co-speech gesture generation research, with a particular focus on deep generative models. First, we articulate the theory describing human gesticulation and how it complements speech. Next, we briefly discuss rule-based and classical statistical gesture synthesis, before delving into deep learning approaches. We employ the choice of input modalities as an organizing principle, examining systems that generate gestures from audio, text, and non-linguistic input. We also chronicle the evolution of the related training data sets in terms of size, diversity, motion quality, and collection method. Finally, we identify key research challenges in gesture generation, including data availability and quality; producing human-like motion; grounding the gesture in the co-occurring speech in interaction with other speakers, and in the environment; performing gesture evaluation; and integration of gesture synthesis into applications. We highlight recent approaches to tackling the various key challenges, as well as the limitations of these approaches, and point toward areas of future development.
Multimodal Lecture Presentations Dataset: Understanding Multimodality in Educational Slides
Aug 17, 2022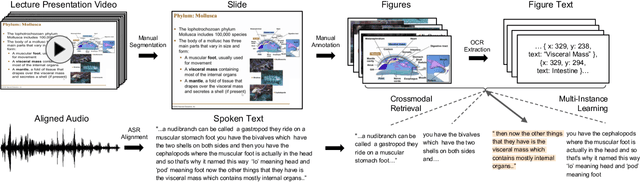
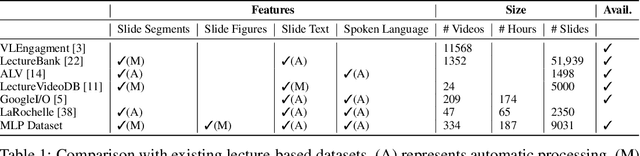
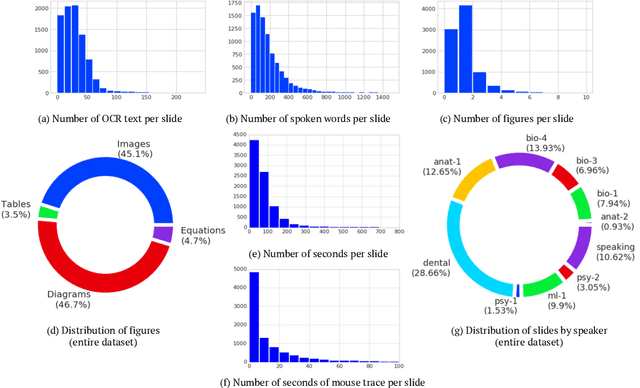
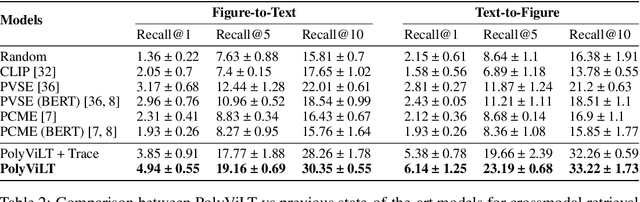
Lecture slide presentations, a sequence of pages that contain text and figures accompanied by speech, are constructed and presented carefully in order to optimally transfer knowledge to students. Previous studies in multimedia and psychology attribute the effectiveness of lecture presentations to their multimodal nature. As a step toward developing AI to aid in student learning as intelligent teacher assistants, we introduce the Multimodal Lecture Presentations dataset as a large-scale benchmark testing the capabilities of machine learning models in multimodal understanding of educational content. Our dataset contains aligned slides and spoken language, for 180+ hours of video and 9000+ slides, with 10 lecturers from various subjects (e.g., computer science, dentistry, biology). We introduce two research tasks which are designed as stepping stones towards AI agents that can explain (automatically captioning a lecture presentation) and illustrate (synthesizing visual figures to accompany spoken explanations) educational content. We provide manual annotations to help implement these two research tasks and evaluate state-of-the-art models on them. Comparing baselines and human student performances, we find that current models struggle in (1) weak crossmodal alignment between slides and spoken text, (2) learning novel visual mediums, (3) technical language, and (4) long-range sequences. Towards addressing this issue, we also introduce PolyViLT, a multimodal transformer trained with a multi-instance learning loss that is more effective than current approaches. We conclude by shedding light on the challenges and opportunities in multimodal understanding of educational presentations.
Style Transfer for Co-Speech Gesture Animation: A Multi-Speaker Conditional-Mixture Approach
Jul 24, 2020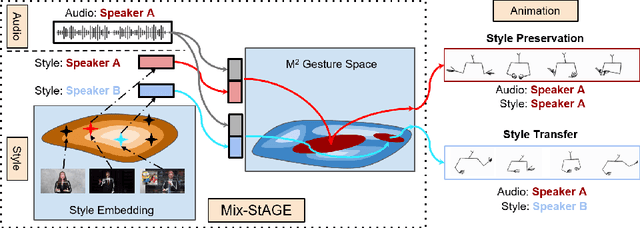
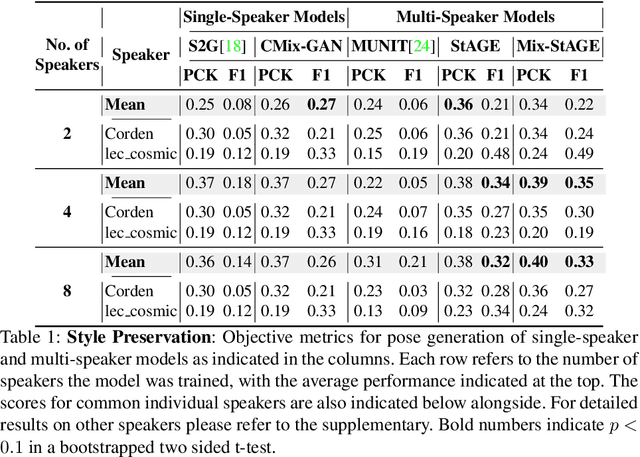
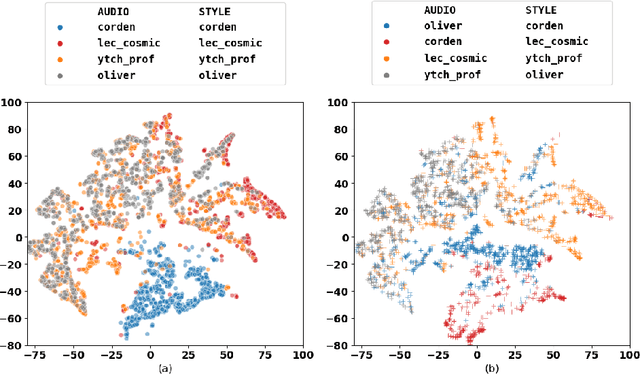
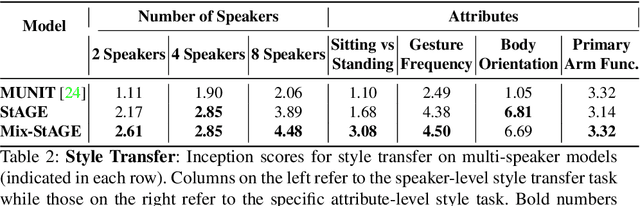
How can we teach robots or virtual assistants to gesture naturally? Can we go further and adapt the gesturing style to follow a specific speaker? Gestures that are naturally timed with corresponding speech during human communication are called co-speech gestures. A key challenge, called gesture style transfer, is to learn a model that generates these gestures for a speaking agent 'A' in the gesturing style of a target speaker 'B'. A secondary goal is to simultaneously learn to generate co-speech gestures for multiple speakers while remembering what is unique about each speaker. We call this challenge style preservation. In this paper, we propose a new model, named Mix-StAGE, which trains a single model for multiple speakers while learning unique style embeddings for each speaker's gestures in an end-to-end manner. A novelty of Mix-StAGE is to learn a mixture of generative models which allows for conditioning on the unique gesture style of each speaker. As Mix-StAGE disentangles style and content of gestures, gesturing styles for the same input speech can be altered by simply switching the style embeddings. Mix-StAGE also allows for style preservation when learning simultaneously from multiple speakers. We also introduce a new dataset, Pose-Audio-Transcript-Style (PATS), designed to study gesture generation and style transfer. Our proposed Mix-StAGE model significantly outperforms the previous state-of-the-art approach for gesture generation and provides a path towards performing gesture style transfer across multiple speakers. Link to code, data, and videos: http://chahuja.com/mix-stage
* 24 pages, 12 figures
To React or not to React: End-to-End Visual Pose Forecasting for Personalized Avatar during Dyadic Conversations
Oct 05, 2019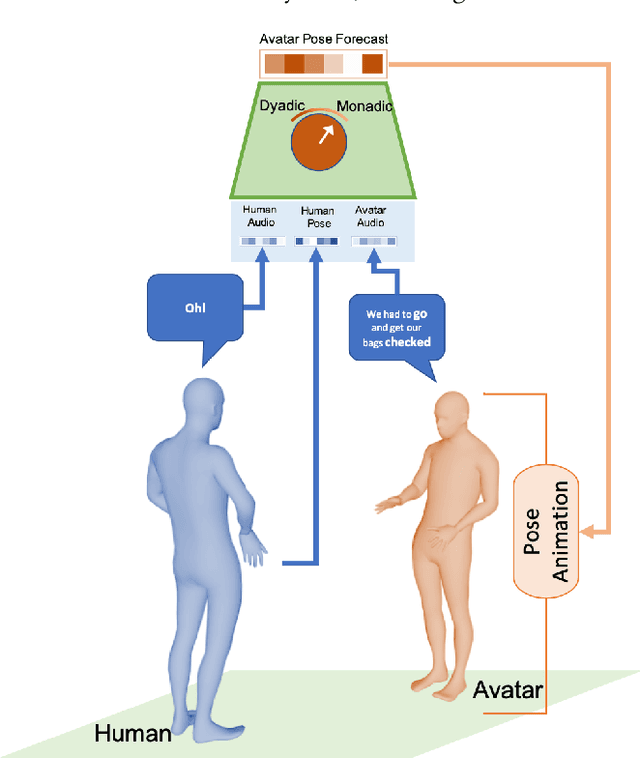
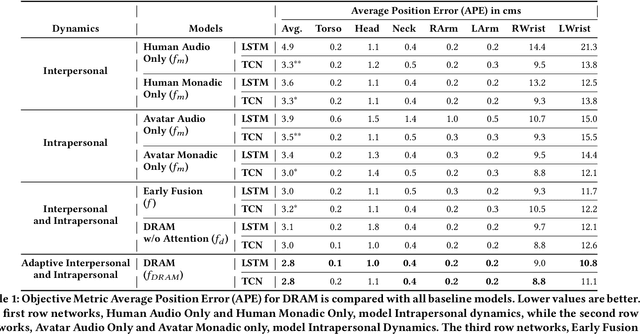
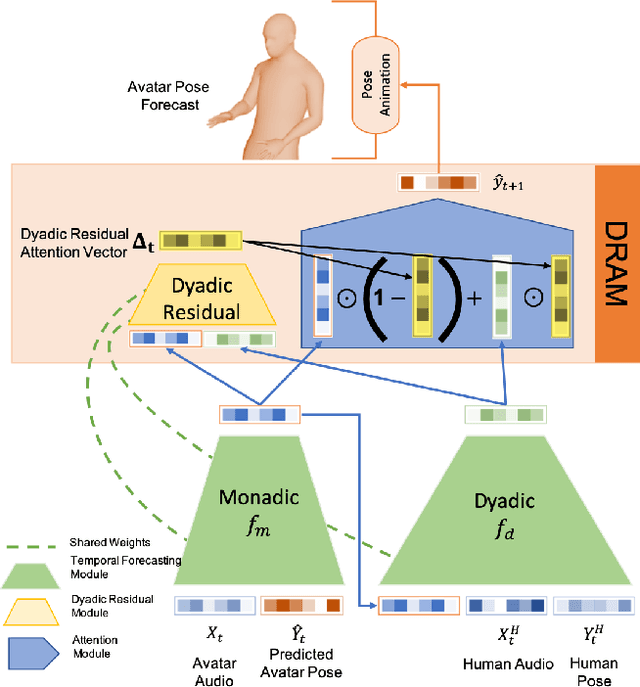
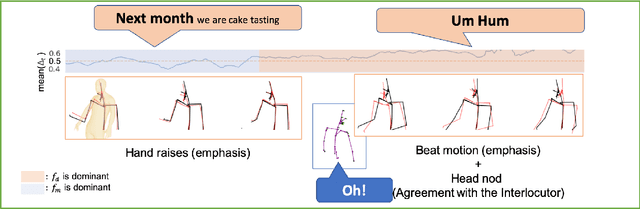
Non verbal behaviours such as gestures, facial expressions, body posture, and para-linguistic cues have been shown to complement or clarify verbal messages. Hence to improve telepresence, in form of an avatar, it is important to model these behaviours, especially in dyadic interactions. Creating such personalized avatars not only requires to model intrapersonal dynamics between a avatar's speech and their body pose, but it also needs to model interpersonal dynamics with the interlocutor present in the conversation. In this paper, we introduce a neural architecture named Dyadic Residual-Attention Model (DRAM), which integrates intrapersonal (monadic) and interpersonal (dyadic) dynamics using selective attention to generate sequences of body pose conditioned on audio and body pose of the interlocutor and audio of the human operating the avatar. We evaluate our proposed model on dyadic conversational data consisting of pose and audio of both participants, confirming the importance of adaptive attention between monadic and dyadic dynamics when predicting avatar pose. We also conduct a user study to analyze judgments of human observers. Our results confirm that the generated body pose is more natural, models intrapersonal dynamics and interpersonal dynamics better than non-adaptive monadic/dyadic models.
Language2Pose: Natural Language Grounded Pose Forecasting
Jul 02, 2019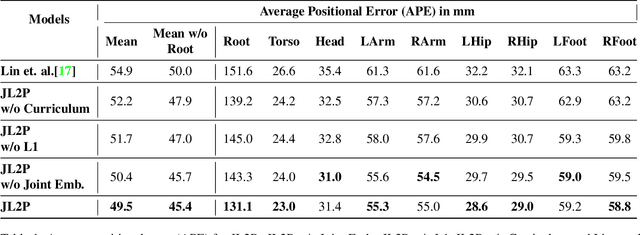
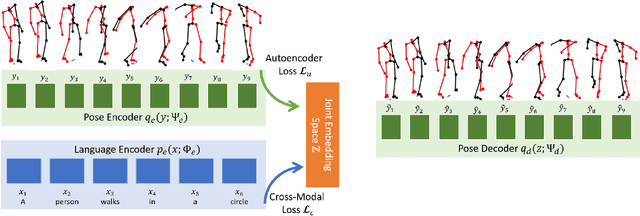
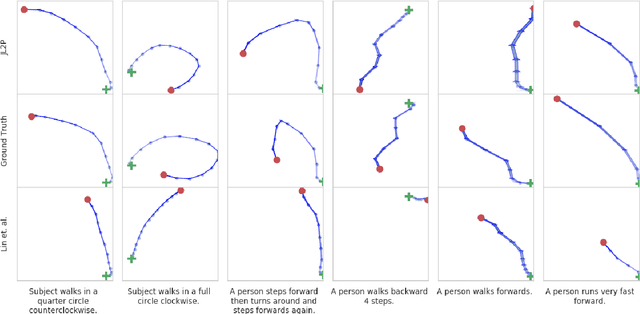
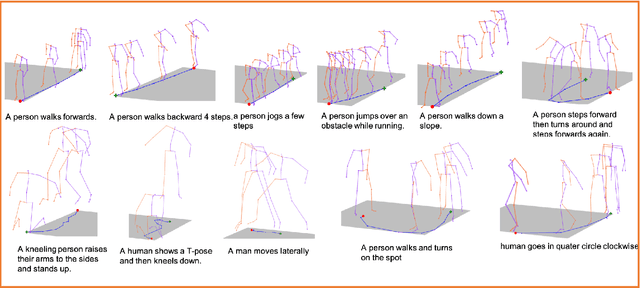
Generating animations from natural language sentences finds its applications in a a number of domains such as movie script visualization, virtual human animation and, robot motion planning. These sentences can describe different kinds of actions, speeds and direction of these actions, and possibly a target destination. The core modeling challenge in this language-to-pose application is how to map linguistic concepts to motion animations. In this paper, we address this multimodal problem by introducing a neural architecture called Joint Language to Pose (or JL2P), which learns a joint embedding of language and pose. This joint embedding space is learned end-to-end using a curriculum learning approach which emphasizes shorter and easier sequences first before moving to longer and harder ones. We evaluate our proposed model on a publicly available corpus of 3D pose data and human-annotated sentences. Both objective metrics and human judgment evaluation confirm that our proposed approach is able to generate more accurate animations and are deemed visually more representative by humans than other data driven approaches.
Lattice Recurrent Unit: Improving Convergence and Statistical Efficiency for Sequence Modeling
Nov 22, 2017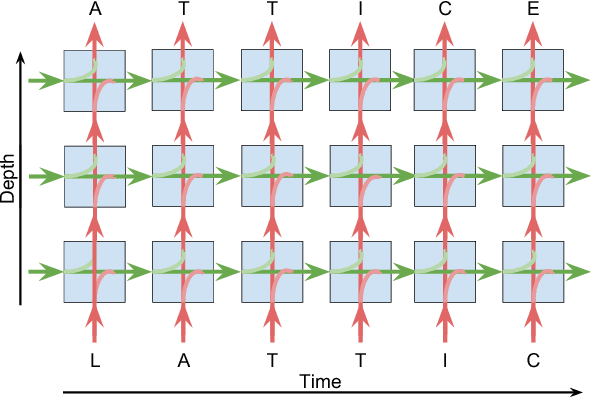
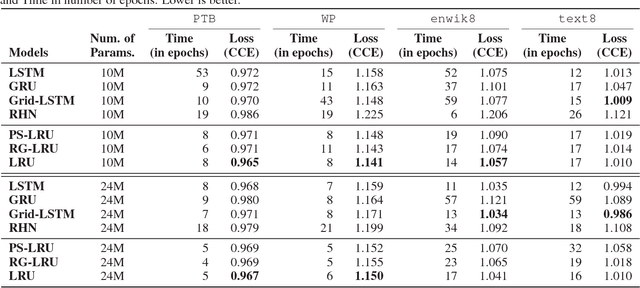
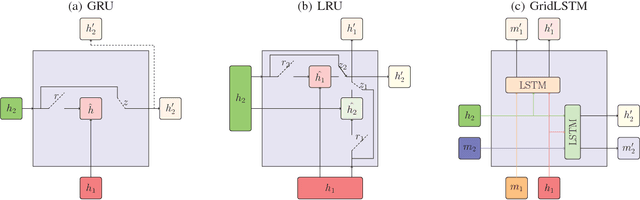

Recurrent neural networks have shown remarkable success in modeling sequences. However low resource situations still adversely affect the generalizability of these models. We introduce a new family of models, called Lattice Recurrent Units (LRU), to address the challenge of learning deep multi-layer recurrent models with limited resources. LRU models achieve this goal by creating distinct (but coupled) flow of information inside the units: a first flow along time dimension and a second flow along depth dimension. It also offers a symmetry in how information can flow horizontally and vertically. We analyze the effects of decoupling three different components of our LRU model: Reset Gate, Update Gate and Projected State. We evaluate this family on new LRU models on computational convergence rates and statistical efficiency. Our experiments are performed on four publicly-available datasets, comparing with Grid-LSTM and Recurrent Highway networks. Our results show that LRU has better empirical computational convergence rates and statistical efficiency values, along with learning more accurate language models.
Multimodal Machine Learning: A Survey and Taxonomy
Aug 01, 2017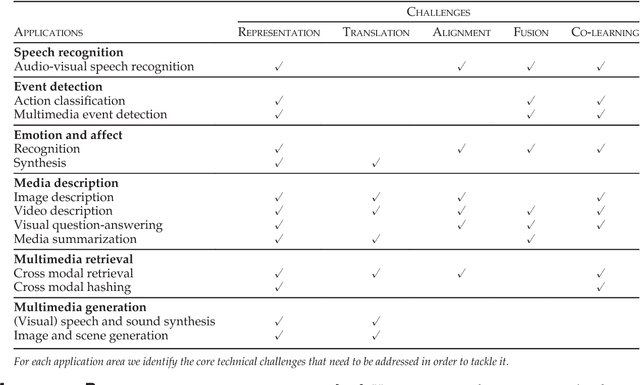
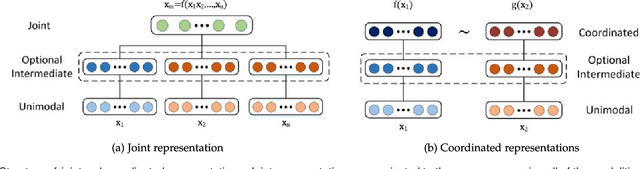
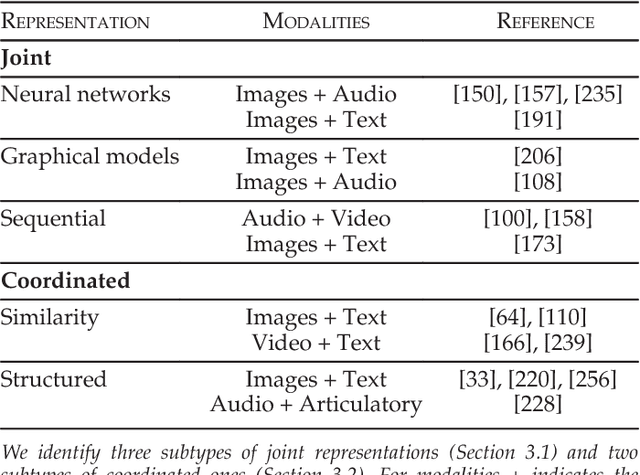
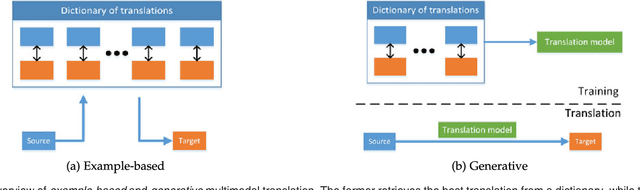
Our experience of the world is multimodal - we see objects, hear sounds, feel texture, smell odors, and taste flavors. Modality refers to the way in which something happens or is experienced and a research problem is characterized as multimodal when it includes multiple such modalities. In order for Artificial Intelligence to make progress in understanding the world around us, it needs to be able to interpret such multimodal signals together. Multimodal machine learning aims to build models that can process and relate information from multiple modalities. It is a vibrant multi-disciplinary field of increasing importance and with extraordinary potential. Instead of focusing on specific multimodal applications, this paper surveys the recent advances in multimodal machine learning itself and presents them in a common taxonomy. We go beyond the typical early and late fusion categorization and identify broader challenges that are faced by multimodal machine learning, namely: representation, translation, alignment, fusion, and co-learning. This new taxonomy will enable researchers to better understand the state of the field and identify directions for future research.