 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Computationally Efficient Multiclass Time-Frequency Common Spatial Pattern Analysis on EEG Motor Imagery
Aug 25, 2020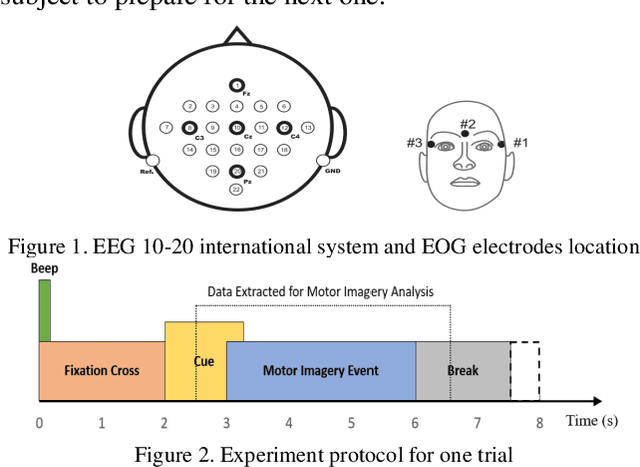
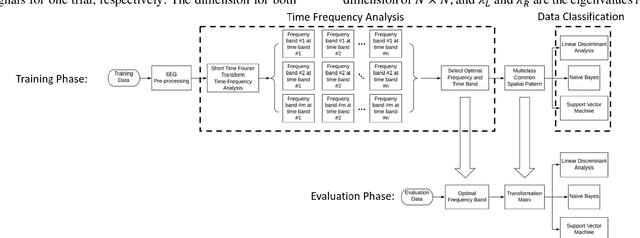
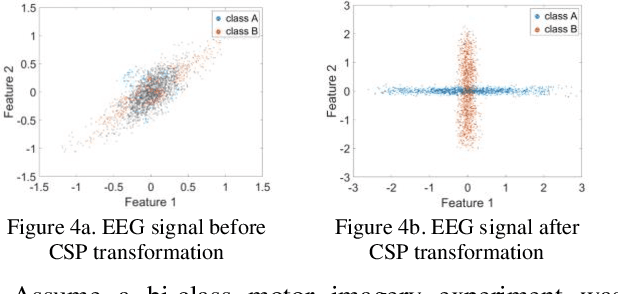
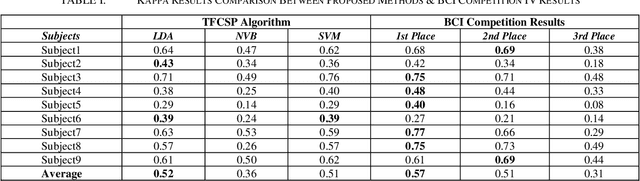
Common spatial pattern (CSP) is a popular feature extraction method for electroencephalogram (EEG) motor imagery (MI). This study modifies the conventional CSP algorithm to improve the multi-class MI classification accuracy and ensure the computation process is efficient. The EEG MI data is gathered from the Brain-Computer Interface (BCI) Competition IV. At first, a bandpass filter and a time-frequency analysis are performed for each experiment trial. Then, the optimal EEG signals for every experiment trials are selected based on the signal energy for CSP feature extraction. In the end, the extracted features are classified by three classifiers, linear discriminant analysis (LDA), na\"ive Bayes (NVB), and support vector machine (SVM), in parallel for classification accuracy comparison. The experiment results show the proposed algorithm average computation time is 37.22% less than the FBCSP (1st winner in the BCI Competition IV) and 4.98% longer than the conventional CSP method. For the classification rate, the proposed algorithm kappa value achieved 2nd highest compared with the top 3 winners in BCI Competition IV.
A Survey and Tutorial of EEG-Based Brain Monitoring for Driver State Analysis
Aug 25, 2020
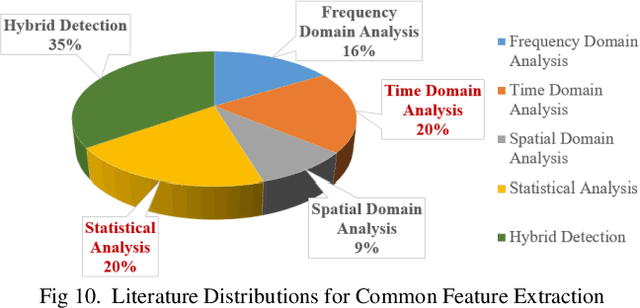
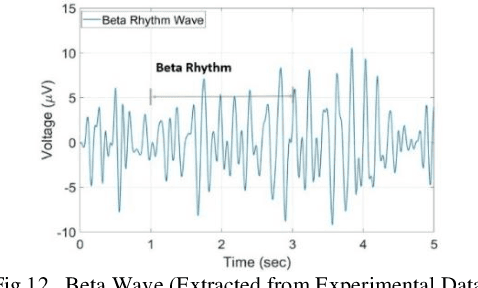
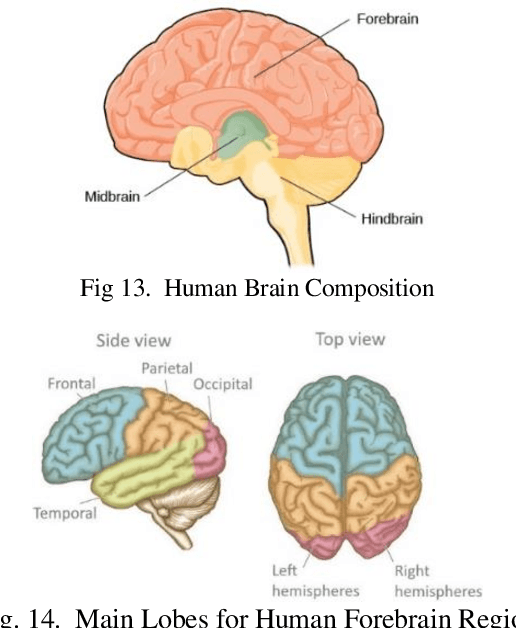
Drivers cognitive and physiological states affect their ability to control their vehicles. Thus, these driver states are important to the safety of automobiles. The design of advanced driver assistance systems (ADAS) or autonomous vehicles will depend on their ability to interact effectively with the driver. A deeper understanding of the driver state is, therefore, paramount. EEG is proven to be one of the most effective methods for driver state monitoring and human error detection. This paper discusses EEG-based driver state detection systems and their corresponding analysis algorithms over the last three decades. First, the commonly used EEG system setup for driver state studies is introduced. Then, the EEG signal preprocessing, feature extraction, and classification algorithms for driver state detection are reviewed. Finally, EEG-based driver state monitoring research is reviewed in-depth, and its future development is discussed. It is concluded that the current EEG-based driver state monitoring algorithms are promising for safety applications. However, many improvements are still required in EEG artifact reduction, real-time processing, and between-subject classification accuracy.
Interactive Feature Generation via Learning Adjacency Tensor of Feature Graph
Jul 29, 2020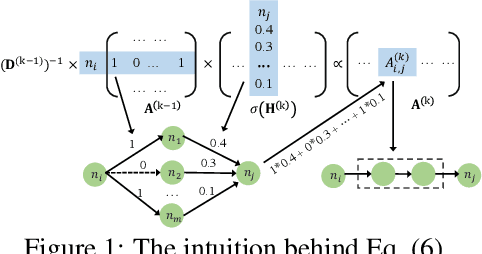
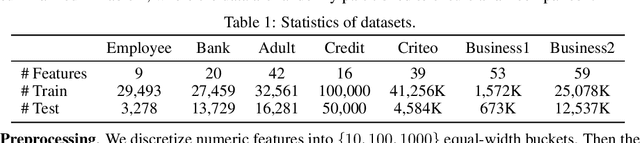
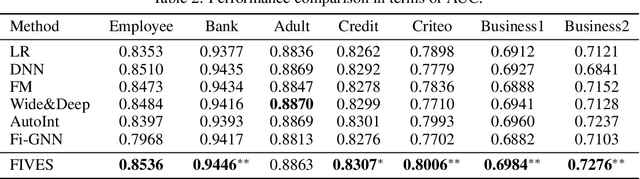
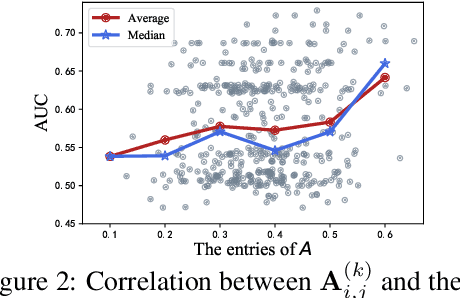
To automate the generation of interactive features, recent methods are proposed to either explicitly traverse the interactive feature space or implicitly express the interactions via intermediate activations of some designed models. These two kinds of methods show that there is essentially a trade-off between feature interpretability and efficient search. To possess both of their merits, we propose a novel method named Feature Interaction Via Edge Search (FIVES), which formulates the task of interactive feature generation as searching for edges on the defined feature graph. We first present our theoretical evidence that motivates us to search for interactive features in an inductive manner. Then we instantiate this search strategy by alternatively updating the edge structure and the predictive model of a graph neural network (GNN) associated with the defined feature graph. In this way, the proposed FIVES method traverses a trimmed search space and enables explicit feature generation according to the learned adjacency tensor of the GNN. Experimental results on both benchmark and real-world datasets demonstrate the advantages of FIVES over several state-of-the-art methods.
Adversarial Learning for Debiasing Knowledge Graph Embeddings
Jun 29, 2020

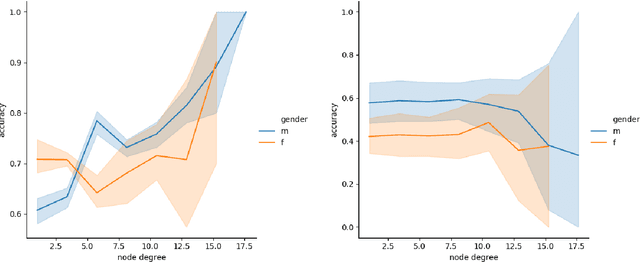
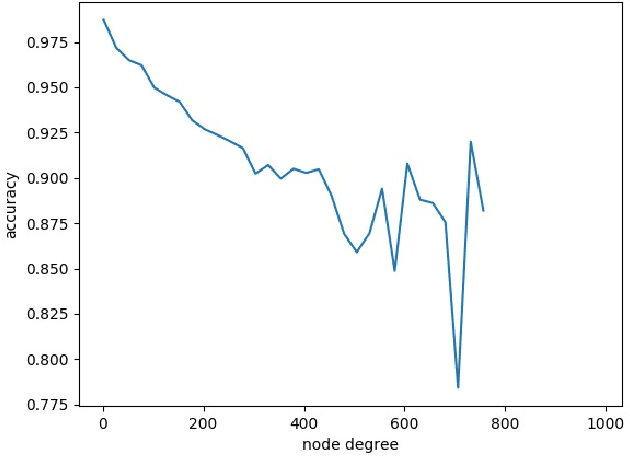
Knowledge Graphs (KG) are gaining increasing attention in both academia and industry. Despite their diverse benefits, recent research have identified social and cultural biases embedded in the representations learned from KGs. Such biases can have detrimental consequences on different population and minority groups as applications of KG begin to intersect and interact with social spheres. This paper aims at identifying and mitigating such biases in Knowledge Graph (KG) embeddings. As a first step, we explore popularity bias -- the relationship between node popularity and link prediction accuracy. In case of node2vec graph embeddings, we find that prediction accuracy of the embedding is negatively correlated with the degree of the node. However, in case of knowledge-graph embeddings (KGE), we observe an opposite trend. As a second step, we explore gender bias in KGE, and a careful examination of popular KGE algorithms suggest that sensitive attribute like the gender of a person can be predicted from the embedding. This implies that such biases in popular KGs is captured by the structural properties of the embedding. As a preliminary solution to debiasing KGs, we introduce a novel framework to filter out the sensitive attribute information from the KG embeddings, which we call FAN (Filtering Adversarial Network). We also suggest the applicability of FAN for debiasing other network embeddings which could be explored in future work.
Nearest Neighbor Classifiers over Incomplete Information: From Certain Answers to Certain Predictions
May 12, 2020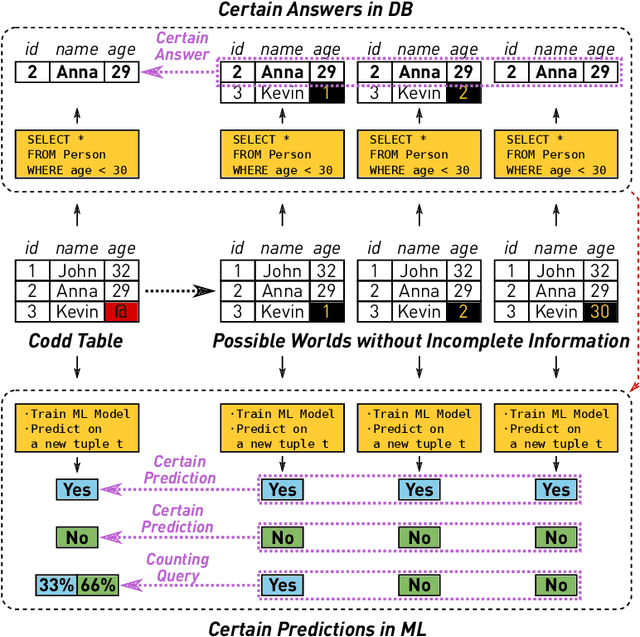
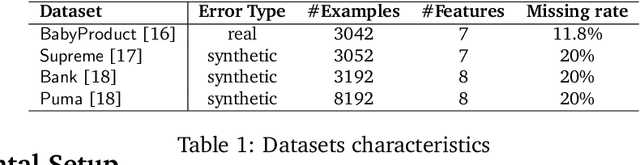
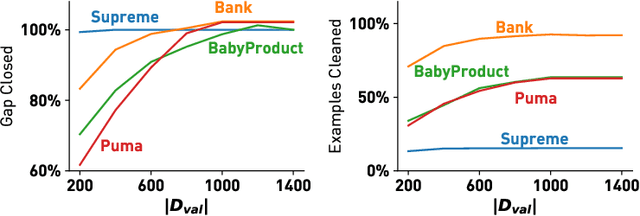
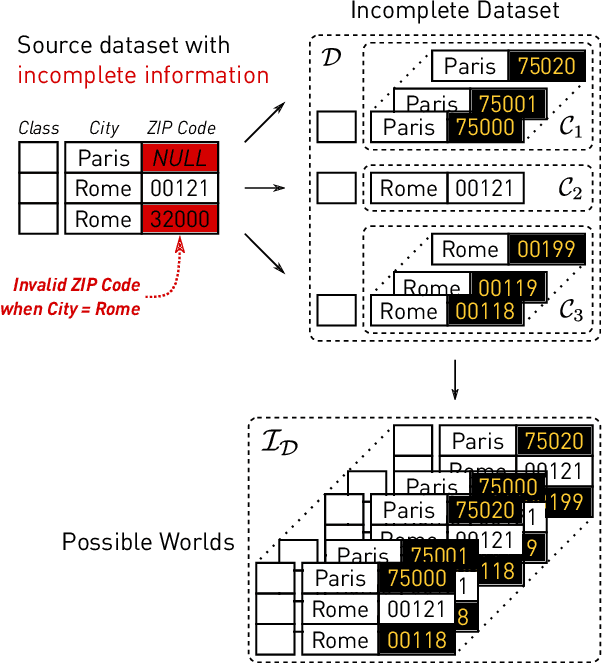
Machine learning (ML) applications have been thriving recently, largely attributed to the increasing availability of data. However, inconsistency and incomplete information are ubiquitous in real-world datasets, and their impact on ML applications remains elusive. In this paper, we present a formal study of this impact by extending the notion of Certain Answers for Codd tables, which has been explored by the database research community for decades, into the field of machine learning. Specifically, we focus on classification problems and propose the notion of "Certain Predictions" (CP) -- a test data example can be certainly predicted (CP'ed) if all possible classifiers trained on top of all possible worlds induced by the incompleteness of data would yield the same prediction. We study two fundamental CP queries: (Q1) checking query that determines whether a data example can be CP'ed; and (Q2) counting query that computes the number of classifiers that support a particular prediction (i.e., label). Given that general solutions to CP queries are, not surprisingly, hard without assumption over the type of classifier, we further present a case study in the context of nearest neighbor (NN) classifiers, where efficient solutions to CP queries can be developed -- we show that it is possible to answer both queries in linear or polynomial time over exponentially many possible worlds. We demonstrate one example use case of CP in the important application of "data cleaning for machine learning (DC for ML)." We show that our proposed CPClean approach built based on CP can often significantly outperform existing techniques in terms of classification accuracy with mild manual cleaning effort.
Control, Generate, Augment: A Scalable Framework for Multi-Attribute Text Generation
Apr 30, 2020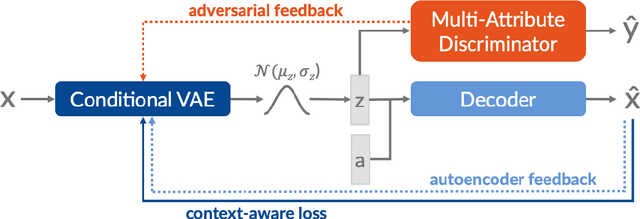


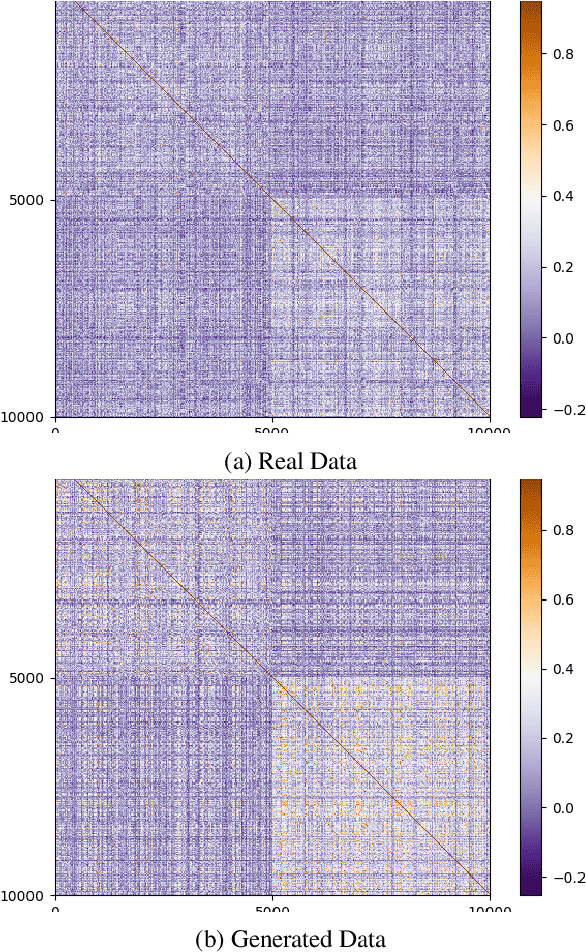
In this work, we present a text generation approach with multi-attribute control for data augmentation. We introduce CGA, a Variational Autoencoder architecture, to control, generate, and augment text. CGA is able to generate natural sentences with multiple controlled attributes by combining adversarial learning with a context-aware loss. The scalability of our approach is established through a single discriminator, independently of the number of attributes. As the main application of our work, we test the potential of this new model in a data augmentation use case. In a downstream NLP task, the sentences generated by our CGA model not only show significant improvements over a strong baseline, but also a classification performance very similar to real data. Furthermore, we are able to show high quality, diversity and attribute control in the generated sentences through a series of automatic and human assessments.
Improving BERT with Self-Supervised Attention
Apr 29, 2020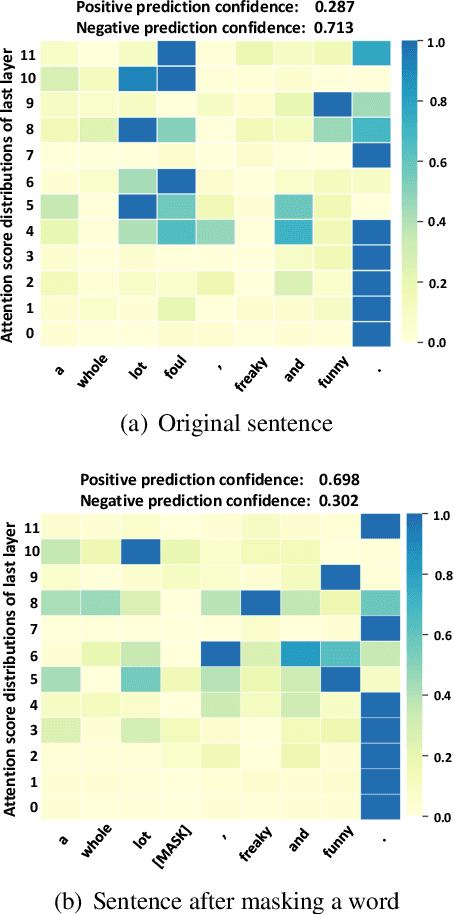
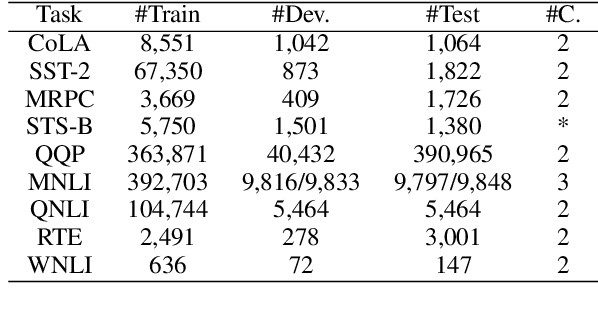
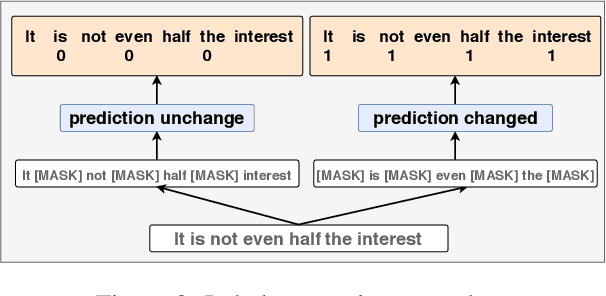
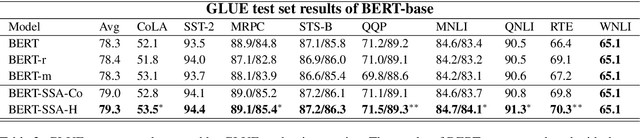
One of the most popular paradigms of applying large, pre-trained NLP models such as BERT is to fine-tune it on a smaller dataset. However, one challenge remains as the fine-tuned model often overfits on smaller datasets. A symptom of this phenomenon is that irrelevant words in the sentences, even when they are obvious to humans, can substantially degrade the performance of these fine-tuned BERT models. In this paper, we propose a novel technique, called Self-Supervised Attention (SSA) to help facilitate this generalization challenge. Specifically, SSA automatically generates weak, token-level attention labels iteratively by "probing" the fine-tuned model from the previous iteration. We investigate two different ways of integrating SSA into BERT and propose a hybrid approach to combine their benefits. Empirically, on a variety of public datasets, we illustrate significant performance improvement using our SSA-enhanced BERT model.
TrueBranch: Metric Learning-based Verification of Forest Conservation Projects
Apr 21, 2020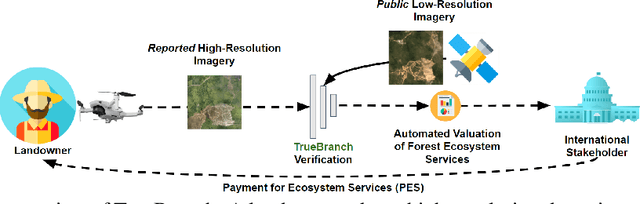
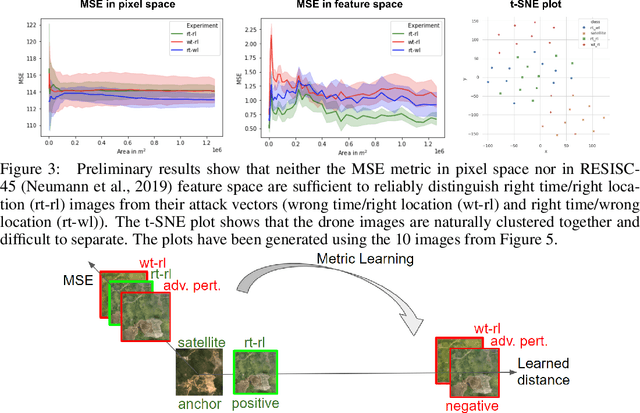

International stakeholders increasingly invest in offsetting carbon emissions, for example, via issuing Payments for Ecosystem Services (PES) to forest conservation projects. Issuing trusted payments requires a transparent monitoring, reporting, and verification (MRV) process of the ecosystem services (e.g., carbon stored in forests). The current MRV process, however, is either too expensive (on-ground inspection of forest) or inaccurate (satellite). Recent works propose low-cost and accurate MRV via automatically determining forest carbon from drone imagery, collected by the landowners. The automation of MRV, however, opens up the possibility that landowners report untruthful drone imagery. To be robust against untruthful reporting, we propose TrueBranch, a metric learning-based algorithm that verifies the truthfulness of drone imagery from forest conservation projects. TrueBranch aims to detect untruthfully reported drone imagery by matching it with public satellite imagery. Preliminary results suggest that nominal distance metrics are not sufficient to reliably detect untruthfully reported imagery. TrueBranch leverages metric learning to create a feature embedding in which truthfully and untruthfully collected imagery is easily distinguishable by distance thresholding.
Provable Robust Learning Based on Transformation-Specific Smoothing
Mar 20, 2020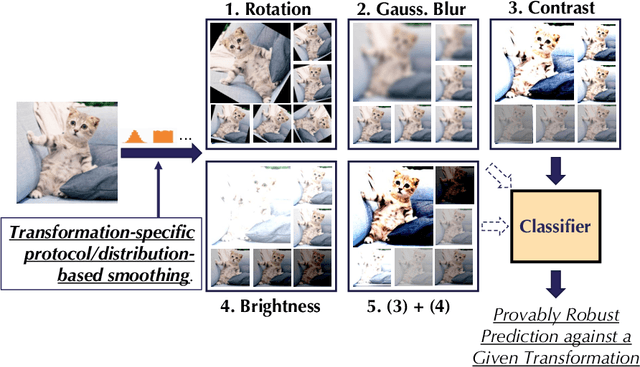

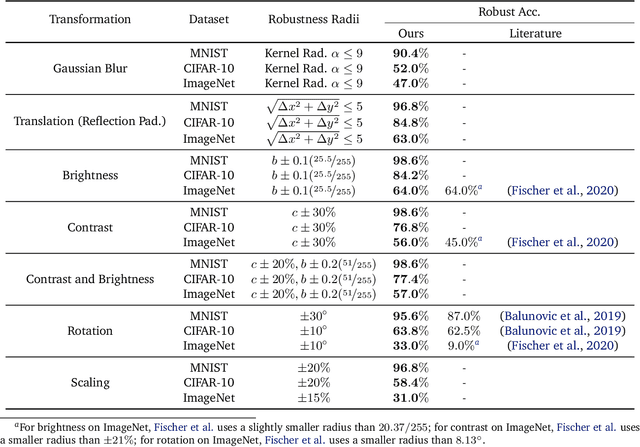
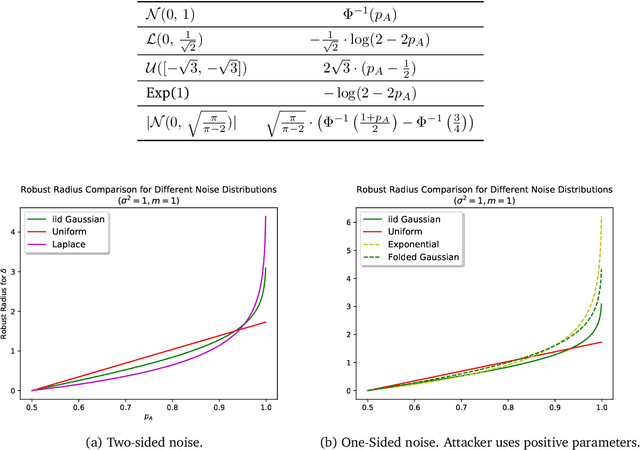
As machine learning systems become pervasive, safeguarding their security is critical. Recent work has demonstrated that motivated adversaries could manipulate the test data to mislead ML systems to make arbitrary mistakes. So far, most research has focused on providing provable robustness guarantees for a specific $\ell_p$ norm bounded adversarial perturbation. However, in practice there are more adversarial transformations that are realistic and of semantic meaning, requiring to be analyzed and ideally certified. In this paper we aim to provide a unified framework for certifying ML model robustness against general adversarial transformations. First, we leverage the function smoothing strategy to certify robustness against a series of adversarial transformations such as rotation, translation, Gaussian blur, etc. We then provide sufficient conditions and strategies for certifying certain transformations. For instance, we propose a novel sampling based interpolation approach with the estimated Lipschitz upper bound to certify the robustness against rotation transformation. In addition, we theoretically optimize the smoothing strategies for certifying the robustness of ML models against different transformations. For instance, we show that smoothing by sampling from exponential distribution provides tighter robustness bound than Gaussian. We also prove two generalization gaps for the proposed framework to understand its theoretic barrier. Extensive experiments show that our proposed unified framework significantly outperforms the state-of-the-art certified robustness approaches on several datasets including ImageNet.
RAB: Provable Robustness Against Backdoor Attacks
Mar 19, 2020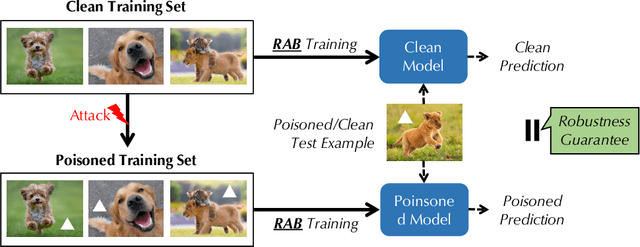
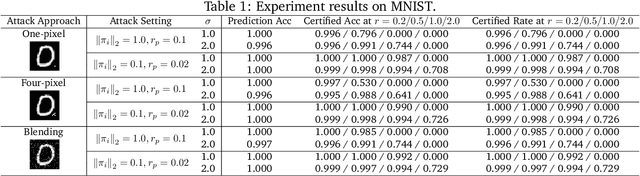
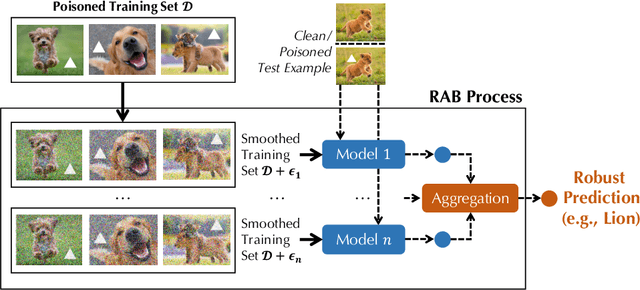
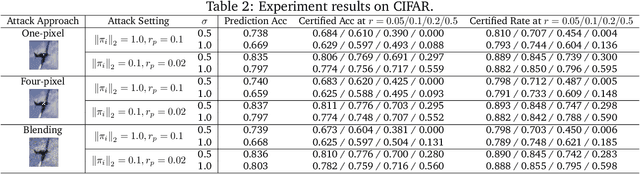
Recent studies have shown that deep neural networks (DNNs) are vulnerable to various attacks, including evasion attacks and poisoning attacks. On the defense side, there have been intensive interests in provable robustness against evasion attacks. In this paper, we focus on improving model robustness against more diverse threat models. Specifically, we provide the first unified framework using smoothing functional to certify the model robustness against general adversarial attacks. In particular, we propose the first robust training process RAB to certify against backdoor attacks. We theoretically prove the robustness bound for machine learning models based on the RAB training process, analyze the tightness of the robustness bound, as well as proposing different smoothing noise distributions such as Gaussian and Uniform distributions. Moreover, we evaluate the certified robustness of a family of "smoothed" DNNs which are trained in a differentially private fashion. In addition, we theoretically show that for simpler models such as K-nearest neighbor models, it is possible to train the robust smoothed models efficiently. For K=1, we propose an exact algorithm to smooth the training process, eliminating the need to sample from a noise distribution.Empirically, we conduct comprehensive experiments for different machine learning models such as DNNs, differentially private DNNs, and KNN models on MNIST, CIFAR-10 and ImageNet datasets to provide the first benchmark for certified robustness against backdoor attacks. In particular, we also evaluate KNN models on a spambase tabular dataset to demonstrate its advantages. Both the theoretic analysis for certified model robustness against arbitrary backdoors, and the comprehensive benchmark on diverse ML models and datasets would shed light on further robust learning strategies against training time or even general adversarial attacks on ML models.