 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposable Function-preserving Expansions for Transformer Architectures
Aug 11, 2023Training state-of-the-art neural networks requires a high cost in terms of compute and time. Model scale is recognized to be a critical factor to achieve and improve the state-of-the-art. Increasing the scale of a neural network normally requires restarting from scratch by randomly initializing all the parameters of the model, as this implies a change of architecture's parameters that does not allow for a straightforward transfer of knowledge from smaller size models. In this work, we propose six composable transformations to incrementally increase the size of transformer-based neural networks while preserving functionality, allowing to expand the capacity of the model as needed. We provide proof of exact function preservation under minimal initialization constraints for each transformation. The proposed methods may enable efficient training pipelines for larger and more powerful models by progressively expanding the architecture throughout training.
Multipath agents for modular multitask ML systems
Feb 06, 2023A standard ML model is commonly generated by a single method that specifies aspects such as architecture, initialization, training data and hyperparameters configuration. The presented work introduces a novel methodology allowing to define multiple methods as distinct agents. Agents can collaborate and compete to generate and improve ML models for a given tasks. The proposed methodology is demonstrated with the generation and extension of a dynamic modular multitask ML system solving more than one hundred image classification tasks. Diverse agents can compete to produce the best performing model for a task by reusing the modules introduced to the system by competing agents. The presented work focuses on the study of agents capable of: 1) reusing the modules generated by concurrent agents, 2) activating in parallel multiple modules in a frozen state by connecting them with trainable modules, 3) condition the activation mixture on each data sample by using a trainable router module. We demonstrate that this simple per-sample parallel routing method can boost the quality of the combined solutions by training a fraction of the activated parameters.
A Multi-Agent Framework for the Asynchronous and Collaborative Extension of Multitask ML Systems
Sep 29, 2022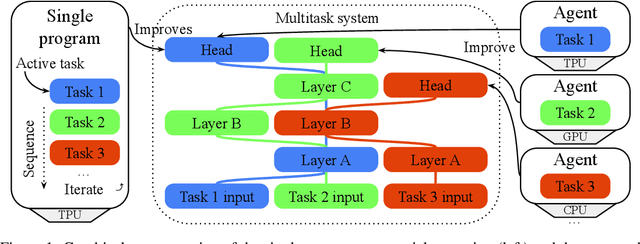
Tradition ML development methodology does not enable a large number of contributors, each with distinct objectives, to work collectively on the creation and extension of a shared intelligent system. Enabling such a collaborative methodology can accelerate the rate of innovation, increase ML technologies accessibility and enable the emergence of novel capabilities. We believe that this can be achieved through the definition of abstraction boundaries and a modularized representation of ML models and methods. We present a multi-agent framework for collaborative and asynchronous extension of dynamic large-scale multitask intelligent systems.
A Continual Development Methodology for Large-scale Multitask Dynamic ML Systems
Sep 15, 2022
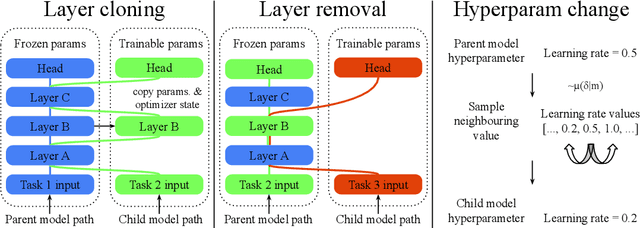
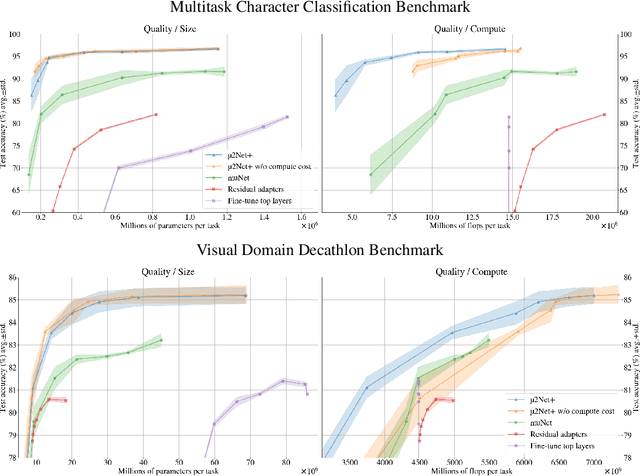
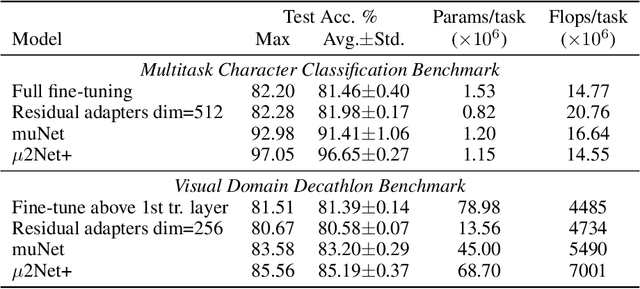
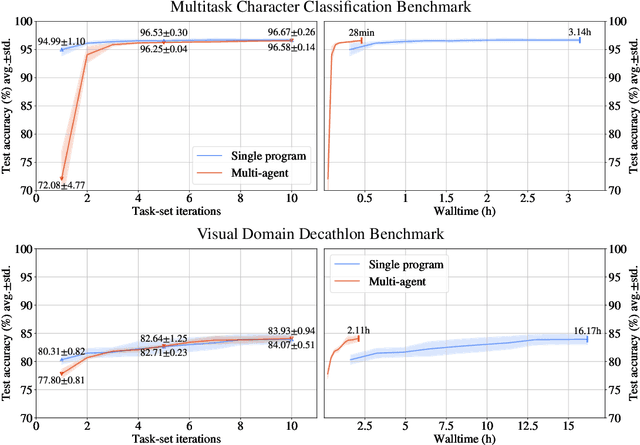
The traditional Machine Learning (ML) methodology requires to fragment the development and experimental process into disconnected iterations whose feedback is used to guide design or tuning choices. This methodology has multiple efficiency and scalability disadvantages, such as leading to spend significant resources into the creation of multiple trial models that do not contribute to the final solution.The presented work is based on the intuition that defining ML models as modular and extensible artefacts allows to introduce a novel ML development methodology enabling the integration of multiple design and evaluation iterations into the continuous enrichment of a single unbounded intelligent system. We define a novel method for the generation of dynamic multitask ML models as a sequence of extensions and generalizations. We first analyze the capabilities of the proposed method by using the standard ML empirical evaluation methodology. Finally, we propose a novel continuous development methodology that allows to dynamically extend a pre-existing multitask large-scale ML system while analyzing the properties of the proposed method extensions. This results in the generation of an ML model capable of jointly solving 124 image classification tasks achieving state of the art quality with improved size and compute cost.
An Evolutionary Approach to Dynamic Introduction of Tasks in Large-scale Multitask Learning Systems
Jun 05, 2022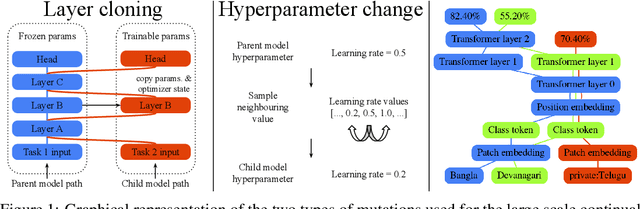


Multitask learning assumes that models capable of learning from multiple tasks can achieve better quality and efficiency via knowledge transfer, a key feature of human learning. Though, state of the art ML models rely on high customization for each task and leverage size and data scale rather than scaling the number of tasks. Also, continual learning, that adds the temporal aspect to multitask, is often focused to the study of common pitfalls such as catastrophic forgetting instead of being studied at a large scale as a critical component to build the next generation artificial intelligence. We propose an evolutionary method that can generate a large scale multitask model, and can support the dynamic and continuous addition of new tasks. The generated multitask model is sparsely activated and integrates a task-based routing that guarantees bounded compute cost and fewer added parameters per task as the model expands. The proposed method relies on a knowledge compartmentalization technique to achieve immunity against catastrophic forgetting and other common pitfalls such as gradient interference and negative transfer. We empirically show that the proposed method can jointly solve and achieve competitive results on 69image classification tasks, for example achieving the best test accuracy reported fora model trained only on public data for competitive tasks such as cifar10: 99.43%.
muNet: Evolving Pretrained Deep Neural Networks into Scalable Auto-tuning Multitask Systems
May 25, 2022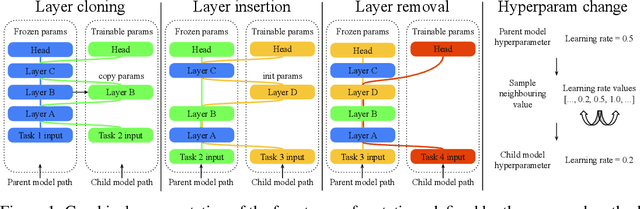
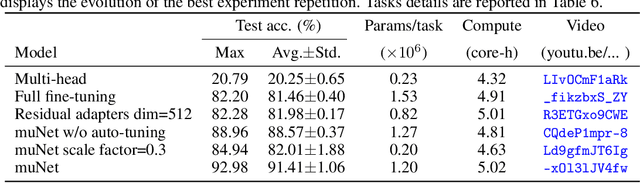
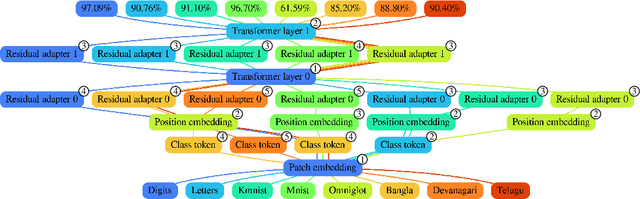
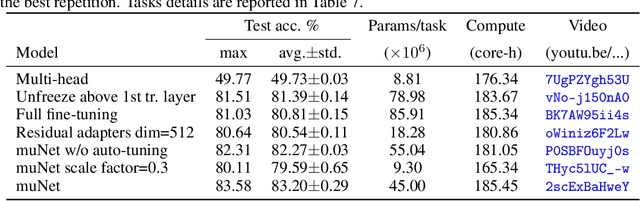
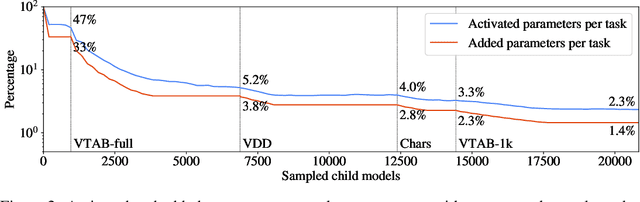
Most uses of machine learning today involve training a model from scratch for a particular task, or sometimes starting with a model pretrained on a related task and then fine-tuning on a downstream task. Both approaches offer limited knowledge transfer between different tasks, time-consuming human-driven customization to individual tasks and high computational costs especially when starting from randomly initialized models. We propose a method that uses the layers of a pretrained deep neural network as building blocks to construct an ML system that can jointly solve an arbitrary number of tasks. The resulting system can leverage cross tasks knowledge transfer, while being immune from common drawbacks of multitask approaches such as catastrophic forgetting, gradients interference and negative transfer. We define an evolutionary approach designed to jointly select the prior knowledge relevant for each task, choose the subset of the model parameters to train and dynamically auto-tune its hyperparameters. Furthermore, a novel scale control method is employed to achieve quality/size trade-offs that outperform common fine-tuning techniques. Compared with standard fine-tuning on a benchmark of 10 diverse image classification tasks, the proposed model improves the average accuracy by 2.39% while using 47% less parameters per task.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022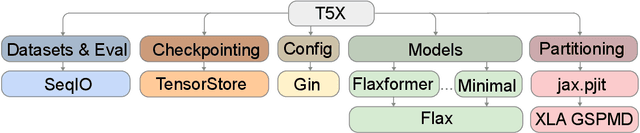
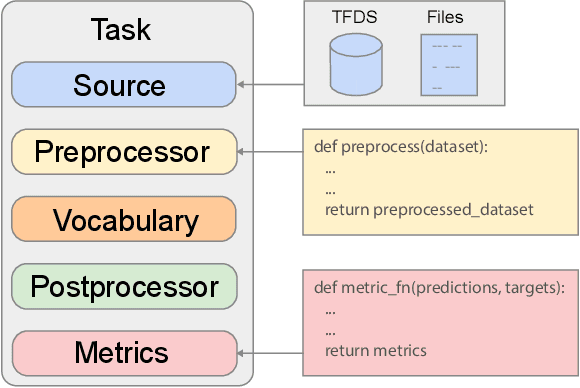
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Routing Networks with Co-training for Continual Learning
Sep 09, 2020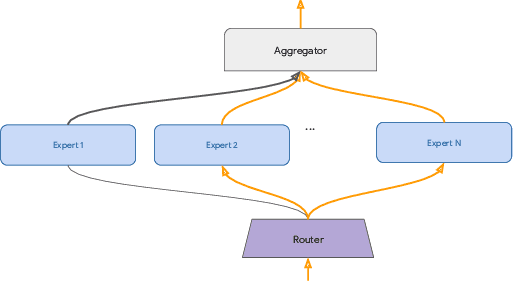

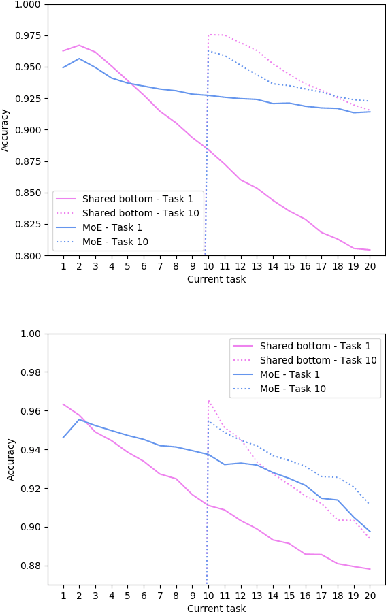
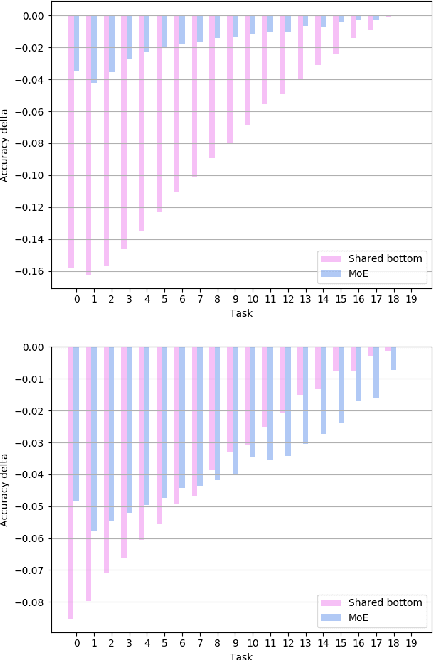
The core challenge with continual learning is catastrophic forgetting, the phenomenon that when neural networks are trained on a sequence of tasks they rapidly forget previously learned tasks. It has been observed that catastrophic forgetting is most severe when tasks are dissimilar to each other. We propose the use of sparse routing networks for continual learning. For each input, these network architectures activate a different path through a network of experts. Routing networks have been shown to learn to route similar tasks to overlapping sets of experts and dissimilar tasks to disjoint sets of experts. In the continual learning context this behaviour is desirable as it minimizes interference between dissimilar tasks while allowing positive transfer between related tasks. In practice, we find it is necessary to develop a new training method for routing networks, which we call co-training which avoids poorly initialized experts when new tasks are presented. When combined with a small episodic memory replay buffer, sparse routing networks with co-training outperform densely connected networks on the MNIST-Permutations and MNIST-Rotations benchmarks.
Ranking architectures using meta-learning
Nov 26, 2019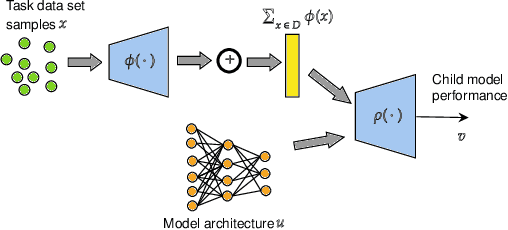
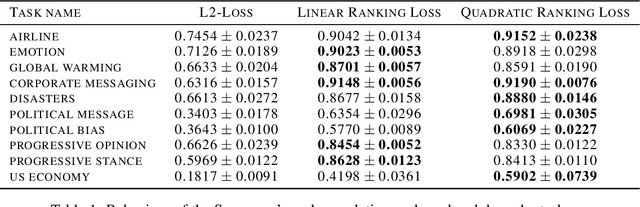
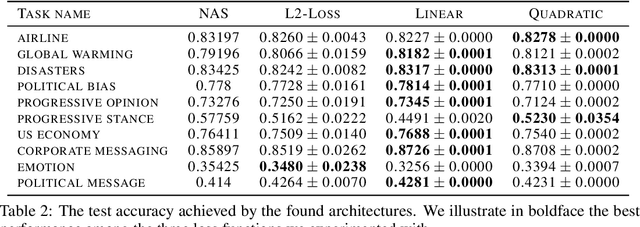
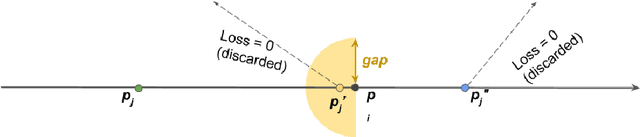
Neural architecture search has recently attracted lots of research efforts as it promises to automate the manual design of neural networks. However, it requires a large amount of computing resources and in order to alleviate this, a performance prediction network has been recently proposed that enables efficient architecture search by forecasting the performance of candidate architectures, instead of relying on actual model training. The performance predictor is task-aware taking as input not only the candidate architecture but also task meta-features and it has been designed to collectively learn from several tasks. In this work, we introduce a pairwise ranking loss for training a network able to rank candidate architectures for a new unseen task conditioning on its task meta-features. We present experimental results, showing that the ranking network is more effective in architecture search than the previously proposed performance predictor.
Gumbel-Matrix Routing for Flexible Multi-task Learning
Oct 10, 2019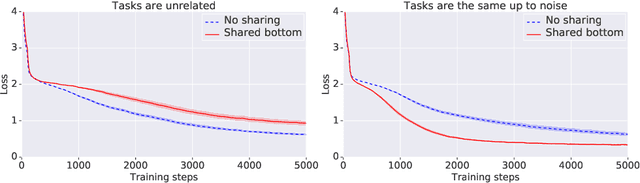

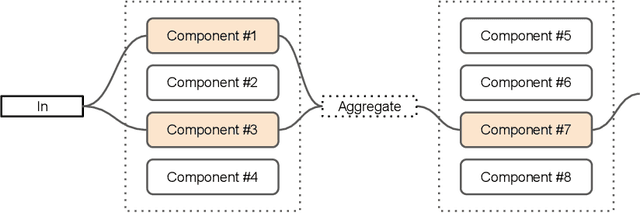
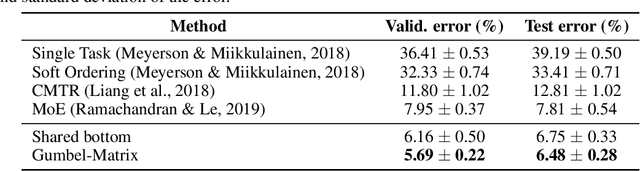
This paper proposes a novel per-task routing method for multi-task applications. Multi-task neural networks can learn to transfer knowledge across different tasks by using parameter sharing. However, sharing parameters between unrelated tasks can hurt performance. To address this issue, we advocate the use of routing networks to learn flexible parameter sharing, where each group of parameters is shared with a different subset of tasks in order to better leverage tasks relatedness. At the same time, it is known that routing networks are notoriously hard to train. We propose the Gumbel-Matrix routing: a novel multi-task routing method, designed to learn fine-grained patterns of parameter sharing. The routing is learned jointly with the model parameters by standard back-propagation thanks to the Gumbel-Softmax trick. When applied to the Omniglot benchmark, the proposed method reduces the state-of-the-art error rate by 17%.