 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoGameBench: Can Vision-Language Models complete popular video games?
May 23, 2025Vision-language models (VLMs) have achieved strong results on coding and math benchmarks that are challenging for humans, yet their ability to perform tasks that come naturally to humans--such as perception, spatial navigation, and memory management--remains understudied. Real video games are crafted to be intuitive for humans to learn and master by leveraging innate inductive biases, making them an ideal testbed for evaluating such capabilities in VLMs. To this end, we introduce VideoGameBench, a benchmark consisting of 10 popular video games from the 1990s that VLMs directly interact with in real-time. VideoGameBench challenges models to complete entire games with access to only raw visual inputs and a high-level description of objectives and controls, a significant departure from existing setups that rely on game-specific scaffolding and auxiliary information. We keep three of the games secret to encourage solutions that generalize to unseen environments. Our experiments show that frontier vision-language models struggle to progress beyond the beginning of each game. We find inference latency to be a major limitation of frontier models in the real-time setting; therefore, we introduce VideoGameBench Lite, a setting where the game pauses while waiting for the LM's next action. The best performing model, Gemini 2.5 Pro, completes only 0.48% of VideoGameBench and 1.6% of VideoGameBench Lite. We hope that the formalization of the human skills mentioned above into this benchmark motivates progress in these research directions.
Agent Context Protocols Enhance Collective Inference
May 20, 2025AI agents have become increasingly adept at complex tasks such as coding, reasoning, and multimodal understanding. However, building generalist systems requires moving beyond individual agents to collective inference -- a paradigm where multi-agent systems with diverse, task-specialized agents complement one another through structured communication and collaboration. Today, coordination is usually handled with imprecise, ad-hoc natural language, which limits complex interaction and hinders interoperability with domain-specific agents. We introduce Agent context protocols (ACPs): a domain- and agent-agnostic family of structured protocols for agent-agent communication, coordination, and error handling. ACPs combine (i) persistent execution blueprints -- explicit dependency graphs that store intermediate agent outputs -- with (ii) standardized message schemas, enabling robust and fault-tolerant multi-agent collective inference. ACP-powered generalist systems reach state-of-the-art performance: 28.3 % accuracy on AssistantBench for long-horizon web assistance and best-in-class multimodal technical reports, outperforming commercial AI systems in human evaluation. ACPs are highly modular and extensible, allowing practitioners to build top-tier generalist agents quickly.
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
Oct 04, 2024



Autonomous systems for software engineering are now capable of fixing bugs and developing features. These systems are commonly evaluated on SWE-bench (Jimenez et al., 2024a), which assesses their ability to solve software issues from GitHub repositories. However, SWE-bench uses only Python repositories, with problem statements presented predominantly as text and lacking visual elements such as images. This limited coverage motivates our inquiry into how existing systems might perform on unrepresented software engineering domains (e.g., front-end, game development, DevOps), which use different programming languages and paradigms. Therefore, we propose SWE-bench Multimodal (SWE-bench M), to evaluate systems on their ability to fix bugs in visual, user-facing JavaScript software. SWE-bench M features 617 task instances collected from 17 JavaScript libraries used for web interface design, diagramming, data visualization, syntax highlighting, and interactive mapping. Each SWE-bench M task instance contains at least one image in its problem statement or unit tests. Our analysis finds that top-performing SWE-bench systems struggle with SWE-bench M, revealing limitations in visual problem-solving and cross-language generalization. Lastly, we show that SWE-agent's flexible language-agnostic features enable it to substantially outperform alternatives on SWE-bench M, resolving 12% of task instances compared to 6% for the next best system.
Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction and Intrinsic Motivation
May 31, 2016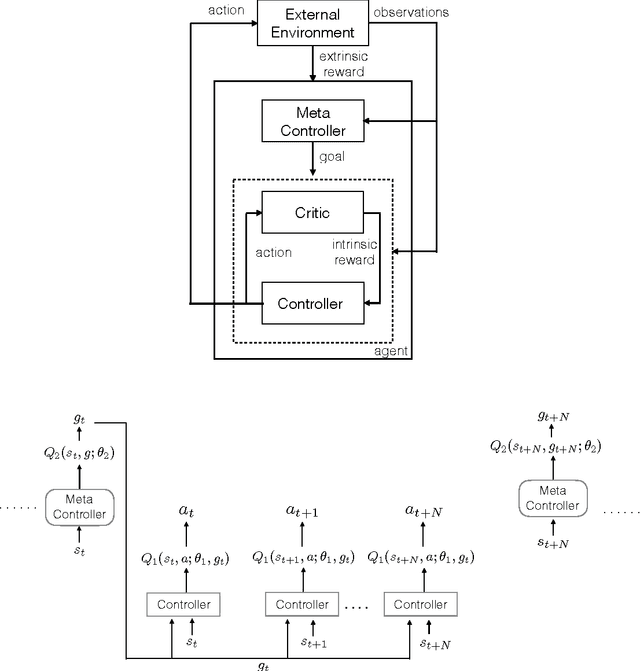
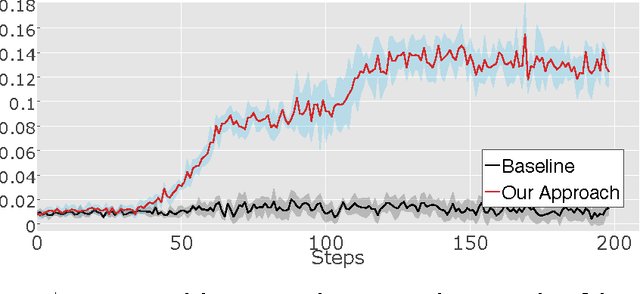
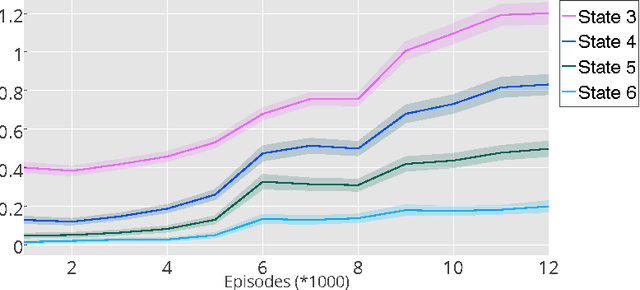
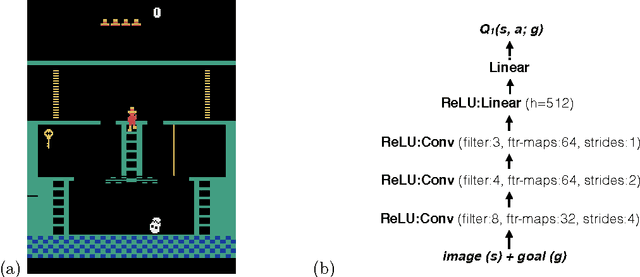
Learning goal-directed behavior in environments with sparse feedback is a major challenge for reinforcement learning algorithms. The primary difficulty arises due to insufficient exploration, resulting in an agent being unable to learn robust value functions. Intrinsically motivated agents can explore new behavior for its own sake rather than to directly solve problems. Such intrinsic behaviors could eventually help the agent solve tasks posed by the environment. We present hierarchical-DQN (h-DQN), a framework to integrate hierarchical value functions, operating at different temporal scales, with intrinsically motivated deep reinforcement learning. A top-level value function learns a policy over intrinsic goals, and a lower-level function learns a policy over atomic actions to satisfy the given goals. h-DQN allows for flexible goal specifications, such as functions over entities and relations. This provides an efficient space for exploration in complicated environments. We demonstrate the strength of our approach on two problems with very sparse, delayed feedback: (1) a complex discrete stochastic decision process, and (2) the classic ATARI game `Montezuma's Revenge'.