 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Learning for Knowledge Distillation
Jun 08, 2021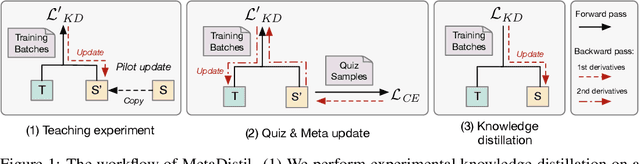
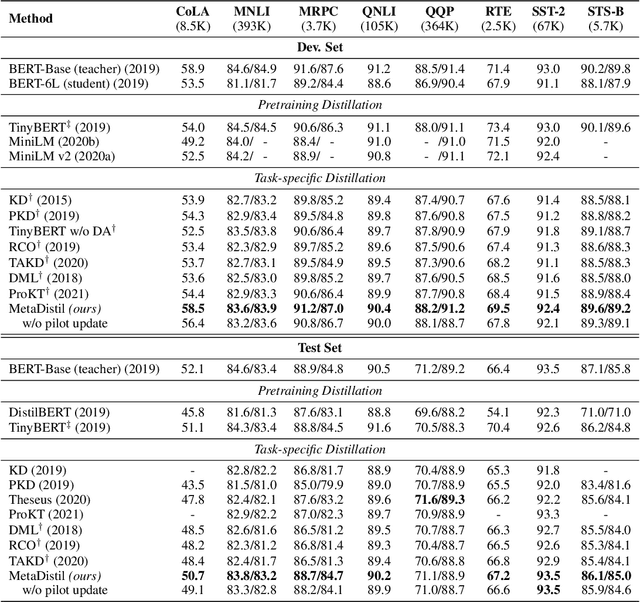
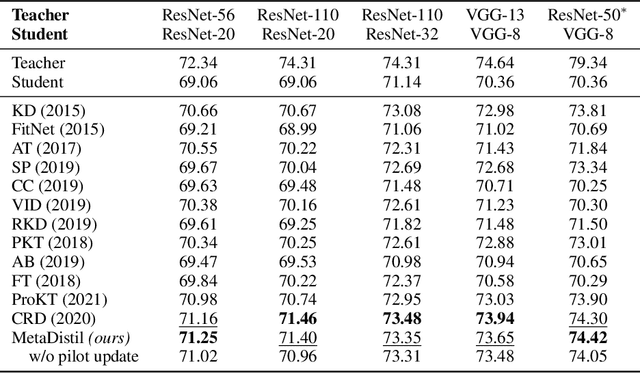
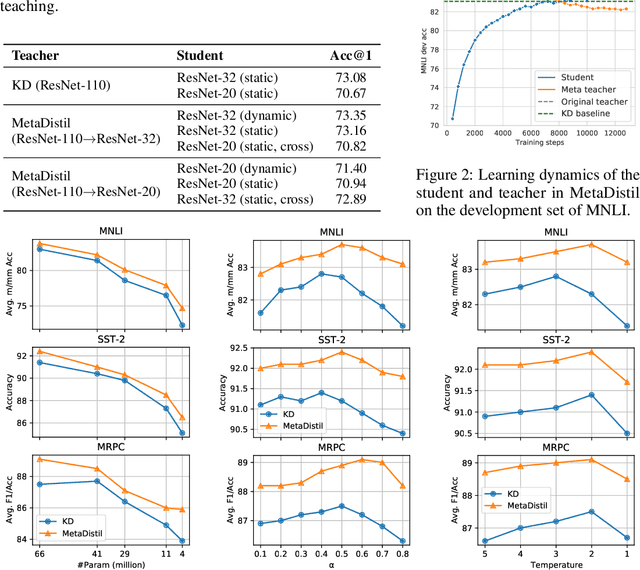
We present Meta Learning for Knowledge Distillation (MetaDistil), a simple yet effective alternative to traditional knowledge distillation (KD) methods where the teacher model is fixed during training. We show the teacher network can learn to better transfer knowledge to the student network (i.e., learning to teach) with the feedback from the performance of the distilled student network in a meta learning framework. Moreover, we introduce a pilot update mechanism to improve the alignment between the inner-learner and meta-learner in meta learning algorithms that focus on an improved inner-learner. Experiments on various benchmarks show that MetaDistil can yield significant improvements compared with traditional KD algorithms and is less sensitive to the choice of different student capacity and hyperparameters, facilitating the use of KD on different tasks and models. The code is available at https://github.com/JetRunner/MetaDistil
Blow the Dog Whistle: A Chinese Dataset for Cant Understanding with Common Sense and World Knowledge
Apr 06, 2021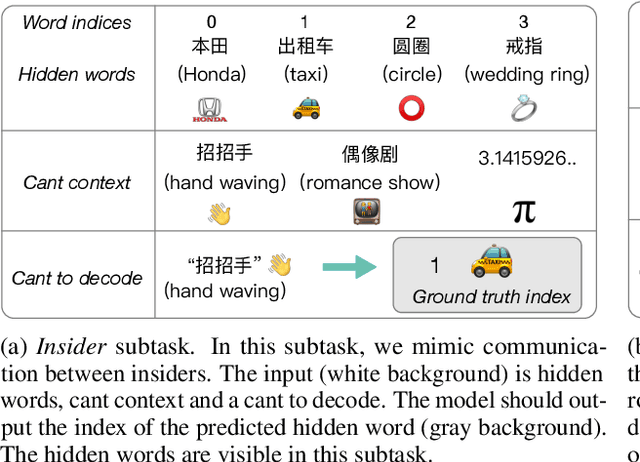
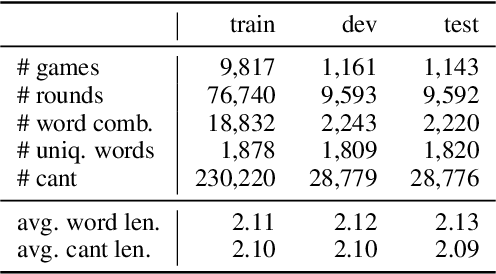
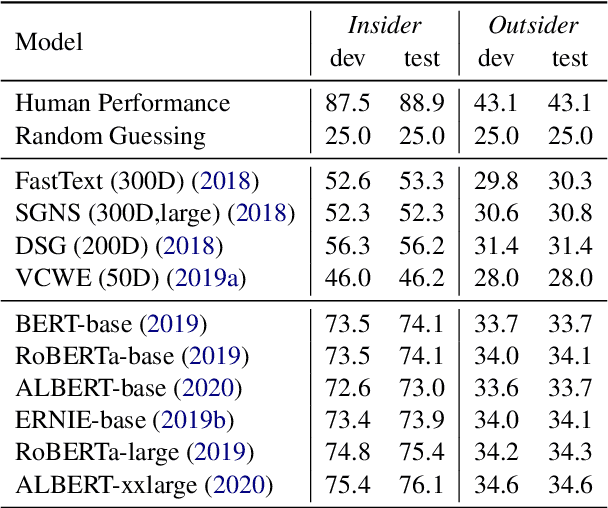
Cant is important for understanding advertising, comedies and dog-whistle politics. However, computational research on cant is hindered by a lack of available datasets. In this paper, we propose a large and diverse Chinese dataset for creating and understanding cant from a computational linguistics perspective. We formulate a task for cant understanding and provide both quantitative and qualitative analysis for tested word embedding similarity and pretrained language models. Experiments suggest that such a task requires deep language understanding, common sense, and world knowledge and thus can be a good testbed for pretrained language models and help models perform better on other tasks. The code is available at https://github.com/JetRunner/dogwhistle. The data and leaderboard are available at https://competitions.codalab.org/competitions/30451.
BERT Loses Patience: Fast and Robust Inference with Early Exit
Jun 29, 2020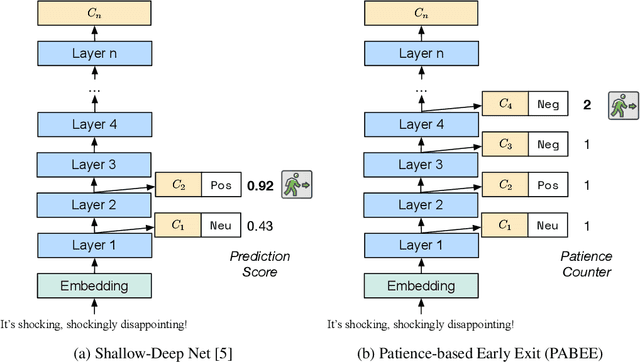
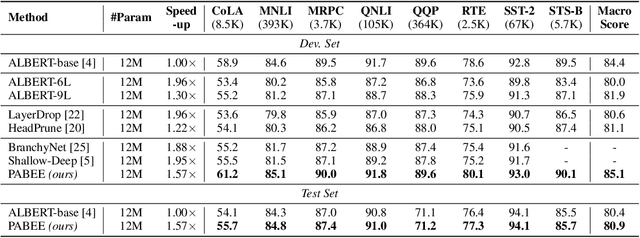
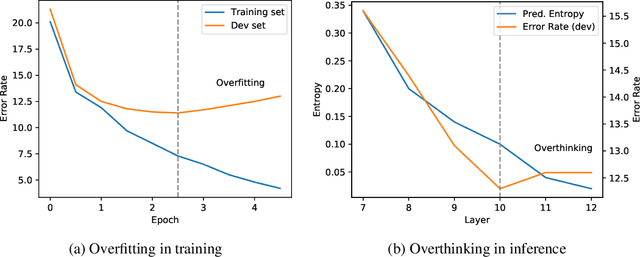
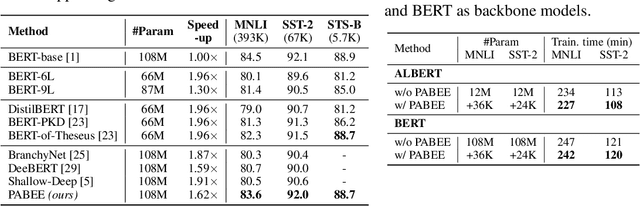
In this paper, we propose Patience-based Early Exit, a straightforward yet effective inference method that can be used as a plug-and-play technique to simultaneously improve the efficiency and robustness of a pretrained language model (PLM). To achieve this, our approach couples an internal-classifier with each layer of a PLM and dynamically stops inference when the intermediate predictions of the internal classifiers remain unchanged for a pre-defined number of steps. Our approach improves inference efficiency as it allows the model to make a prediction with fewer layers. Meanwhile, experimental results with an ALBERT model show that our method can improve the accuracy and robustness of the model by preventing it from overthinking and exploiting multiple classifiers for prediction, yielding a better accuracy-speed trade-off compared to existing early exit methods.
MATINF: A Jointly Labeled Large-Scale Dataset for Classification, Question Answering and Summarization
May 23, 2020
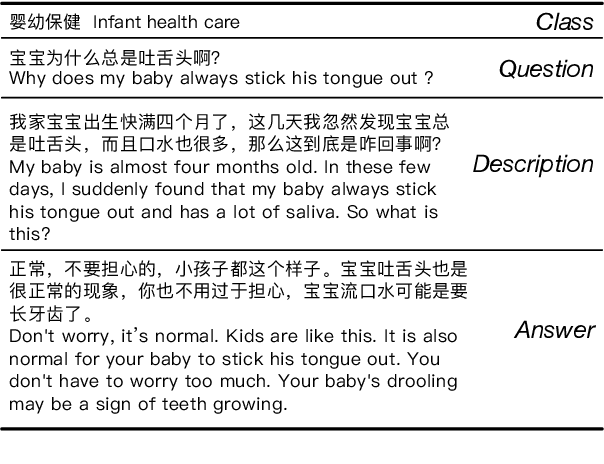
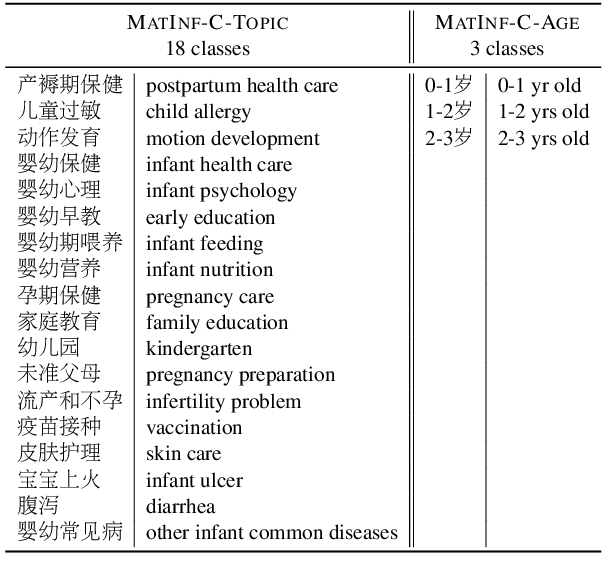
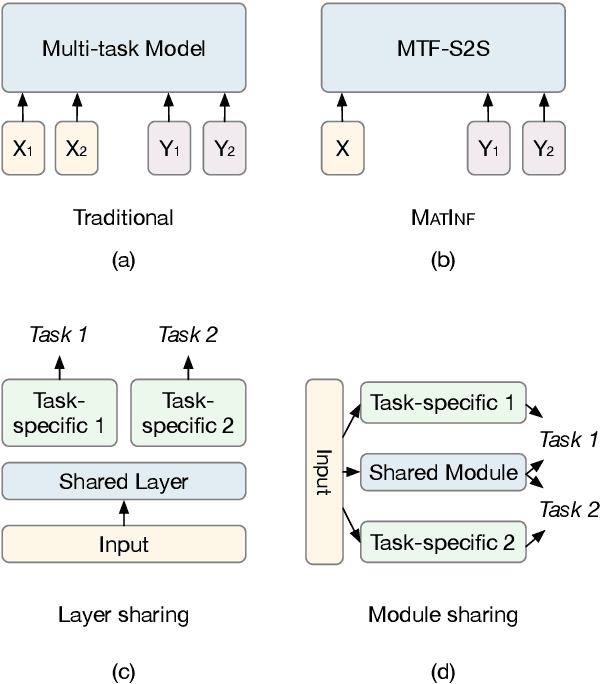
Recently, large-scale datasets have vastly facilitated the development in nearly all domains of Natural Language Processing. However, there is currently no cross-task dataset in NLP, which hinders the development of multi-task learning. We propose MATINF, the first jointly labeled large-scale dataset for classification, question answering and summarization. MATINF contains 1.07 million question-answer pairs with human-labeled categories and user-generated question descriptions. Based on such rich information, MATINF is applicable for three major NLP tasks, including classification, question answering, and summarization. We benchmark existing methods and a novel multi-task baseline over MATINF to inspire further research. Our comprehensive comparison and experiments over MATINF and other datasets demonstrate the merits held by MATINF.
BERT-of-Theseus: Compressing BERT by Progressive Module Replacing
Feb 10, 2020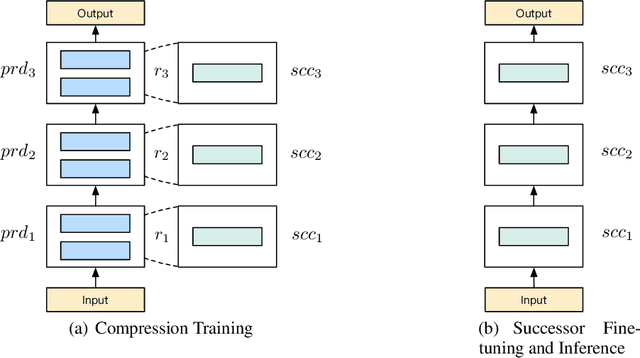

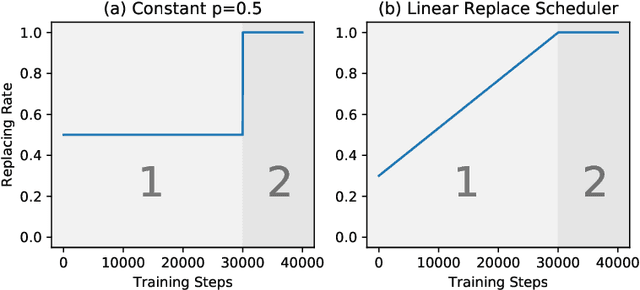
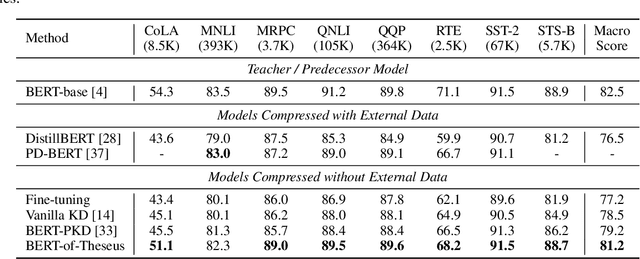
In this paper, we propose a novel model compression approach to effectively compress BERT by progressive module replacing. Our approach first divides the original BERT into several modules and builds their compact substitutes. Then, we randomly replace the original modules with their substitutes to train the compact modules to mimic the behavior of the original modules. We progressively increase the probability of replacement through the training. In this way, our approach brings a deeper level of interaction between the original and compact models, and smooths the training process. Compared to the previous knowledge distillation approaches for BERT compression, our approach leverages only one loss function and one hyper-parameter, liberating human effort from hyper-parameter tuning. Our approach outperforms existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression.
Pre-train and Plug-in: Flexible Conditional Text Generation with Variational Auto-Encoders
Nov 10, 2019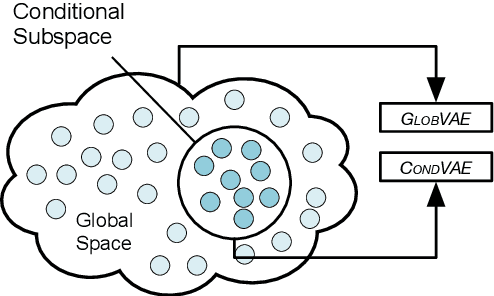
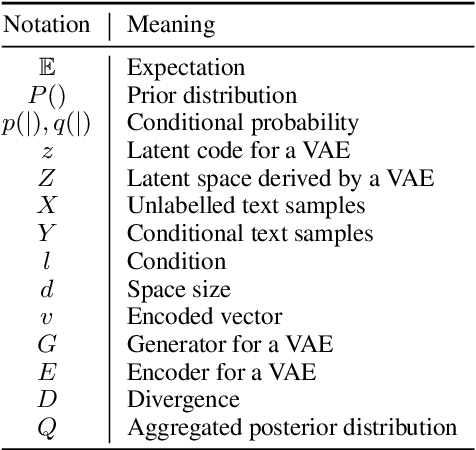
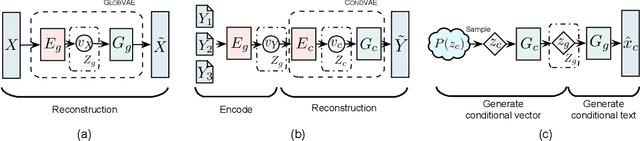

Current neural Natural Language Generation (NLG) models cannot handle emerging conditions due to their joint end-to-end learning fashion. When the need for generating text under a new condition emerges, these techniques require not only sufficiently supplementary labeled data but also a full re-training of the existing model. In this paper, we present a new framework named Hierarchical Neural Auto-Encoder (HAE) toward flexible conditional text generation. HAE decouples the text generation module from the condition representation module to allow "one-to-many" conditional generation. When a fresh condition emerges, only a lightweight network needs to be trained and works as a plug-in for HAE, which is efficient and desirable for real-world applications. Extensive experiments demonstrate the superiority of HAE against the existing alternatives with much less training time and fewer model parameters.
Exploiting Multiple Embeddings for Chinese Named Entity Recognition
Aug 28, 2019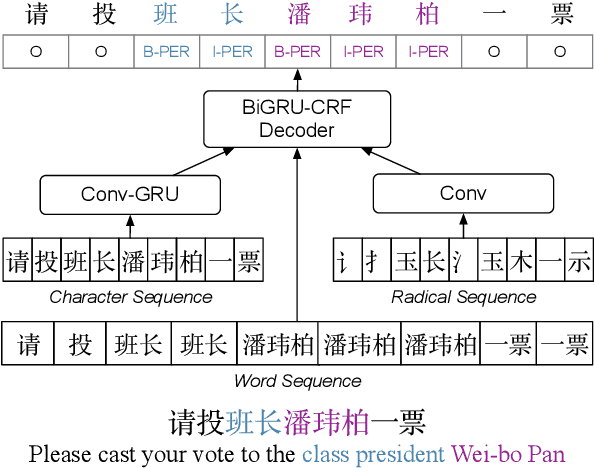
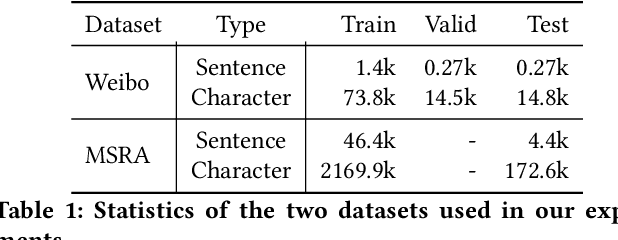
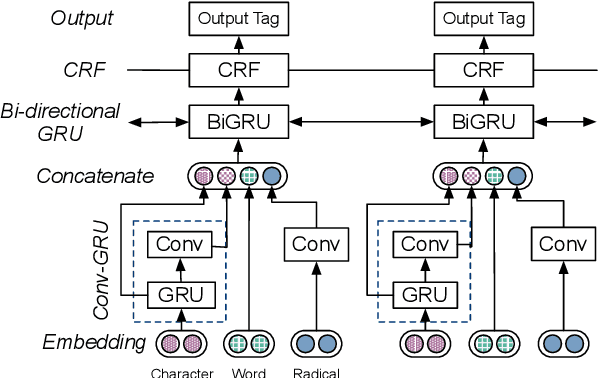
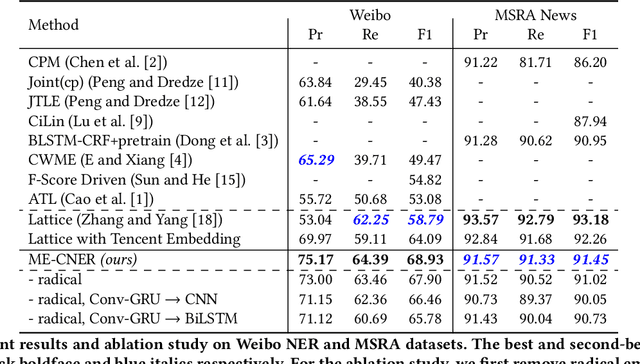
Identifying the named entities mentioned in text would enrich many semantic applications at the downstream level. However, due to the predominant usage of colloquial language in microblogs, the named entity recognition (NER) in Chinese microblogs experience significant performance deterioration, compared with performing NER in formal Chinese corpus. In this paper, we propose a simple yet effective neural framework to derive the character-level embeddings for NER in Chinese text, named ME-CNER. A character embedding is derived with rich semantic information harnessed at multiple granularities, ranging from radical, character to word levels. The experimental results demonstrate that the proposed approach achieves a large performance improvement on Weibo dataset and comparable performance on MSRA news dataset with lower computational cost against the existing state-of-the-art alternatives.
Obj-GloVe: Scene-Based Contextual Object Embedding
Jul 02, 2019
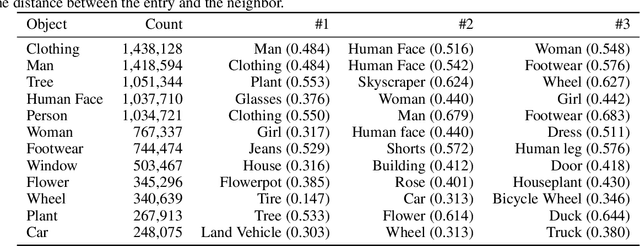

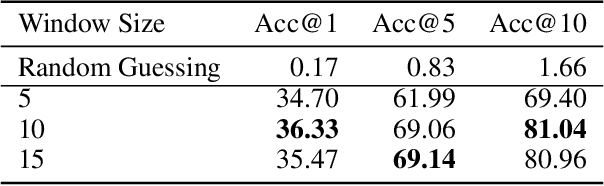
Recently, with the prevalence of large-scale image dataset, the co-occurrence information among classes becomes rich, calling for a new way to exploit it to facilitate inference. In this paper, we propose Obj-GloVe, a generic scene-based contextual embedding for common visual objects, where we adopt the word embedding method GloVe to exploit the co-occurrence between entities. We train the embedding on pre-processed Open Images V4 dataset and provide extensive visualization and analysis by dimensionality reduction and projecting the vectors along a specific semantic axis, and showcasing the nearest neighbors of the most common objects. Furthermore, we reveal the potential applications of Obj-GloVe on object detection and text-to-image synthesis, then verify its effectiveness on these two applications respectively.
DLocRL: A Deep Learning Pipeline for Fine-Grained Location Recognition and Linking in Tweets
Jan 24, 2019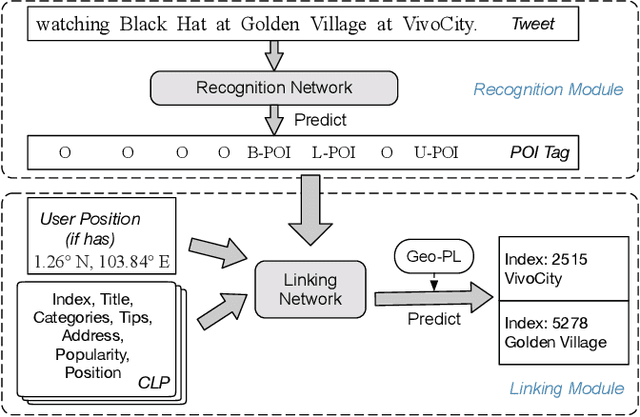
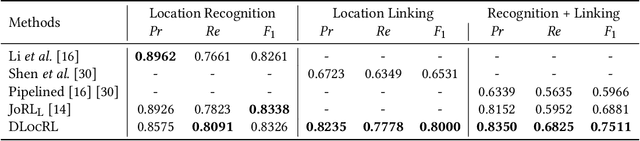
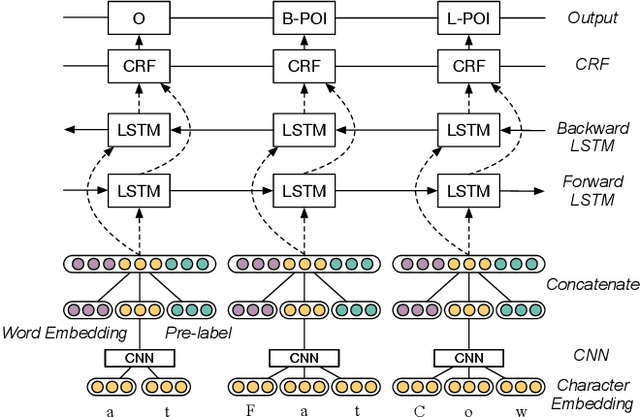
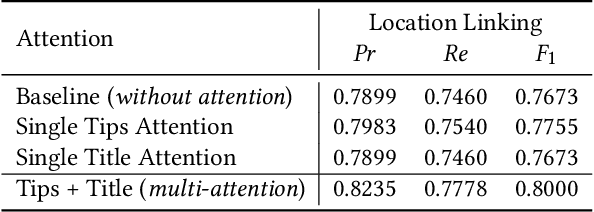
In recent years, with the prevalence of social media and smart devices, people causally reveal their locations such as shops, hotels, and restaurants in their tweets. Recognizing and linking such fine-grained location mentions to well-defined location profiles are beneficial for retrieval and recommendation systems. Prior studies heavily rely on hand-crafted linguistic features. Recently, deep learning has shown its effectiveness in feature representation learning for many NLP tasks. In this paper, we propose DLocRL, a new Deep pipeline for fine-grained Location Recognition and Linking in tweets. DLocRL leverages representation learning, semantic composition, attention and gate mechanisms to exploit semantic context features for location recognition and linking. Furthermore, a novel post-processing strategy, named Geographical Pair Linking, is developed to improve the linking performance. In this way, DLocRL does not require hand-crafted features. The experimental results show the effectiveness of DLocRL on fine-grained location recognition and linking with a real-world Twitter dataset.