 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObj-GloVe: Scene-Based Contextual Object Embedding
Paper and Code
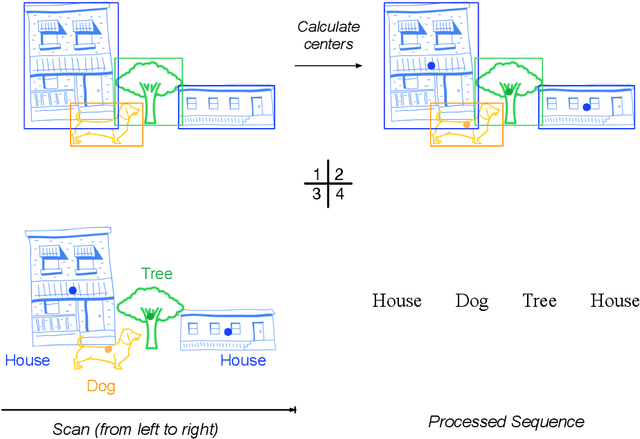
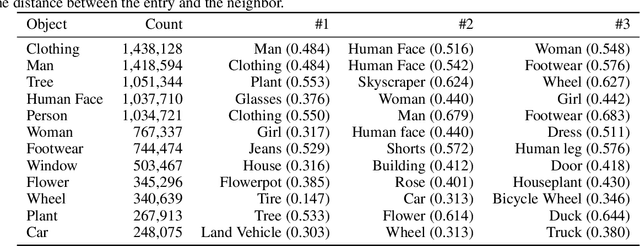

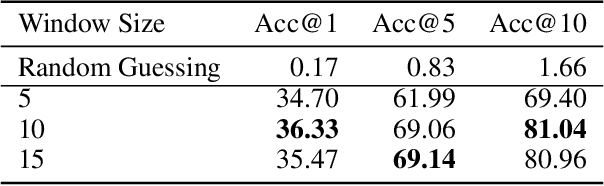
Recently, with the prevalence of large-scale image dataset, the co-occurrence information among classes becomes rich, calling for a new way to exploit it to facilitate inference. In this paper, we propose Obj-GloVe, a generic scene-based contextual embedding for common visual objects, where we adopt the word embedding method GloVe to exploit the co-occurrence between entities. We train the embedding on pre-processed Open Images V4 dataset and provide extensive visualization and analysis by dimensionality reduction and projecting the vectors along a specific semantic axis, and showcasing the nearest neighbors of the most common objects. Furthermore, we reveal the potential applications of Obj-GloVe on object detection and text-to-image synthesis, then verify its effectiveness on these two applications respectively.