 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERT-of-Theseus: Compressing BERT by Progressive Module Replacing
Paper and Code
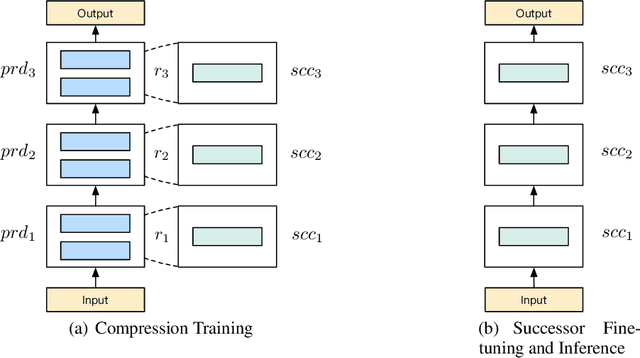

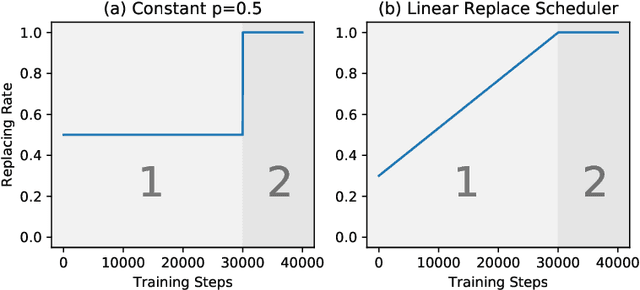
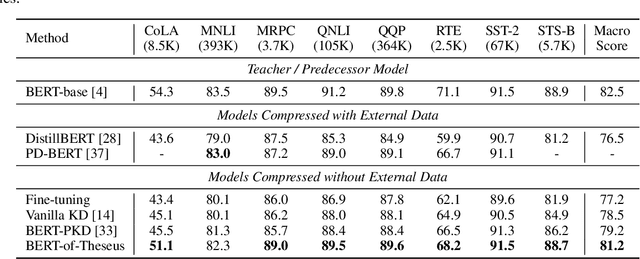
In this paper, we propose a novel model compression approach to effectively compress BERT by progressive module replacing. Our approach first divides the original BERT into several modules and builds their compact substitutes. Then, we randomly replace the original modules with their substitutes to train the compact modules to mimic the behavior of the original modules. We progressively increase the probability of replacement through the training. In this way, our approach brings a deeper level of interaction between the original and compact models, and smooths the training process. Compared to the previous knowledge distillation approaches for BERT compression, our approach leverages only one loss function and one hyper-parameter, liberating human effort from hyper-parameter tuning. Our approach outperforms existing knowledge distillation approaches on GLUE benchmark, showing a new perspective of model compression.