 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSource-free Depth for Object Pop-out
Dec 10, 2022



Depth cues are known to be useful for visual perception. However, direct measurement of depth is often impracticable. Fortunately, though, modern learning-based methods offer promising depth maps by inference in the wild. In this work, we adapt such depth inference models for object segmentation using the objects' ``pop-out'' prior in 3D. The ``pop-out'' is a simple composition prior that assumes objects reside on the background surface. Such compositional prior allows us to reason about objects in the 3D space. More specifically, we adapt the inferred depth maps such that objects can be localized using only 3D information. Such separation, however, requires knowledge about contact surface which we learn using the weak supervision of the segmentation mask. Our intermediate representation of contact surface, and thereby reasoning about objects purely in 3D, allows us to better transfer the depth knowledge into semantics. The proposed adaptation method uses only the depth model without needing the source data used for training, making the learning process efficient and practical. Our experiments on eight datasets of two challenging tasks, namely camouflaged object detection and salient object detection, consistently demonstrate the benefit of our method in terms of both performance and generalizability.
RGB-Event Fusion for Moving Object Detection in Autonomous Driving
Sep 17, 2022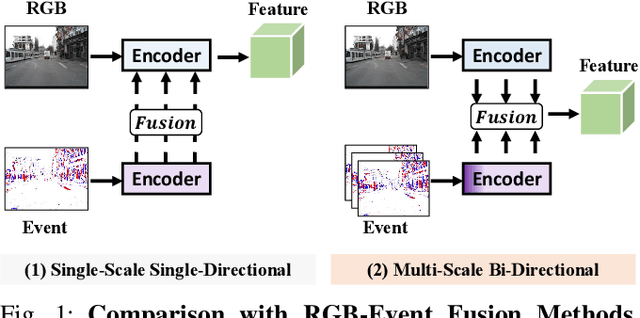
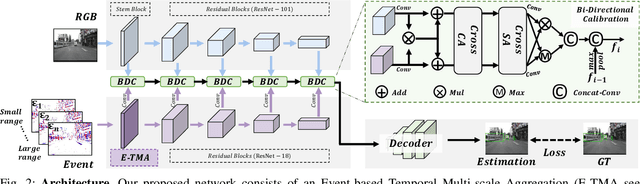
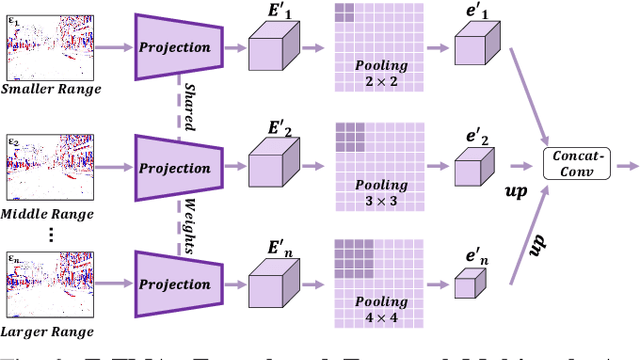
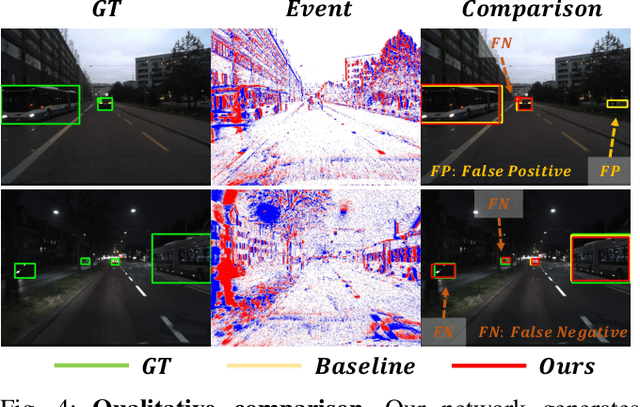
Moving Object Detection (MOD) is a critical vision task for successfully achieving safe autonomous driving. Despite plausible results of deep learning methods, most existing approaches are only frame-based and may fail to reach reasonable performance when dealing with dynamic traffic participants. Recent advances in sensor technologies, especially the Event camera, can naturally complement the conventional camera approach to better model moving objects. However, event-based works often adopt a pre-defined time window for event representation, and simply integrate it to estimate image intensities from events, neglecting much of the rich temporal information from the available asynchronous events. Therefore, from a new perspective, we propose RENet, a novel RGB-Event fusion Network, that jointly exploits the two complementary modalities to achieve more robust MOD under challenging scenarios for autonomous driving. Specifically, we first design a temporal multi-scale aggregation module to fully leverage event frames from both the RGB exposure time and larger intervals. Then we introduce a bi-directional fusion module to attentively calibrate and fuse multi-modal features. To evaluate the performance of our network, we carefully select and annotate a sub-MOD dataset from the commonly used DSEC dataset. Extensive experiments demonstrate that our proposed method performs significantly better than the state-of-the-art RGB-Event fusion alternatives.
Robust RGB-D Fusion for Saliency Detection
Aug 02, 2022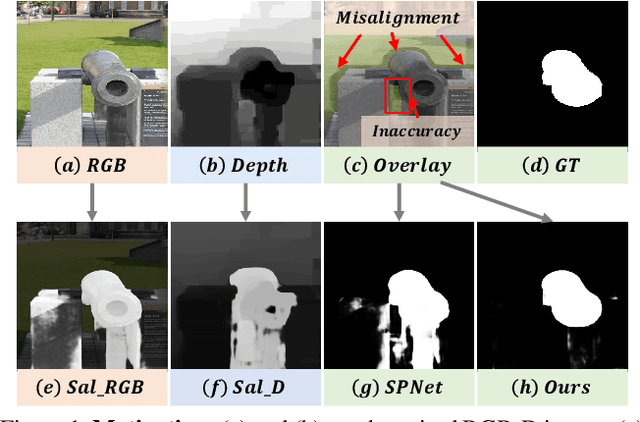
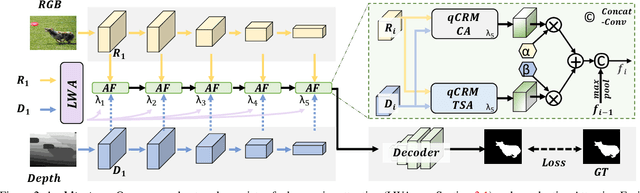

Efficiently exploiting multi-modal inputs for accurate RGB-D saliency detection is a topic of high interest. Most existing works leverage cross-modal interactions to fuse the two streams of RGB-D for intermediate features' enhancement. In this process, a practical aspect of the low quality of the available depths has not been fully considered yet. In this work, we aim for RGB-D saliency detection that is robust to the low-quality depths which primarily appear in two forms: inaccuracy due to noise and the misalignment to RGB. To this end, we propose a robust RGB-D fusion method that benefits from (1) layer-wise, and (2) trident spatial, attention mechanisms. On the one hand, layer-wise attention (LWA) learns the trade-off between early and late fusion of RGB and depth features, depending upon the depth accuracy. On the other hand, trident spatial attention (TSA) aggregates the features from a wider spatial context to address the depth misalignment problem. The proposed LWA and TSA mechanisms allow us to efficiently exploit the multi-modal inputs for saliency detection while being robust against low-quality depths. Our experiments on five benchmark datasets demonstrate that the proposed fusion method performs consistently better than the state-of-the-art fusion alternatives.
Depth-Adapted CNNs for RGB-D Semantic Segmentation
Jun 08, 2022
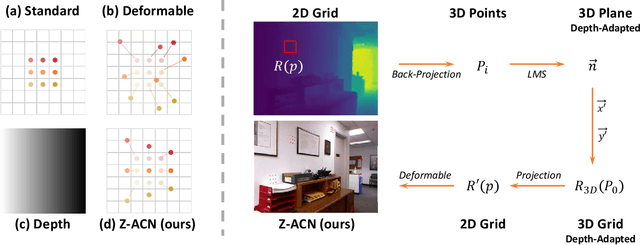
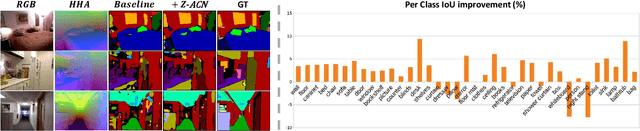
Recent RGB-D semantic segmentation has motivated research interest thanks to the accessibility of complementary modalities from the input side. Existing works often adopt a two-stream architecture that processes photometric and geometric information in parallel, with few methods explicitly leveraging the contribution of depth cues to adjust the sampling position on RGB images. In this paper, we propose a novel framework to incorporate the depth information in the RGB convolutional neural network (CNN), termed Z-ACN (Depth-Adapted CNN). Specifically, our Z-ACN generates a 2D depth-adapted offset which is fully constrained by low-level features to guide the feature extraction on RGB images. With the generated offset, we introduce two intuitive and effective operations to replace basic CNN operators: depth-adapted convolution and depth-adapted average pooling. Extensive experiments on both indoor and outdoor semantic segmentation tasks demonstrate the effectiveness of our approach.
N-QGN: Navigation Map from a Monocular Camera using Quadtree Generating Networks
Feb 24, 2022
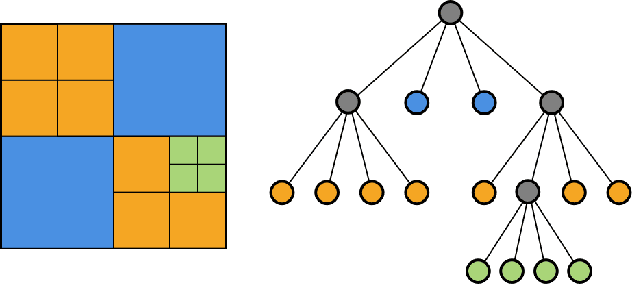
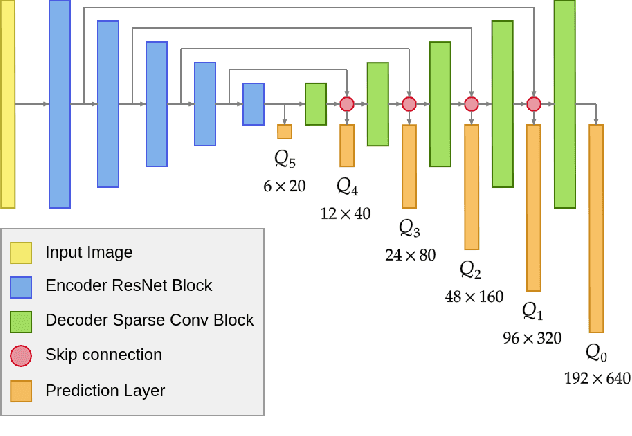
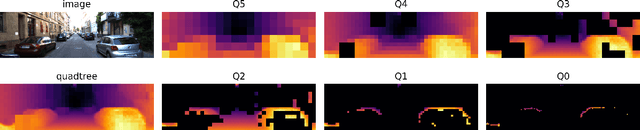
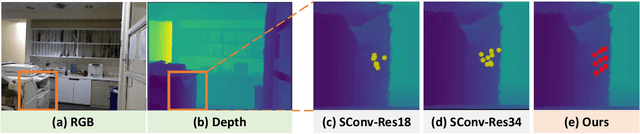
Monocular depth estimation has been a popular area of research for several years, especially since self-supervised networks have shown increasingly good results in bridging the gap with supervised and stereo methods. However, these approaches focus their interest on dense 3D reconstruction and sometimes on tiny details that are superfluous for autonomous navigation. In this paper, we propose to address this issue by estimating the navigation map under a quadtree representation. The objective is to create an adaptive depth map prediction that only extract details that are essential for the obstacle avoidance. Other 3D space which leaves large room for navigation will be provided with approximate distance. Experiment on KITTI dataset shows that our method can significantly reduce the number of output information without major loss of accuracy.
Modality-Guided Subnetwork for Salient Object Detection
Oct 25, 2021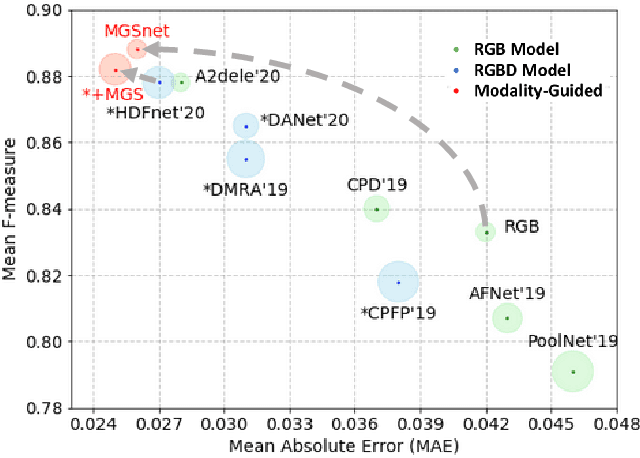
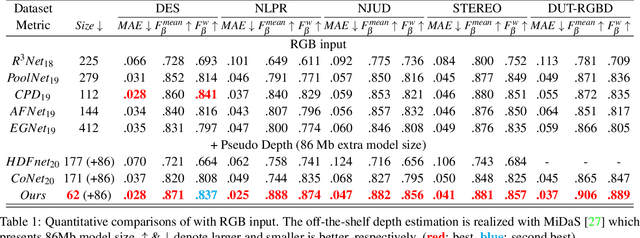
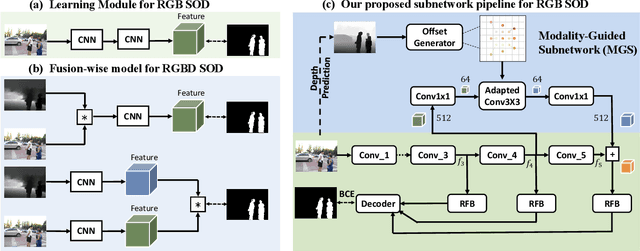
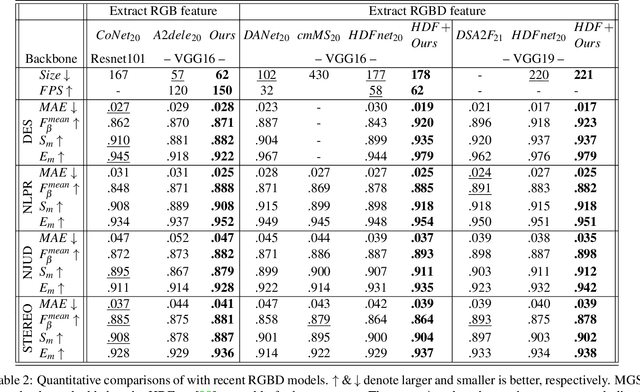
Recent RGBD-based models for saliency detection have attracted research attention. The depth clues such as boundary clues, surface normal, shape attribute, etc., contribute to the identification of salient objects with complicated scenarios. However, most RGBD networks require multi-modalities from the input side and feed them separately through a two-stream design, which inevitably results in extra costs on depth sensors and computation. To tackle these inconveniences, we present in this paper a novel fusion design named modality-guided subnetwork (MGSnet). It has the following superior designs: 1) Our model works for both RGB and RGBD data, and dynamically estimating depth if not available. Taking the inner workings of depth-prediction networks into account, we propose to estimate the pseudo-geometry maps from RGB input - essentially mimicking the multi-modality input. 2) Our MGSnet for RGB SOD results in real-time inference but achieves state-of-the-art performance compared to other RGB models. 3) The flexible and lightweight design of MGS facilitates the integration into RGBD two-streaming models. The introduced fusion design enables a cross-modality interaction to enable further progress but with a minimal cost.
Unsupervised Learning of Category-Specific Symmetric 3D Keypoints from Point Sets
Mar 17, 2020
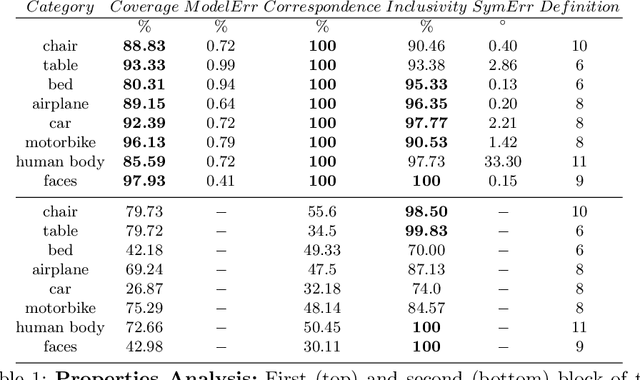
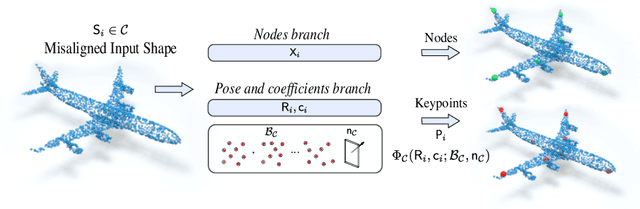
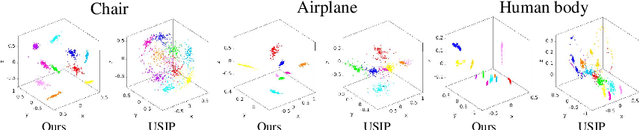
Automatic discovery of category-specific 3D keypoints from a collection of objects of some category is a challenging problem. One reason is that not all objects in a category necessarily have the same semantic parts. The level of difficulty adds up further when objects are represented by 3D point clouds, with variations in shape and unknown coordinate frames. We define keypoints to be category-specific, if they meaningfully represent objects' shape and their correspondences can be simply established order-wise across all objects. This paper aims at learning category-specific 3D keypoints, in an unsupervised manner, using a collection of misaligned 3D point clouds of objects from an unknown category. In order to do so, we model shapes defined by the keypoints, within a category, using the symmetric linear basis shapes without assuming the plane of symmetry to be known. The usage of symmetry prior leads us to learn stable keypoints suitable for higher misalignments. To the best of our knowledge, this is the first work on learning such keypoints directly from 3D point clouds. Using categories from four benchmark datasets, we demonstrate the quality of our learned keypoints by quantitative and qualitative evaluations. Our experiments also show that the keypoints discovered by our method are geometrically and semantically consistent.
What's in my Room? Object Recognition on Indoor Panoramic Images
Oct 14, 2019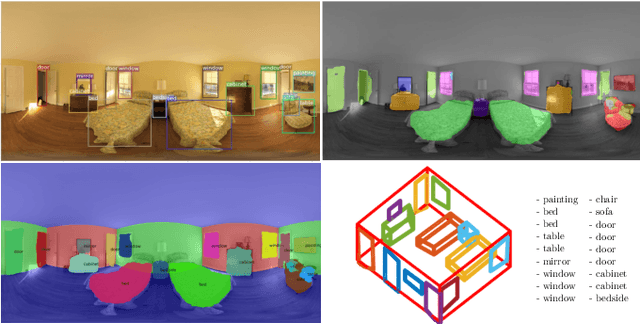

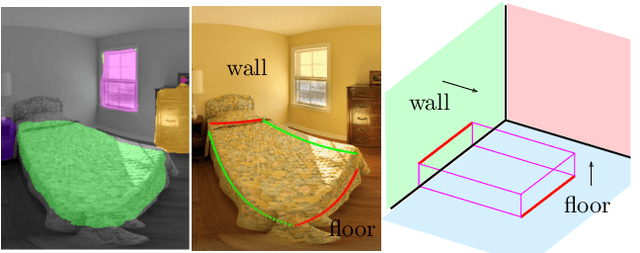
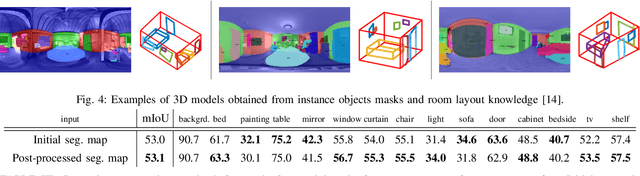
In the last few years, there has been a growing interest in taking advantage of the 360 panoramic images potential, while managing the new challenges they imply. While several tasks have been improved thanks to the contextual information these images offer, object recognition in indoor scenes still remains a challenging problem that has not been deeply investigated. This paper provides an object recognition system that performs object detection and semantic segmentation tasks by using a deep learning model adapted to match the nature of equirectangular images. From these results, instance segmentation masks are recovered, refined and transformed into 3D bounding boxes that are placed into the 3D model of the room. Quantitative and qualitative results support that our method outperforms the state of the art by a large margin and show a complete understanding of the main objects in indoor scenes.
Corners for Layout: End-to-End Layout Recovery from 360 Images
Mar 25, 2019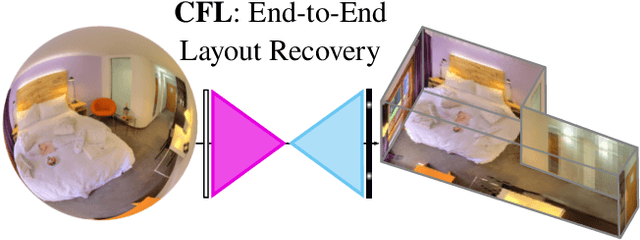

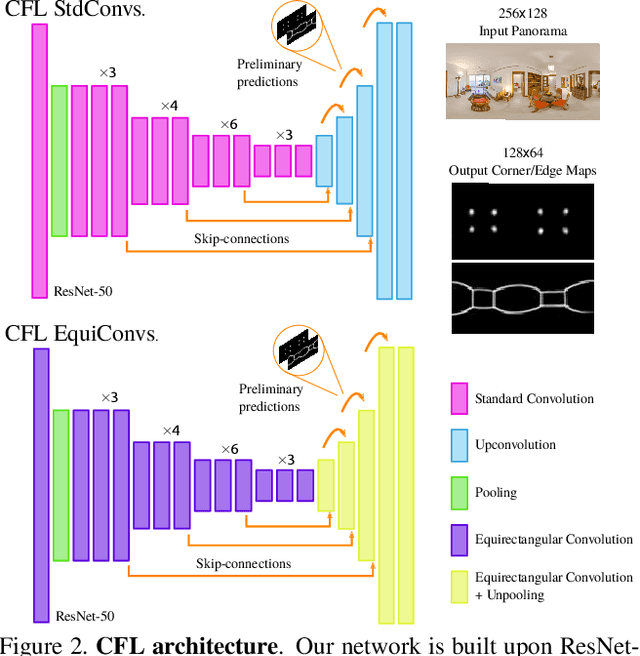

The problem of 3D layout recovery in indoor scenes has been a core research topic for over a decade. However, there are still several major challenges that remain unsolved. Among the most relevant ones, a major part of the state-of-the-art methods make implicit or explicit assumptions on the scenes -- e.g. box-shaped or Manhattan layouts. Also, current methods are computationally expensive and not suitable for real-time applications like robot navigation and AR/VR. In this work we present CFL (Corners for Layout), the first end-to-end model for 3D layout recovery on 360 images. Our experimental results show that we outperform the state of the art relaxing assumptions about the scene and at a lower cost. We also show that our model generalizes better to camera position variations than conventional approaches by using EquiConvs, a type of convolution applied directly on the sphere projection and hence invariant to the equirectangular distortions. CFL Webpage: https://cfernandezlab.github.io/CFL/