 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-SRIF: Preconditioned Cholesky-based Square Root Information Filter for Vision-aided Inertial Navigation
Sep 17, 2024



In this paper, we introduce a novel estimator for vision-aided inertial navigation systems (VINS), the Preconditioned Cholesky-based Square Root Information Filter (PC-SRIF). When solving linear systems, employing Cholesky decomposition offers superior efficiency but can compromise numerical stability. Due to this, existing VINS utilizing (Square Root) Information Filters often opt for QR decomposition on platforms where single precision is preferred, avoiding the numerical challenges associated with Cholesky decomposition. While these issues are often attributed to the ill-conditioned information matrix in VINS, our analysis reveals that this is not an inherent property of VINS but rather a consequence of specific parameterizations. We identify several factors that contribute to an ill-conditioned information matrix and propose a preconditioning technique to mitigate these conditioning issues. Building on this analysis, we present PC-SRIF, which exhibits remarkable stability in performing Cholesky decomposition in single precision when solving linear systems in VINS. Consequently, PC-SRIF achieves superior theoretical efficiency compared to alternative estimators. To validate the efficiency advantages and numerical stability of PC-SRIF based VINS, we have conducted well controlled experiments, which provide empirical evidence in support of our theoretical findings. Remarkably, in our VINS implementation, PC-SRIF's runtime is 41% faster than QR-based SRIF.
Monitored Distillation for Positive Congruent Depth Completion
Mar 30, 2022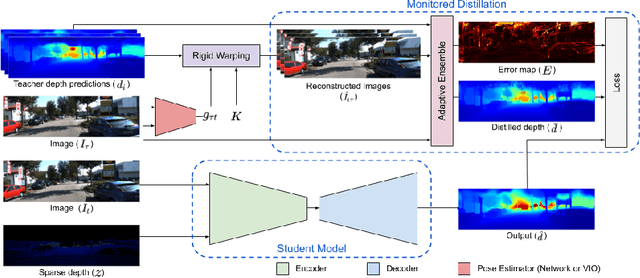
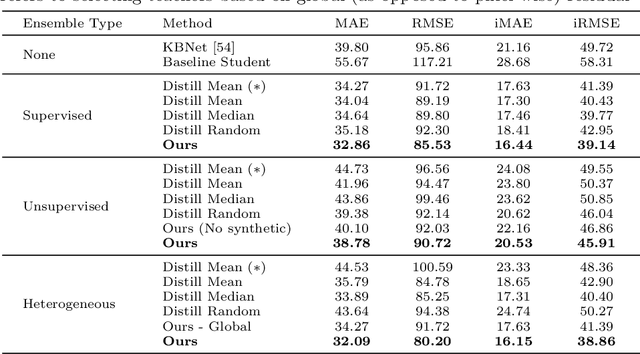

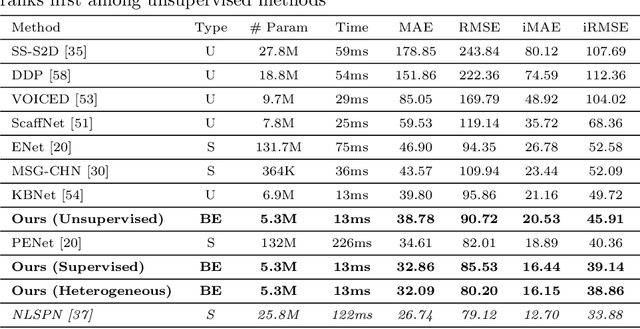
We propose a method to infer a dense depth map from a single image, its calibration, and the associated sparse point cloud. In order to leverage existing models that produce putative depth maps (teacher models), we propose an adaptive knowledge distillation approach that yields a positive congruent training process, where a student model avoids learning the error modes of the teachers. We consider the scenario of a blind ensemble where we do not have access to ground truth for model selection nor training. The crux of our method, termed Monitored Distillation, lies in a validation criterion that allows us to learn from teachers by choosing predictions that best minimize the photometric reprojection error for a given image. The result of which is a distilled depth map and a confidence map, or "monitor", for how well a prediction from a particular teacher fits the observed image. The monitor adaptively weights the distilled depth where, if all of the teachers exhibit high residuals, the standard unsupervised image reconstruction loss takes over as the supervisory signal. On indoor scenes (VOID), we outperform blind ensembling baselines by 13.3% and unsupervised methods by 20.3%; we boast a 79% model size reduction while maintaining comparable performance to the best supervised method. For outdoors (KITTI), we tie for 5th overall on the benchmark despite not using ground truth.
Stereoscopic Universal Perturbations across Different Architectures and Datasets
Jan 07, 2022
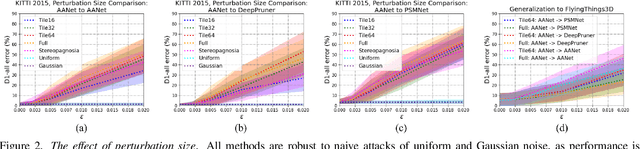
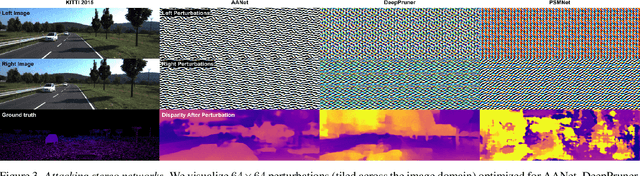
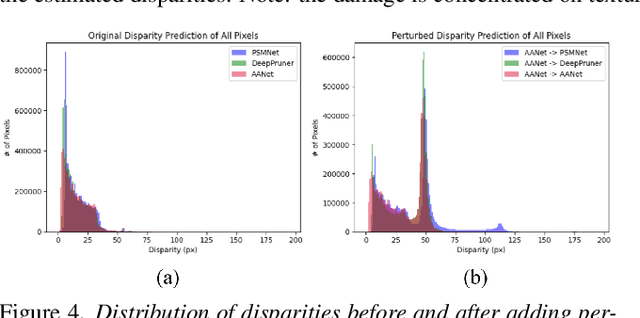
We study the effect of adversarial perturbations of images on deep stereo matching networks for the disparity estimation task. We present a method to craft a single set of perturbations that, when added to any stereo image pair in a dataset, can fool a stereo network to significantly alter the perceived scene geometry. Our perturbation images are "universal" in that they not only corrupt estimates of the network on the dataset they are optimized for, but also generalize to stereo networks with different architectures across different datasets. We evaluate our approach on multiple public benchmark datasets and show that our perturbations can increase D1-error (akin to fooling rate) of state-of-the-art stereo networks from 1% to as much as 87%. We investigate the effect of perturbations on the estimated scene geometry and identify object classes that are most vulnerable. Our analysis on the activations of registered points between left and right images led us to find that certain architectural components, i.e. deformable convolution and explicit matching, can increase robustness against adversaries. We demonstrate that by simply designing networks with such components, one can reduce the effect of adversaries by up to 60.5%, which rivals the robustness of networks fine-tuned with costly adversarial data augmentation.