 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating by Contrasting: A Data-efficient Framework for Multimodal Generative Models
Jul 02, 2020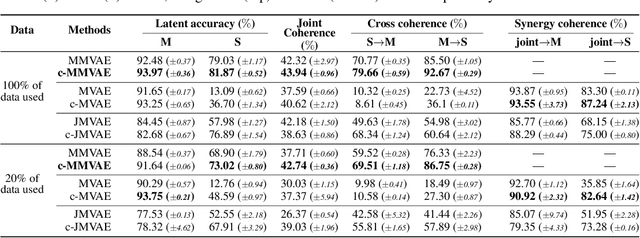
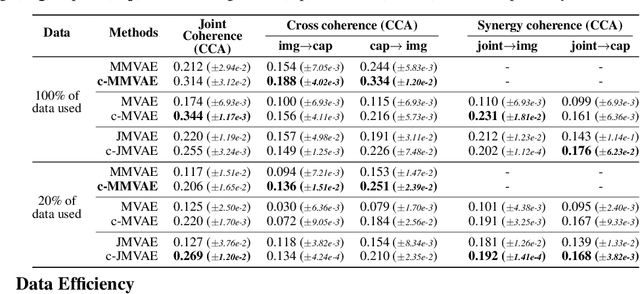


Multimodal learning for generative models often refers to the learning of abstract concepts from the commonality of information in multiple modalities, such as vision and language. While it has proven effective for learning generalisable representations, the training of such models often requires a large amount of "related" multimodal data that shares commonality, which can be expensive to come by. To mitigate this, we develop a novel contrastive framework for generative model learning, allowing us to train the model not just by the commonality between modalities, but by the distinction between "related" and "unrelated" multimodal data. We show in experiments that our method enables data-efficient multimodal learning on challenging datasets for various multimodal VAE models. We also show that under our proposed framework, the generative model can accurately identify related samples from unrelated ones, making it possible to make use of the plentiful unlabeled, unpaired multimodal data.
Learning Bijective Feature Maps for Linear ICA
Feb 19, 2020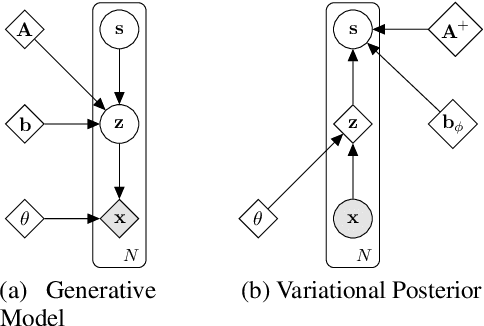
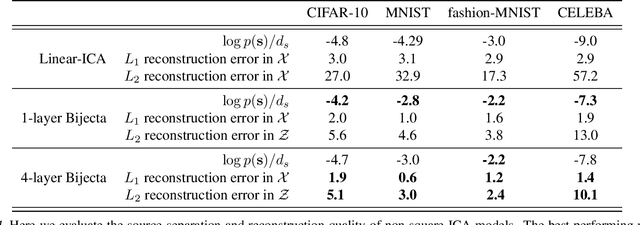

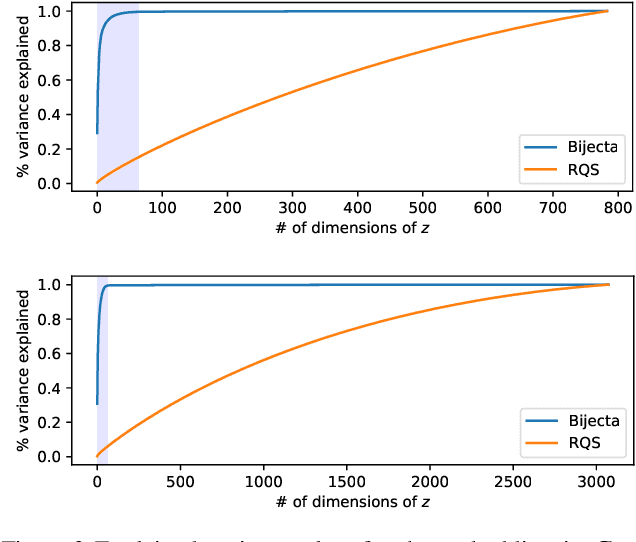
Separating high-dimensional data like images into independent latent factors remains an open research problem. Here we develop a method that jointly learns a linear independent component analysis (ICA) model with non-linear bijective feature maps. By combining these two methods, ICA can learn interpretable latent structure for images. For non-square ICA, where we assume the number of sources is less than the dimensionality of data, we achieve better unsupervised latent factor discovery than flow-based models and linear ICA. This performance scales to large image datasets such as CelebA.
Variational Mixture-of-Experts Autoencoders for Multi-Modal Deep Generative Models
Nov 08, 2019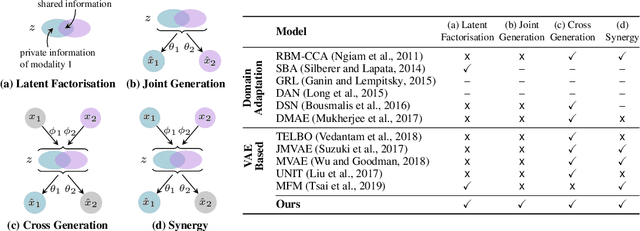


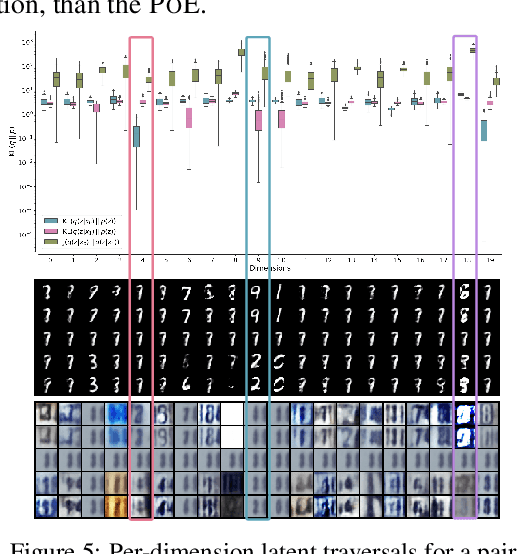
Learning generative models that span multiple data modalities, such as vision and language, is often motivated by the desire to learn more useful, generalisable representations that faithfully capture common underlying factors between the modalities. In this work, we characterise successful learning of such models as the fulfillment of four criteria: i) implicit latent decomposition into shared and private subspaces, ii) coherent joint generation over all modalities, iii) coherent cross-generation across individual modalities, and iv) improved model learning for individual modalities through multi-modal integration. Here, we propose a mixture-of-experts multimodal variational autoencoder (MMVAE) to learn generative models on different sets of modalities, including a challenging image-language dataset, and demonstrate its ability to satisfy all four criteria, both qualitatively and quantitatively.
Data Generation for Neural Programming by Example
Nov 06, 2019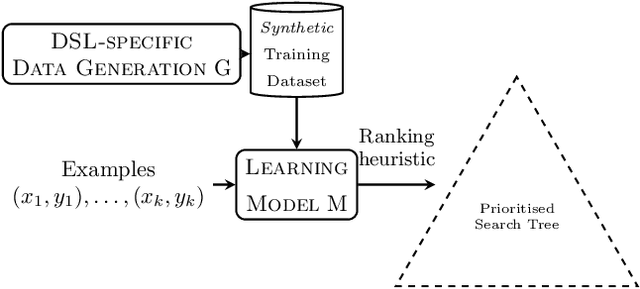



Programming by example is the problem of synthesizing a program from a small set of input / output pairs. Recent works applying machine learning methods to this task show promise, but are typically reliant on generating synthetic examples for training. A particular challenge lies in generating meaningful sets of inputs and outputs, which well-characterize a given program and accurately demonstrate its behavior. Where examples used for testing are generated by the same method as training data then the performance of a model may be partly reliant on this similarity. In this paper we introduce a novel approach using an SMT solver to synthesize inputs which cover a diverse set of behaviors for a given program. We carry out a case study comparing this method to existing synthetic data generation procedures in the literature, and find that data generated using our approach improves both the discriminatory power of example sets and the ability of trained machine learning models to generalize to unfamiliar data.
A Model to Search for Synthesizable Molecules
Jun 12, 2019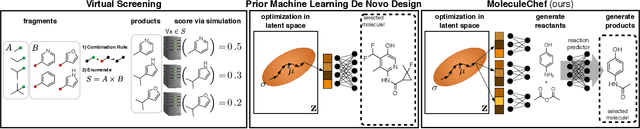
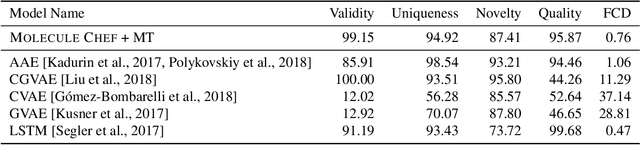
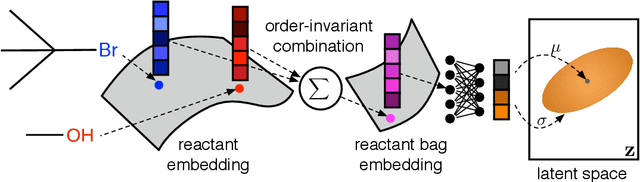

Deep generative models are able to suggest new organic molecules by generating strings, trees, and graphs representing their structure. While such models allow one to generate molecules with desirable properties, they give no guarantees that the molecules can actually be synthesized in practice. We propose a new molecule generation model, mirroring a more realistic real-world process, where (a) reactants are selected, and (b) combined to form more complex molecules. More specifically, our generative model proposes a bag of initial reactants (selected from a pool of commercially-available molecules) and uses a reaction model to predict how they react together to generate new molecules. We first show that the model can generate diverse, valid and unique molecules due to the useful inductive biases of modeling reactions. Furthermore, our model allows chemists to interrogate not only the properties of the generated molecules but also the feasibility of the synthesis routes. We conclude by using our model to solve retrosynthesis problems, predicting a set of reactants that can produce a target product.
Learning a Generative Model for Validity in Complex Discrete Structures
Nov 02, 2018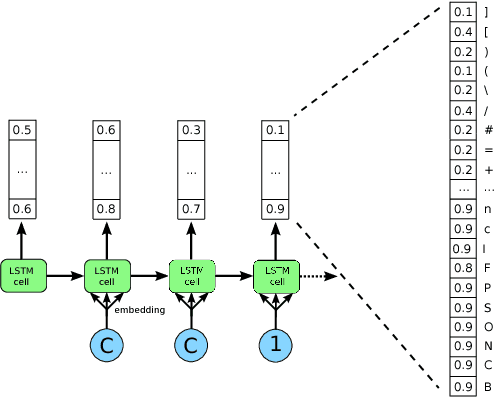
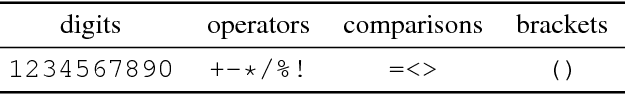
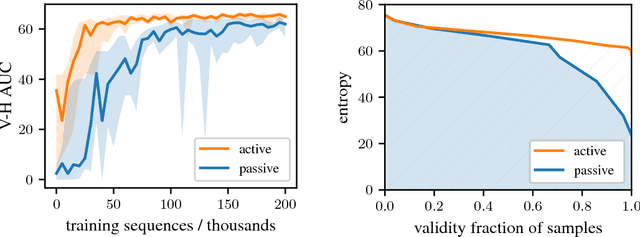

Deep generative models have been successfully used to learn representations for high-dimensional discrete spaces by representing discrete objects as sequences and employing powerful sequence-based deep models. Unfortunately, these sequence-based models often produce invalid sequences: sequences which do not represent any underlying discrete structure; invalid sequences hinder the utility of such models. As a step towards solving this problem, we propose to learn a deep recurrent validator model, which can estimate whether a partial sequence can function as the beginning of a full, valid sequence. This validator provides insight as to how individual sequence elements influence the validity of the overall sequence, and can be used to constrain sequence based models to generate valid sequences -- and thus faithfully model discrete objects. Our approach is inspired by reinforcement learning, where an oracle which can evaluate validity of complete sequences provides a sparse reward signal. We demonstrate its effectiveness as a generative model of Python 3 source code for mathematical expressions, and in improving the ability of a variational autoencoder trained on SMILES strings to decode valid molecular structures.
An Introduction to Probabilistic Programming
Sep 27, 2018
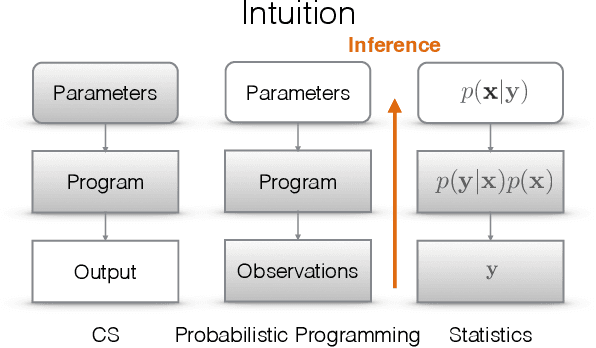


This document is designed to be a first-year graduate-level introduction to probabilistic programming. It not only provides a thorough background for anyone wishing to use a probabilistic programming system, but also introduces the techniques needed to design and build these systems. It is aimed at people who have an undergraduate-level understanding of either or, ideally, both probabilistic machine learning and programming languages. We start with a discussion of model-based reasoning and explain why conditioning as a foundational computation is central to the fields of probabilistic machine learning and artificial intelligence. We then introduce a simple first-order probabilistic programming language (PPL) whose programs define static-computation-graph, finite-variable-cardinality models. In the context of this restricted PPL we introduce fundamental inference algorithms and describe how they can be implemented in the context of models denoted by probabilistic programs. In the second part of this document, we introduce a higher-order probabilistic programming language, with a functionality analogous to that of established programming languages. This affords the opportunity to define models with dynamic computation graphs, at the cost of requiring inference methods that generate samples by repeatedly executing the program. Foundational inference algorithms for this kind of probabilistic programming language are explained in the context of an interface between program executions and an inference controller. This document closes with a chapter on advanced topics which we believe to be, at the time of writing, interesting directions for probabilistic programming research; directions that point towards a tight integration with deep neural network research and the development of systems for next-generation artificial intelligence applications.
Take a Look Around: Using Street View and Satellite Images to Estimate House Prices
Jul 18, 2018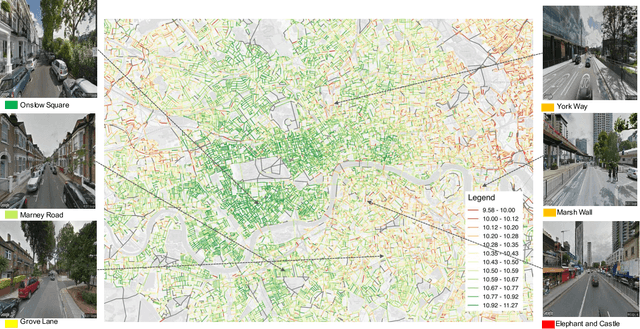
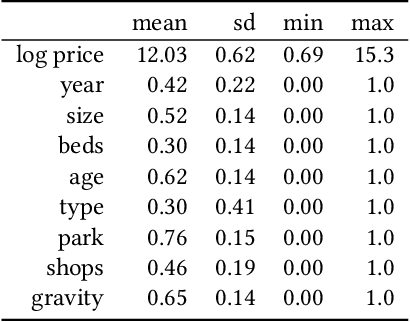
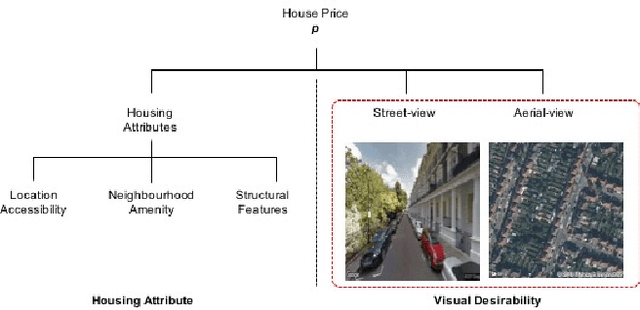
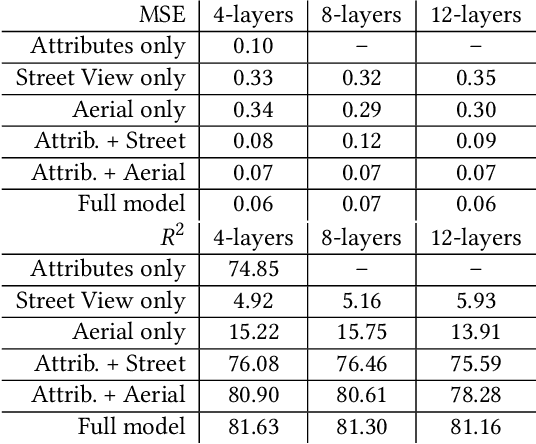
When an individual purchases a home, they simultaneously purchase its structural features, its accessibility to work, and the neighborhood amenities. Some amenities, such as air quality, are measurable whilst others, such as the prestige or the visual impression of a neighborhood, are difficult to quantify. Despite the well-known impacts intangible housing features have on house prices, limited attention has been given to systematically quantifying these difficult to measure amenities. Two issues have lead to this neglect. Not only do few quantitative methods exist that can measure the urban environment, but that the collection of such data is both costly and subjective. We show that street image and satellite image data can capture these urban qualities and improve the estimation of house prices. We propose a pipeline that uses a deep neural network model to automatically extract visual features from images to estimate house prices in London, UK. We make use of traditional housing features such as age, size and accessibility as well as visual features from Google Street View images and Bing aerial images in estimating the house price model. We find encouraging results where learning to characterize the urban quality of a neighborhood improves house price prediction, even when generalizing to previously unseen London boroughs. We explore the use of non-linear vs. linear methods to fuse these cues with conventional models of house pricing, and show how the interpretability of linear models allows us to directly extract the visual desirability of neighborhoods as proxy variables that are both of interest in their own right, and could be used as inputs to other econometric methods. This is particularly valuable as once the network has been trained with the training data, it can be applied elsewhere, allowing us to generate vivid dense maps of the desirability of London streets.
Structured Disentangled Representations
May 29, 2018



Deep latent-variable models learn representations of high-dimensional data in an unsupervised manner. A number of recent efforts have focused on learning representations that disentangle statistically independent axes of variation by introducing modifications to the standard objective function. These approaches generally assume a simple diagonal Gaussian prior and as a result are not able to reliably disentangle discrete factors of variation. We propose a two-level hierarchical objective to control relative degree of statistical independence between blocks of variables and individual variables within blocks. We derive this objective as a generalization of the evidence lower bound, which allows us to explicitly represent the trade-offs between mutual information between data and representation, KL divergence between representation and prior, and coverage of the support of the empirical data distribution. Experiments on a variety of datasets demonstrate that our objective can not only disentangle discrete variables, but that doing so also improves disentanglement of other variables and, importantly, generalization even to unseen combinations of factors.
Predicting Electron Paths
May 23, 2018
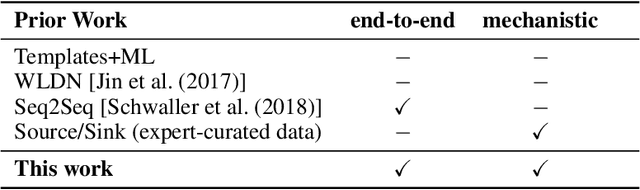
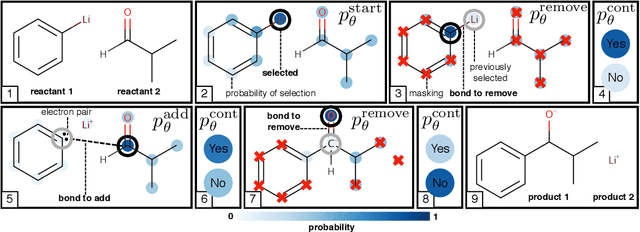
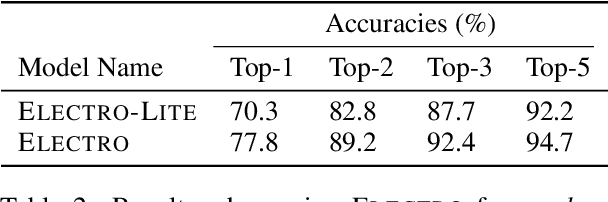
Chemical reactions can be described as the stepwise redistribution of electrons in molecules. As such, reactions are often depicted using "arrow-pushing" diagrams which show this movement as a sequence of arrows. We propose an electron path prediction model (ELECTRO) to learn these sequences directly from raw reaction data. Instead of predicting product molecules directly from reactant molecules in one shot, learning a model of electron movement has the benefits of (a) being easy for chemists to interpret, (b) incorporating constraints of chemistry, such as balanced atom counts before and after the reaction, and (c) naturally encoding the sparsity of chemical reactions, which usually involve changes in only a small number of atoms in the reactants. We design a method to extract approximate reaction paths from any dataset of atom-mapped reaction SMILES strings. Our model achieves state-of-the-art results on a subset of the UPSTO reaction dataset. Furthermore, we show that our model recovers a basic knowledge of chemistry without being explicitly trained to do so.