 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRouting with Self-Attention for Multimodal Capsule Networks
Dec 01, 2021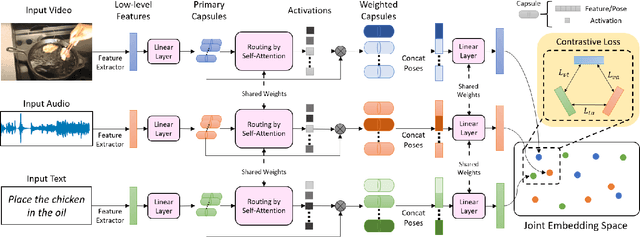
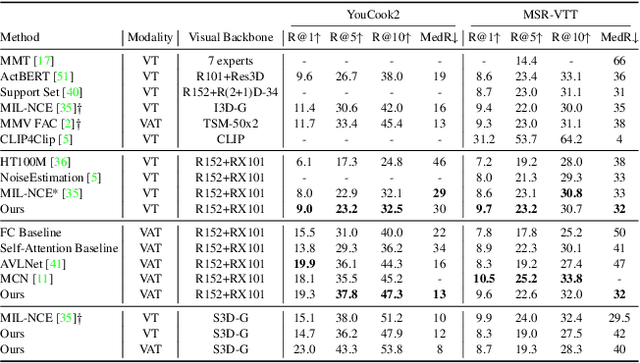
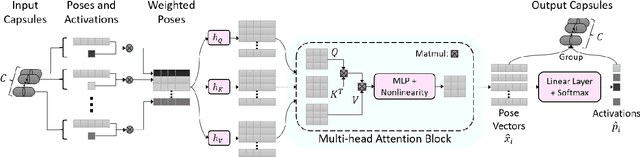
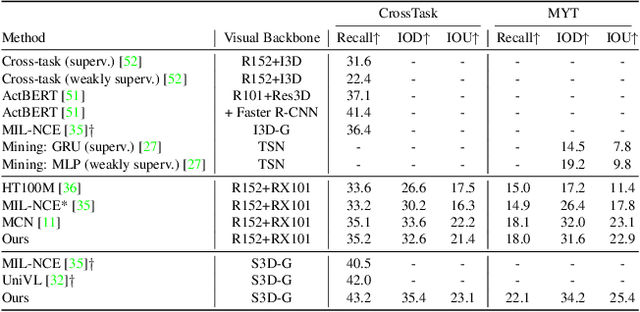
The task of multimodal learning has seen a growing interest recently as it allows for training neural architectures based on different modalities such as vision, text, and audio. One challenge in training such models is that they need to jointly learn semantic concepts and their relationships across different input representations. Capsule networks have been shown to perform well in context of capturing the relation between low-level input features and higher-level concepts. However, capsules have so far mainly been used only in small-scale fully supervised settings due to the resource demand of conventional routing algorithms. We present a new multimodal capsule network that allows us to leverage the strength of capsules in the context of a multimodal learning framework on large amounts of video data. To adapt the capsules to large-scale input data, we propose a novel routing by self-attention mechanism that selects relevant capsules which are then used to generate a final joint multimodal feature representation. This allows not only for robust training with noisy video data, but also to scale up the size of the capsule network compared to traditional routing methods while still being computationally efficient. We evaluate the proposed architecture by pretraining it on a large-scale multimodal video dataset and applying it on four datasets in two challenging downstream tasks. Results show that the proposed multimodal capsule network is not only able to improve results compared to other routing techniques, but also achieves competitive performance on the task of multimodal learning.
Cascaded Multilingual Audio-Visual Learning from Videos
Nov 08, 2021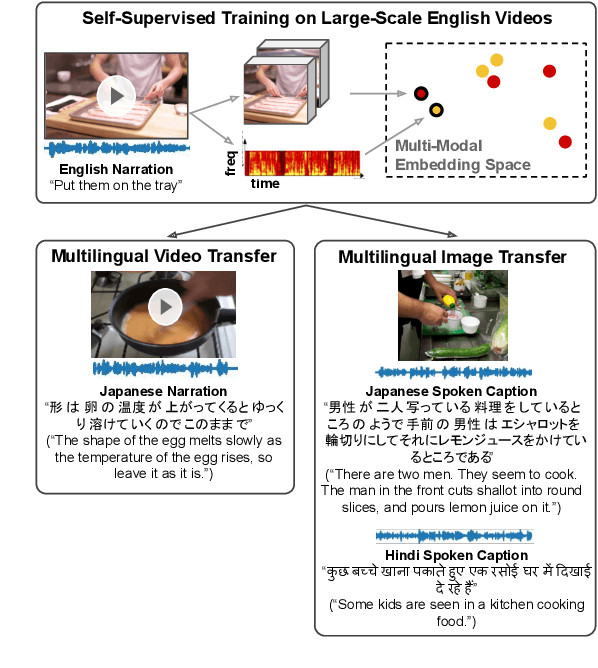
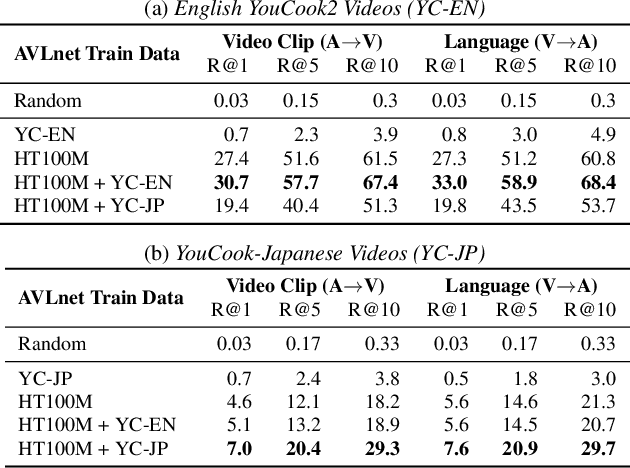

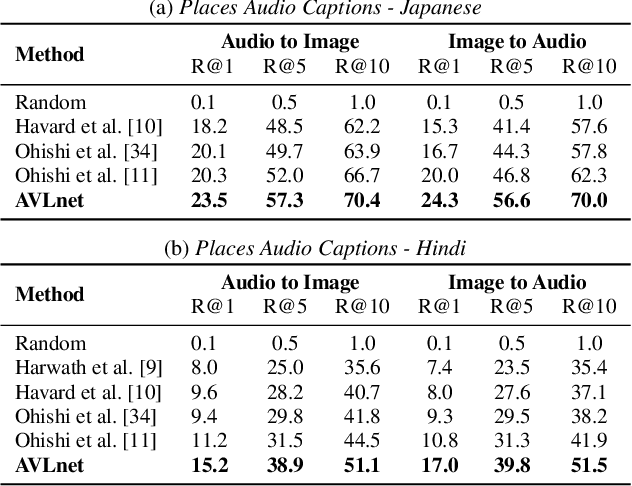
In this paper, we explore self-supervised audio-visual models that learn from instructional videos. Prior work has shown that these models can relate spoken words and sounds to visual content after training on a large-scale dataset of videos, but they were only trained and evaluated on videos in English. To learn multilingual audio-visual representations, we propose a cascaded approach that leverages a model trained on English videos and applies it to audio-visual data in other languages, such as Japanese videos. With our cascaded approach, we show an improvement in retrieval performance of nearly 10x compared to training on the Japanese videos solely. We also apply the model trained on English videos to Japanese and Hindi spoken captions of images, achieving state-of-the-art performance.
Joint Multimedia Event Extraction from Video and Article
Sep 27, 2021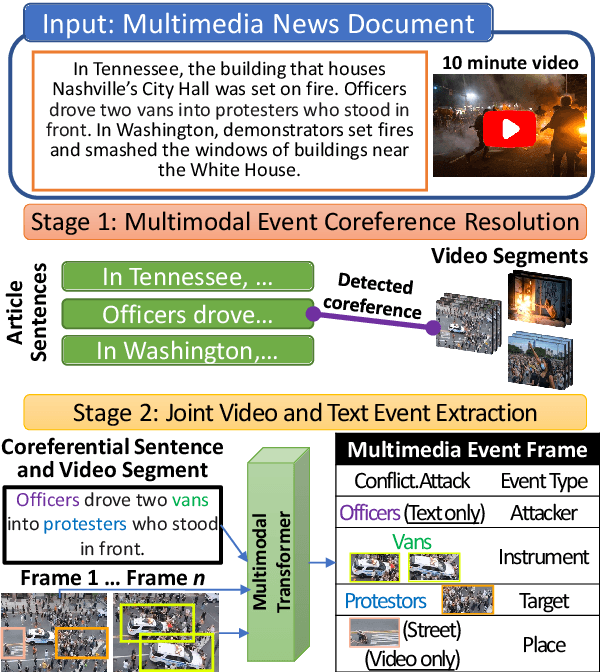
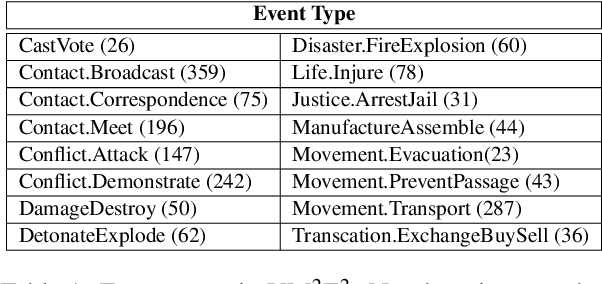


Visual and textual modalities contribute complementary information about events described in multimedia documents. Videos contain rich dynamics and detailed unfoldings of events, while text describes more high-level and abstract concepts. However, existing event extraction methods either do not handle video or solely target video while ignoring other modalities. In contrast, we propose the first approach to jointly extract events from video and text articles. We introduce the new task of Video MultiMedia Event Extraction (Video M2E2) and propose two novel components to build the first system towards this task. First, we propose the first self-supervised multimodal event coreference model that can determine coreference between video events and text events without any manually annotated pairs. Second, we introduce the first multimodal transformer which extracts structured event information jointly from both videos and text documents. We also construct and will publicly release a new benchmark of video-article pairs, consisting of 860 video-article pairs with extensive annotations for evaluating methods on this task. Our experimental results demonstrate the effectiveness of our proposed method on our new benchmark dataset. We achieve 6.0% and 5.8% absolute F-score gain on multimodal event coreference resolution and multimedia event extraction.
Multimodal Clustering Networks for Self-supervised Learning from Unlabeled Videos
May 05, 2021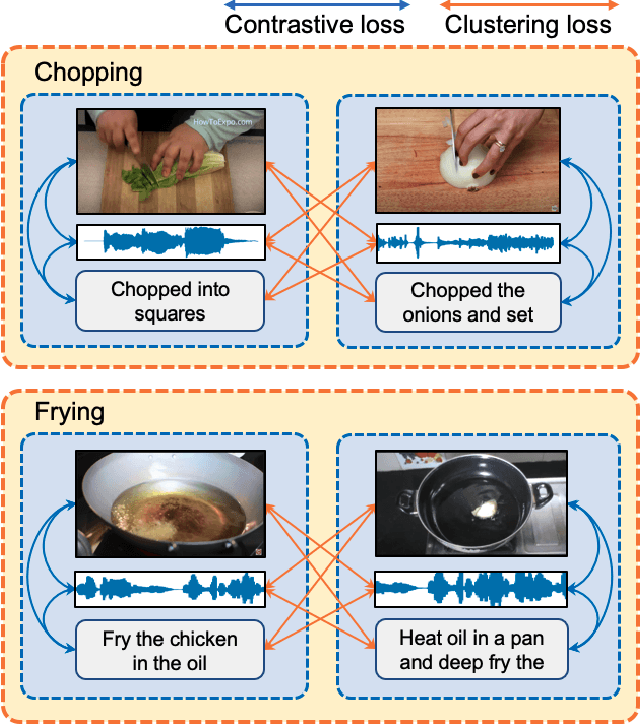
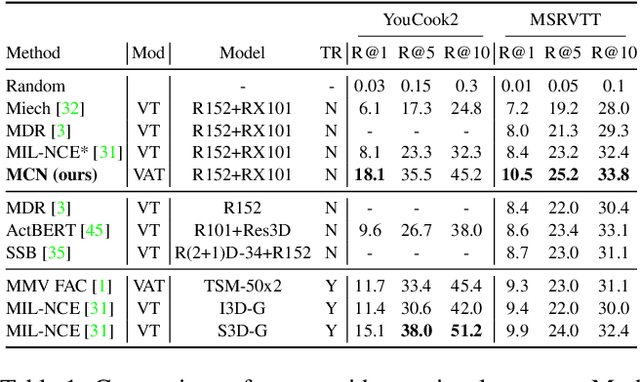
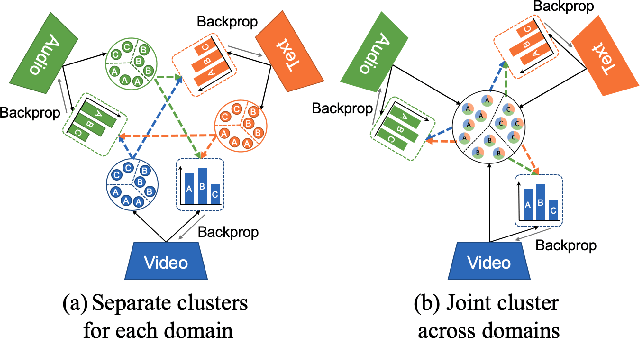
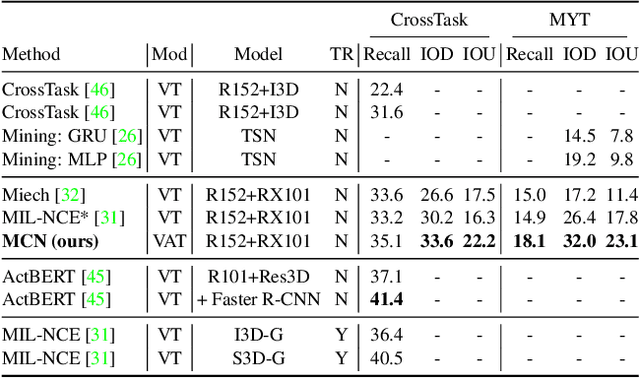
Multimodal self-supervised learning is getting more and more attention as it allows not only to train large networks without human supervision but also to search and retrieve data across various modalities. In this context, this paper proposes a self-supervised training framework that learns a common multimodal embedding space that, in addition to sharing representations across different modalities, enforces a grouping of semantically similar instances. To this end, we extend the concept of instance-level contrastive learning with a multimodal clustering step in the training pipeline to capture semantic similarities across modalities. The resulting embedding space enables retrieval of samples across all modalities, even from unseen datasets and different domains. To evaluate our approach, we train our model on the HowTo100M dataset and evaluate its zero-shot retrieval capabilities in two challenging domains, namely text-to-video retrieval, and temporal action localization, showing state-of-the-art results on four different datasets.
Meta Variational Monte Carlo
Nov 20, 2020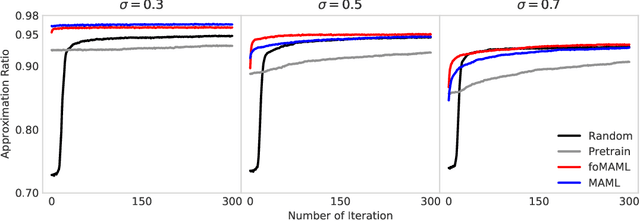
An identification is found between meta-learning and the problem of determining the ground state of a randomly generated Hamiltonian drawn from a known ensemble. A model-agnostic meta-learning approach is proposed to solve the associated learning problem and a preliminary experimental study of random Max-Cut problems indicates that the resulting Meta Variational Monte Carlo accelerates training and improves convergence.
General Partial Label Learning via Dual Bipartite Graph Autoencoder
Jan 05, 2020
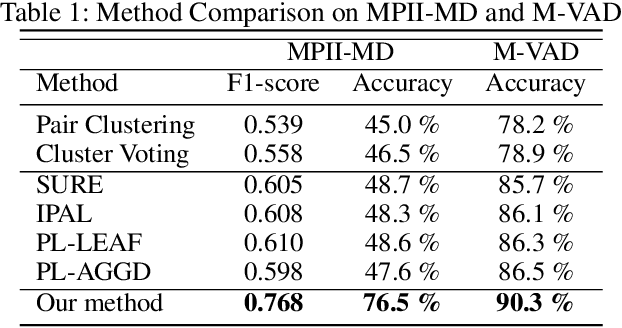
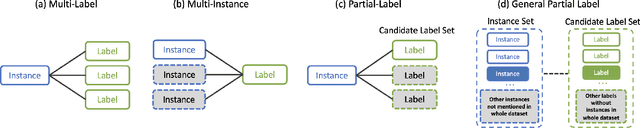
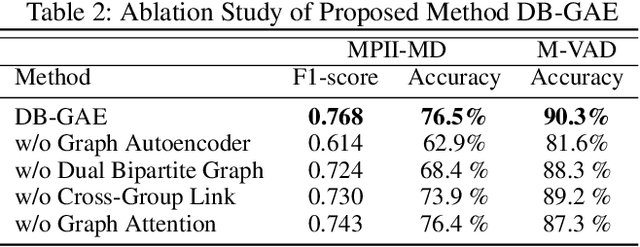
We formulate a practical yet challenging problem: General Partial Label Learning (GPLL). Compared to the traditional Partial Label Learning (PLL) problem, GPLL relaxes the supervision assumption from instance-level --- a label set partially labels an instance --- to group-level: 1) a label set partially labels a group of instances, where the within-group instance-label link annotations are missing, and 2) cross-group links are allowed --- instances in a group may be partially linked to the label set from another group. Such ambiguous group-level supervision is more practical in real-world scenarios as additional annotation on the instance-level is no longer required, e.g., face-naming in videos where the group consists of faces in a frame, labeled by a name set in the corresponding caption. In this paper, we propose a novel graph convolutional network (GCN) called Dual Bipartite Graph Autoencoder (DB-GAE) to tackle the label ambiguity challenge of GPLL. First, we exploit the cross-group correlations to represent the instance groups as dual bipartite graphs: within-group and cross-group, which reciprocally complements each other to resolve the linking ambiguities. Second, we design a GCN autoencoder to encode and decode them, where the decodings are considered as the refined results. It is worth noting that DB-GAE is self-supervised and transductive, as it only uses the group-level supervision without a separate offline training stage. Extensive experiments on two real-world datasets demonstrate that DB-GAE significantly outperforms the best baseline over absolute 0.159 F1-score and 24.8% accuracy. We further offer analysis on various levels of label ambiguities.
Multi-level Multimodal Common Semantic Space for Image-Phrase Grounding
Nov 28, 2018


We address the problem of phrase grounding by learning a multi-level common semantic space shared by the textual and visual modalities. This common space is instantiated at multiple layers of a Deep Convolutional Neural Network by exploiting its feature maps, as well as contextualized word-level and sentence-level embeddings extracted from a character-based language model. Following a dedicated non-linear mapping for visual features at each level, word, and sentence embeddings, we obtain a common space in which comparisons between the target text and the visual content at any semantic level can be performed simply with cosine similarity. We guide the model by a multi-level multimodal attention mechanism which outputs attended visual features at different semantic levels. The best level is chosen to be compared with text content for maximizing the pertinence scores of image-sentence pairs of the ground truth. Experiments conducted on three publicly available benchmarks show significant performance gains (20%-60% relative) over the state-of-the-art in phrase localization and set a new performance record on those datasets. We also provide a detailed ablation study to show the contribution of each element of our approach.