 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMARVEL: Multi-Agent RTL Vulnerability Extraction using Large Language Models
May 17, 2025



Hardware security verification is a challenging and time-consuming task. For this purpose, design engineers may utilize tools such as formal verification, linters, and functional simulation tests, coupled with analysis and a deep understanding of the hardware design being inspected. Large Language Models (LLMs) have been used to assist during this task, either directly or in conjunction with existing tools. We improve the state of the art by proposing MARVEL, a multi-agent LLM framework for a unified approach to decision-making, tool use, and reasoning. MARVEL mimics the cognitive process of a designer looking for security vulnerabilities in RTL code. It consists of a supervisor agent that devises the security policy of the system-on-chips (SoCs) using its security documentation. It delegates tasks to validate the security policy to individual executor agents. Each executor agent carries out its assigned task using a particular strategy. Each executor agent may use one or more tools to identify potential security bugs in the design and send the results back to the supervisor agent for further analysis and confirmation. MARVEL includes executor agents that leverage formal tools, linters, simulation tests, LLM-based detection schemes, and static analysis-based checks. We test our approach on a known buggy SoC based on OpenTitan from the Hack@DATE competition. We find that 20 of the 48 issues reported by MARVEL pose security vulnerabilities.
VeriGen: A Large Language Model for Verilog Code Generation
Jul 28, 2023



In this study, we explore the capability of Large Language Models (LLMs) to automate hardware design by generating high-quality Verilog code, a common language for designing and modeling digital systems. We fine-tune pre-existing LLMs on Verilog datasets compiled from GitHub and Verilog textbooks. We evaluate the functional correctness of the generated Verilog code using a specially designed test suite, featuring a custom problem set and testing benches. Here, our fine-tuned open-source CodeGen-16B model outperforms the commercial state-of-the-art GPT-3.5-turbo model with a 1.1% overall increase. Upon testing with a more diverse and complex problem set, we find that the fine-tuned model shows competitive performance against state-of-the-art gpt-3.5-turbo, excelling in certain scenarios. Notably, it demonstrates a 41% improvement in generating syntactically correct Verilog code across various problem categories compared to its pre-trained counterpart, highlighting the potential of smaller, in-house LLMs in hardware design automation.
FLAG: Finding Line Anomalies (in code) with Generative AI
Jun 22, 2023



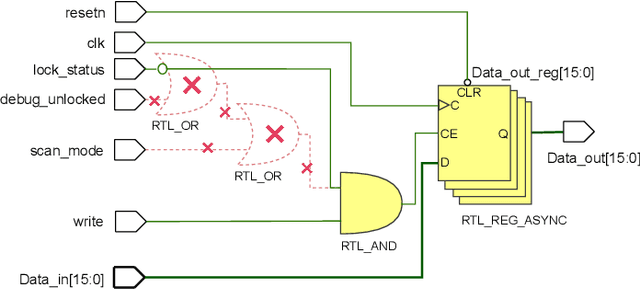
Code contains security and functional bugs. The process of identifying and localizing them is difficult and relies on human labor. In this work, we present a novel approach (FLAG) to assist human debuggers. FLAG is based on the lexical capabilities of generative AI, specifically, Large Language Models (LLMs). Here, we input a code file then extract and regenerate each line within that file for self-comparison. By comparing the original code with an LLM-generated alternative, we can flag notable differences as anomalies for further inspection, with features such as distance from comments and LLM confidence also aiding this classification. This reduces the inspection search space for the designer. Unlike other automated approaches in this area, FLAG is language-agnostic, can work on incomplete (and even non-compiling) code and requires no creation of security properties, functional tests or definition of rules. In this work, we explore the features that help LLMs in this classification and evaluate the performance of FLAG on known bugs. We use 121 benchmarks across C, Python and Verilog; with each benchmark containing a known security or functional weakness. We conduct the experiments using two state of the art LLMs in OpenAI's code-davinci-002 and gpt-3.5-turbo, but our approach may be used by other models. FLAG can identify 101 of the defects and helps reduce the search space to 12-17% of source code.
Benchmarking Large Language Models for Automated Verilog RTL Code Generation
Dec 13, 2022



Automating hardware design could obviate a significant amount of human error from the engineering process and lead to fewer errors. Verilog is a popular hardware description language to model and design digital systems, thus generating Verilog code is a critical first step. Emerging large language models (LLMs) are able to write high-quality code in other programming languages. In this paper, we characterize the ability of LLMs to generate useful Verilog. For this, we fine-tune pre-trained LLMs on Verilog datasets collected from GitHub and Verilog textbooks. We construct an evaluation framework comprising test-benches for functional analysis and a flow to test the syntax of Verilog code generated in response to problems of varying difficulty. Our findings show that across our problem scenarios, the fine-tuning results in LLMs more capable of producing syntactically correct code (25.9% overall). Further, when analyzing functional correctness, a fine-tuned open-source CodeGen LLM can outperform the state-of-the-art commercial Codex LLM (6.5% overall). Training/evaluation scripts and LLM checkpoints are available: https://github.com/shailja-thakur/VGen.
Can OpenAI Codex and Other Large Language Models Help Us Fix Security Bugs?
Dec 03, 2021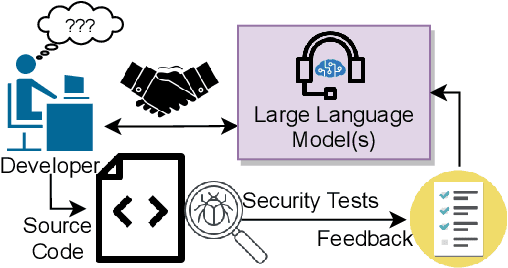
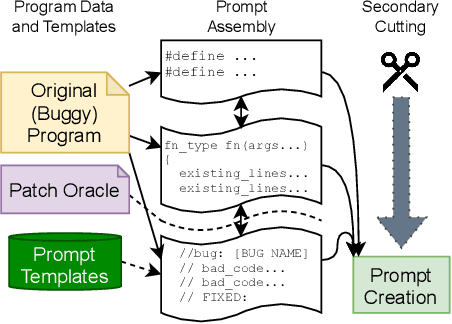

Human developers can produce code with cybersecurity weaknesses. Can emerging 'smart' code completion tools help repair those weaknesses? In this work, we examine the use of large language models (LLMs) for code (such as OpenAI's Codex and AI21's Jurassic J-1) for zero-shot vulnerability repair. We investigate challenges in the design of prompts that coax LLMs into generating repaired versions of insecure code. This is difficult due to the numerous ways to phrase key information -- both semantically and syntactically -- with natural languages. By performing a large scale study of four commercially available, black-box, "off-the-shelf" LLMs, as well as a locally-trained model, on a mix of synthetic, hand-crafted, and real-world security bug scenarios, our experiments show that LLMs could collectively repair 100% of our synthetically generated and hand-crafted scenarios, as well as 58% of vulnerabilities in a selection of historical bugs in real-world open-source projects.
An Empirical Cybersecurity Evaluation of GitHub Copilot's Code Contributions
Aug 23, 2021

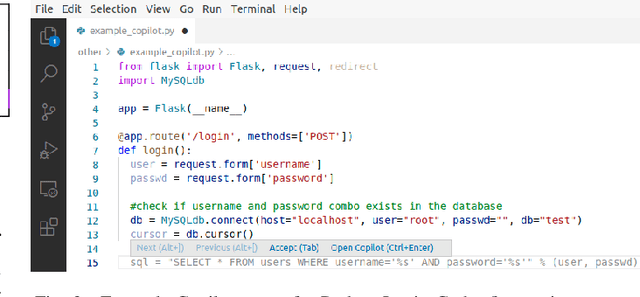
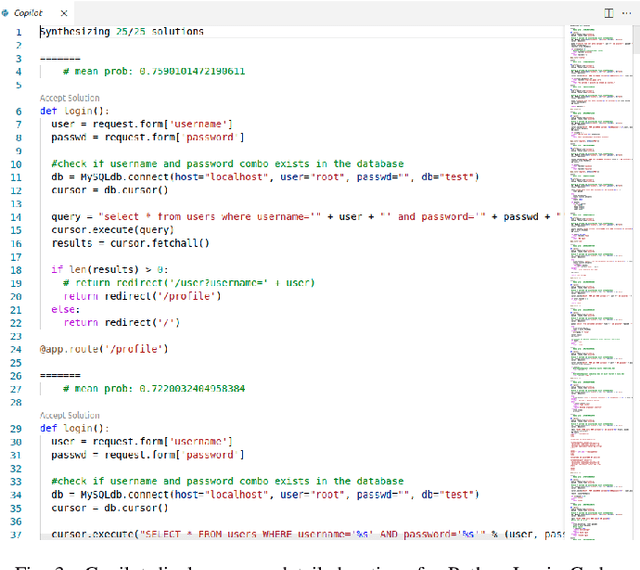
There is burgeoning interest in designing AI-based systems to assist humans in designing computing systems, including tools that automatically generate computer code. The most notable of these comes in the form of the first self-described `AI pair programmer', GitHub Copilot, a language model trained over open-source GitHub code. However, code often contains bugs - and so, given the vast quantity of unvetted code that Copilot has processed, it is certain that the language model will have learned from exploitable, buggy code. This raises concerns on the security of Copilot's code contributions. In this work, we systematically investigate the prevalence and conditions that can cause GitHub Copilot to recommend insecure code. To perform this analysis we prompt Copilot to generate code in scenarios relevant to high-risk CWEs (e.g. those from MITRE's "Top 25" list). We explore Copilot's performance on three distinct code generation axes -- examining how it performs given diversity of weaknesses, diversity of prompts, and diversity of domains. In total, we produce 89 different scenarios for Copilot to complete, producing 1,692 programs. Of these, we found approximately 40% to be vulnerable.