 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models
Dec 21, 2022Large language models (LLMs) have demonstrated excellent zero-shot generalization to new language tasks. However, effective utilization of LLMs for zero-shot visual question-answering (VQA) remains challenging, primarily due to the modality disconnection and task disconnection between LLM and VQA task. End-to-end training on vision and language data may bridge the disconnections, but is inflexible and computationally expensive. To address this issue, we propose \emph{Img2Prompt}, a plug-and-play module that provides the prompts that can bridge the aforementioned modality and task disconnections, so that LLMs can perform zero-shot VQA tasks without end-to-end training. In order to provide such prompts, we further employ LLM-agnostic models to provide prompts that can describe image content and self-constructed question-answer pairs, which can effectively guide LLM to perform zero-shot VQA tasks. Img2Prompt offers the following benefits: 1) It can flexibly work with various LLMs to perform VQA. 2)~Without the needing of end-to-end training, it significantly reduces the cost of deploying LLM for zero-shot VQA tasks. 3) It achieves comparable or better performance than methods relying on end-to-end training. For example, we outperform Flamingo~\cite{Deepmind:Flamingo2022} by 5.6\% on VQAv2. On the challenging A-OKVQA dataset, our method even outperforms few-shot methods by as much as 20\%.
Is GPT-3 a Good Data Annotator?
Dec 20, 2022GPT-3 (Generative Pre-trained Transformer 3) is a large-scale autoregressive language model developed by OpenAI, which has demonstrated impressive few-shot performance on a wide range of natural language processing (NLP) tasks. Hence, an intuitive application is to use it for data annotation. In this paper, we investigate whether GPT-3 can be used as a good data annotator for NLP tasks. Data annotation is the process of labeling data that could be used to train machine learning models. It is a crucial step in the development of NLP systems, as it allows the model to learn the relationship between the input data and the desired output. Given the impressive language capabilities of GPT-3, it is natural to wonder whether it can be used to effectively annotate data for NLP tasks. In this paper, we evaluate the performance of GPT-3 as a data annotator by comparing it with traditional data annotation methods and analyzing its output on a range of tasks. Through this analysis, we aim to provide insight into the potential of GPT-3 as a general-purpose data annotator in NLP.
Evaluating and Mitigating Static Bias of Action Representations in the Background and the Foreground
Nov 23, 2022Deep neural networks for video action recognition easily learn to utilize shortcut static features, such as background and objects instead of motion features. This results in poor generalization to atypical videos such as soccer playing on concrete surfaces (instead of soccer fields). However, due to the rarity of out-of-distribution (OOD) data, quantitative evaluation of static bias remains a difficult task. In this paper, we synthesize new sets of benchmarks to evaluate static bias of action representations, including SCUB for static cues in the background, and SCUF for static cues in the foreground. Further, we propose a simple yet effective video data augmentation technique, StillMix, that automatically identifies bias-inducing video frames; unlike similar augmentation techniques, StillMix does not need to enumerate or precisely segment biased content. With extensive experiments, we quantitatively compare and analyze existing action recognition models on the created benchmarks to reveal their characteristics. We validate the effectiveness of StillMix and show that it improves TSM (Lin, Gan, and Han 2021) and Video Swin Transformer (Liu et al. 2021) by more than 10% of accuracy on SCUB for OOD action recognition.
A Survey of Computer Vision Technologies In Urban and Controlled-environment Agriculture
Oct 20, 2022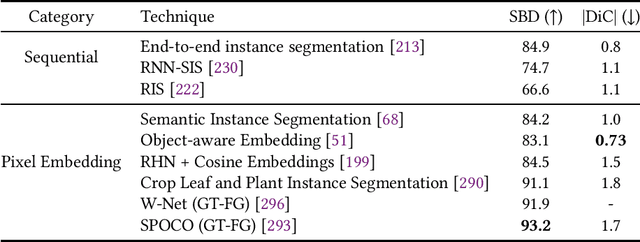
In the evolution of agriculture to its next stage, Agriculture 5.0, artificial intelligence will play a central role. Controlled-environment agriculture, or CEA, is a special form of urban and suburban agricultural practice that offers numerous economic, environmental, and social benefits, including shorter transportation routes to population centers, reduced environmental impact, and increased productivity. Due to its ability to control environmental factors, CEA couples well with computer vision (CV) in the adoption of real-time monitoring of the plant conditions and autonomous cultivation and harvesting. The objective of this paper is to familiarize CV researchers with agricultural applications and agricultural practitioners with the solutions offered by CV. We identify five major CV applications in CEA, analyze their requirements and motivation, and survey the state of the art as reflected in 68 technical papers using deep learning methods. In addition, we discuss five key subareas of computer vision and how they related to these CEA problems, as well as nine vision-based CEA datasets. We hope the survey will help researchers quickly gain a bird-eye view of the striving research area and will spark inspiration for new research and development.
Plug-and-Play VQA: Zero-shot VQA by Conjoining Large Pretrained Models with Zero Training
Oct 17, 2022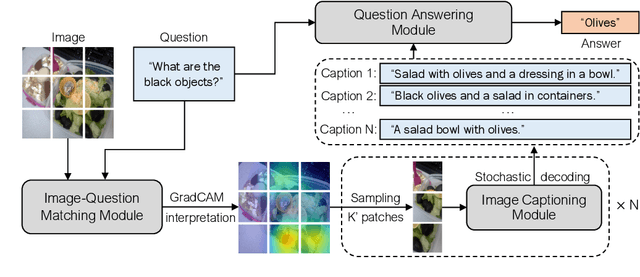
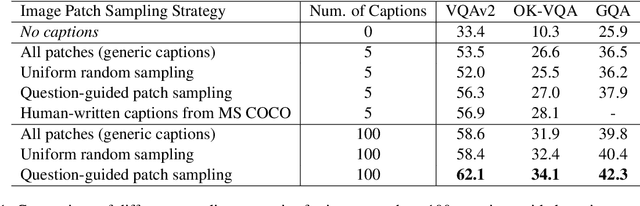

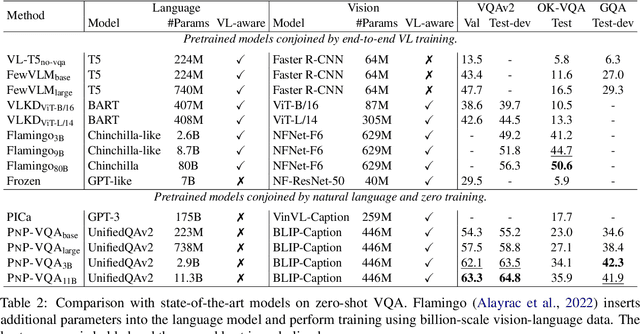
Visual question answering (VQA) is a hallmark of vision and language reasoning and a challenging task under the zero-shot setting. We propose Plug-and-Play VQA (PNP-VQA), a modular framework for zero-shot VQA. In contrast to most existing works, which require substantial adaptation of pretrained language models (PLMs) for the vision modality, PNP-VQA requires no additional training of the PLMs. Instead, we propose to use natural language and network interpretation as an intermediate representation that glues pretrained models together. We first generate question-guided informative image captions, and pass the captions to a PLM as context for question answering. Surpassing end-to-end trained baselines, PNP-VQA achieves state-of-the-art results on zero-shot VQAv2 and GQA. With 11B parameters, it outperforms the 80B-parameter Flamingo model by 8.5% on VQAv2. With 738M PLM parameters, PNP-VQA achieves an improvement of 9.1% on GQA over FewVLM with 740M PLM parameters. Code is released at https://github.com/salesforce/LAVIS/tree/main/projects/pnp-vqa
Improving the Sample Efficiency of Prompt Tuning with Domain Adaptation
Oct 06, 2022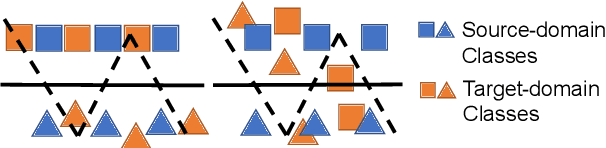
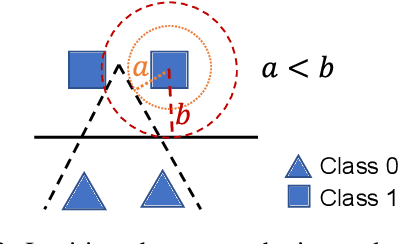

Prompt tuning, or the conditioning of a frozen pretrained language model (PLM) with soft prompts learned from data, has demonstrated impressive performance on a wide range of NLP tasks. However, prompt tuning requires a large training dataset to be effective and is outperformed by finetuning the entire PLM in data-scarce regimes. Previous work \citep{gu-etal-2022-ppt,vu-etal-2022-spot} proposed to transfer soft prompts pretrained on the source domain to the target domain. In this paper, we explore domain adaptation for prompt tuning, a problem setting where unlabeled data from the target domain are available during pretraining. We propose bOosting Prompt TunIng with doMain Adaptation (OPTIMA), which regularizes the decision boundary to be smooth around regions where source and target data distributions are similar. Extensive experiments demonstrate that OPTIMA significantly enhances the transferability and sample-efficiency of prompt tuning compared to strong baselines. Moreover, in few-shot settings, OPTIMA exceeds full-model tuning by a large margin.
MTU-Net: Multi-level TransUNet for Space-based Infrared Tiny Ship Detection
Sep 28, 2022
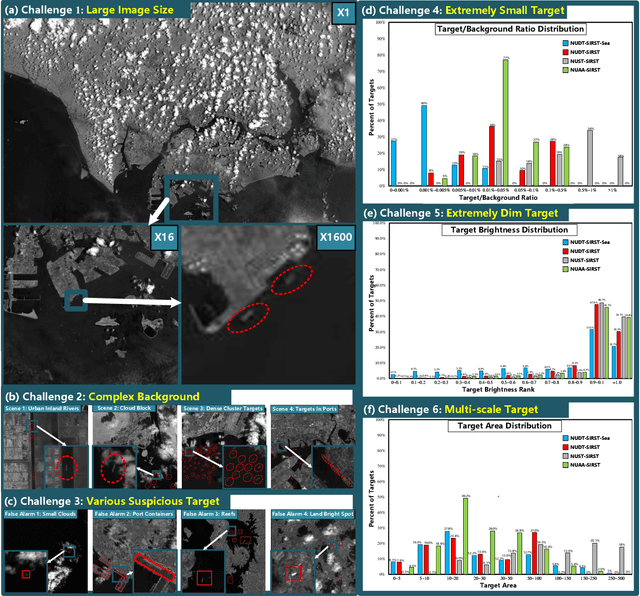
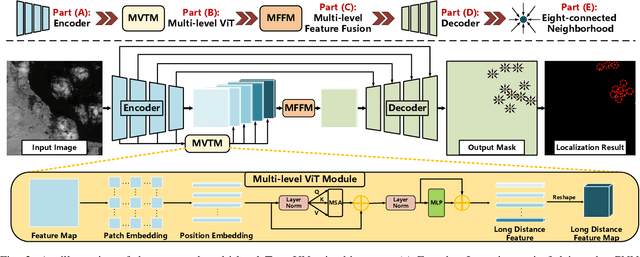
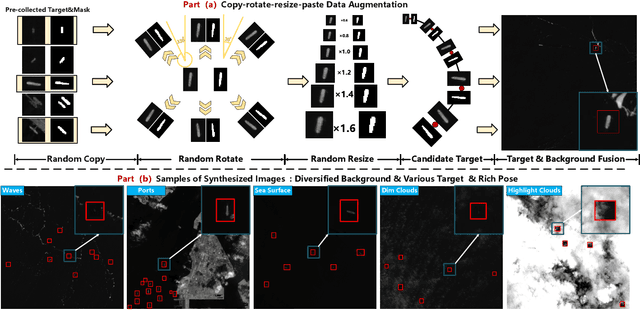
Space-based infrared tiny ship detection aims at separating tiny ships from the images captured by earth orbiting satellites. Due to the extremely large image coverage area (e.g., thousands square kilometers), candidate targets in these images are much smaller, dimer, more changeable than those targets observed by aerial-based and land-based imaging devices. Existing short imaging distance-based infrared datasets and target detection methods cannot be well adopted to the space-based surveillance task. To address these problems, we develop a space-based infrared tiny ship detection dataset (namely, NUDT-SIRST-Sea) with 48 space-based infrared images and 17598 pixel-level tiny ship annotations. Each image covers about 10000 square kilometers of area with 10000X10000 pixels. Considering the extreme characteristics (e.g., small, dim, changeable) of those tiny ships in such challenging scenes, we propose a multi-level TransUNet (MTU-Net) in this paper. Specifically, we design a Vision Transformer (ViT) Convolutional Neural Network (CNN) hybrid encoder to extract multi-level features. Local feature maps are first extracted by several convolution layers and then fed into the multi-level feature extraction module (MVTM) to capture long-distance dependency. We further propose a copy-rotate-resize-paste (CRRP) data augmentation approach to accelerate the training phase, which effectively alleviates the issue of sample imbalance between targets and background. Besides, we design a FocalIoU loss to achieve both target localization and shape description. Experimental results on the NUDT-SIRST-Sea dataset show that our MTU-Net outperforms traditional and existing deep learning based SIRST methods in terms of probability of detection, false alarm rate and intersection over union.
Minimalist and High-performance Conversational Recommendation with Uncertainty Estimation for User Preference
Jul 01, 2022

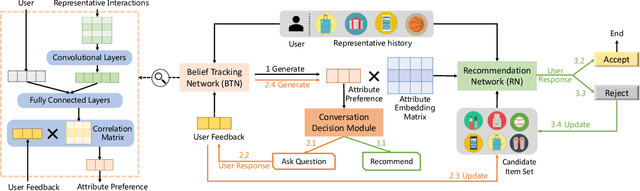
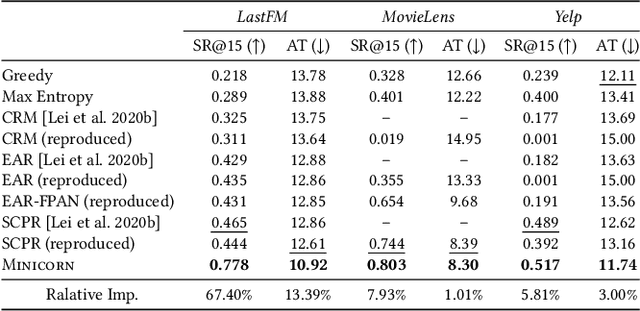
Conversational recommendation system (CRS) is emerging as a user-friendly way to capture users' dynamic preferences over candidate items and attributes. Multi-shot CRS is designed to make recommendations multiple times until the user either accepts the recommendation or leaves at the end of their patience. Existing works are trained with reinforcement learning (RL), which may suffer from unstable learning and prohibitively high demands for computing. In this work, we propose a simple and efficient CRS, MInimalist Non-reinforced Interactive COnversational Recommender Network (MINICORN). MINICORN models the epistemic uncertainty of the estimated user preference and queries the user for the attribute with the highest uncertainty. The system employs a simple network architecture and makes the query-vs-recommendation decision using a single rule. Somewhat surprisingly, this minimalist approach outperforms state-of-the-art RL methods on three real-world datasets by large margins. We hope that MINICORN will serve as a valuable baseline for future research.
Efficient Self-supervised Vision Pretraining with Local Masked Reconstruction
Jun 01, 2022
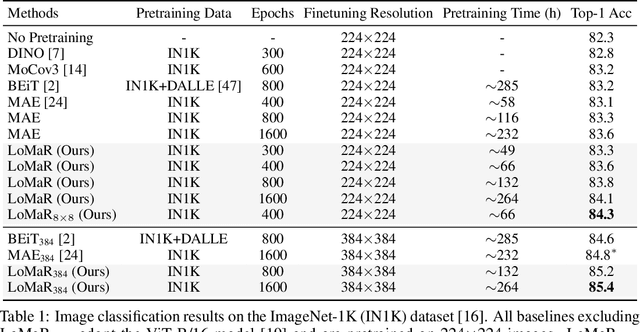
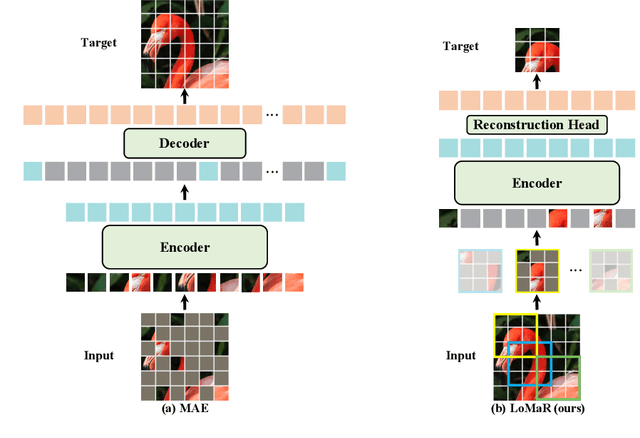
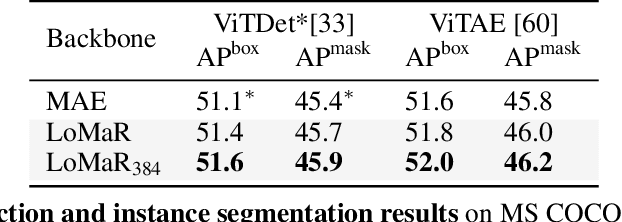
Self-supervised learning for computer vision has achieved tremendous progress and improved many downstream vision tasks such as image classification, semantic segmentation, and object detection. Among these, generative self-supervised vision learning approaches such as MAE and BEiT show promising performance. However, their global masked reconstruction mechanism is computationally demanding. To address this issue, we propose local masked reconstruction (LoMaR), a simple yet effective approach that performs masked reconstruction within a small window of 7$\times$7 patches on a simple Transformer encoder, improving the trade-off between efficiency and accuracy compared to global masked reconstruction over the entire image. Extensive experiments show that LoMaR reaches 84.1% top-1 accuracy on ImageNet-1K classification, outperforming MAE by 0.5%. After finetuning the pretrained LoMaR on 384$\times$384 images, it can reach 85.4% top-1 accuracy, surpassing MAE by 0.6%. On MS COCO, LoMaR outperforms MAE by 0.5 $\text{AP}^\text{box}$ on object detection and 0.5 $\text{AP}^\text{mask}$ on instance segmentation. LoMaR is especially more computation-efficient on pretraining high-resolution images, e.g., it is 3.1$\times$ faster than MAE with 0.2% higher classification accuracy on pretraining 448$\times$448 images. This local masked reconstruction learning mechanism can be easily integrated into any other generative self-supervised learning approach. Our code will be publicly available.
Synopses of Movie Narratives: a Video-Language Dataset for Story Understanding
Mar 11, 2022

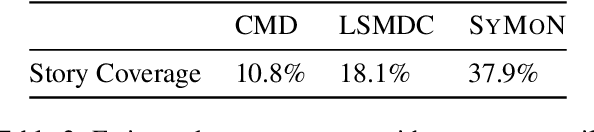
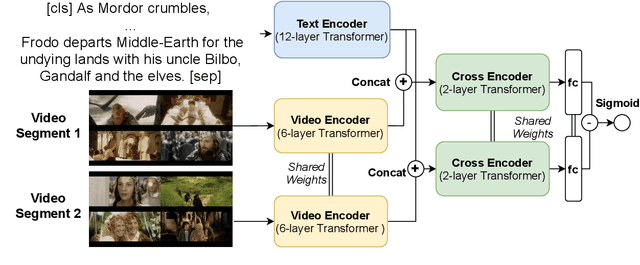
Despite recent advances of AI, story understanding remains an open and under-investigated problem. We collect, preprocess, and publicly release a video-language story dataset, Synopses of Movie Narratives(SyMoN), containing 5,193 video summaries of popular movies and TV series. SyMoN captures naturalistic storytelling videos for human audience made by human creators, and has higher story coverage and more frequent mental-state references than similar video-language story datasets. Differing from most existing video-text datasets, SyMoN features large semantic gaps between the visual and the textual modalities due to the prevalence of reporting bias and mental state descriptions. We establish benchmarks on video-text retrieval and zero-shot alignment on movie summary videos. With SyMoN, we hope to lay the groundwork for progress in multimodal story understanding.