 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAP: The Vulnerability-Adaptive Protection Paradigm Toward Reliable Autonomous Machines
Sep 30, 2024



The next ubiquitous computing platform, following personal computers and smartphones, is poised to be inherently autonomous, encompassing technologies like drones, robots, and self-driving cars. Ensuring reliability for these autonomous machines is critical. However, current resiliency solutions make fundamental trade-offs between reliability and cost, resulting in significant overhead in performance, energy consumption, and chip area. This is due to the "one-size-fits-all" approach commonly used, where the same protection scheme is applied throughout the entire software computing stack. This paper presents the key insight that to achieve high protection coverage with minimal cost, we must leverage the inherent variations in robustness across different layers of the autonomous machine software stack. Specifically, we demonstrate that various nodes in this complex stack exhibit different levels of robustness against hardware faults. Our findings reveal that the front-end of an autonomous machine's software stack tends to be more robust, whereas the back-end is generally more vulnerable. Building on these inherent robustness differences, we propose a Vulnerability-Adaptive Protection (VAP) design paradigm. In this paradigm, the allocation of protection resources - whether spatially (e.g., through modular redundancy) or temporally (e.g., via re-execution) - is made inversely proportional to the inherent robustness of tasks or algorithms within the autonomous machine system. Experimental results show that VAP provides high protection coverage while maintaining low overhead in both autonomous vehicle and drone systems.
Esports Debut as a Medal Event at 2023 Asian Games: Exploring Public Perceptions with BERTopic and GPT-4 Topic Fine-Tuning
Sep 27, 2024This study examined the public opinions of esports at the 2023 Asian Games and value co-creation during the event using an LLM-enhanced BERTopic modeling analysis. We identified five major themes representing public perceptions, as well as how major stakeholders co-created value within and beyond the esports ecosystem. Key findings highlighted the strategic use of social media marketing to influence public opinion and promote esports events and brands, emphasizing the importance of event logistics and infrastructure. Additionally, the study revealed the co-creation value contributed by stakeholders outside the traditional esports ecosystem, particularly in promoting national representation and performance. Our findings supported the ongoing efforts to legitimize esports as a sport, noting that mainstream recognition remains a challenge. The inclusion of esports as a medal event showcased broader acceptance and helped mitigate negative public perceptions. Moreover, contributions from non-traditional stakeholders underscored the value of cross-subcultural collaborations in esports.
Corki: Enabling Real-time Embodied AI Robots via Algorithm-Architecture Co-Design
Jul 05, 2024



Embodied AI robots have the potential to fundamentally improve the way human beings live and manufacture. Continued progress in the burgeoning field of using large language models to control robots depends critically on an efficient computing substrate. In particular, today's computing systems for embodied AI robots are designed purely based on the interest of algorithm developers, where robot actions are divided into a discrete frame-basis. Such an execution pipeline creates high latency and energy consumption. This paper proposes Corki, an algorithm-architecture co-design framework for real-time embodied AI robot control. Our idea is to decouple LLM inference, robotic control and data communication in the embodied AI robots compute pipeline. Instead of predicting action for one single frame, Corki predicts the trajectory for the near future to reduce the frequency of LLM inference. The algorithm is coupled with a hardware that accelerates transforming trajectory into actual torque signals used to control robots and an execution pipeline that parallels data communication with computation. Corki largely reduces LLM inference frequency by up to 8.0x, resulting in up to 3.6x speed up. The success rate improvement can be up to 17.3%. Code is provided for re-implementation. https://github.com/hyy0613/Corki
Constellation Dataset: Benchmarking High-Altitude Object Detection for an Urban Intersection
Apr 25, 2024



We introduce Constellation, a dataset of 13K images suitable for research on detection of objects in dense urban streetscapes observed from high-elevation cameras, collected for a variety of temporal conditions. The dataset addresses the need for curated data to explore problems in small object detection exemplified by the limited pixel footprint of pedestrians observed tens of meters from above. It enables the testing of object detection models for variations in lighting, building shadows, weather, and scene dynamics. We evaluate contemporary object detection architectures on the dataset, observing that state-of-the-art methods have lower performance in detecting small pedestrians compared to vehicles, corresponding to a 10% difference in average precision (AP). Using structurally similar datasets for pretraining the models results in an increase of 1.8% mean AP (mAP). We further find that incorporating domain-specific data augmentations helps improve model performance. Using pseudo-labeled data, obtained from inference outcomes of the best-performing models, improves the performance of the models. Finally, comparing the models trained using the data collected in two different time intervals, we find a performance drift in models due to the changes in intersection conditions over time. The best-performing model achieves a pedestrian AP of 92.0% with 11.5 ms inference time on NVIDIA A100 GPUs, and an mAP of 95.4%.
Autonomy 2.0: The Quest for Economies of Scale
Jul 08, 2023



With the advancement of robotics and AI technologies in the past decade, we have now entered the age of autonomous machines. In this new age of information technology, autonomous machines, such as service robots, autonomous drones, delivery robots, and autonomous vehicles, rather than humans, will provide services. In this article, through examining the technical challenges and economic impact of the digital economy, we argue that scalability is both highly necessary from a technical perspective and significantly advantageous from an economic perspective, thus is the key for the autonomy industry to achieve its full potential. Nonetheless, the current development paradigm, dubbed Autonomy 1.0, scales with the number of engineers, instead of with the amount of data or compute resources, hence preventing the autonomy industry to fully benefit from the economies of scale, especially the exponentially cheapening compute cost and the explosion of available data. We further analyze the key scalability blockers and explain how a new development paradigm, dubbed Autonomy 2.0, can address these problems to greatly boost the autonomy industry.
Data and Knowledge Co-driving for Cancer Subtype Classification on Multi-Scale Histopathological Slides
Apr 18, 2023



Artificial intelligence-enabled histopathological data analysis has become a valuable assistant to the pathologist. However, existing models lack representation and inference abilities compared with those of pathologists, especially in cancer subtype diagnosis, which is unconvincing in clinical practice. For instance, pathologists typically observe the lesions of a slide from global to local, and then can give a diagnosis based on their knowledge and experience. In this paper, we propose a Data and Knowledge Co-driving (D&K) model to replicate the process of cancer subtype classification on a histopathological slide like a pathologist. Specifically, in the data-driven module, the bagging mechanism in ensemble learning is leveraged to integrate the histological features from various bags extracted by the embedding representation unit. Furthermore, a knowledge-driven module is established based on the Gestalt principle in psychology to build the three-dimensional (3D) expert knowledge space and map histological features into this space for metric. Then, the diagnosis can be made according to the Euclidean distance between them. Extensive experimental results on both public and in-house datasets demonstrate that the D&K model has a high performance and credible results compared with the state-of-the-art methods for diagnosing histopathological subtypes. Code: https://github.com/Dennis-YB/Data-and-Knowledge-Co-driving-for-Cancer-Subtypes-Classification
Multi-Modality Multi-Scale Cardiovascular Disease Subtypes Classification Using Raman Image and Medical History
Apr 18, 2023



Raman spectroscopy (RS) has been widely used for disease diagnosis, e.g., cardiovascular disease (CVD), owing to its efficiency and component-specific testing capabilities. A series of popular deep learning methods have recently been introduced to learn nuance features from RS for binary classifications and achieved outstanding performance than conventional machine learning methods. However, these existing deep learning methods still confront some challenges in classifying subtypes of CVD. For example, the nuance between subtypes is quite hard to capture and represent by intelligent models due to the chillingly similar shape of RS sequences. Moreover, medical history information is an essential resource for distinguishing subtypes, but they are underutilized. In light of this, we propose a multi-modality multi-scale model called M3S, which is a novel deep learning method with two core modules to address these issues. First, we convert RS data to various resolution images by the Gramian angular field (GAF) to enlarge nuance, and a two-branch structure is leveraged to get embeddings for distinction in the multi-scale feature extraction module. Second, a probability matrix and a weight matrix are used to enhance the classification capacity by combining the RS and medical history data in the multi-modality data fusion module. We perform extensive evaluations of M3S and found its outstanding performance on our in-house dataset, with accuracy, precision, recall, specificity, and F1 score of 0.9330, 0.9379, 0.9291, 0.9752, and 0.9334, respectively. These results demonstrate that the M3S has high performance and robustness compared with popular methods in diagnosing CVD subtypes.
Thales: Formulating and Estimating Architectural Vulnerability Factors for DNN Accelerators
Dec 05, 2022



As Deep Neural Networks (DNNs) are increasingly deployed in safety critical and privacy sensitive applications such as autonomous driving and biometric authentication, it is critical to understand the fault-tolerance nature of DNNs. Prior work primarily focuses on metrics such as Failures In Time (FIT) rate and the Silent Data Corruption (SDC) rate, which quantify how often a device fails. Instead, this paper focuses on quantifying the DNN accuracy given that a transient error has occurred, which tells us how well a network behaves when a transient error occurs. We call this metric Resiliency Accuracy (RA). We show that existing RA formulation is fundamentally inaccurate, because it incorrectly assumes that software variables (model weights/activations) have equal faulty probability under hardware transient faults. We present an algorithm that captures the faulty probabilities of DNN variables under transient faults and, thus, provides correct RA estimations validated by hardware. To accelerate RA estimation, we reformulate RA calculation as a Monte Carlo integration problem, and solve it using importance sampling driven by DNN specific heuristics. Using our lightweight RA estimation method, we show that transient faults lead to far greater accuracy degradation than what todays DNN resiliency tools estimate. We show how our RA estimation tool can help design more resilient DNNs by integrating it with a Network Architecture Search framework.
INTERNEURON: A Middleware with Multi-Network Communication Reliability for Infrastructure Vehicle Cooperative Autonomous Driving
Oct 28, 2022



Infrastructure-Vehicle Cooperative Autonomous Driving (IVCAD) is a new paradigm of autonomous driving, which relies on the cooperation between intelligent roads and autonomous vehicles. This paradigm has been shown to be safer and more efficient compared to the on-vehicle-only autonomous driving paradigm. Our real-world deployment data indicates that the effectiveness of IVCAD is constrained by reliability and performance of commercial communication networks. This paper targets this exact problem, and proposes INTERNEURON, a middleware to achieve high communication reliability between intelligent roads and autonomous vehicles, in the context of IVCAD. Specifically, INTERNEURON dynamically matches IVCAD applications and the underlying communication technologies based on varying communication performance and quality needs. Evaluation results confirm that INTERNEURON reduces deadline violations by more than 95\%, significantly improving the reliability of IVCAD systems.
Factor Graph Accelerator for LiDAR-Inertial Odometry
Sep 06, 2022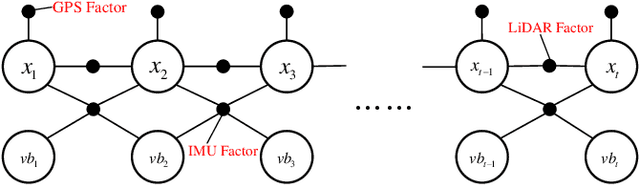
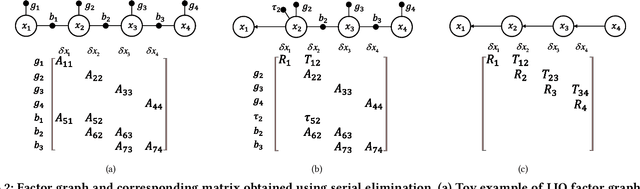
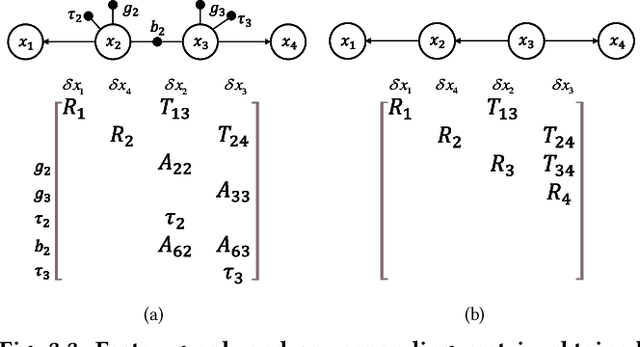

Factor graph is a graph representing the factorization of a probability distribution function, and has been utilized in many autonomous machine computing tasks, such as localization, tracking, planning and control etc. We are developing an architecture with the goal of using factor graph as a common abstraction for most, if not, all autonomous machine computing tasks. If successful, the architecture would provide a very simple interface of mapping autonomous machine functions to the underlying compute hardware. As a first step of such an attempt, this paper presents our most recent work of developing a factor graph accelerator for LiDAR-Inertial Odometry (LIO), an essential task in many autonomous machines, such as autonomous vehicles and mobile robots. By modeling LIO as a factor graph, the proposed accelerator not only supports multi-sensor fusion such as LiDAR, inertial measurement unit (IMU), GPS, etc., but solves the global optimization problem of robot navigation in batch or incremental modes. Our evaluation demonstrates that the proposed design significantly improves the real-time performance and energy efficiency of autonomous machine navigation systems. The initial success suggests the potential of generalizing the factor graph architecture as a common abstraction for autonomous machine computing, including tracking, planning, and control etc.