 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRainNet: A Large-Scale Dataset for Spatial Precipitation Downscaling
Dec 18, 2020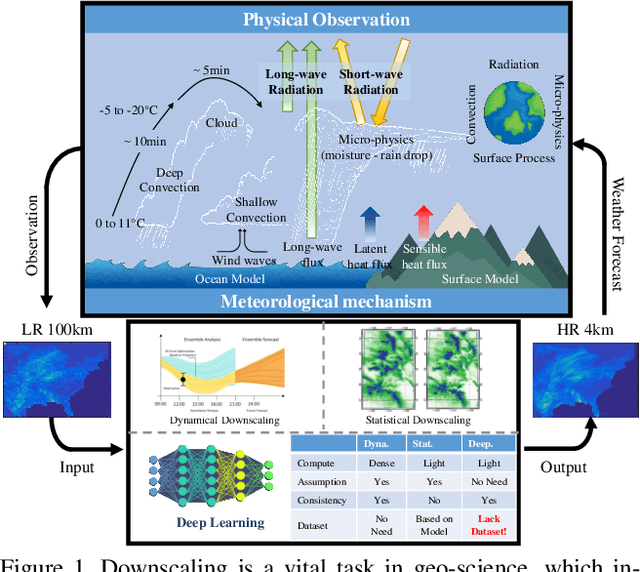
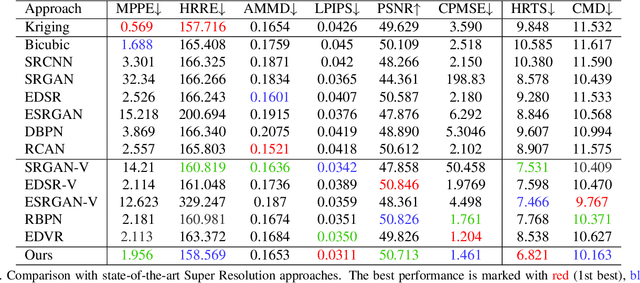
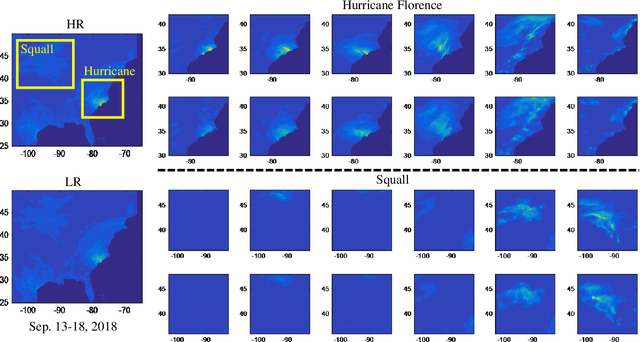
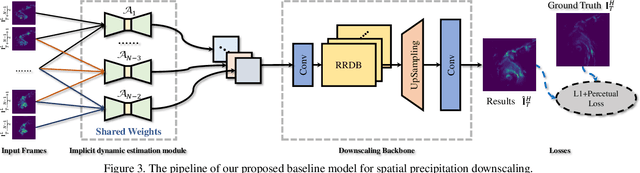
Spatial Precipitation Downscaling is one of the most important problems in the geo-science community. However, it still remains an unaddressed issue. Deep learning is a promising potential solution for downscaling. In order to facilitate the research on precipitation downscaling for deep learning, we present the first REAL (non-simulated) Large-Scale Spatial Precipitation Downscaling Dataset, RainNet, which contains 62,424 pairs of low-resolution and high-resolution precipitation maps for 17 years. Contrary to simulated data, this real dataset covers various types of real meteorological phenomena (e.g., Hurricane, Squall, etc.), and shows the physical characters - Temporal Misalignment, Temporal Sparse and Fluid Properties - that challenge the downscaling algorithms. In order to fully explore potential downscaling solutions, we propose an implicit physical estimation framework to learn the above characteristics. Eight metrics specifically considering the physical property of the data set are raised, while fourteen models are evaluated on the proposed dataset. Finally, we analyze the effectiveness and feasibility of these models on precipitation downscaling task. The Dataset and Code will be available at https://neuralchen.github.io/RainNet/.
Sketch Generation with Drawing Process Guided by Vector Flow and Grayscale
Dec 16, 2020
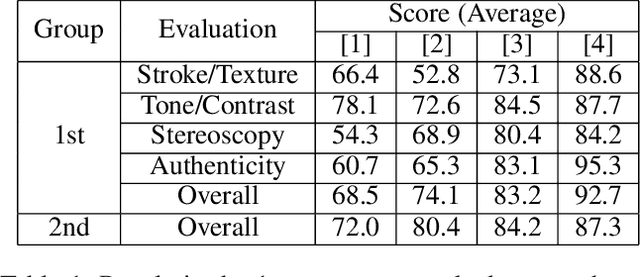
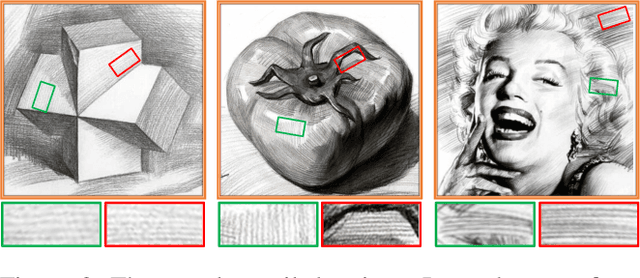
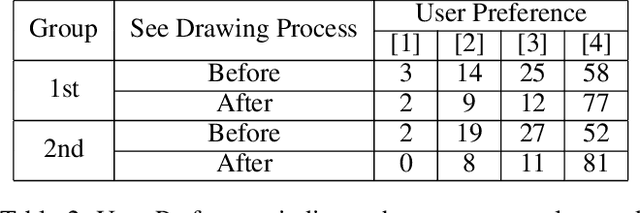
We propose a novel image-to-pencil translation method that could not only generate high-quality pencil sketches but also offer the drawing process. Existing pencil sketch algorithms are based on texture rendering rather than the direct imitation of strokes, making them unable to show the drawing process but only a final result. To address this challenge, we first establish a pencil stroke imitation mechanism. Next, we develop a framework with three branches to guide stroke drawing: the first branch guides the direction of the strokes, the second branch determines the shade of the strokes, and the third branch enhances the details further. Under this framework's guidance, we can produce a pencil sketch by drawing one stroke every time. Our method is fully interpretable. Comparison with existing pencil drawing algorithms shows that our method is superior to others in terms of texture quality, style, and user evaluation.
Omni-GAN: On the Secrets of cGANs and Beyond
Nov 26, 2020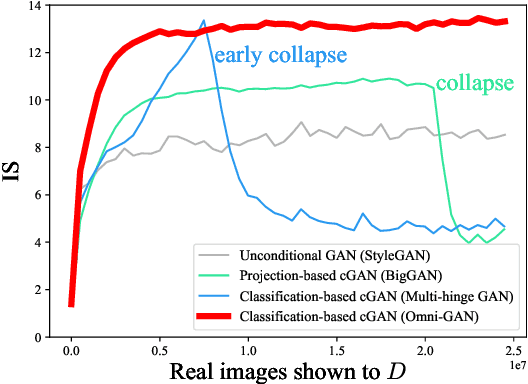
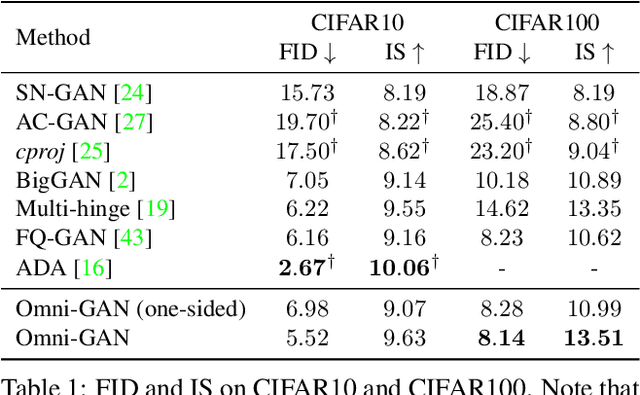
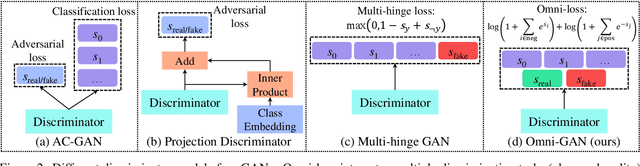
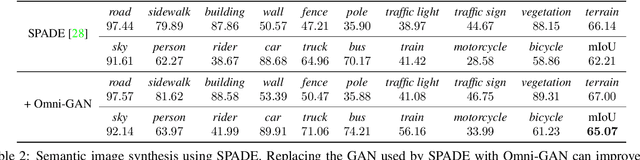
It has been an important problem to design a proper discriminator for conditional generative adversarial networks (cGANs). In this paper, we investigate two popular choices, the projection-based and classification-based discriminators, and reveal that both of them suffer some kind of drawbacks that affect the learning ability of cGANs. Then, we present our solution that trains a powerful discriminator and avoids over-fitting with regularization. In addition, we unify multiple targets (class, domain, reality, etc.) into one loss function to enable a wider range of applications. Our algorithm, named \textbf{Omni-GAN}, achieves competitive performance on a few popular benchmarks. More importantly, Omni-GAN enjoys both high generation quality and low risks in mode collapse, offering new possibilities for optimizing cGANs.Code is available at \url{https://github.com/PeterouZh/Omni-GAN-PyTorch}.
MedMNIST Classification Decathlon: A Lightweight AutoML Benchmark for Medical Image Analysis
Nov 14, 2020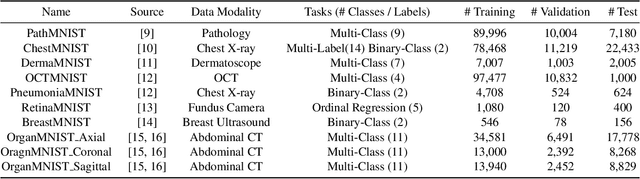
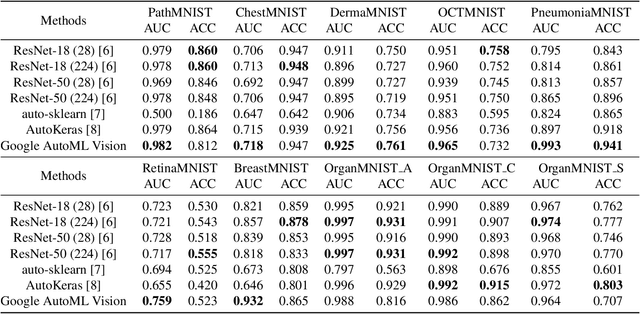

We present MedMNIST, a collection of 10 pre-processed medical open datasets. MedMNIST is standardized to perform classification tasks on lightweight 28x28 images, which requires no background knowledge. Covering the primary data modalities in medical image analysis, it is diverse on data scale (from 100 to 100,000) and tasks (binary/multi-class, ordinal regression and multi-label). MedMNIST could be used for educational purpose, rapid prototyping, multi-modal machine learning or AutoML in medical image analysis. Moreover, MedMNIST Classification Decathlon is designed to benchmark AutoML algorithms on all 10 datasets; We have compared several baseline methods, including open-source or commercial AutoML tools. The datasets, evaluation code and baseline methods for MedMNIST are publicly available at https://medmnist.github.io/.
CooGAN: A Memory-Efficient Framework for High-Resolution Facial Attribute Editing
Nov 03, 2020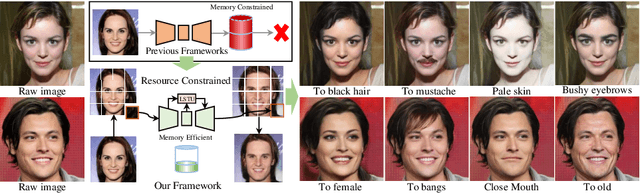

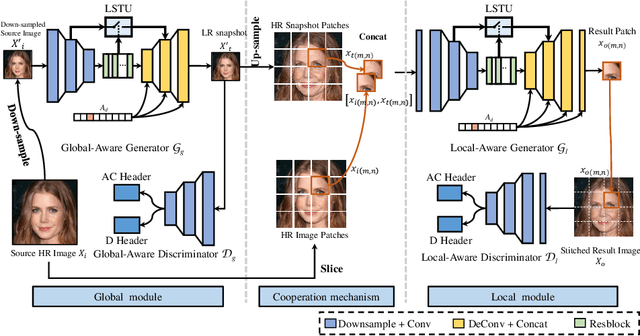

In contrast to great success of memory-consuming face editing methods at a low resolution, to manipulate high-resolution (HR) facial images, i.e., typically larger than 7682 pixels, with very limited memory is still challenging. This is due to the reasons of 1) intractable huge demand of memory; 2) inefficient multi-scale features fusion. To address these issues, we propose a NOVEL pixel translation framework called Cooperative GAN(CooGAN) for HR facial image editing. This framework features a local path for fine-grained local facial patch generation (i.e., patch-level HR, LOW memory) and a global path for global lowresolution (LR) facial structure monitoring (i.e., image-level LR, LOW memory), which largely reduce memory requirements. Both paths work in a cooperative manner under a local-to-global consistency objective (i.e., for smooth stitching). In addition, we propose a lighter selective transfer unit for more efficient multi-scale features fusion, yielding higher fidelity facial attributes manipulation. Extensive experiments on CelebAHQ well demonstrate the memory efficiency as well as the high image generation quality of the proposed framework.
Learning Black-Box Attackers with Transferable Priors and Query Feedback
Oct 21, 2020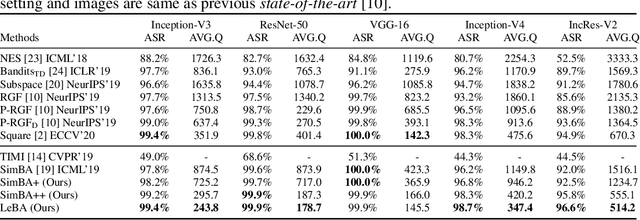
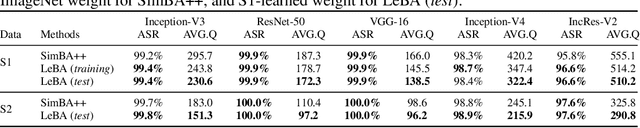
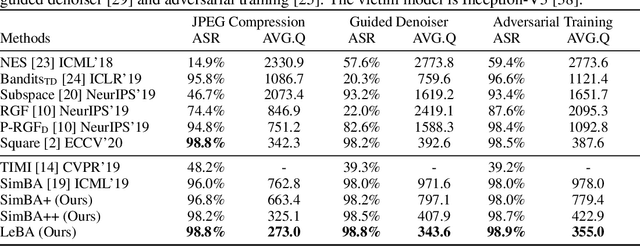

This paper addresses the challenging black-box adversarial attack problem, where only classification confidence of a victim model is available. Inspired by consistency of visual saliency between different vision models, a surrogate model is expected to improve the attack performance via transferability. By combining transferability-based and query-based black-box attack, we propose a surprisingly simple baseline approach (named SimBA++) using the surrogate model, which significantly outperforms several state-of-the-art methods. Moreover, to efficiently utilize the query feedback, we update the surrogate model in a novel learning scheme, named High-Order Gradient Approximation (HOGA). By constructing a high-order gradient computation graph, we update the surrogate model to approximate the victim model in both forward and backward pass. The SimBA++ and HOGA result in Learnable Black-Box Attack (LeBA), which surpasses previous state of the art by considerable margins: the proposed LeBA significantly reduces queries, while keeping higher attack success rates close to 100% in extensive ImageNet experiments, including attacking vision benchmarks and defensive models. Code is open source at https://github.com/TrustworthyDL/LeBA.
Anisotropic Stroke Control for Multiple Artists Style Transfer
Oct 16, 2020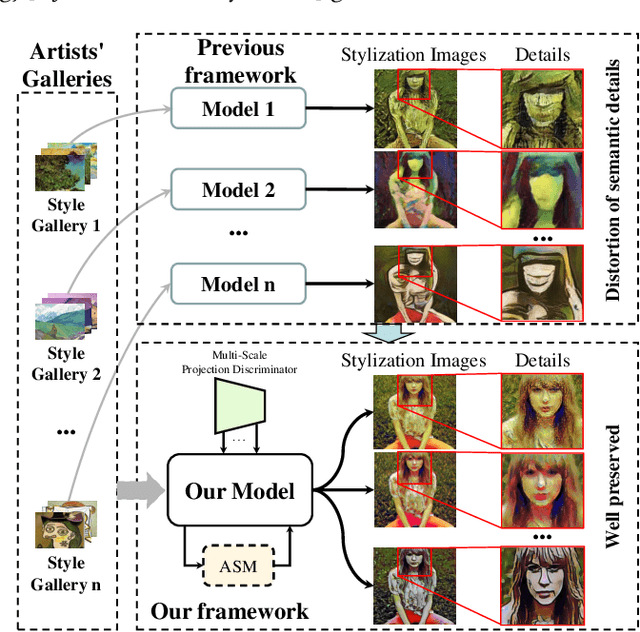
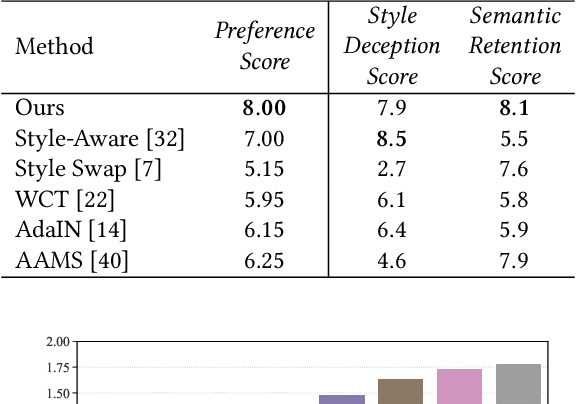

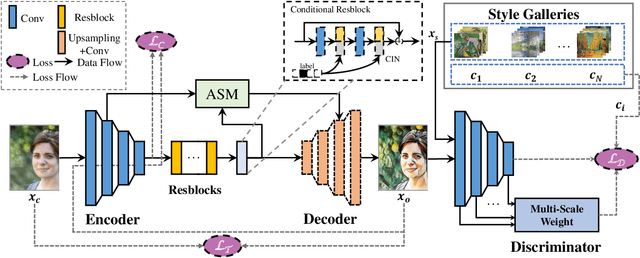
Though significant progress has been made in artistic style transfer, semantic information is usually difficult to be preserved in a fine-grained locally consistent manner by most existing methods, especially when multiple artists styles are required to transfer within one single model. To circumvent this issue, we propose a Stroke Control Multi-Artist Style Transfer framework. On the one hand, we develop a multi-condition single-generator structure which first performs multi-artist style transfer. On the one hand, we design an Anisotropic Stroke Module (ASM) which realizes the dynamic adjustment of style-stroke between the non-trivial and the trivial regions. ASM endows the network with the ability of adaptive semantic-consistency among various styles. On the other hand, we present an novel Multi-Scale Projection Discriminator} to realize the texture-level conditional generation. In contrast to the single-scale conditional discriminator, our discriminator is able to capture multi-scale texture clue to effectively distinguish a wide range of artistic styles. Extensive experimental results well demonstrate the feasibility and effectiveness of our approach. Our framework can transform a photograph into different artistic style oil painting via only ONE single model. Furthermore, the results are with distinctive artistic style and retain the anisotropic semantic information.
MIA-Prognosis: A Deep Learning Framework to Predict Therapy Response
Oct 08, 2020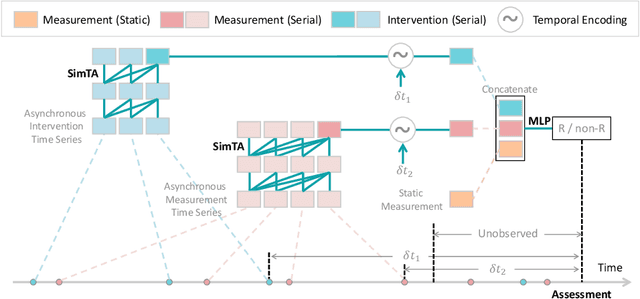
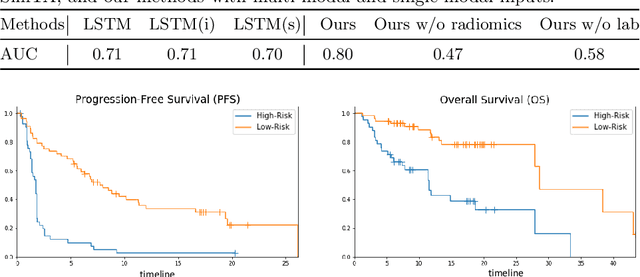
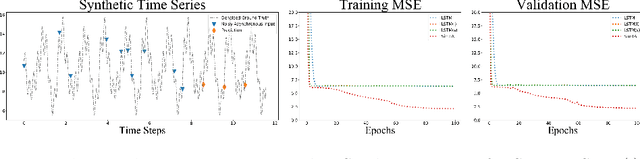
Predicting clinical outcome is remarkably important but challenging. Research efforts have been paid on seeking significant biomarkers associated with the therapy response or/and patient survival. However, these biomarkers are generally costly and invasive, and possibly dissatifactory for novel therapy. On the other hand, multi-modal, heterogeneous, unaligned temporal data is continuously generated in clinical practice. This paper aims at a unified deep learning approach to predict patient prognosis and therapy response, with easily accessible data, e.g., radiographics, laboratory and clinical information. Prior arts focus on modeling single data modality, or ignore the temporal changes. Importantly, the clinical time series is asynchronous in practice, i.e., recorded with irregular intervals. In this study, we formalize the prognosis modeling as a multi-modal asynchronous time series classification task, and propose a MIA-Prognosis framework with Measurement, Intervention and Assessment (MIA) information to predict therapy response, where a Simple Temporal Attention (SimTA) module is developed to process the asynchronous time series. Experiments on synthetic dataset validate the superiory of SimTA over standard RNN-based approaches. Furthermore, we experiment the proposed method on an in-house, retrospective dataset of real-world non-small cell lung cancer patients under anti-PD-1 immunotherapy. The proposed method achieves promising performance on predicting the immunotherapy response. Notably, our predictive model could further stratify low-risk and high-risk patients in terms of long-term survival.
Hierarchical Classification of Pulmonary Lesions: A Large-Scale Radio-Pathomics Study
Oct 08, 2020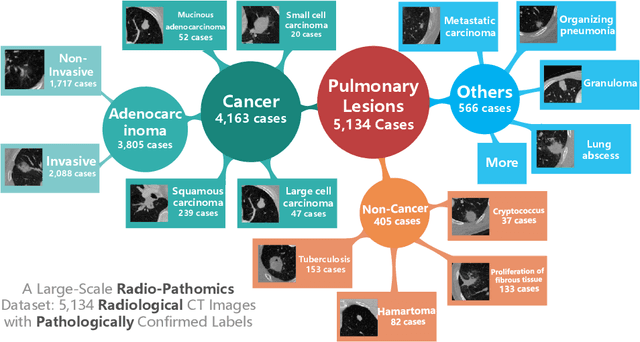
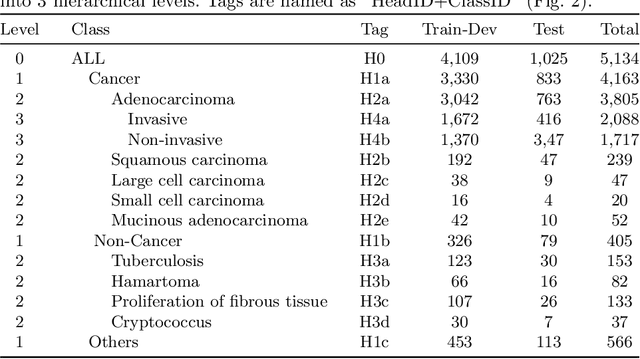
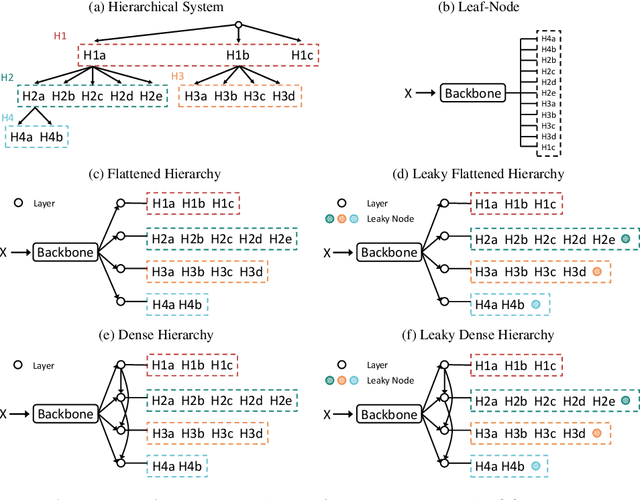
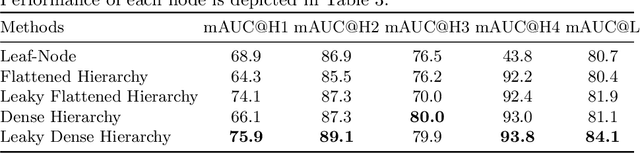
Diagnosis of pulmonary lesions from computed tomography (CT) is important but challenging for clinical decision making in lung cancer related diseases. Deep learning has achieved great success in computer aided diagnosis (CADx) area for lung cancer, whereas it suffers from label ambiguity due to the difficulty in the radiological diagnosis. Considering that invasive pathological analysis serves as the clinical golden standard of lung cancer diagnosis, in this study, we solve the label ambiguity issue via a large-scale radio-pathomics dataset containing 5,134 radiological CT images with pathologically confirmed labels, including cancers (e.g., invasive/non-invasive adenocarcinoma, squamous carcinoma) and non-cancer diseases (e.g., tuberculosis, hamartoma). This retrospective dataset, named Pulmonary-RadPath, enables development and validation of accurate deep learning systems to predict invasive pathological labels with a non-invasive procedure, i.e., radiological CT scans. A three-level hierarchical classification system for pulmonary lesions is developed, which covers most diseases in cancer-related diagnosis. We explore several techniques for hierarchical classification on this dataset, and propose a Leaky Dense Hierarchy approach with proven effectiveness in experiments. Our study significantly outperforms prior arts in terms of data scales (6x larger), disease comprehensiveness and hierarchies. The promising results suggest the potentials to facilitate precision medicine.
Hierarchical Style-based Networks for Motion Synthesis
Aug 24, 2020

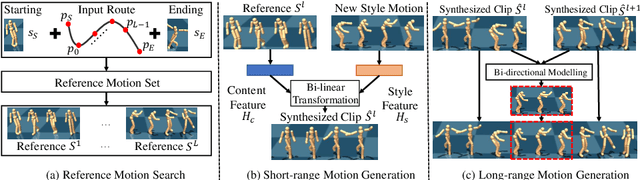
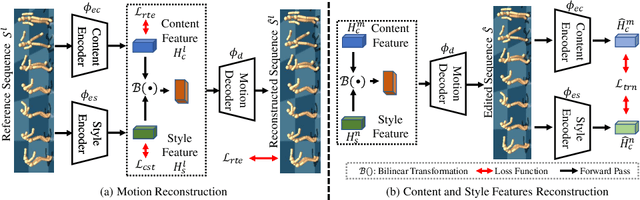
Generating diverse and natural human motion is one of the long-standing goals for creating intelligent characters in the animated world. In this paper, we propose a self-supervised method for generating long-range, diverse and plausible behaviors to achieve a specific goal location. Our proposed method learns to model the motion of human by decomposing a long-range generation task in a hierarchical manner. Given the starting and ending states, a memory bank is used to retrieve motion references as source material for short-range clip generation. We first propose to explicitly disentangle the provided motion material into style and content counterparts via bi-linear transformation modelling, where diverse synthesis is achieved by free-form combination of these two components. The short-range clips are then connected to form a long-range motion sequence. Without ground truth annotation, we propose a parameterized bi-directional interpolation scheme to guarantee the physical validity and visual naturalness of generated results. On large-scale skeleton dataset, we show that the proposed method is able to synthesise long-range, diverse and plausible motion, which is also generalizable to unseen motion data during testing. Moreover, we demonstrate the generated sequences are useful as subgoals for actual physical execution in the animated world.