 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimPO: Simultaneous Prediction and Optimization
Mar 31, 2022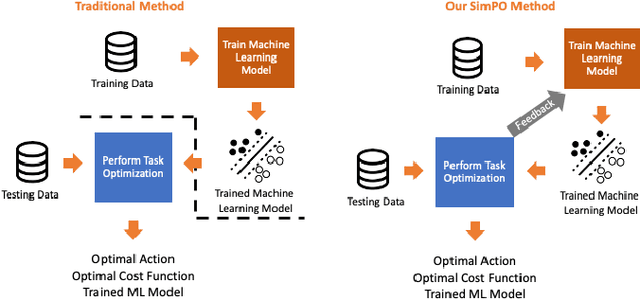
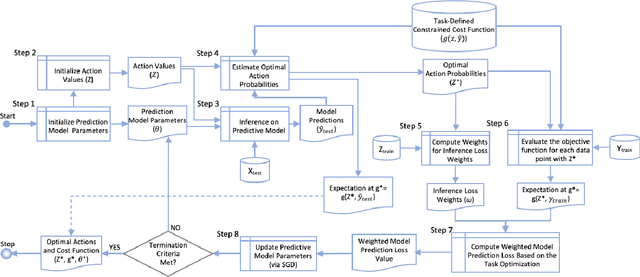
Many machine learning (ML) models are integrated within the context of a larger system as part of a key component for decision making processes. Concretely, predictive models are often employed in estimating the parameters for the input values that are utilized for optimization models as isolated processes. Traditionally, the predictive models are built first, then the model outputs are used to generate decision values separately. However, it is often the case that the prediction values that are trained independently of the optimization process produce sub-optimal solutions. In this paper, we propose a formulation for the Simultaneous Prediction and Optimization (SimPO) framework. This framework introduces the use of a joint weighted loss of a decision-driven predictive ML model and an optimization objective function, which is optimized end-to-end directly through gradient-based methods.
SpectralFormer: Rethinking Hyperspectral Image Classification with Transformers
Jul 07, 2021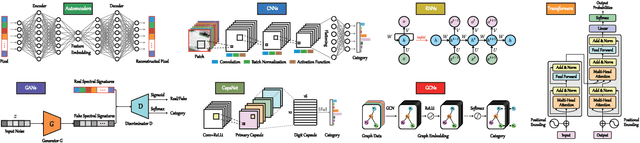
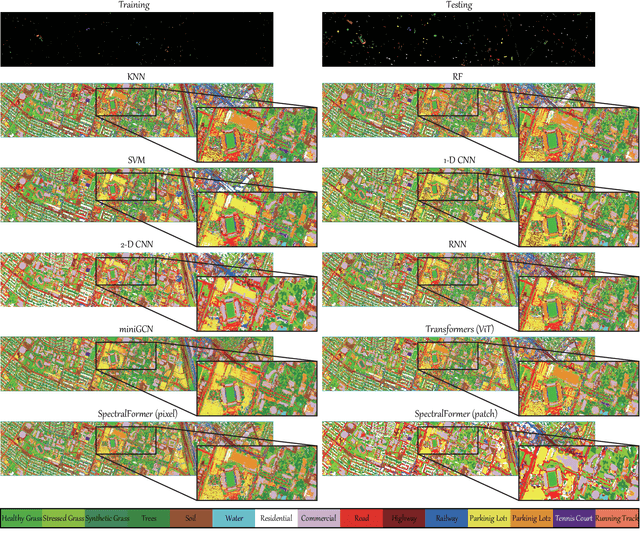
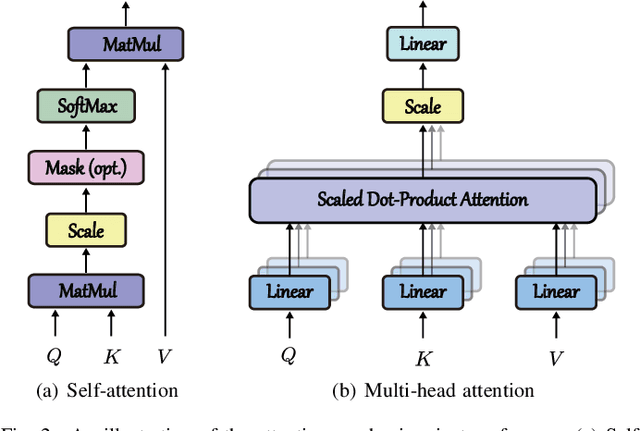
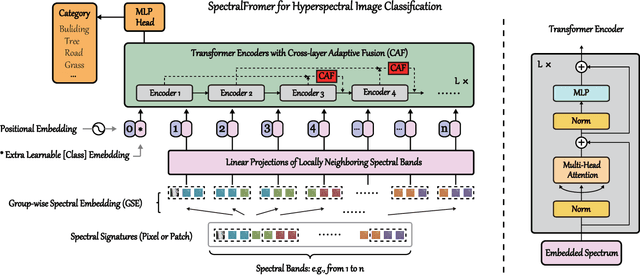
Hyperspectral (HS) images are characterized by approximately contiguous spectral information, enabling the fine identification of materials by capturing subtle spectral discrepancies. Owing to their excellent locally contextual modeling ability, convolutional neural networks (CNNs) have been proven to be a powerful feature extractor in HS image classification. However, CNNs fail to mine and represent the sequence attributes of spectral signatures well due to the limitations of their inherent network backbone. To solve this issue, we rethink HS image classification from a sequential perspective with transformers, and propose a novel backbone network called \ul{SpectralFormer}. Beyond band-wise representations in classic transformers, SpectralFormer is capable of learning spectrally local sequence information from neighboring bands of HS images, yielding group-wise spectral embeddings. More significantly, to reduce the possibility of losing valuable information in the layer-wise propagation process, we devise a cross-layer skip connection to convey memory-like components from shallow to deep layers by adaptively learning to fuse "soft" residuals across layers. It is worth noting that the proposed SpectralFormer is a highly flexible backbone network, which can be applicable to both pixel- and patch-wise inputs. We evaluate the classification performance of the proposed SpectralFormer on three HS datasets by conducting extensive experiments, showing the superiority over classic transformers and achieving a significant improvement in comparison with state-of-the-art backbone networks. The codes of this work will be available at \url{https://sites.google.com/view/danfeng-hong} for the sake of reproducibility.
An Attention-Fused Network for Semantic Segmentation of Very-High-Resolution Remote Sensing Imagery
May 28, 2021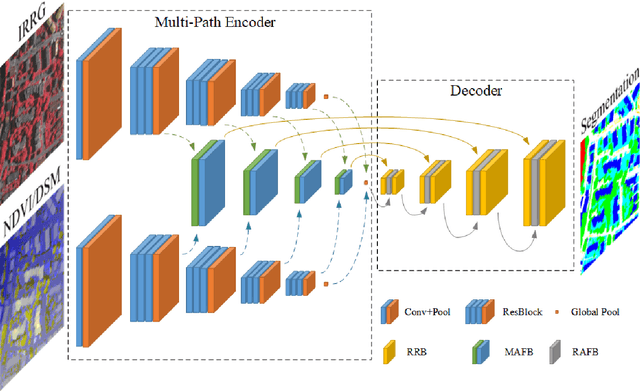
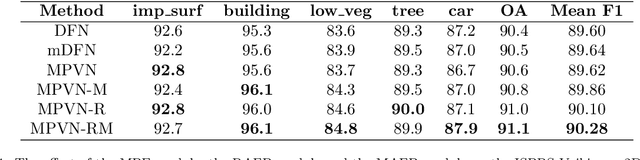
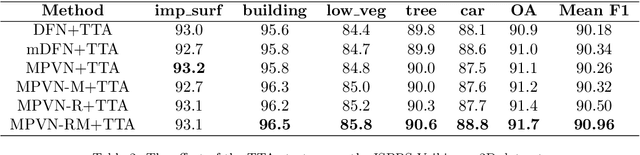
Semantic segmentation is an essential part of deep learning. In recent years, with the development of remote sensing big data, semantic segmentation has been increasingly used in remote sensing. Deep convolutional neural networks (DCNNs) face the challenge of feature fusion: very-high-resolution remote sensing image multisource data fusion can increase the network's learnable information, which is conducive to correctly classifying target objects by DCNNs; simultaneously, the fusion of high-level abstract features and low-level spatial features can improve the classification accuracy at the border between target objects. In this paper, we propose a multipath encoder structure to extract features of multipath inputs, a multipath attention-fused block module to fuse multipath features, and a refinement attention-fused block module to fuse high-level abstract features and low-level spatial features. Furthermore, we propose a novel convolutional neural network architecture, named attention-fused network (AFNet). Based on our AFNet, we achieve state-of-the-art performance with an overall accuracy of 91.7% and a mean F1 score of 90.96% on the ISPRS Vaihingen 2D dataset and an overall accuracy of 92.1% and a mean F1 score of 93.44% on the ISPRS Potsdam 2D dataset.
* 35 pages. Published by ISPRS Journal of Photogrammetry and Remote Sensing
FCCDN: Feature Constraint Network for VHR Image Change Detection
May 23, 2021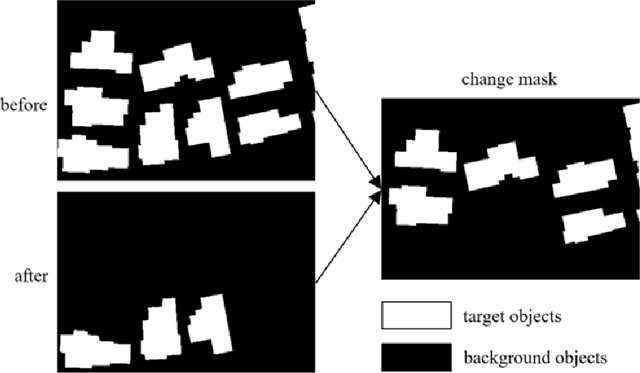

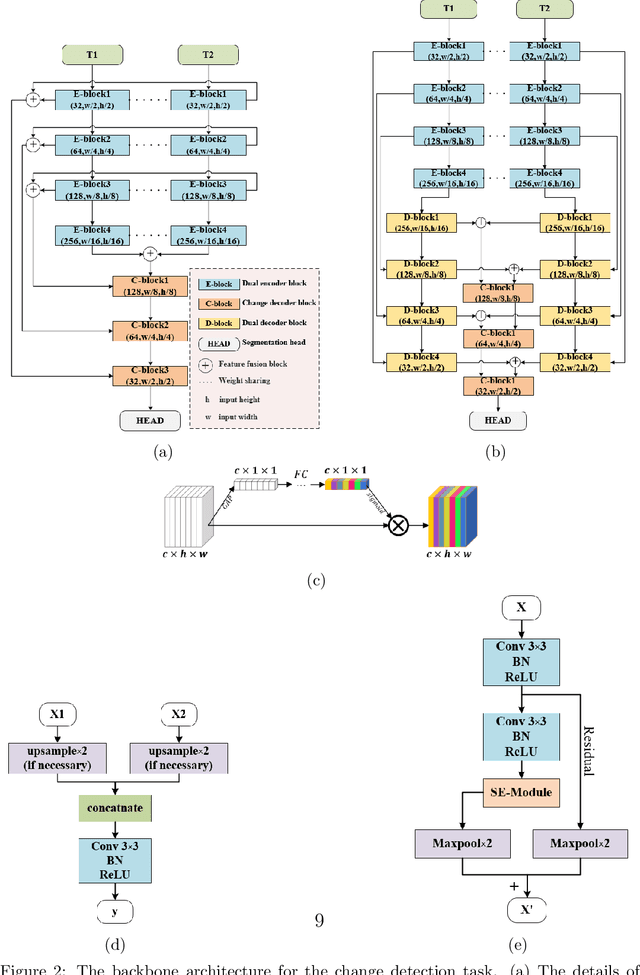
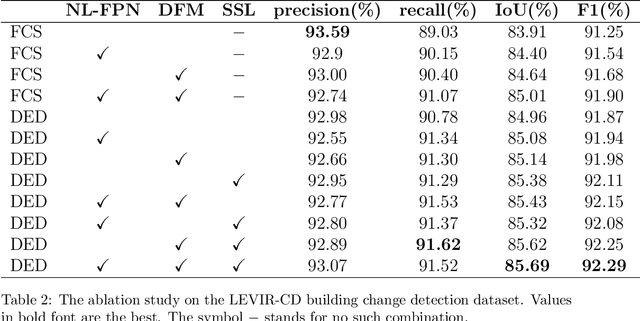
Change detection is the process of identifying pixel-wise differences of bi-temporal co-registered images. It is of great significance to Earth observation. Recently, with the emerging of deep learning (DL), deep convolutional neural networks (CNNs) based methods have shown their power and feasibility in the field of change detection. However, there is still a lack of effective supervision for change feature learning. In this work, a feature constraint change detection network (FCCDN) is proposed. We constrain features both on bi-temporal feature extraction and feature fusion. More specifically, we propose a dual encoder-decoder network backbone for the change detection task. At the center of the backbone, we design a non-local feature pyramid network to extract and fuse multi-scale features. To fuse bi-temporal features in a robust way, we build a dense connection-based feature fusion module. Moreover, a self-supervised learning-based strategy is proposed to constrain feature learning. Based on FCCDN, we achieve state-of-the-art performance on two building change detection datasets (LEVIR-CD and WHU). On the LEVIR-CD dataset, we achieve IoU of 0.8569 and F1 score of 0.9229. On the WHU dataset, we achieve IoU of 0.8820 and F1 score of 0.9373. Moreover, we, for the first time, achieve the acquire of accurate bi-temporal semantic segmentation results without using semantic segmentation labels. It is vital for the application of change detection because it saves the cost of labeling.
Endmember-Guided Unmixing Network (EGU-Net): A General Deep Learning Framework for Self-Supervised Hyperspectral Unmixing
May 21, 2021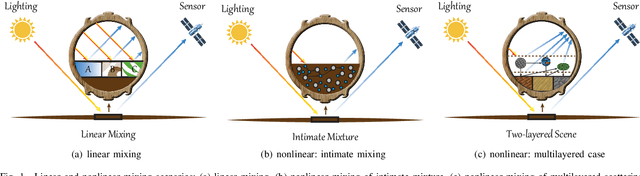
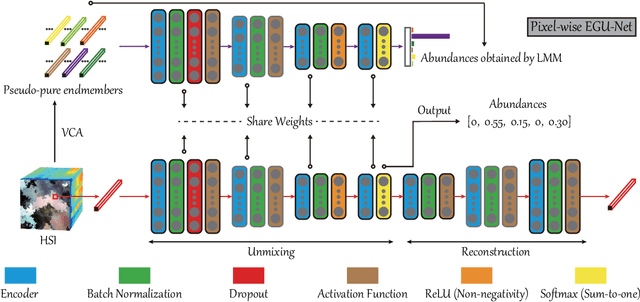
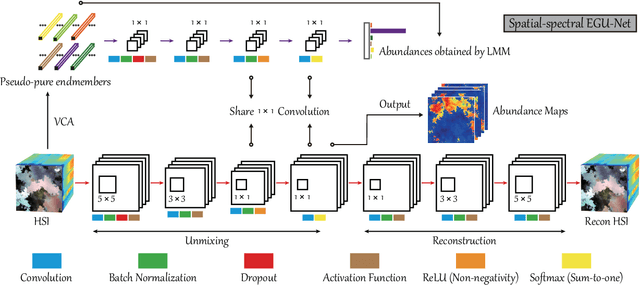

Over the past decades, enormous efforts have been made to improve the performance of linear or nonlinear mixing models for hyperspectral unmixing, yet their ability to simultaneously generalize various spectral variabilities and extract physically meaningful endmembers still remains limited due to the poor ability in data fitting and reconstruction and the sensitivity to various spectral variabilities. Inspired by the powerful learning ability of deep learning, we attempt to develop a general deep learning approach for hyperspectral unmixing, by fully considering the properties of endmembers extracted from the hyperspectral imagery, called endmember-guided unmixing network (EGU-Net). Beyond the alone autoencoder-like architecture, EGU-Net is a two-stream Siamese deep network, which learns an additional network from the pure or nearly-pure endmembers to correct the weights of another unmixing network by sharing network parameters and adding spectrally meaningful constraints (e.g., non-negativity and sum-to-one) towards a more accurate and interpretable unmixing solution. Furthermore, the resulting general framework is not only limited to pixel-wise spectral unmixing but also applicable to spatial information modeling with convolutional operators for spatial-spectral unmixing. Experimental results conducted on three different datasets with the ground-truth of abundance maps corresponding to each material demonstrate the effectiveness and superiority of the EGU-Net over state-of-the-art unmixing algorithms. The codes will be available from the website: https://github.com/danfenghong/IEEE_TNNLS_EGU-Net.
Cross-Modality Brain Tumor Segmentation via Bidirectional Global-to-Local Unsupervised Domain Adaptation
May 17, 2021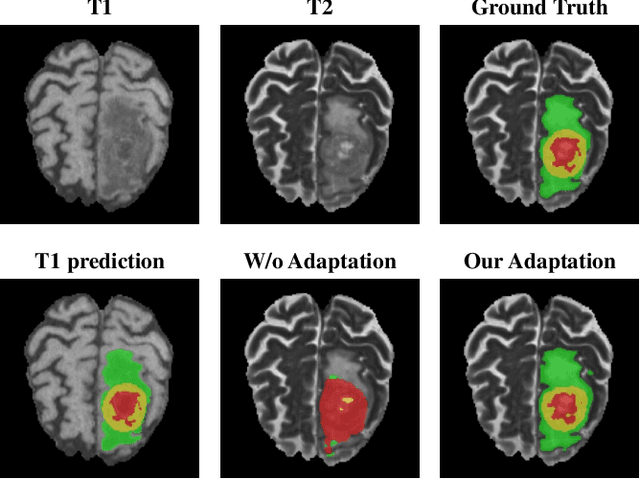
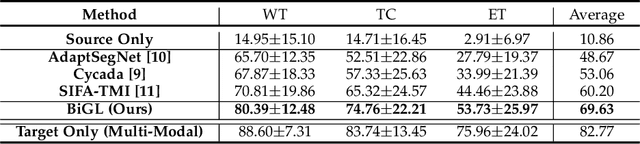
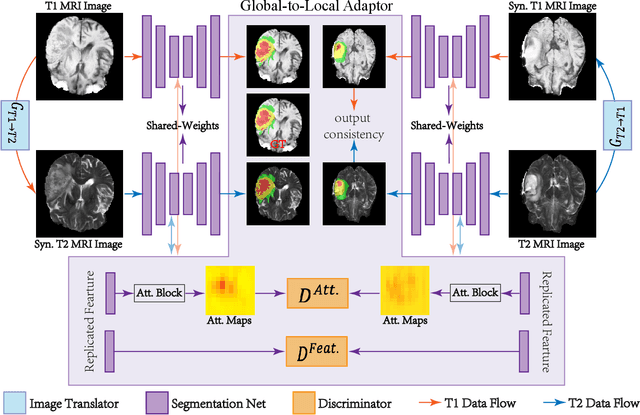
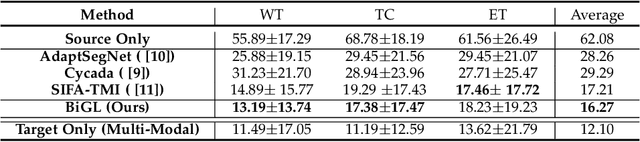
Accurate segmentation of brain tumors from multi-modal Magnetic Resonance (MR) images is essential in brain tumor diagnosis and treatment. However, due to the existence of domain shifts among different modalities, the performance of networks decreases dramatically when training on one modality and performing on another, e.g., train on T1 image while performing on T2 image, which is often required in clinical applications. This also prohibits a network from being trained on labeled data and then transferred to unlabeled data from a different domain. To overcome this, unsupervised domain adaptation (UDA) methods provide effective solutions to alleviate the domain shift between labeled source data and unlabeled target data. In this paper, we propose a novel Bidirectional Global-to-Local (BiGL) adaptation framework under a UDA scheme. Specifically, a bidirectional image synthesis and segmentation module is proposed to segment the brain tumor using the intermediate data distributions generated for the two domains, which includes an image-to-image translator and a shared-weighted segmentation network. Further, a global-to-local consistency learning module is proposed to build robust representation alignments in an integrated way. Extensive experiments on a multi-modal brain MR benchmark dataset demonstrate that the proposed method outperforms several state-of-the-art unsupervised domain adaptation methods by a large margin, while a comprehensive ablation study validates the effectiveness of each key component. The implementation code of our method will be released at \url{https://github.com/KeleiHe/BiGL}.
Using Low-rank Representation of Abundance Maps and Nonnegative Tensor Factorization for Hyperspectral Nonlinear Unmixing
Mar 30, 2021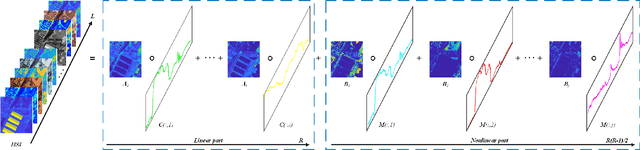

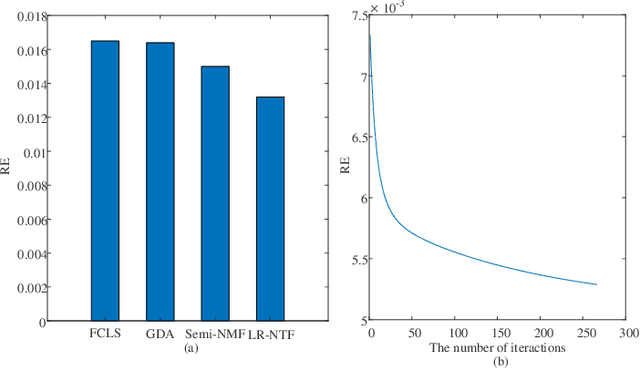
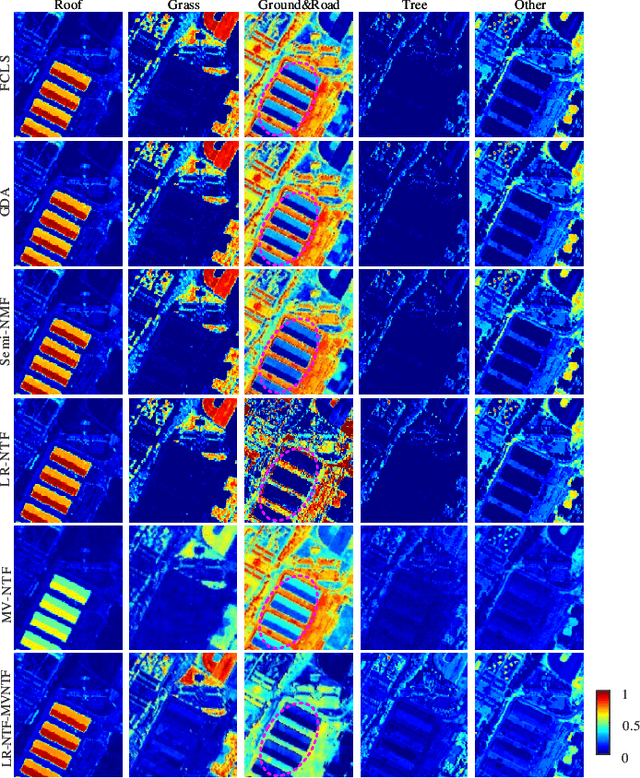
Tensor-based methods have been widely studied to attack inverse problems in hyperspectral imaging since a hyperspectral image (HSI) cube can be naturally represented as a third-order tensor, which can perfectly retain the spatial information in the image. In this article, we extend the linear tensor method to the nonlinear tensor method and propose a nonlinear low-rank tensor unmixing algorithm to solve the generalized bilinear model (GBM). Specifically, the linear and nonlinear parts of the GBM can both be expressed as tensors. Furthermore, the low-rank structures of abundance maps and nonlinear interaction abundance maps are exploited by minimizing their nuclear norm, thus taking full advantage of the high spatial correlation in HSIs. Synthetic and real-data experiments show that the low rank of abundance maps and nonlinear interaction abundance maps exploited in our method can improve the performance of the nonlinear unmixing. A MATLAB demo of this work will be available at https://github.com/LinaZhuang for the sake of reproducibility.
Hyperspectral Image Denoising and Anomaly Detection Based on Low-rank and Sparse Representations
Mar 12, 2021
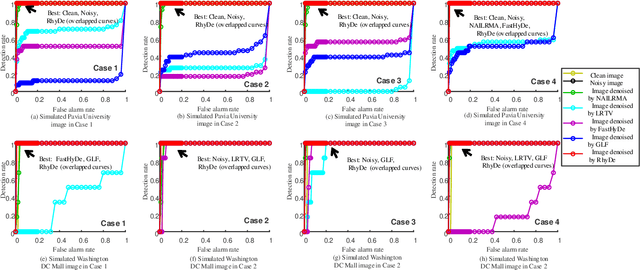
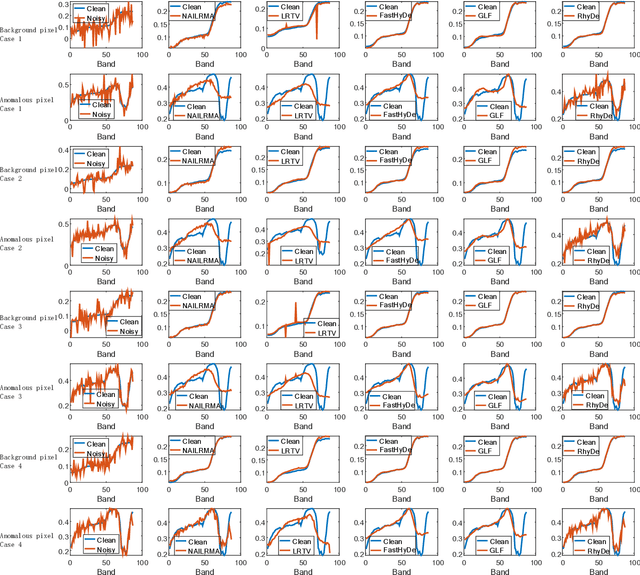
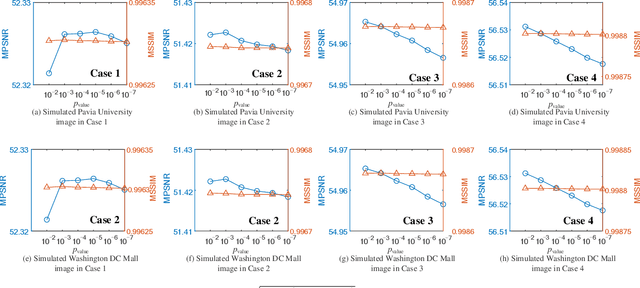
Hyperspectral imaging measures the amount of electromagnetic energy across the instantaneous field of view at a very high resolution in hundreds or thousands of spectral channels. This enables objects to be detected and the identification of materials that have subtle differences between them. However, the increase in spectral resolution often means that there is a decrease in the number of photons received in each channel, which means that the noise linked to the image formation process is greater. This degradation limits the quality of the extracted information and its potential applications. Thus, denoising is a fundamental problem in hyperspectral image (HSI) processing. As images of natural scenes with highly correlated spectral channels, HSIs are characterized by a high level of self-similarity and can be well approximated by low-rank representations. These characteristics underlie the state-of-the-art methods used in HSI denoising. However, where there are rarely occurring pixel types, the denoising performance of these methods is not optimal, and the subsequent detection of these pixels may be compromised. To address these hurdles, in this article, we introduce RhyDe (Robust hyperspectral Denoising), a powerful HSI denoiser, which implements explicit low-rank representation, promotes self-similarity, and, by using a form of collaborative sparsity, preserves rare pixels. The denoising and detection effectiveness of the proposed robust HSI denoiser is illustrated using semireal and real data.
SLCRF: Subspace Learning with Conditional Random Field for Hyperspectral Image Classification
Oct 07, 2020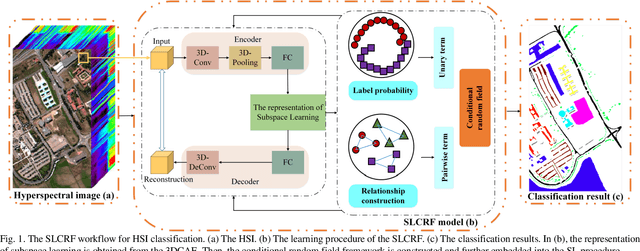

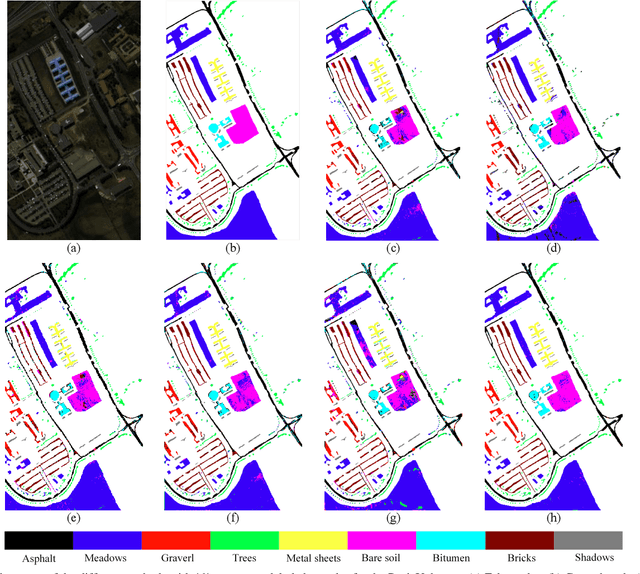
Subspace learning (SL) plays an important role in hyperspectral image (HSI) classification, since it can provide an effective solution to reduce the redundant information in the image pixels of HSIs. Previous works about SL aim to improve the accuracy of HSI recognition. Using a large number of labeled samples, related methods can train the parameters of the proposed solutions to obtain better representations of HSI pixels. However, the data instances may not be sufficient enough to learn a precise model for HSI classification in real applications. Moreover, it is well-known that it takes much time, labor and human expertise to label HSI images. To avoid the aforementioned problems, a novel SL method that includes the probability assumption called subspace learning with conditional random field (SLCRF) is developed. In SLCRF, first, the 3D convolutional autoencoder (3DCAE) is introduced to remove the redundant information in HSI pixels. In addition, the relationships are also constructed using the spectral-spatial information among the adjacent pixels. Then, the conditional random field (CRF) framework can be constructed and further embedded into the HSI SL procedure with the semi-supervised approach. Through the linearized alternating direction method termed LADMAP, the objective function of SLCRF is optimized using a defined iterative algorithm. The proposed method is comprehensively evaluated using the challenging public HSI datasets. We can achieve stateof-the-art performance using these HSI sets.
More Diverse Means Better: Multimodal Deep Learning Meets Remote Sensing Imagery Classification
Aug 12, 2020
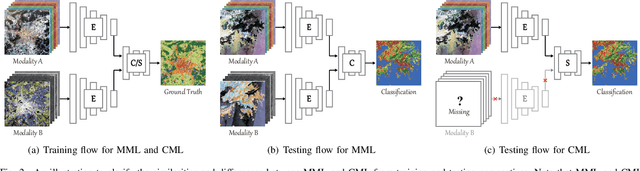
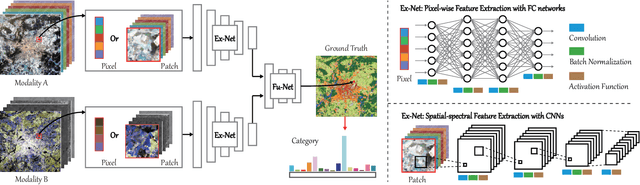
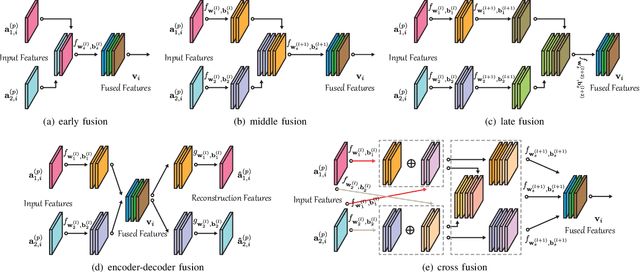
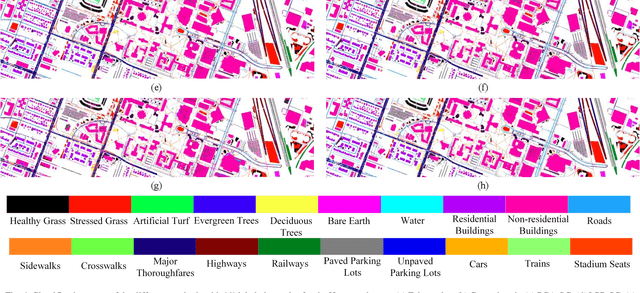
Classification and identification of the materials lying over or beneath the Earth's surface have long been a fundamental but challenging research topic in geoscience and remote sensing (RS) and have garnered a growing concern owing to the recent advancements of deep learning techniques. Although deep networks have been successfully applied in single-modality-dominated classification tasks, yet their performance inevitably meets the bottleneck in complex scenes that need to be finely classified, due to the limitation of information diversity. In this work, we provide a baseline solution to the aforementioned difficulty by developing a general multimodal deep learning (MDL) framework. In particular, we also investigate a special case of multi-modality learning (MML) -- cross-modality learning (CML) that exists widely in RS image classification applications. By focusing on "what", "where", and "how" to fuse, we show different fusion strategies as well as how to train deep networks and build the network architecture. Specifically, five fusion architectures are introduced and developed, further being unified in our MDL framework. More significantly, our framework is not only limited to pixel-wise classification tasks but also applicable to spatial information modeling with convolutional neural networks (CNNs). To validate the effectiveness and superiority of the MDL framework, extensive experiments related to the settings of MML and CML are conducted on two different multimodal RS datasets. Furthermore, the codes and datasets will be available at https://github.com/danfenghong/IEEE_TGRS_MDL-RS, contributing to the RS community.