 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Pose Estimation for Stereo Rolling Shutter Cameras
Jun 14, 2020
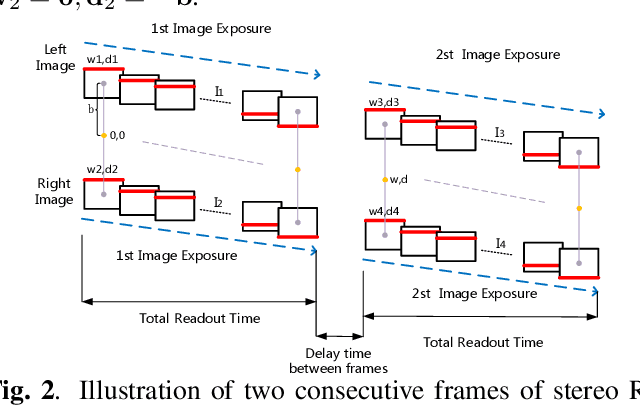
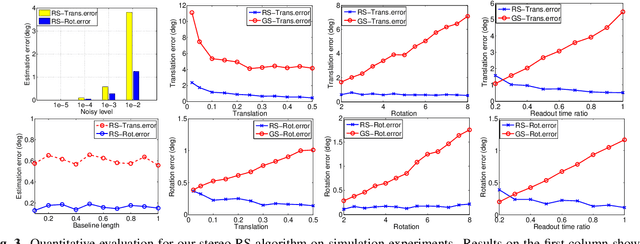

In this paper, we present a novel linear algorithm to estimate the 6 DoF relative pose from consecutive frames of stereo rolling shutter (RS) cameras. Our method is derived based on the assumption that stereo cameras undergo motion with constant velocity around the center of the baseline, which needs 9 pairs of correspondences on both left and right consecutive frames. The stereo RS images enable the recovery of depth maps from the semi-global matching (SGM) algorithm. With the estimated camera motion and depth map, we can correct the RS images to get the undistorted images without any scene structure assumption. Experiments on both simulated points and synthetic RS images demonstrate the effectiveness of our algorithm in relative pose estimation.
Deep Attention Aware Feature Learning for Person Re-Identification
Mar 01, 2020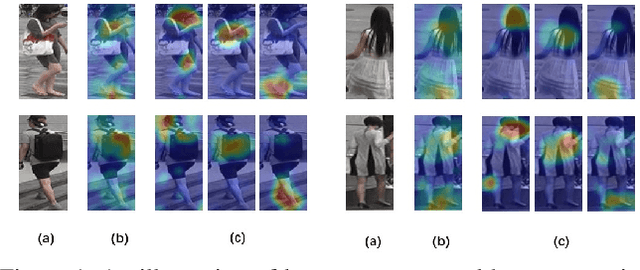

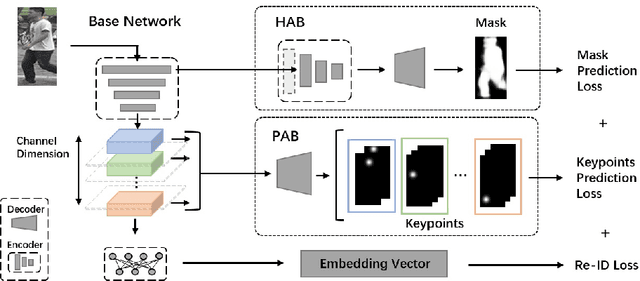
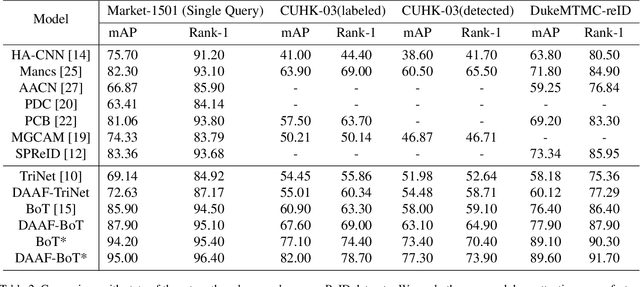
Visual attention has proven to be effective in improving the performance of person re-identification. Most existing methods apply visual attention heuristically by learning an additional attention map to re-weight the feature maps for person re-identification. However, this kind of methods inevitably increase the model complexity and inference time. In this paper, we propose to incorporate the attention learning as additional objectives in a person ReID network without changing the original structure, thus maintain the same inference time and model size. Two kinds of attentions have been considered to make the learned feature maps being aware of the person and related body parts respectively. Globally, a holistic attention branch (HAB) makes the feature maps obtained by backbone focus on persons so as to alleviate the influence of background. Locally, a partial attention branch (PAB) makes the extracted features be decoupled into several groups and be separately responsible for different body parts (i.e., keypoints), thus increasing the robustness to pose variation and partial occlusion. These two kinds of attentions are universal and can be incorporated into existing ReID networks. We have tested its performance on two typical networks (TriNet and Bag of Tricks) and observed significant performance improvement on five widely used datasets.
AugFPN: Improving Multi-scale Feature Learning for Object Detection
Dec 11, 2019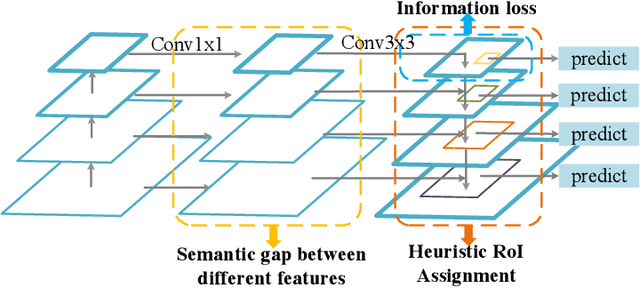
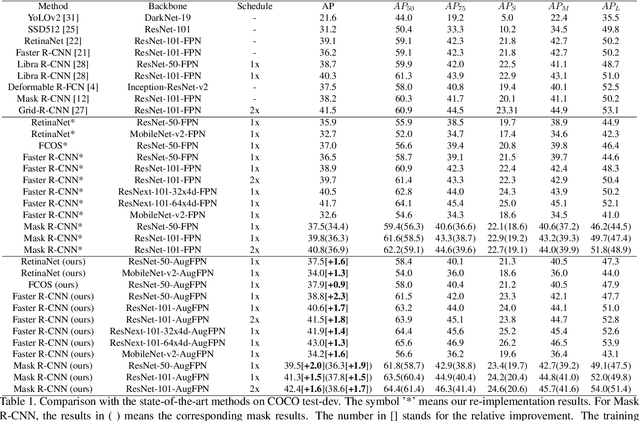
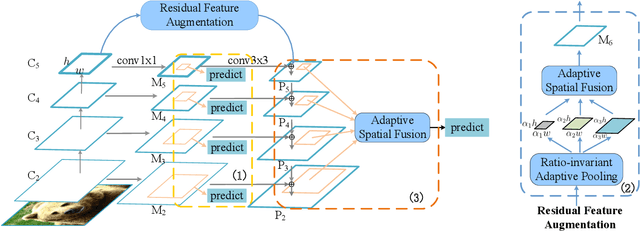
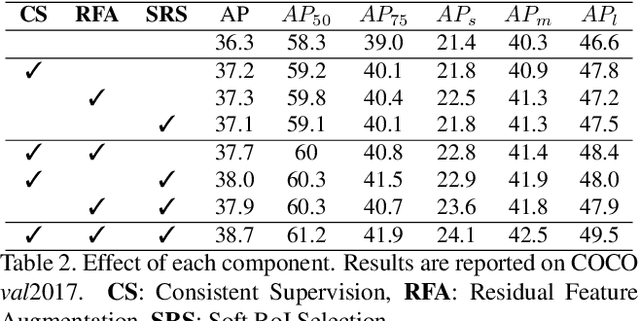
Current state-of-the-art detectors typically exploit feature pyramid to detect objects at different scales. Among them, FPN is one of the representative works that build a feature pyramid by multi-scale features summation. However, the design defects behind prevent the multi-scale features from being fully exploited. In this paper, we begin by first analyzing the design defects of feature pyramid in FPN, and then introduce a new feature pyramid architecture named AugFPN to address these problems. Specifically, AugFPN consists of three components: Consistent Supervision, Residual Feature Augmentation, and Soft RoI Selection. AugFPN narrows the semantic gaps between features of different scales before feature fusion through Consistent Supervision. In feature fusion, ratio-invariant context information is extracted by Residual Feature Augmentation to reduce the information loss of feature map at the highest pyramid level. Finally, Soft RoI Selection is employed to learn a better RoI feature adaptively after feature fusion. By replacing FPN with AugFPN in Faster R-CNN, our models achieve 2.3 and 1.6 points higher Average Precision (AP) when using ResNet50 and MobileNet-v2 as backbone respectively. Furthermore, AugFPN improves RetinaNet by 1.6 points AP and FCOS by 0.9 points AP when using ResNet50 as backbone. Codes will be made available.
DensePoint: Learning Densely Contextual Representation for Efficient Point Cloud Processing
Sep 09, 2019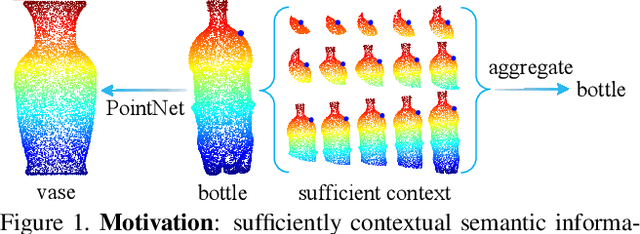
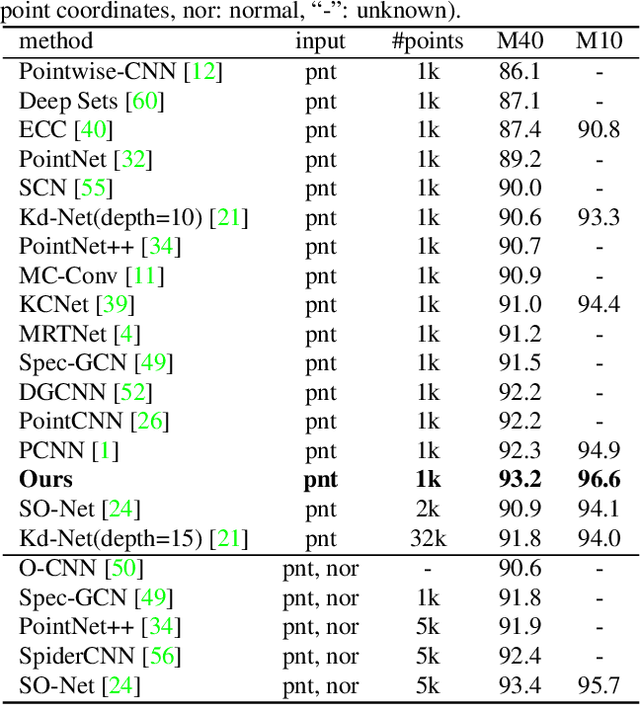
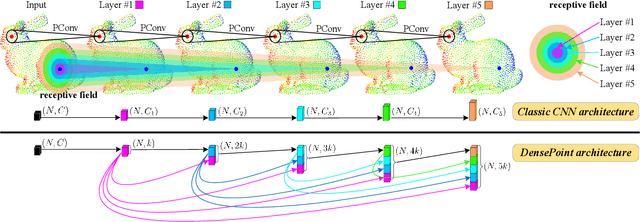
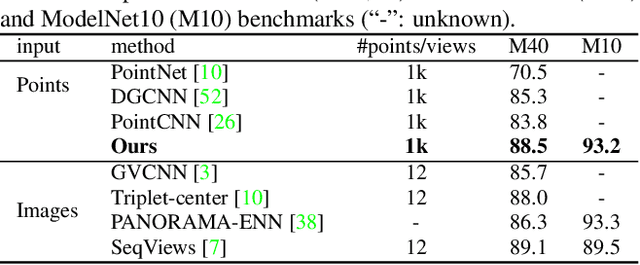
Point cloud processing is very challenging, as the diverse shapes formed by irregular points are often indistinguishable. A thorough grasp of the elusive shape requires sufficiently contextual semantic information, yet few works devote to this. Here we propose DensePoint, a general architecture to learn densely contextual representation for point cloud processing. Technically, it extends regular grid CNN to irregular point configuration by generalizing a convolution operator, which holds the permutation invariance of points, and achieves efficient inductive learning of local patterns. Architecturally, it finds inspiration from dense connection mode, to repeatedly aggregate multi-level and multi-scale semantics in a deep hierarchy. As a result, densely contextual information along with rich semantics, can be acquired by DensePoint in an organic manner, making it highly effective. Extensive experiments on challenging benchmarks across four tasks, as well as thorough model analysis, verify DensePoint achieves the state of the arts.
Relation-Shape Convolutional Neural Network for Point Cloud Analysis
May 26, 2019
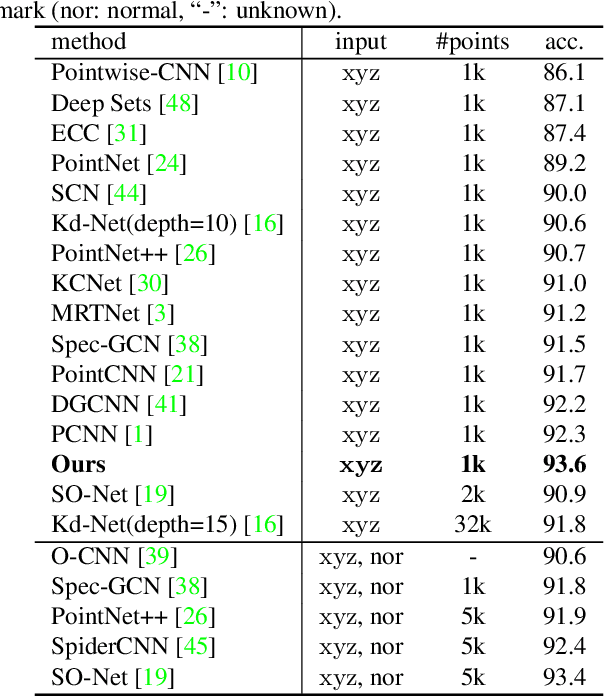

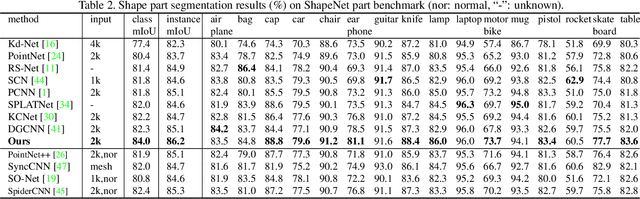
Point cloud analysis is very challenging, as the shape implied in irregular points is difficult to capture. In this paper, we propose RS-CNN, namely, Relation-Shape Convolutional Neural Network, which extends regular grid CNN to irregular configuration for point cloud analysis. The key to RS-CNN is learning from relation, i.e., the geometric topology constraint among points. Specifically, the convolutional weight for local point set is forced to learn a high-level relation expression from predefined geometric priors, between a sampled point from this point set and the others. In this way, an inductive local representation with explicit reasoning about the spatial layout of points can be obtained, which leads to much shape awareness and robustness. With this convolution as a basic operator, RS-CNN, a hierarchical architecture can be developed to achieve contextual shape-aware learning for point cloud analysis. Extensive experiments on challenging benchmarks across three tasks verify RS-CNN achieves the state of the arts.
SOSNet: Second Order Similarity Regularization for Local Descriptor Learning
Apr 10, 2019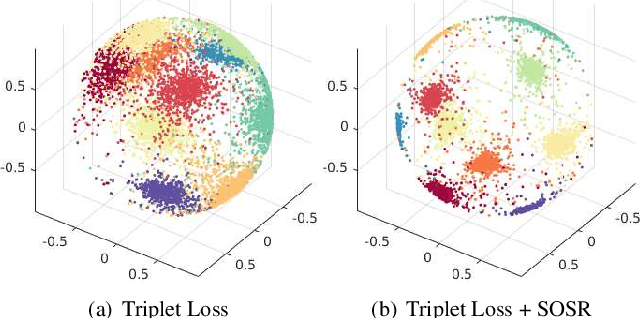
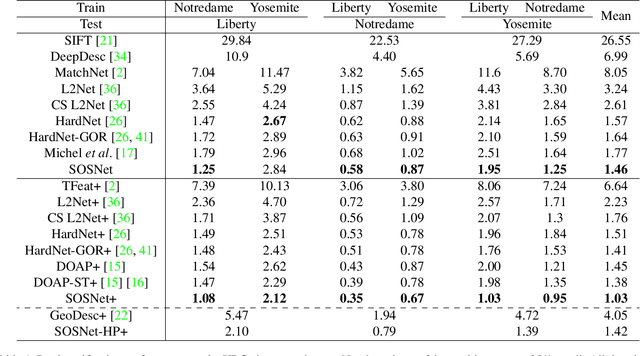
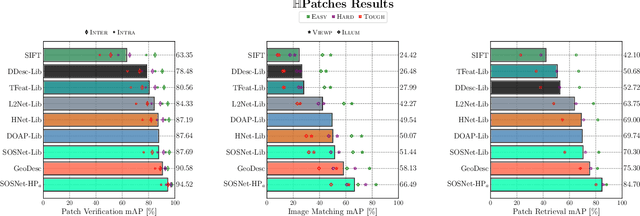
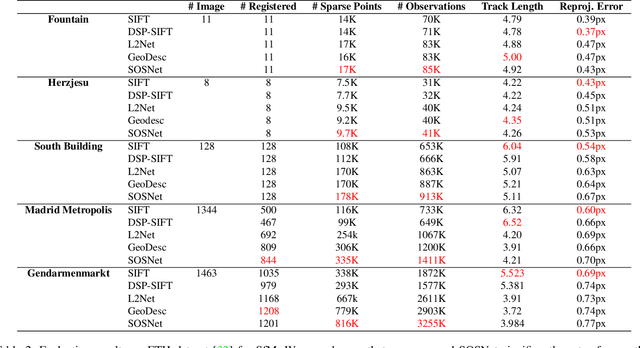
Despite the fact that Second Order Similarity (SOS) has been used with significant success in tasks such as graph matching and clustering, it has not been exploited for learning local descriptors. In this work, we explore the potential of SOS in the field of descriptor learning by building upon the intuition that a positive pair of matching points should exhibit similar distances with respect to other points in the embedding space. Thus, we propose a novel regularization term, named Second Order Similarity Regularization (SOSR), that follows this principle. By incorporating SOSR into training, our learned descriptor achieves state-of-the-art performance on several challenging benchmarks containing distinct tasks ranging from local patch retrieval to structure from motion. Furthermore, by designing a von Mises-Fischer distribution based evaluation method, we link the utilization of the descriptor space to the matching performance, thus demonstrating the effectiveness of our proposed SOSR. Extensive experimental results, empirical evidence, and in-depth analysis are provided, indicating that SOSR can significantly boost the matching performance of the learned descriptor.
Progressive Sparse Local Attention for Video object detection
Mar 25, 2019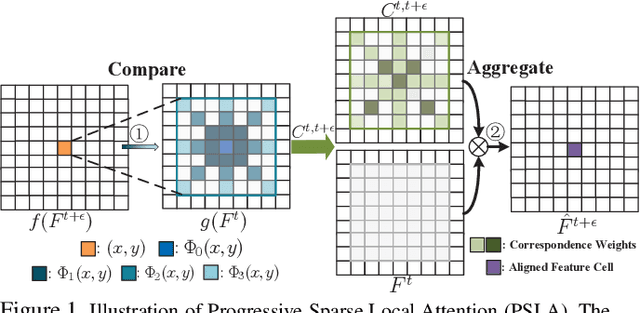
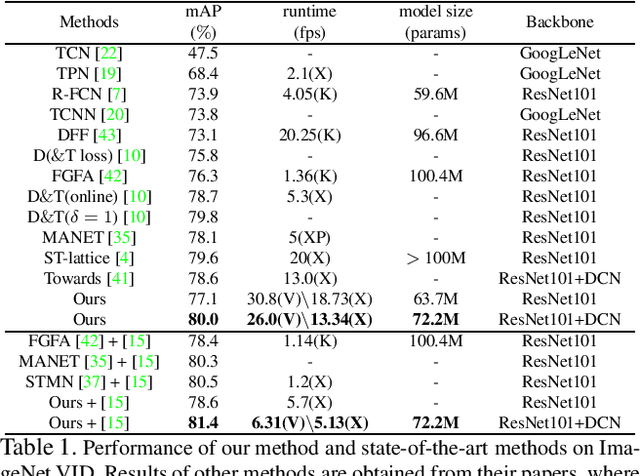
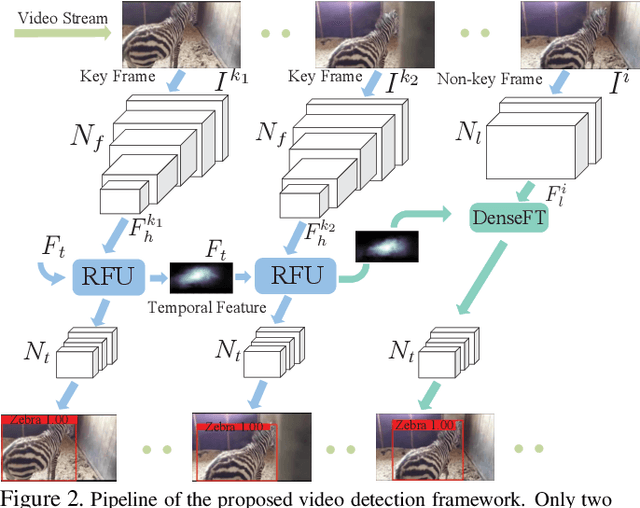
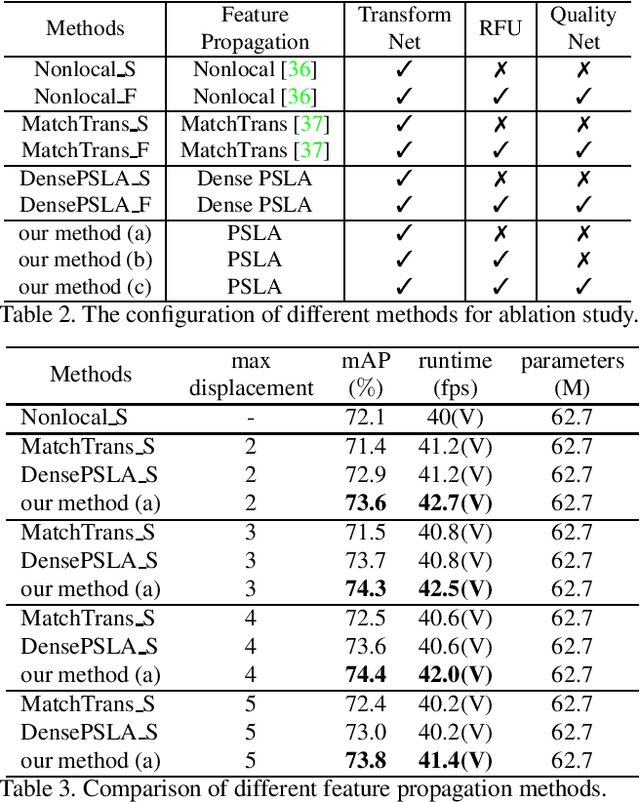
Transferring image-based object detectors to the domain of videos remains a challenging problem. Previous efforts mostly exploit optical flow to propagate features across frames, aiming to achieve a good trade-off between accuracy and efficiency. However, introducing an extra model to estimate optical flow would significantly increase the overall model size. The gap between optical flow and high-level features can also hinder it from establishing spatial correspondence accurately. Instead of relying on optical flow, this paper proposes a novel module called Progressive Sparse Local Attention (PSLA), which establishes the spatial correspondence between features across frames in a local region with progressive sparser stride and uses the correspondence to propagate features. Based on PSLA, Recursive Feature Updating (RFU) and Dense Feature Transforming (DFT) are proposed to model temporal appearance and enrich feature representation respectively in a novel video object detection framework. Experiments on ImageNet VID show that our method achieves the best accuracy compared to existing methods with smaller model size and acceptable runtime speed.
Semantic Labeling in Very High Resolution Images via a Self-Cascaded Convolutional Neural Network
Jul 30, 2018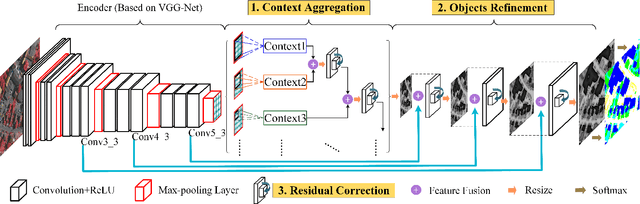


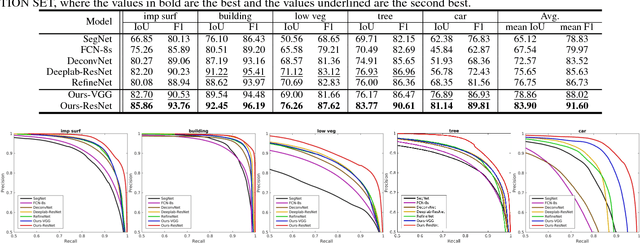
Semantic labeling for very high resolution (VHR) images in urban areas, is of significant importance in a wide range of remote sensing applications. However, many confusing manmade objects and intricate fine-structured objects make it very difficult to obtain both coherent and accurate labeling results. For this challenging task, we propose a novel deep model with convolutional neural networks (CNNs), i.e., an end-to-end self-cascaded network (ScasNet). Specifically, for confusing manmade objects, ScasNet improves the labeling coherence with sequential global-to-local contexts aggregation. Technically, multi-scale contexts are captured on the output of a CNN encoder, and then they are successively aggregated in a self-cascaded manner. Meanwhile, for fine-structured objects, ScasNet boosts the labeling accuracy with a coarse-to-fine refinement strategy. It progressively refines the target objects using the low-level features learned by CNN's shallow layers. In addition, to correct the latent fitting residual caused by multi-feature fusion inside ScasNet, a dedicated residual correction scheme is proposed. It greatly improves the effectiveness of ScasNet. Extensive experimental results on three public datasets, including two challenging benchmarks, show that ScasNet achieves the state-of-the-art performance.
A Performance Evaluation of Local Features for Image Based 3D Reconstruction
Dec 14, 2017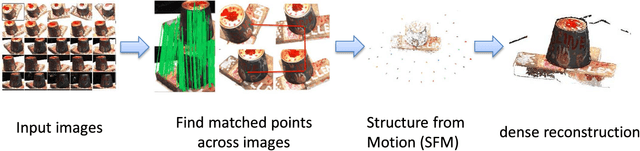

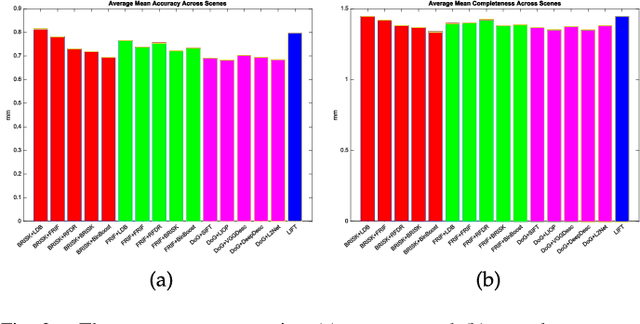
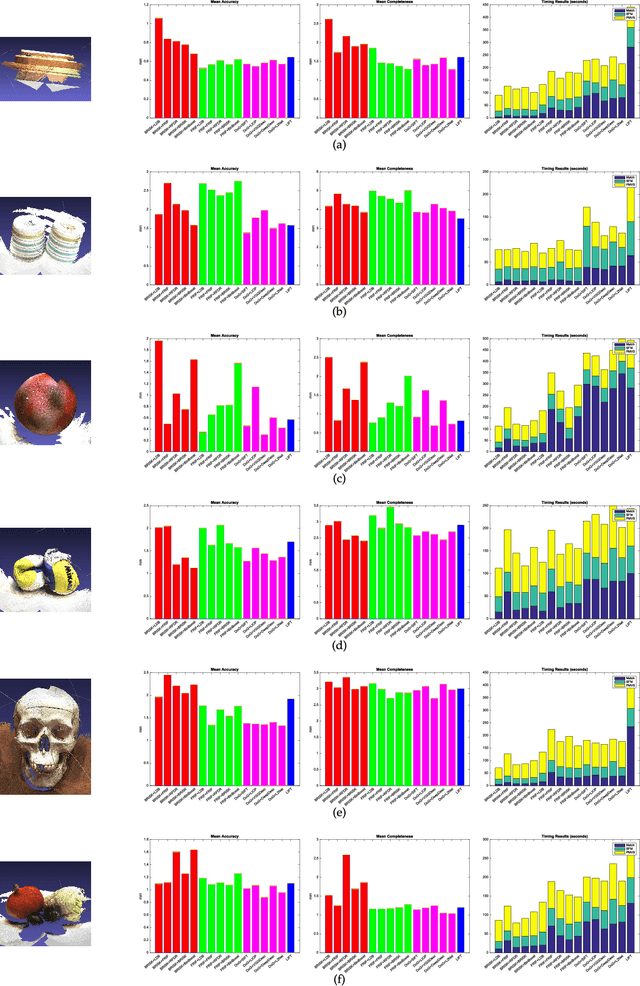
This paper performs a comprehensive and comparative evaluation of the state of the art local features for the task of image based 3D reconstruction. The evaluated local features cover the recently developed ones by using powerful machine learning techniques and the elaborately designed handcrafted features. To obtain a comprehensive evaluation, we choose to include both float type features and binary ones. Meanwhile, two kinds of datasets have been used in this evaluation. One is a dataset of many different scene types with groundtruth 3D points, containing images of different scenes captured at fixed positions, for quantitative performance evaluation of different local features in the controlled image capturing situations. The other dataset contains Internet scale image sets of several landmarks with a lot of unrelated images, which is used for qualitative performance evaluation of different local features in the free image collection situations. Our experimental results show that binary features are competent to reconstruct scenes from controlled image sequences with only a fraction of processing time compared to use float type features. However, for the case of large scale image set with many distracting images, float type features show a clear advantage over binary ones.
Effective Spectral Unmixing via Robust Representation and Learning-based Sparsity
Aug 26, 2017
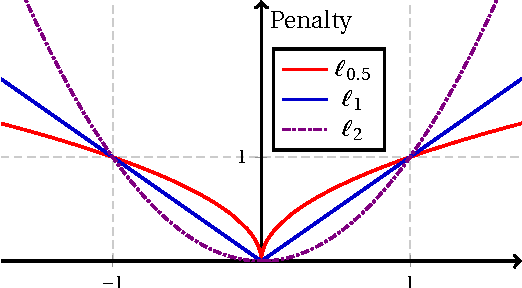

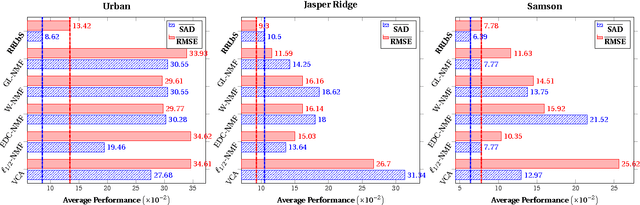
Hyperspectral unmixing (HU) plays a fundamental role in a wide range of hyperspectral applications. It is still challenging due to the common presence of outlier channels and the large solution space. To address the above two issues, we propose a novel model by emphasizing both robust representation and learning-based sparsity. Specifically, we apply the $\ell_{2,1}$-norm to measure the representation error, preventing outlier channels from dominating our objective. In this way, the side effects of outlier channels are greatly relieved. Besides, we observe that the mixed level of each pixel varies over image grids. Based on this observation, we exploit a learning-based sparsity method to simultaneously learn the HU results and a sparse guidance map. Via this guidance map, the sparsity constraint in the $\ell_{p}\!\left(\!0\!<\! p\!\leq\!1\right)$-norm is adaptively imposed according to the learnt mixed level of each pixel. Compared with state-of-the-art methods, our model is better suited to the real situation, thus expected to achieve better HU results. The resulted objective is highly non-convex and non-smooth, and so it is hard to optimize. As a profound theoretical contribution, we propose an efficient algorithm to solve it. Meanwhile, the convergence proof and the computational complexity analysis are systematically provided. Extensive evaluations verify that our method is highly promising for the HU task---it achieves very accurate guidance maps and much better HU results compared with state-of-the-art methods.