 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynetgy: Algorithm-hardware Co-design for ConvNet Accelerators on Embedded FPGAs
Nov 21, 2018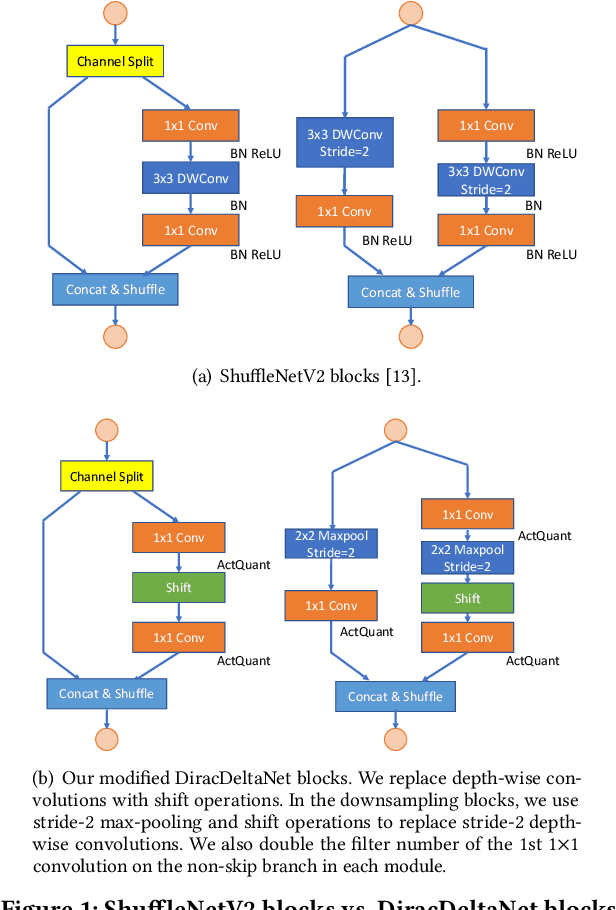
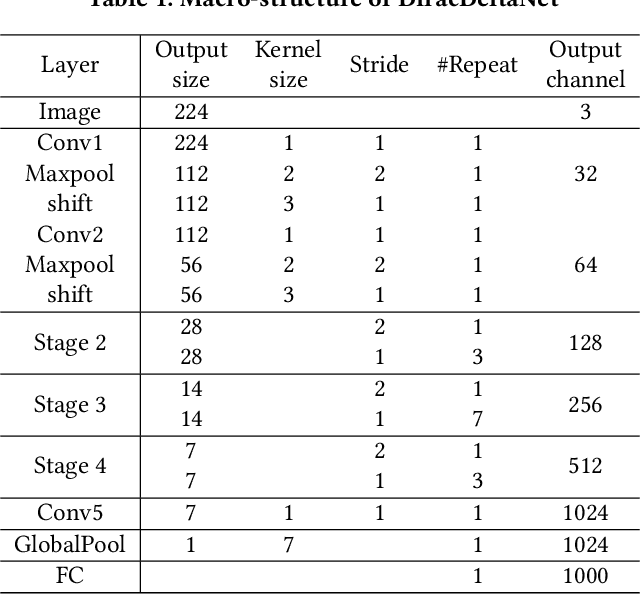
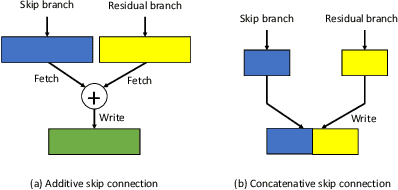
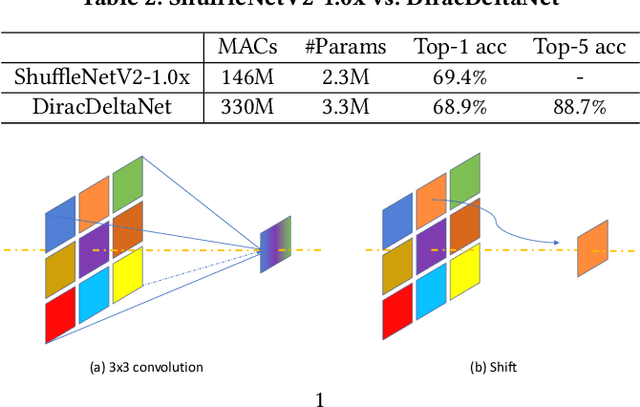
Using FPGAs to accelerate ConvNets has attracted significant attention in recent years. However, FPGA accelerator design has not leveraged the latest progress of ConvNets. As a result, the key application characteristics such as frames-per-second (FPS) are ignored in favor of simply counting GOPs, and results on accuracy, which is critical to application success, are often not even reported. In this work, we adopt an algorithm-hardware co-design approach to develop a ConvNet accelerator called Synetgy and a novel ConvNet model called DiracNet. Both the accelerator and ConvNet are tailored to FPGA requirements. DiractNet, as the name suggests, is a ConvNet with only 1x1 convolutions while spatial convolutions are replaced by more efficient shift operations. DiracNet achieves competitive accuracy on ImageNet (89.0% top-5), but with 48x fewer parameters and 65x fewer OPs than VGG16. We further quantize DiracNet's weights to 1-bit and activations to 4-bits, with less than 1% accuracy loss. These quantizations exploit well the nature of FPGA hardware. In short, DiracNet's small model size, low computational OP count, ultra-low precision and simplified operators allow us to co-design a highly customized computing unit for an FPGA. We implement the computing units for DiracNet on an Ultra96 SoC system through high-level synthesis. The implementation only took 2 people 1 month to complete. Our accelerator's final top-5 accuracy of 88.3% on ImageNet, is higher than all the previously reported embedded FPGA accelerators. In addition, the accelerator reaches an inference speed of 72.8 FPS on the ImageNet classification task, surpassing prior works with similar accuracy by at least 12.8x.
SqueezeSegV2: Improved Model Structure and Unsupervised Domain Adaptation for Road-Object Segmentation from a LiDAR Point Cloud
Sep 22, 2018
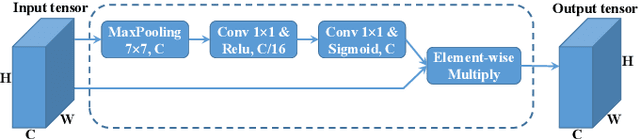

Earlier work demonstrates the promise of deep-learning-based approaches for point cloud segmentation; however, these approaches need to be improved to be practically useful. To this end, we introduce a new model SqueezeSegV2 that is more robust to dropout noise in LiDAR point clouds. With improved model structure, training loss, batch normalization and additional input channel, SqueezeSegV2 achieves significant accuracy improvement when trained on real data. Training models for point cloud segmentation requires large amounts of labeled point-cloud data, which is expensive to obtain. To sidestep the cost of collection and annotation, simulators such as GTA-V can be used to create unlimited amounts of labeled, synthetic data. However, due to domain shift, models trained on synthetic data often do not generalize well to the real world. We address this problem with a domain-adaptation training pipeline consisting of three major components: 1) learned intensity rendering, 2) geodesic correlation alignment, and 3) progressive domain calibration. When trained on real data, our new model exhibits segmentation accuracy improvements of 6.0-8.6% over the original SqueezeSeg. When training our new model on synthetic data using the proposed domain adaptation pipeline, we nearly double test accuracy on real-world data, from 29.0% to 57.4%. Our source code and synthetic dataset will be open-sourced.
SqueezeNext: Hardware-Aware Neural Network Design
Aug 27, 2018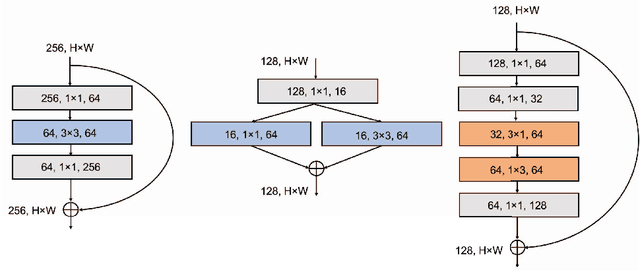
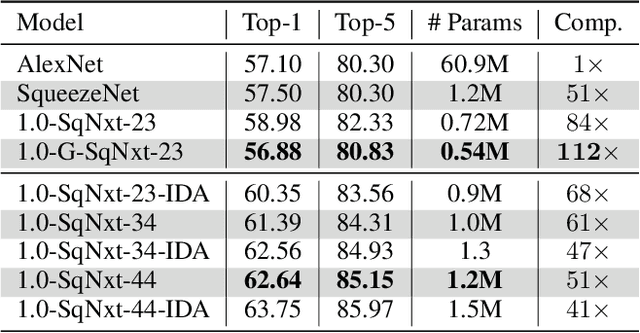
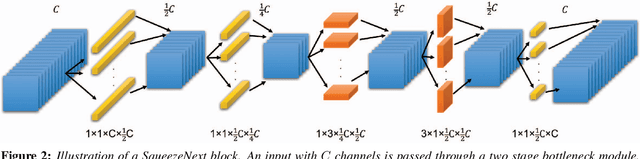
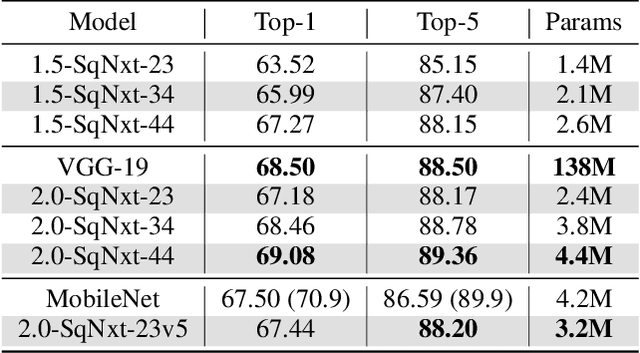
One of the main barriers for deploying neural networks on embedded systems has been large memory and power consumption of existing neural networks. In this work, we introduce SqueezeNext, a new family of neural network architectures whose design was guided by considering previous architectures such as SqueezeNet, as well as by simulation results on a neural network accelerator. This new network is able to match AlexNet's accuracy on the ImageNet benchmark with $112\times$ fewer parameters, and one of its deeper variants is able to achieve VGG-19 accuracy with only 4.4 Million parameters, ($31\times$ smaller than VGG-19). SqueezeNext also achieves better top-5 classification accuracy with $1.3\times$ fewer parameters as compared to MobileNet, but avoids using depthwise-separable convolutions that are inefficient on some mobile processor platforms. This wide range of accuracy gives the user the ability to make speed-accuracy tradeoffs, depending on the available resources on the target hardware. Using hardware simulation results for power and inference speed on an embedded system has guided us to design variations of the baseline model that are $2.59\times$/$8.26\times$ faster and $2.25\times$/$7.5\times$ more energy efficient as compared to SqueezeNet/AlexNet without any accuracy degradation.
A LiDAR Point Cloud Generator: from a Virtual World to Autonomous Driving
Mar 31, 2018
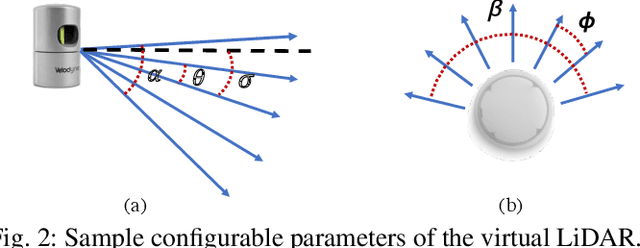
3D LiDAR scanners are playing an increasingly important role in autonomous driving as they can generate depth information of the environment. However, creating large 3D LiDAR point cloud datasets with point-level labels requires a significant amount of manual annotation. This jeopardizes the efficient development of supervised deep learning algorithms which are often data-hungry. We present a framework to rapidly create point clouds with accurate point-level labels from a computer game. The framework supports data collection from both auto-driving scenes and user-configured scenes. Point clouds from auto-driving scenes can be used as training data for deep learning algorithms, while point clouds from user-configured scenes can be used to systematically test the vulnerability of a neural network, and use the falsifying examples to make the neural network more robust through retraining. In addition, the scene images can be captured simultaneously in order for sensor fusion tasks, with a method proposed to do automatic calibration between the point clouds and captured scene images. We show a significant improvement in accuracy (+9%) in point cloud segmentation by augmenting the training dataset with the generated synthesized data. Our experiments also show by testing and retraining the network using point clouds from user-configured scenes, the weakness/blind spots of the neural network can be fixed.
Unsupervised Domain Adaptation: from Simulation Engine to the RealWorld
Mar 24, 2018


Large-scale labeled training datasets have enabled deep neural networks to excel on a wide range of benchmark vision tasks. However, in many applications it is prohibitively expensive or time-consuming to obtain large quantities of labeled data. To cope with limited labeled training data, many have attempted to directly apply models trained on a large-scale labeled source domain to another sparsely labeled target domain. Unfortunately, direct transfer across domains often performs poorly due to domain shift and dataset bias. Domain adaptation is the machine learning paradigm that aims to learn a model from a source domain that can perform well on a different (but related) target domain. In this paper, we summarize and compare the latest unsupervised domain adaptation methods in computer vision applications. We classify the non-deep approaches into sample re-weighting and intermediate subspace transformation categories, while the deep strategy includes discrepancy-based methods, adversarial generative models, adversarial discriminative models and reconstruction-based methods. We also discuss some potential directions.
Shift: A Zero FLOP, Zero Parameter Alternative to Spatial Convolutions
Dec 03, 2017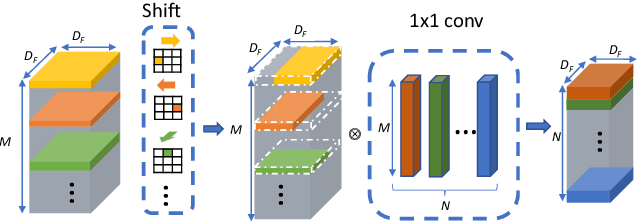
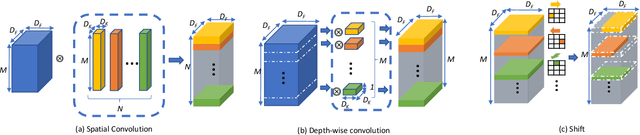
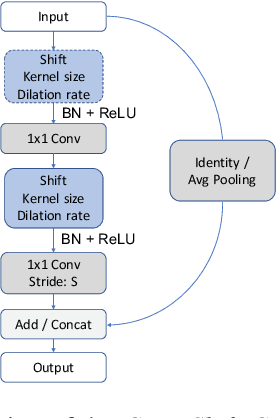
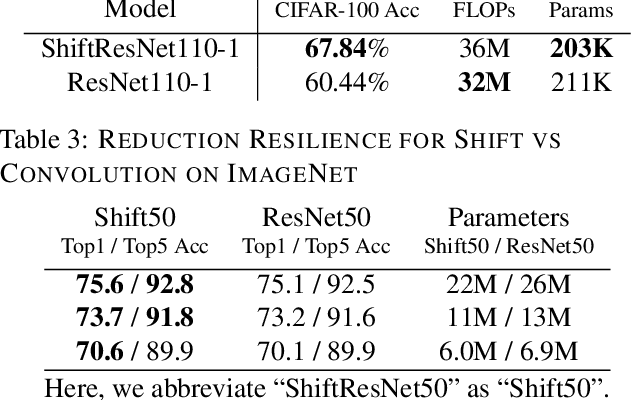
Neural networks rely on convolutions to aggregate spatial information. However, spatial convolutions are expensive in terms of model size and computation, both of which grow quadratically with respect to kernel size. In this paper, we present a parameter-free, FLOP-free "shift" operation as an alternative to spatial convolutions. We fuse shifts and point-wise convolutions to construct end-to-end trainable shift-based modules, with a hyperparameter characterizing the tradeoff between accuracy and efficiency. To demonstrate the operation's efficacy, we replace ResNet's 3x3 convolutions with shift-based modules for improved CIFAR10 and CIFAR100 accuracy using 60% fewer parameters; we additionally demonstrate the operation's resilience to parameter reduction on ImageNet, outperforming ResNet family members. We finally show the shift operation's applicability across domains, achieving strong performance with fewer parameters on classification, face verification and style transfer.
SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving
Nov 29, 2017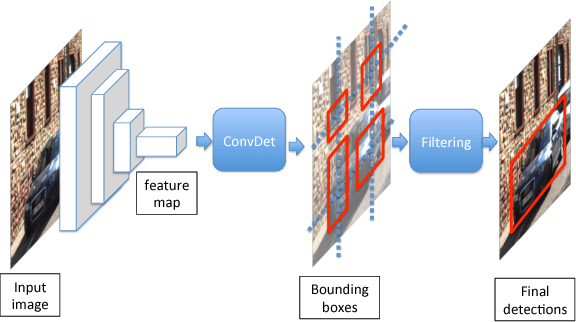
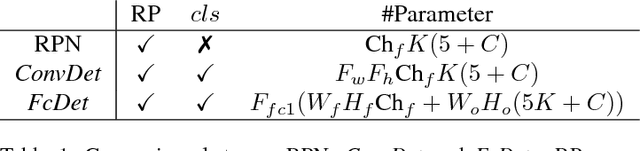
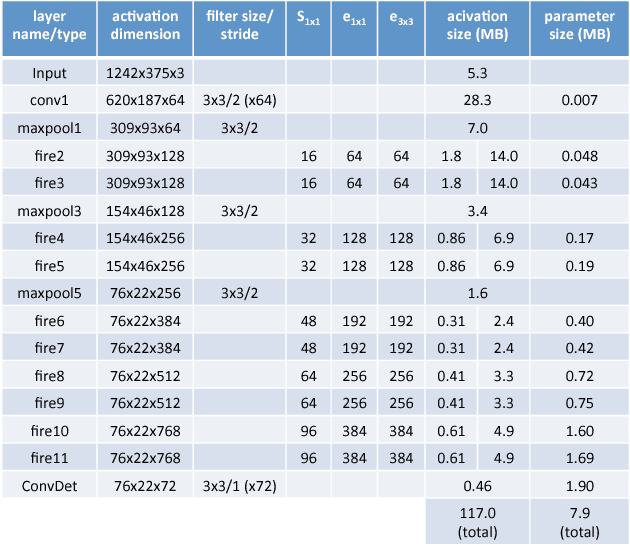
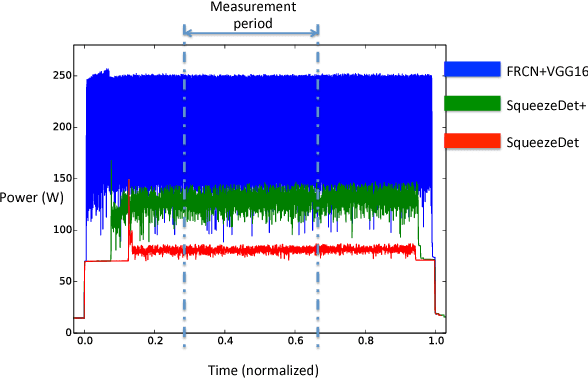
Object detection is a crucial task for autonomous driving. In addition to requiring high accuracy to ensure safety, object detection for autonomous driving also requires real-time inference speed to guarantee prompt vehicle control, as well as small model size and energy efficiency to enable embedded system deployment. In this work, we propose SqueezeDet, a fully convolutional neural network for object detection that aims to simultaneously satisfy all of the above constraints. In our network we use convolutional layers not only to extract feature maps, but also as the output layer to compute bounding boxes and class probabilities. The detection pipeline of our model only contains a single forward pass of a neural network, thus it is extremely fast. Our model is fully-convolutional, which leads to small model size and better energy efficiency. Finally, our experiments show that our model is very accurate, achieving state-of-the-art accuracy on the KITTI benchmark.
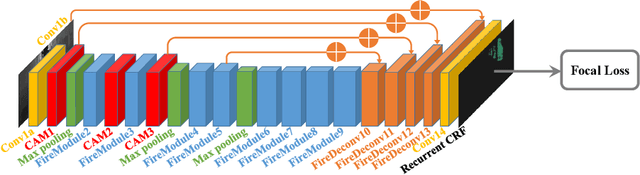
SqueezeSeg: Convolutional Neural Nets with Recurrent CRF for Real-Time Road-Object Segmentation from 3D LiDAR Point Cloud
Oct 19, 2017

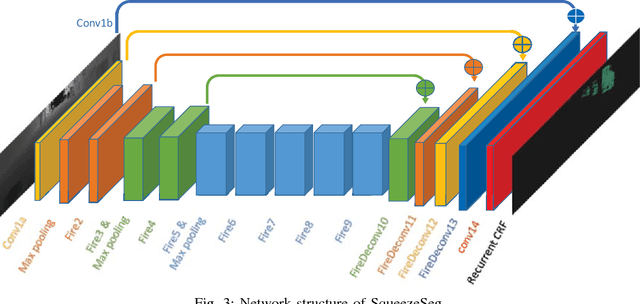
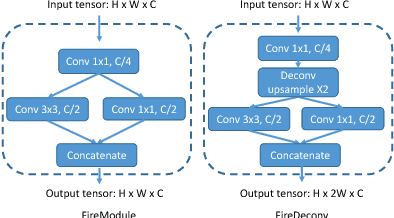
In this paper, we address semantic segmentation of road-objects from 3D LiDAR point clouds. In particular, we wish to detect and categorize instances of interest, such as cars, pedestrians and cyclists. We formulate this problem as a point- wise classification problem, and propose an end-to-end pipeline called SqueezeSeg based on convolutional neural networks (CNN): the CNN takes a transformed LiDAR point cloud as input and directly outputs a point-wise label map, which is then refined by a conditional random field (CRF) implemented as a recurrent layer. Instance-level labels are then obtained by conventional clustering algorithms. Our CNN model is trained on LiDAR point clouds from the KITTI dataset, and our point-wise segmentation labels are derived from 3D bounding boxes from KITTI. To obtain extra training data, we built a LiDAR simulator into Grand Theft Auto V (GTA-V), a popular video game, to synthesize large amounts of realistic training data. Our experiments show that SqueezeSeg achieves high accuracy with astonishingly fast and stable runtime (8.7 ms per frame), highly desirable for autonomous driving applications. Furthermore, additionally training on synthesized data boosts validation accuracy on real-world data. Our source code and synthesized data will be open-sourced.
Shallow Networks for High-Accuracy Road Object-Detection
Jun 05, 2016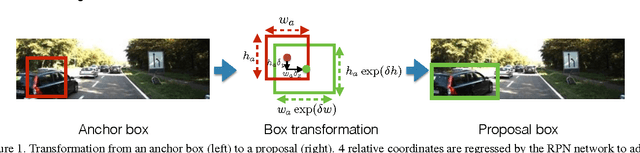

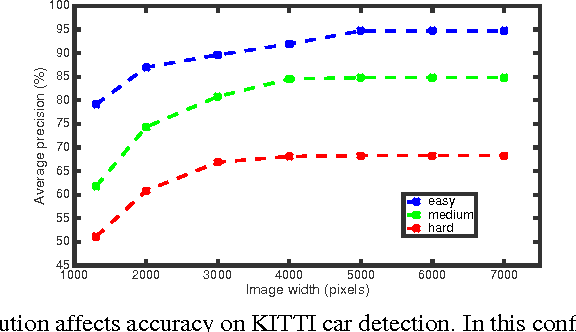

The ability to automatically detect other vehicles on the road is vital to the safety of partially-autonomous and fully-autonomous vehicles. Most of the high-accuracy techniques for this task are based on R-CNN or one of its faster variants. In the research community, much emphasis has been applied to using 3D vision or complex R-CNN variants to achieve higher accuracy. However, are there more straightforward modifications that could deliver higher accuracy? Yes. We show that increasing input image resolution (i.e. upsampling) offers up to 12 percentage-points higher accuracy compared to an off-the-shelf baseline. We also find situations where earlier/shallower layers of CNN provide higher accuracy than later/deeper layers. We further show that shallow models and upsampled images yield competitive accuracy. Our findings contrast with the current trend towards deeper and larger models to achieve high accuracy in domain specific detection tasks.