 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving
Nov 29, 2017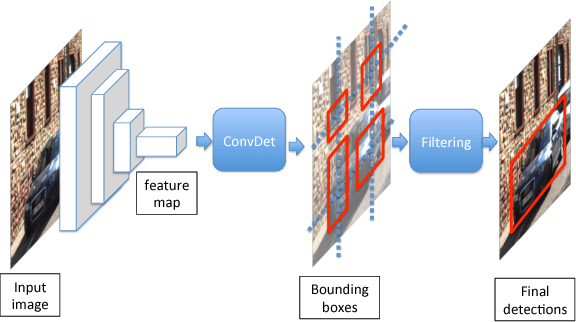
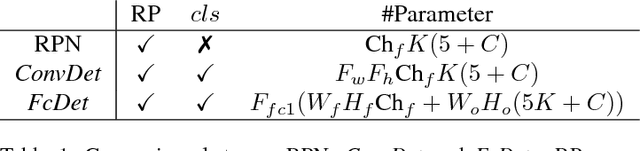
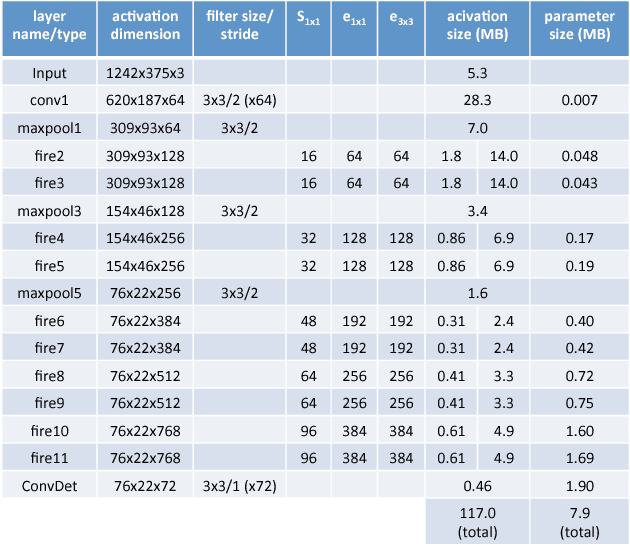
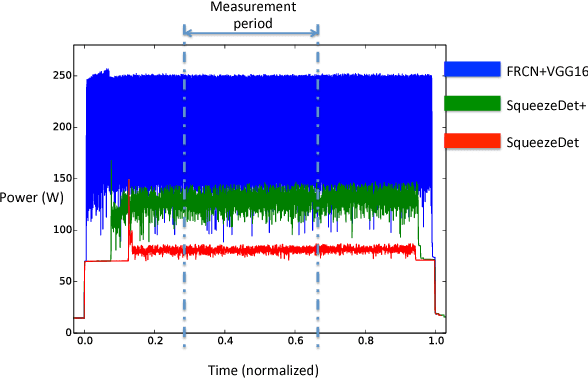
Object detection is a crucial task for autonomous driving. In addition to requiring high accuracy to ensure safety, object detection for autonomous driving also requires real-time inference speed to guarantee prompt vehicle control, as well as small model size and energy efficiency to enable embedded system deployment. In this work, we propose SqueezeDet, a fully convolutional neural network for object detection that aims to simultaneously satisfy all of the above constraints. In our network we use convolutional layers not only to extract feature maps, but also as the output layer to compute bounding boxes and class probabilities. The detection pipeline of our model only contains a single forward pass of a neural network, thus it is extremely fast. Our model is fully-convolutional, which leads to small model size and better energy efficiency. Finally, our experiments show that our model is very accurate, achieving state-of-the-art accuracy on the KITTI benchmark.
How to scale distributed deep learning?
Nov 14, 2016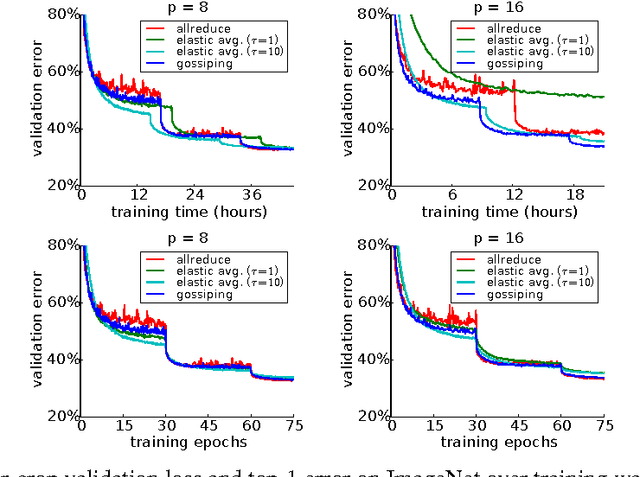
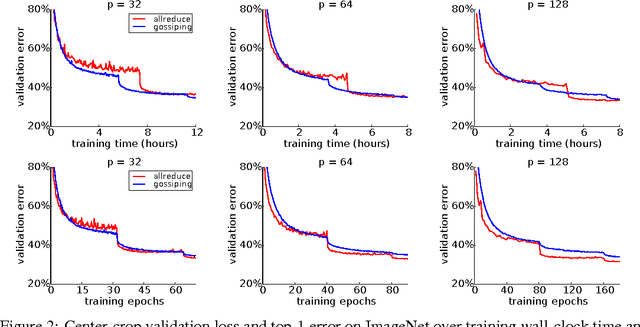
Training time on large datasets for deep neural networks is the principal workflow bottleneck in a number of important applications of deep learning, such as object classification and detection in automatic driver assistance systems (ADAS). To minimize training time, the training of a deep neural network must be scaled beyond a single machine to as many machines as possible by distributing the optimization method used for training. While a number of approaches have been proposed for distributed stochastic gradient descent (SGD), at the current time synchronous approaches to distributed SGD appear to be showing the greatest performance at large scale. Synchronous scaling of SGD suffers from the need to synchronize all processors on each gradient step and is not resilient in the face of failing or lagging processors. In asynchronous approaches using parameter servers, training is slowed by contention to the parameter server. In this paper we compare the convergence of synchronous and asynchronous SGD for training a modern ResNet network architecture on the ImageNet classification problem. We also propose an asynchronous method, gossiping SGD, that aims to retain the positive features of both systems by replacing the all-reduce collective operation of synchronous training with a gossip aggregation algorithm. We find, perhaps counterintuitively, that asynchronous SGD, including both elastic averaging and gossiping, converges faster at fewer nodes (up to about 32 nodes), whereas synchronous SGD scales better to more nodes (up to about 100 nodes).
Convolutional Monte Carlo Rollouts in Go
Dec 10, 2015


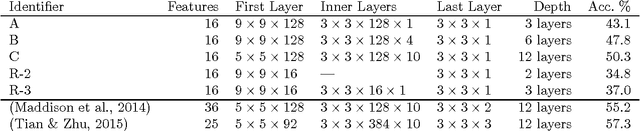
In this work, we present a MCTS-based Go-playing program which uses convolutional networks in all parts. Our method performs MCTS in batches, explores the Monte Carlo search tree using Thompson sampling and a convolutional network, and evaluates convnet-based rollouts on the GPU. We achieve strong win rates against open source Go programs and attain competitive results against state of the art convolutional net-based Go-playing programs.