 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrieval Collapses When AI Pollutes the Web
Feb 18, 2026The rapid proliferation of AI-generated content on the Web presents a structural risk to information retrieval, as search engines and Retrieval-Augmented Generation (RAG) systems increasingly consume evidence produced by the Large Language Models (LLMs). We characterize this ecosystem-level failure mode as Retrieval Collapse, a two-stage process where (1) AI-generated content dominates search results, eroding source diversity, and (2) low-quality or adversarial content infiltrates the retrieval pipeline. We analyzed this dynamic through controlled experiments involving both high-quality SEO-style content and adversarially crafted content. In the SEO scenario, a 67\% pool contamination led to over 80\% exposure contamination, creating a homogenized yet deceptively healthy state where answer accuracy remains stable despite the reliance on synthetic sources. Conversely, under adversarial contamination, baselines like BM25 exposed $\sim$19\% of harmful content, whereas LLM-based rankers demonstrated stronger suppression capabilities. These findings highlight the risk of retrieval pipelines quietly shifting toward synthetic evidence and the need for retrieval-aware strategies to prevent a self-reinforcing cycle of quality decline in Web-grounded systems.
CUE-M: Contextual Understanding and Enhanced Search with Multimodal Large Language Model
Nov 19, 2024



The integration of Retrieval-Augmented Generation (RAG) with Multimodal Large Language Models (MLLMs) has expanded the scope of multimodal query resolution. However, current systems struggle with intent understanding, information retrieval, and safety filtering, limiting their effectiveness. This paper introduces Contextual Understanding and Enhanced Search with MLLM (CUE-M), a novel multimodal search pipeline that addresses these challenges through a multi-stage framework comprising image context enrichment, intent refinement, contextual query generation, external API integration, and relevance-based filtering. CUE-M incorporates a robust safety framework combining image-based, text-based, and multimodal classifiers, dynamically adapting to instance- and category-specific risks. Evaluations on a multimodal Q&A dataset and a public safety benchmark demonstrate that CUE-M outperforms baselines in accuracy, knowledge integration, and safety, advancing the capabilities of multimodal retrieval systems.
Deciding Whether to Ask Clarifying Questions in Large-Scale Spoken Language Understanding
Sep 25, 2021
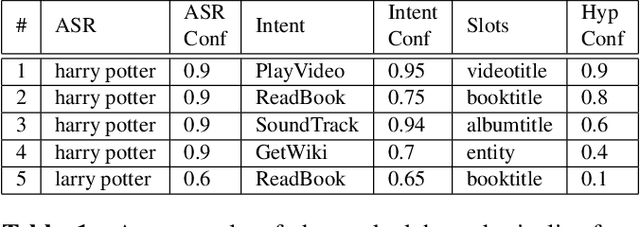

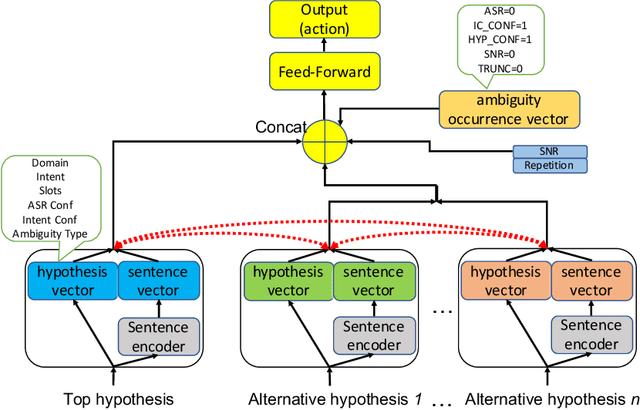
A large-scale conversational agent can suffer from understanding user utterances with various ambiguities such as ASR ambiguity, intent ambiguity, and hypothesis ambiguity. When ambiguities are detected, the agent should engage in a clarifying dialog to resolve the ambiguities before committing to actions. However, asking clarifying questions for all the ambiguity occurrences could lead to asking too many questions, essentially hampering the user experience. To trigger clarifying questions only when necessary for the user satisfaction, we propose a neural self-attentive model that leverages the hypotheses with ambiguities and contextual signals. We conduct extensive experiments on five common ambiguity types using real data from a large-scale commercial conversational agent and demonstrate significant improvement over a set of baseline approaches.
AUGNLG: Few-shot Natural Language Generation using Self-trained Data Augmentation
Jun 10, 2021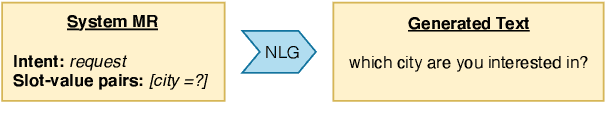
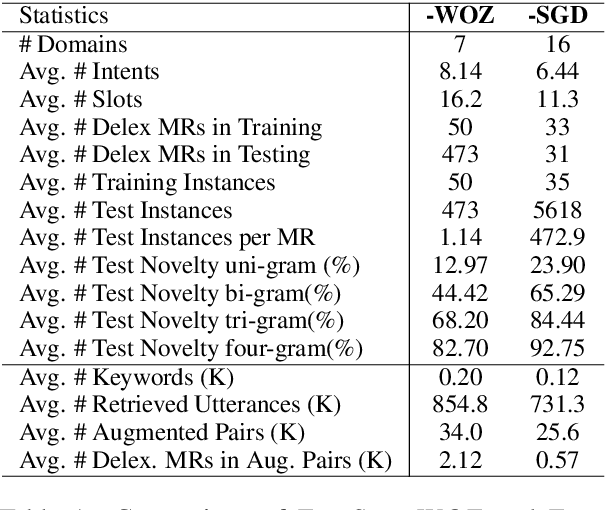
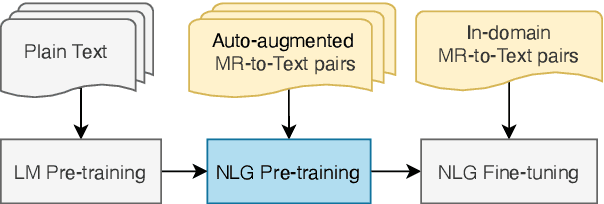

Natural Language Generation (NLG) is a key component in a task-oriented dialogue system, which converts the structured meaning representation (MR) to the natural language. For large-scale conversational systems, where it is common to have over hundreds of intents and thousands of slots, neither template-based approaches nor model-based approaches are scalable. Recently, neural NLGs started leveraging transfer learning and showed promising results in few-shot settings. This paper proposes AUGNLG, a novel data augmentation approach that combines a self-trained neural retrieval model with a few-shot learned NLU model, to automatically create MR-to-Text data from open-domain texts. The proposed system mostly outperforms the state-of-the-art methods on the FewShotWOZ data in both BLEU and Slot Error Rate. We further confirm improved results on the FewShotSGD data and provide comprehensive analysis results on key components of our system. Our code and data are available at https://github.com/XinnuoXu/AugNLG.
Learning Slice-Aware Representations with Mixture of Attentions
Jun 04, 2021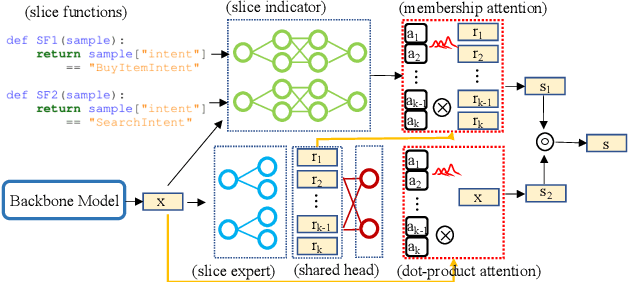

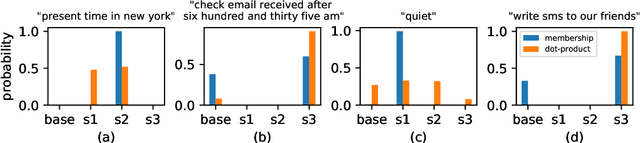
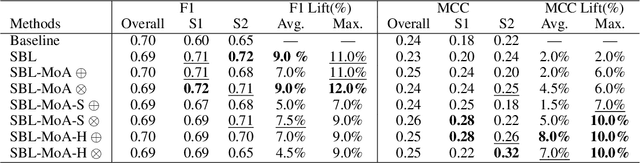
Real-world machine learning systems are achieving remarkable performance in terms of coarse-grained metrics like overall accuracy and F-1 score. However, model improvement and development often require fine-grained modeling on individual data subsets or slices, for instance, the data slices where the models have unsatisfactory results. In practice, it gives tangible values for developing such models that can pay extra attention to critical or interested slices while retaining the original overall performance. This work extends the recent slice-based learning (SBL)~\cite{chen2019slice} with a mixture of attentions (MoA) to learn slice-aware dual attentive representations. We empirically show that the MoA approach outperforms the baseline method as well as the original SBL approach on monitored slices with two natural language understanding (NLU) tasks.
Handling Long-Tail Queries with Slice-Aware Conversational Systems
Apr 26, 2021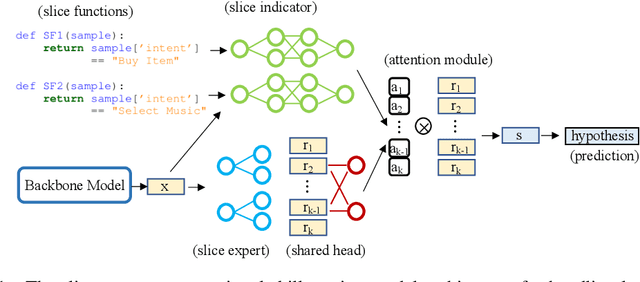

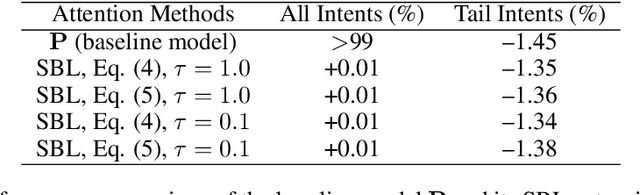

We have been witnessing the usefulness of conversational AI systems such as Siri and Alexa, directly impacting our daily lives. These systems normally rely on machine learning models evolving over time to provide quality user experience. However, the development and improvement of the models are challenging because they need to support both high (head) and low (tail) usage scenarios, requiring fine-grained modeling strategies for specific data subsets or slices. In this paper, we explore the recent concept of slice-based learning (SBL) (Chen et al., 2019) to improve our baseline conversational skill routing system on the tail yet critical query traffic. We first define a set of labeling functions to generate weak supervision data for the tail intents. We then extend the baseline model towards a slice-aware architecture, which monitors and improves the model performance on the selected tail intents. Applied to de-identified live traffic from a commercial conversational AI system, our experiments show that the slice-aware model is beneficial in improving model performance for the tail intents while maintaining the overall performance.
Neural model robustness for skill routing in large-scale conversational AI systems: A design choice exploration
Mar 04, 2021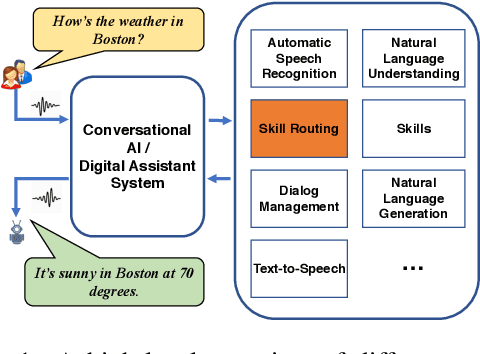
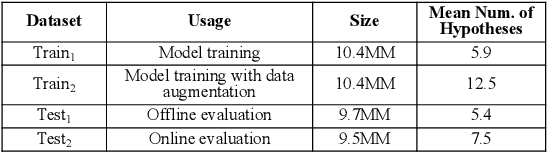
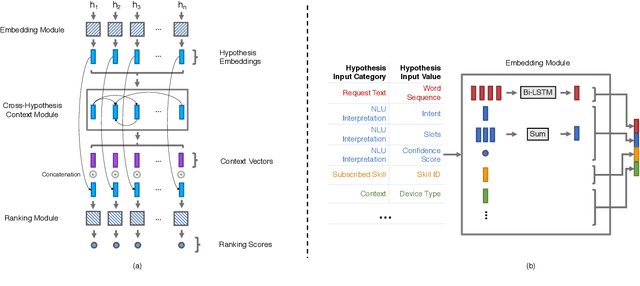
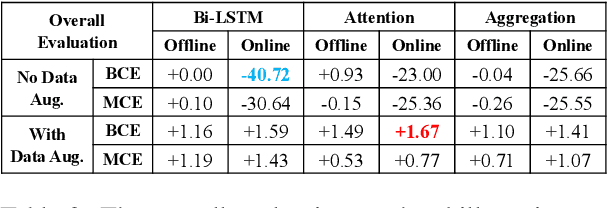
Current state-of-the-art large-scale conversational AI or intelligent digital assistant systems in industry comprises a set of components such as Automatic Speech Recognition (ASR) and Natural Language Understanding (NLU). For some of these systems that leverage a shared NLU ontology (e.g., a centralized intent/slot schema), there exists a separate skill routing component to correctly route a request to an appropriate skill, which is either a first-party or third-party application that actually executes on a user request. The skill routing component is needed as there are thousands of skills that can either subscribe to the same intent and/or subscribe to an intent under specific contextual conditions (e.g., device has a screen). Ensuring model robustness or resilience in the skill routing component is an important problem since skills may dynamically change their subscription in the ontology after the skill routing model has been deployed to production. We show how different modeling design choices impact the model robustness in the context of skill routing on a state-of-the-art commercial conversational AI system, specifically on the choices around data augmentation, model architecture, and optimization method. We show that applying data augmentation can be a very effective and practical way to drastically improve model robustness.
A Data-driven Approach to Estimate User Satisfaction in Multi-turn Dialogues
Mar 01, 2021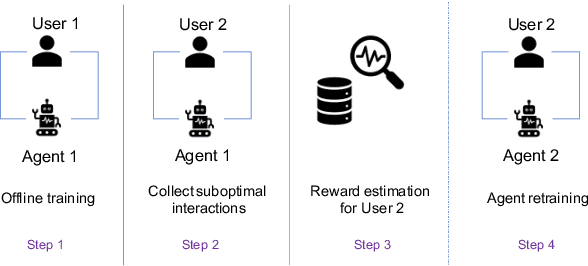
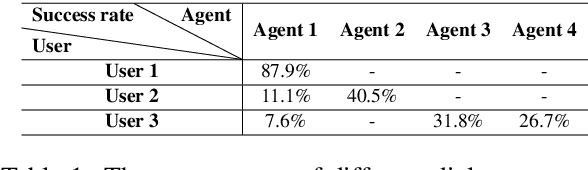

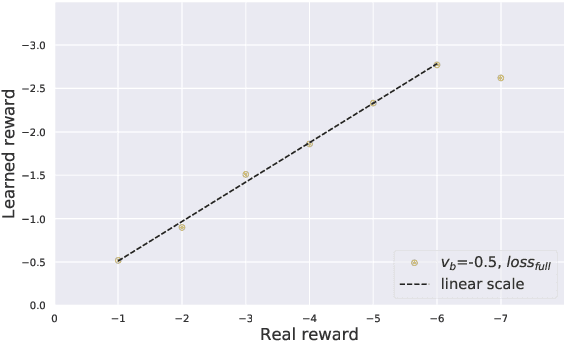
The evaluation of multi-turn dialogues remains challenging. The common approach of labeling the user satisfaction with the experience on the dialogue level does not reflect the task's difficulty. Therefore assigning the same experience score to two tasks with different complexity levels is misleading. Another approach, which suggests evaluating each dialogue turn independently, ignores each turn's long-term influence over the final user experience with dialogue. We instead develop a new method to estimate the turn-level satisfaction for dialogue, which is context-sensitive and has a long-term view. Our approach is data-driven which makes it easily personalized. The interactions between users and dialogue systems are formulated using a budget consumption setup. We assume the user has an initial interaction budget for a conversation based on the task complexity, and each dialogue turn has a cost. When the task is completed or the budget has been run out, the user will quit the interaction. We demonstrate the effectiveness of our method by extensive experimentation with a simulated dialogue platform and a realistic dialogue dataset.
A Scalable Framework for Learning From Implicit User Feedback to Improve Natural Language Understanding in Large-Scale Conversational AI Systems
Oct 23, 2020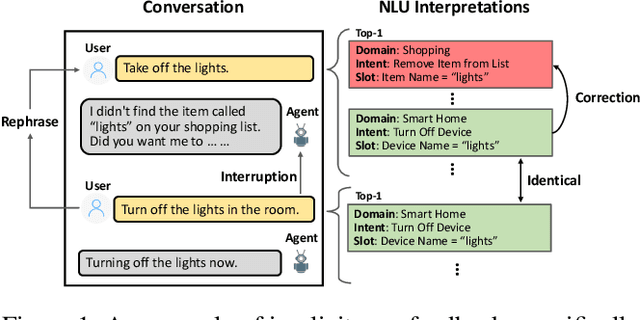
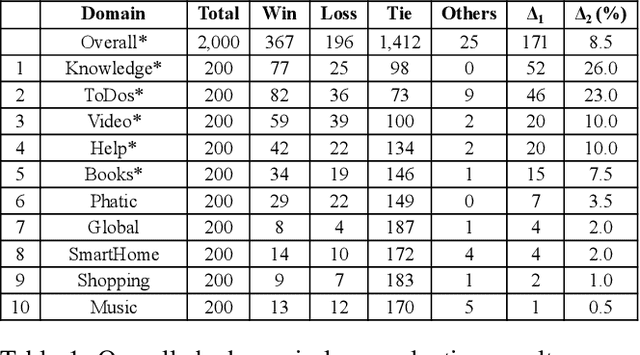
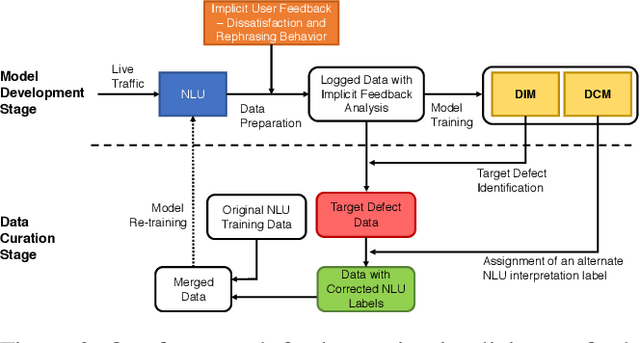
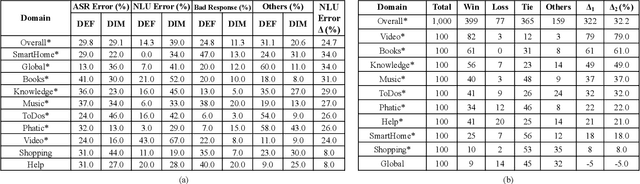
Natural Language Understanding (NLU) is an established component within a conversational AI or digital assistant system, and it is responsible for producing semantic understanding of a user request. We propose a scalable and automatic approach for improving NLU in a large-scale conversational AI system by leveraging implicit user feedback, with an insight that user interaction data and dialog context have rich information embedded from which user satisfaction and intention can be inferred. In particular, we propose a general domain-agnostic framework for curating new supervision data for improving NLU from live production traffic. With an extensive set of experiments, we show the results of applying the framework and improving NLU for a large-scale production system and show its impact across 10 domains.
Self-Supervised Contrastive Learning for Efficient User Satisfaction Prediction in Conversational Agents
Oct 21, 2020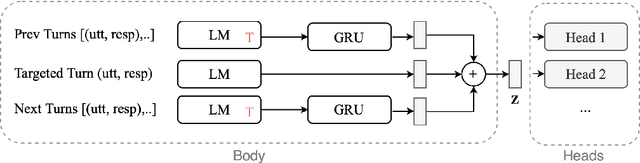
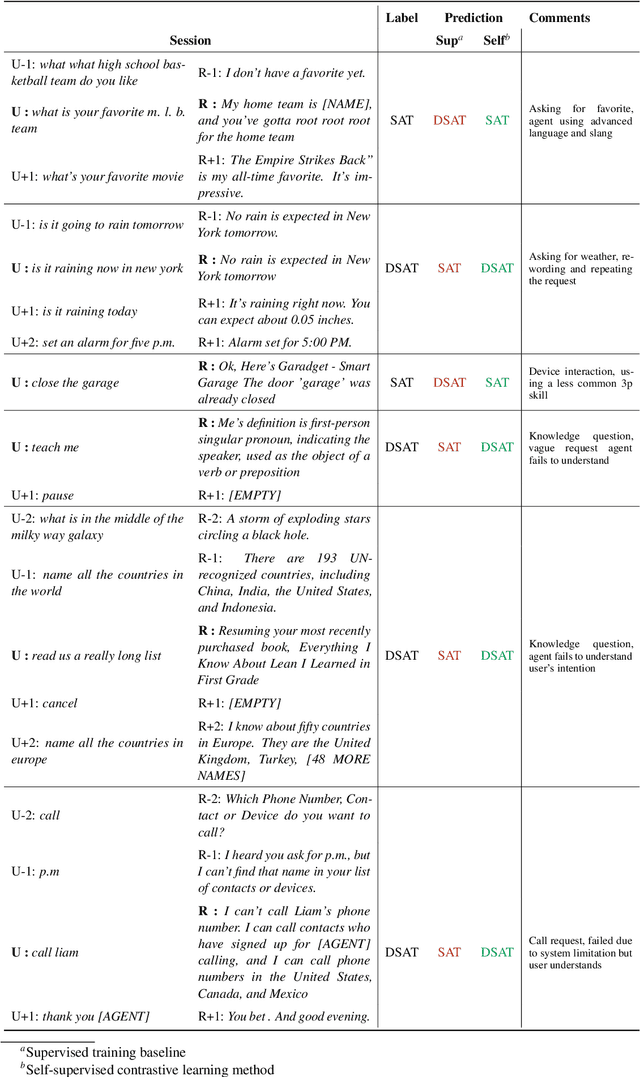


Turn-level user satisfaction is one of the most important performance metrics for conversational agents. It can be used to monitor the agent's performance and provide insights about defective user experiences. Moreover, a powerful satisfaction model can be used as an objective function that a conversational agent continuously optimizes for. While end-to-end deep learning has shown promising results, having access to a large number of reliable annotated samples required by these methods remains challenging. In a large-scale conversational system, there is a growing number of newly developed skills, making the traditional data collection, annotation, and modeling process impractical due to the required annotation costs as well as the turnaround times. In this paper, we suggest a self-supervised contrastive learning approach that leverages the pool of unlabeled data to learn user-agent interactions. We show that the pre-trained models using the self-supervised objective are transferable to the user satisfaction prediction. In addition, we propose a novel few-shot transfer learning approach that ensures better transferability for very small sample sizes. The suggested few-shot method does not require any inner loop optimization process and is scalable to very large datasets and complex models. Based on our experiments using real-world data from a large-scale commercial system, the suggested approach is able to significantly reduce the required number of annotations, while improving the generalization on unseen out-of-domain skills.