 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRidgeSfM: Structure from Motion via Robust Pairwise Matching Under Depth Uncertainty
Nov 20, 2020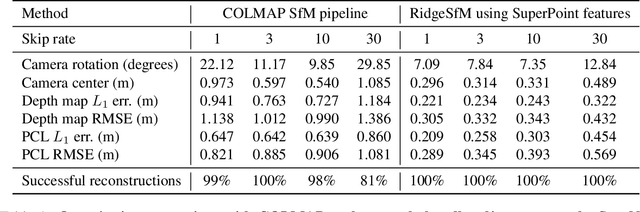
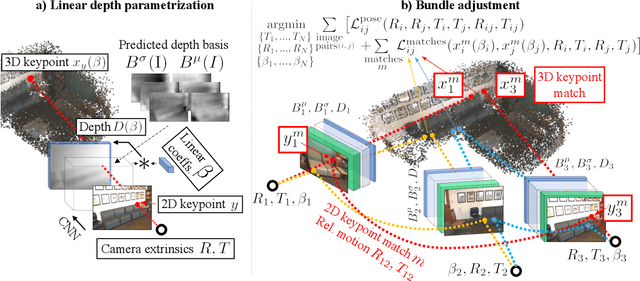
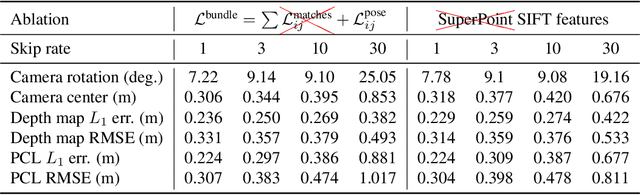

We consider the problem of simultaneously estimating a dense depth map and camera pose for a large set of images of an indoor scene. While classical SfM pipelines rely on a two-step approach where cameras are first estimated using a bundle adjustment in order to ground the ensuing multi-view stereo stage, both our poses and dense reconstructions are a direct output of an altered bundle adjuster. To this end, we parametrize each depth map with a linear combination of a limited number of basis "depth-planes" predicted in a monocular fashion by a deep net. Using a set of high-quality sparse keypoint matches, we optimize over the per-frame linear combinations of depth planes and camera poses to form a geometrically consistent cloud of keypoints. Although our bundle adjustment only considers sparse keypoints, the inferred linear coefficients of the basis planes immediately give us dense depth maps. RidgeSfM is able to collectively align hundreds of frames, which is its main advantage over recent memory-heavy deep alternatives that can align at most 10 frames. Quantitative comparisons reveal performance superior to a state-of-the-art large-scale SfM pipeline.
3D Multi-bodies: Fitting Sets of Plausible 3D Human Models to Ambiguous Image Data
Nov 02, 2020
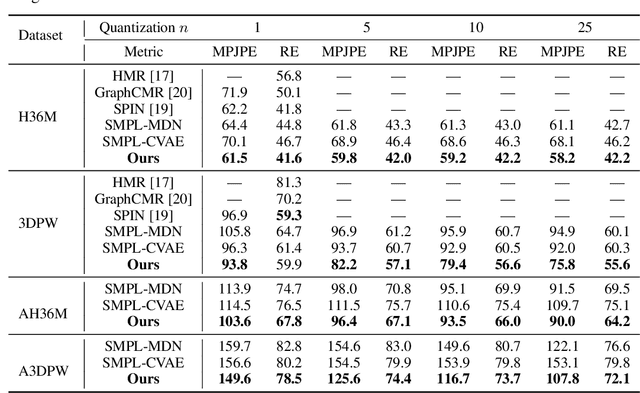

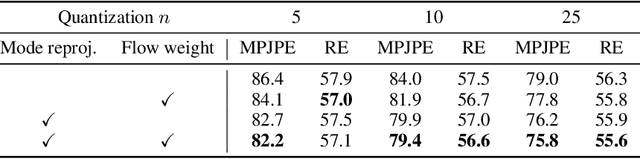
We consider the problem of obtaining dense 3D reconstructions of humans from single and partially occluded views. In such cases, the visual evidence is usually insufficient to identify a 3D reconstruction uniquely, so we aim at recovering several plausible reconstructions compatible with the input data. We suggest that ambiguities can be modelled more effectively by parametrizing the possible body shapes and poses via a suitable 3D model, such as SMPL for humans. We propose to learn a multi-hypothesis neural network regressor using a best-of-M loss, where each of the M hypotheses is constrained to lie on a manifold of plausible human poses by means of a generative model. We show that our method outperforms alternative approaches in ambiguous pose recovery on standard benchmarks for 3D humans, and in heavily occluded versions of these benchmarks.
Training with Quantization Noise for Extreme Model Compression
Apr 17, 2020
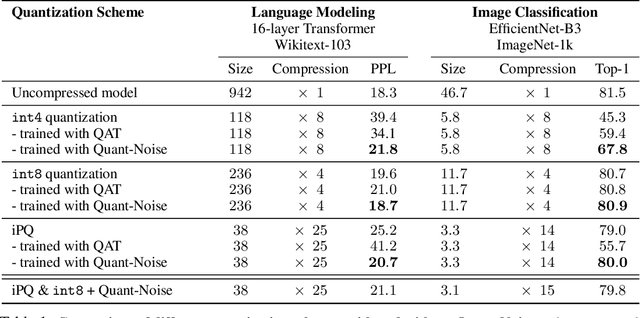
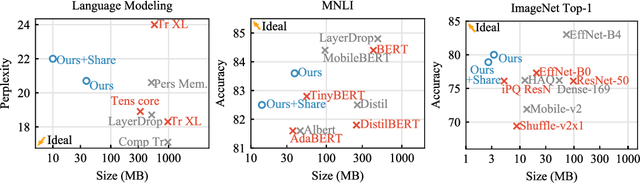
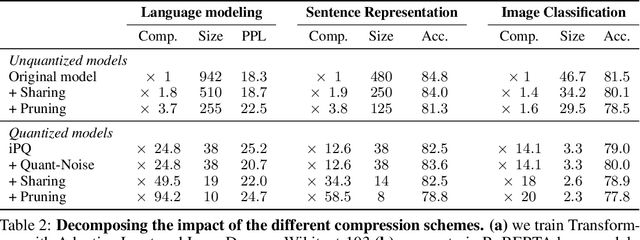
We tackle the problem of producing compact models, maximizing their accuracy for a given model size. A standard solution is to train networks with Quantization Aware Training, where the weights are quantized during training and the gradients approximated with the Straight-Through Estimator. In this paper, we extend this approach to work beyond int8 fixed-point quantization with extreme compression methods where the approximations introduced by STE are severe, such as Product Quantization. Our proposal is to only quantize a different random subset of weights during each forward, allowing for unbiased gradients to flow through the other weights. Controlling the amount of noise and its form allows for extreme compression rates while maintaining the performance of the original model. As a result we establish new state-of-the-art compromises between accuracy and model size both in natural language processing and image classification. For example, applying our method to state-of-the-art Transformer and ConvNet architectures, we can achieve 82.5% accuracy on MNLI by compressing RoBERTa to 14MB and 80.0 top-1 accuracy on ImageNet by compressing an EfficientNet-B3 to 3.3MB.
C3DPO: Canonical 3D Pose Networks for Non-Rigid Structure From Motion
Oct 15, 2019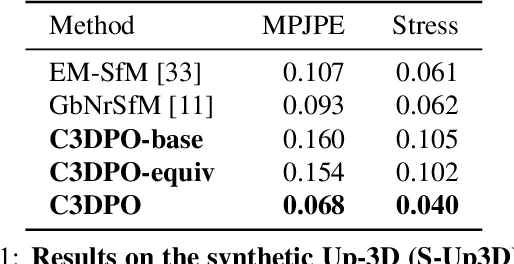
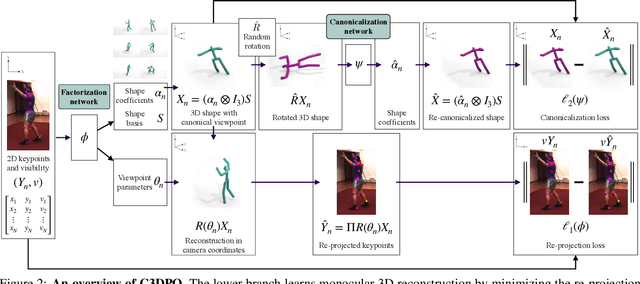
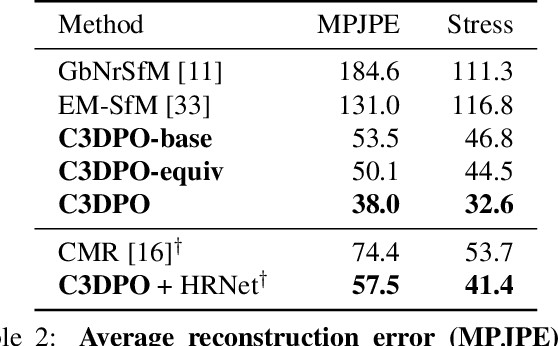
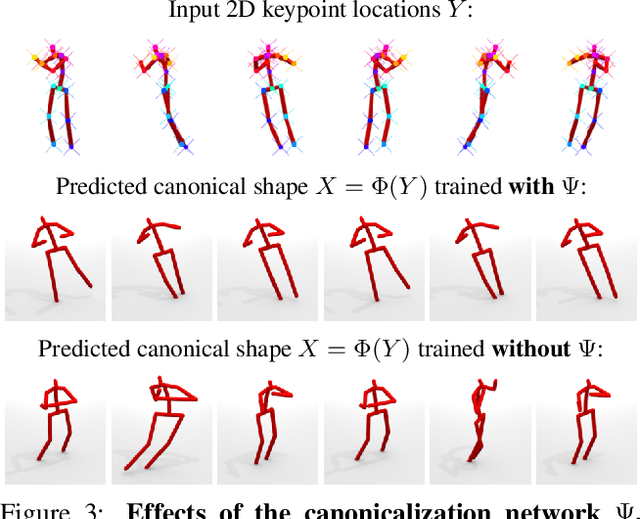
We propose C3DPO, a method for extracting 3D models of deformable objects from 2D keypoint annotations in unconstrained images. We do so by learning a deep network that reconstructs a 3D object from a single view at a time, accounting for partial occlusions, and explicitly factoring the effects of viewpoint changes and object deformations. In order to achieve this factorization, we introduce a novel regularization technique. We first show that the factorization is successful if, and only if, there exists a certain canonicalization function of the reconstructed shapes. Then, we learn the canonicalization function together with the reconstruction one, which constrains the result to be consistent. We demonstrate state-of-the-art reconstruction results for methods that do not use ground-truth 3D supervision for a number of benchmarks, including Up3D and PASCAL3D+. Source code has been made available at https://github.com/facebookresearch/c3dpo_nrsfm.
* Added a link to the source code into the abstract
And the Bit Goes Down: Revisiting the Quantization of Neural Networks
Jul 29, 2019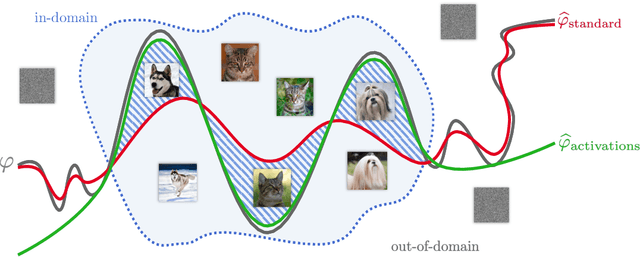
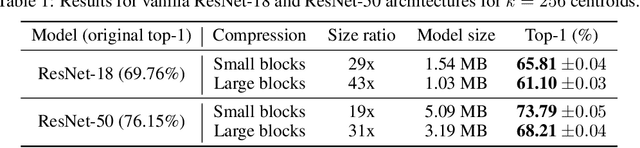
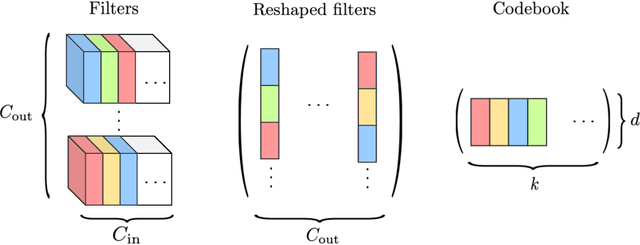

In this paper, we address the problem of reducing the memory footprint of ResNet-like convolutional network architectures. We introduce a vector quantization method that aims at preserving the quality of the reconstruction of the network outputs and not its weights. The advantage of our approach is that it minimizes the loss reconstruction error for in-domain inputs and does not require any labelled data. We also use byte-aligned codebooks to produce compressed networks with efficient inference on CPU. We validate our approach by quantizing a high performing ResNet-50 model to a memory size of 5 MB (20x compression factor) while preserving a top-1 accuracy of 76.1% on ImageNet object classification and by compressing a Mask R-CNN with a size budget around 6 MB.
Equi-normalization of Neural Networks
Feb 27, 2019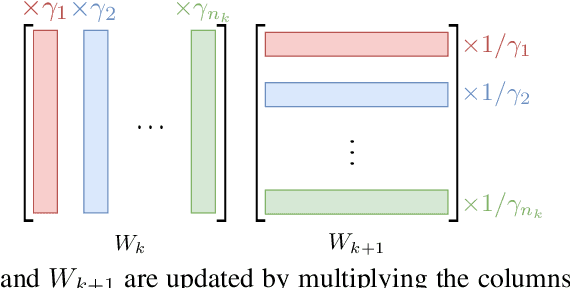

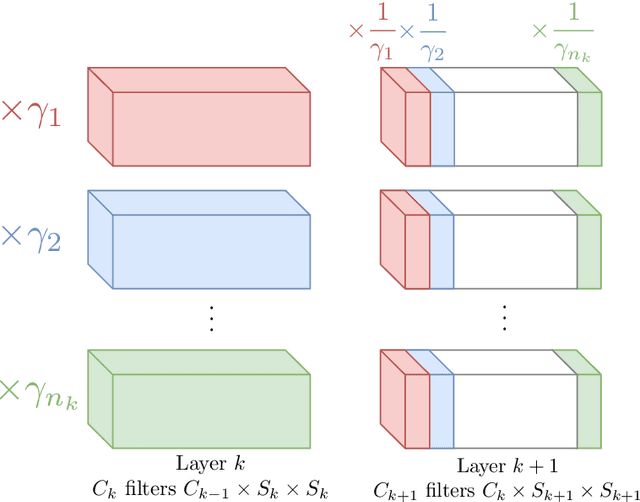
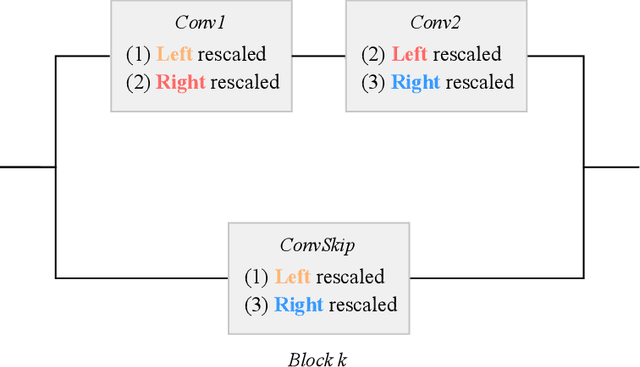
Modern neural networks are over-parametrized. In particular, each rectified linear hidden unit can be modified by a multiplicative factor by adjusting input and output weights, without changing the rest of the network. Inspired by the Sinkhorn-Knopp algorithm, we introduce a fast iterative method for minimizing the L2 norm of the weights, equivalently the weight decay regularizer. It provably converges to a unique solution. Interleaving our algorithm with SGD during training improves the test accuracy. For small batches, our approach offers an alternative to batch-and group-normalization on CIFAR-10 and ImageNet with a ResNet-18.
Unsupervised learning with sparse space-and-time autoencoders
Nov 26, 2018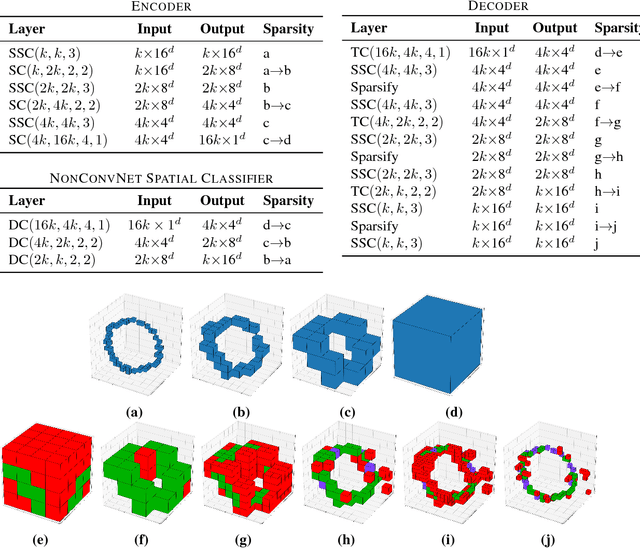

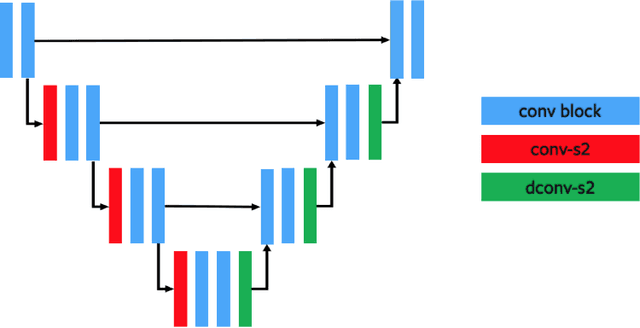
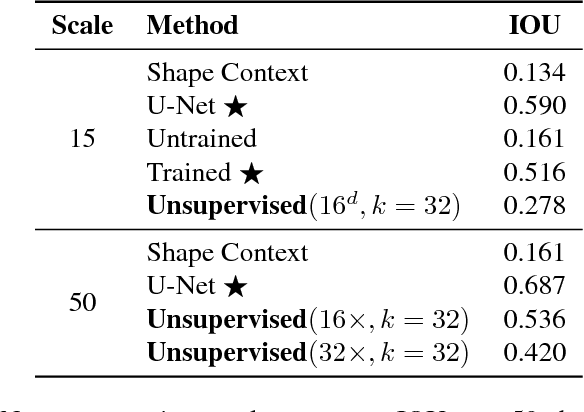
We use spatially-sparse two, three and four dimensional convolutional autoencoder networks to model sparse structures in 2D space, 3D space, and 3+1=4 dimensional space-time. We evaluate the resulting latent spaces by testing their usefulness for downstream tasks. Applications are to handwriting recognition in 2D, segmentation for parts in 3D objects, segmentation for objects in 3D scenes, and body-part segmentation for 4D wire-frame models generated from motion capture data.
3D Semantic Segmentation with Submanifold Sparse Convolutional Networks
Nov 28, 2017

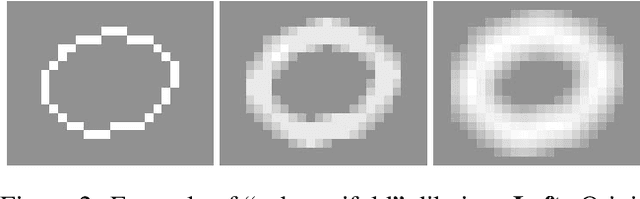
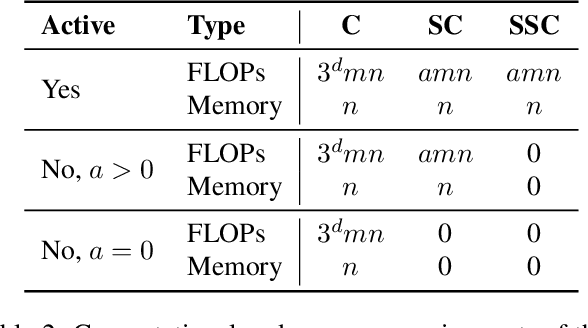
Convolutional networks are the de-facto standard for analyzing spatio-temporal data such as images, videos, and 3D shapes. Whilst some of this data is naturally dense (e.g., photos), many other data sources are inherently sparse. Examples include 3D point clouds that were obtained using a LiDAR scanner or RGB-D camera. Standard "dense" implementations of convolutional networks are very inefficient when applied on such sparse data. We introduce new sparse convolutional operations that are designed to process spatially-sparse data more efficiently, and use them to develop spatially-sparse convolutional networks. We demonstrate the strong performance of the resulting models, called submanifold sparse convolutional networks (SSCNs), on two tasks involving semantic segmentation of 3D point clouds. In particular, our models outperform all prior state-of-the-art on the test set of a recent semantic segmentation competition.
Large-Scale 3D Shape Reconstruction and Segmentation from ShapeNet Core55
Oct 27, 2017
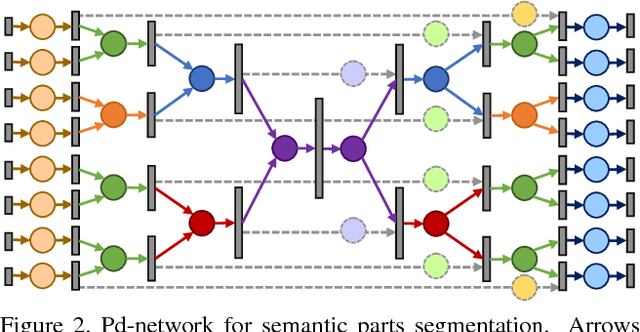
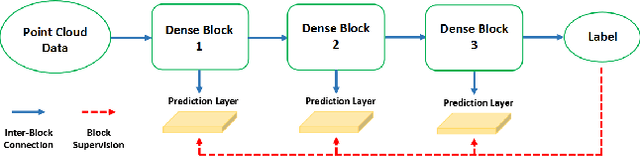
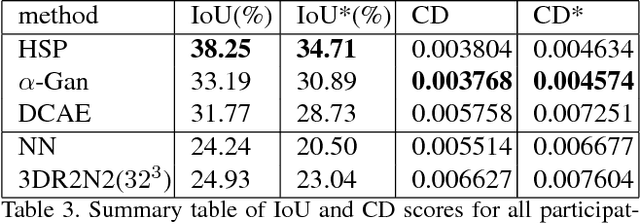
We introduce a large-scale 3D shape understanding benchmark using data and annotation from ShapeNet 3D object database. The benchmark consists of two tasks: part-level segmentation of 3D shapes and 3D reconstruction from single view images. Ten teams have participated in the challenge and the best performing teams have outperformed state-of-the-art approaches on both tasks. A few novel deep learning architectures have been proposed on various 3D representations on both tasks. We report the techniques used by each team and the corresponding performances. In addition, we summarize the major discoveries from the reported results and possible trends for the future work in the field.
Submanifold Sparse Convolutional Networks
Jun 05, 2017
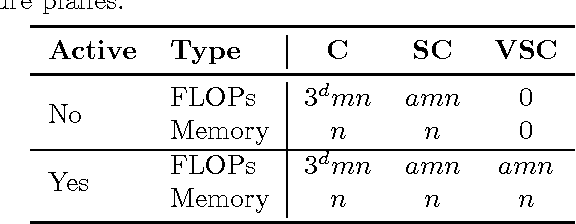
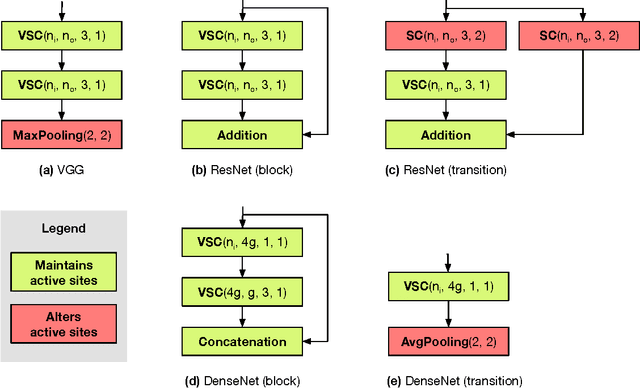
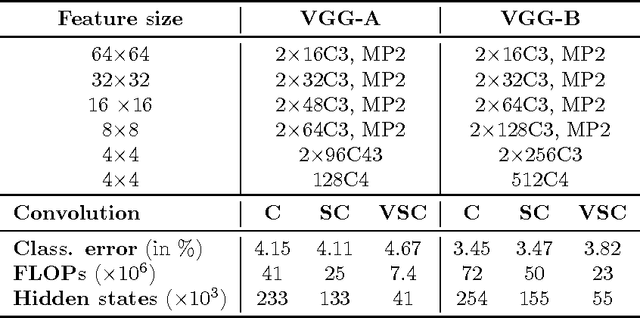
Convolutional network are the de-facto standard for analysing spatio-temporal data such as images, videos, 3D shapes, etc. Whilst some of this data is naturally dense (for instance, photos), many other data sources are inherently sparse. Examples include pen-strokes forming on a piece of paper, or (colored) 3D point clouds that were obtained using a LiDAR scanner or RGB-D camera. Standard "dense" implementations of convolutional networks are very inefficient when applied on such sparse data. We introduce a sparse convolutional operation tailored to processing sparse data that differs from prior work on sparse convolutional networks in that it operates strictly on submanifolds, rather than "dilating" the observation with every layer in the network. Our empirical analysis of the resulting submanifold sparse convolutional networks shows that they perform on par with state-of-the-art methods whilst requiring substantially less computation.