 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEclipse: Disambiguating Illumination and Materials using Unintended Shadows
Jun 08, 2023



Decomposing an object's appearance into representations of its materials and the surrounding illumination is difficult, even when the object's 3D shape is known beforehand. This problem is ill-conditioned because diffuse materials severely blur incoming light, and is ill-posed because diffuse materials under high-frequency lighting can be indistinguishable from shiny materials under low-frequency lighting. We show that it is possible to recover precise materials and illumination -- even from diffuse objects -- by exploiting unintended shadows, like the ones cast onto an object by the photographer who moves around it. These shadows are a nuisance in most previous inverse rendering pipelines, but here we exploit them as signals that improve conditioning and help resolve material-lighting ambiguities. We present a method based on differentiable Monte Carlo ray tracing that uses images of an object to jointly recover its spatially-varying materials, the surrounding illumination environment, and the shapes of the unseen light occluders who inadvertently cast shadows upon it.
Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields
Apr 13, 2023



Neural Radiance Field training can be accelerated through the use of grid-based representations in NeRF's learned mapping from spatial coordinates to colors and volumetric density. However, these grid-based approaches lack an explicit understanding of scale and therefore often introduce aliasing, usually in the form of jaggies or missing scene content. Anti-aliasing has previously been addressed by mip-NeRF 360, which reasons about sub-volumes along a cone rather than points along a ray, but this approach is not natively compatible with current grid-based techniques. We show how ideas from rendering and signal processing can be used to construct a technique that combines mip-NeRF 360 and grid-based models such as Instant NGP to yield error rates that are 8% - 76% lower than either prior technique, and that trains 22x faster than mip-NeRF 360.
DreamBooth3D: Subject-Driven Text-to-3D Generation
Mar 27, 2023We present DreamBooth3D, an approach to personalize text-to-3D generative models from as few as 3-6 casually captured images of a subject. Our approach combines recent advances in personalizing text-to-image models (DreamBooth) with text-to-3D generation (DreamFusion). We find that naively combining these methods fails to yield satisfactory subject-specific 3D assets due to personalized text-to-image models overfitting to the input viewpoints of the subject. We overcome this through a 3-stage optimization strategy where we jointly leverage the 3D consistency of neural radiance fields together with the personalization capability of text-to-image models. Our method can produce high-quality, subject-specific 3D assets with text-driven modifications such as novel poses, colors and attributes that are not seen in any of the input images of the subject.
BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis
Feb 28, 2023



We present a method for reconstructing high-quality meshes of large unbounded real-world scenes suitable for photorealistic novel view synthesis. We first optimize a hybrid neural volume-surface scene representation designed to have well-behaved level sets that correspond to surfaces in the scene. We then bake this representation into a high-quality triangle mesh, which we equip with a simple and fast view-dependent appearance model based on spherical Gaussians. Finally, we optimize this baked representation to best reproduce the captured viewpoints, resulting in a model that can leverage accelerated polygon rasterization pipelines for real-time view synthesis on commodity hardware. Our approach outperforms previous scene representations for real-time rendering in terms of accuracy, speed, and power consumption, and produces high quality meshes that enable applications such as appearance editing and physical simulation.
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
Feb 23, 2023



Neural radiance fields enable state-of-the-art photorealistic view synthesis. However, existing radiance field representations are either too compute-intensive for real-time rendering or require too much memory to scale to large scenes. We present a Memory-Efficient Radiance Field (MERF) representation that achieves real-time rendering of large-scale scenes in a browser. MERF reduces the memory consumption of prior sparse volumetric radiance fields using a combination of a sparse feature grid and high-resolution 2D feature planes. To support large-scale unbounded scenes, we introduce a novel contraction function that maps scene coordinates into a bounded volume while still allowing for efficient ray-box intersection. We design a lossless procedure for baking the parameterization used during training into a model that achieves real-time rendering while still preserving the photorealistic view synthesis quality of a volumetric radiance field.
AligNeRF: High-Fidelity Neural Radiance Fields via Alignment-Aware Training
Nov 17, 2022Neural Radiance Fields (NeRFs) are a powerful representation for modeling a 3D scene as a continuous function. Though NeRF is able to render complex 3D scenes with view-dependent effects, few efforts have been devoted to exploring its limits in a high-resolution setting. Specifically, existing NeRF-based methods face several limitations when reconstructing high-resolution real scenes, including a very large number of parameters, misaligned input data, and overly smooth details. In this work, we conduct the first pilot study on training NeRF with high-resolution data and propose the corresponding solutions: 1) marrying the multilayer perceptron (MLP) with convolutional layers which can encode more neighborhood information while reducing the total number of parameters; 2) a novel training strategy to address misalignment caused by moving objects or small camera calibration errors; and 3) a high-frequency aware loss. Our approach is nearly free without introducing obvious training/testing costs, while experiments on different datasets demonstrate that it can recover more high-frequency details compared with the current state-of-the-art NeRF models. Project page: \url{https://yifanjiang.net/alignerf.}
DreamFusion: Text-to-3D using 2D Diffusion
Sep 29, 2022


Recent breakthroughs in text-to-image synthesis have been driven by diffusion models trained on billions of image-text pairs. Adapting this approach to 3D synthesis would require large-scale datasets of labeled 3D data and efficient architectures for denoising 3D data, neither of which currently exist. In this work, we circumvent these limitations by using a pretrained 2D text-to-image diffusion model to perform text-to-3D synthesis. We introduce a loss based on probability density distillation that enables the use of a 2D diffusion model as a prior for optimization of a parametric image generator. Using this loss in a DeepDream-like procedure, we optimize a randomly-initialized 3D model (a Neural Radiance Field, or NeRF) via gradient descent such that its 2D renderings from random angles achieve a low loss. The resulting 3D model of the given text can be viewed from any angle, relit by arbitrary illumination, or composited into any 3D environment. Our approach requires no 3D training data and no modifications to the image diffusion model, demonstrating the effectiveness of pretrained image diffusion models as priors.
Block-NeRF: Scalable Large Scene Neural View Synthesis
Feb 10, 2022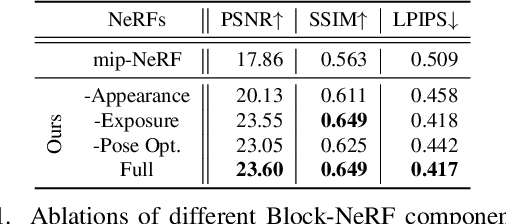
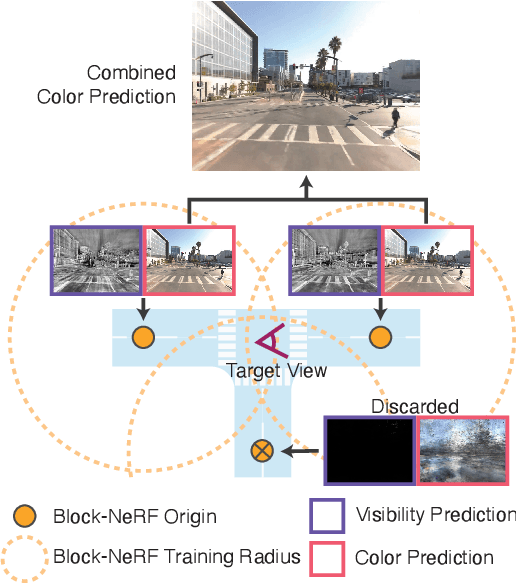
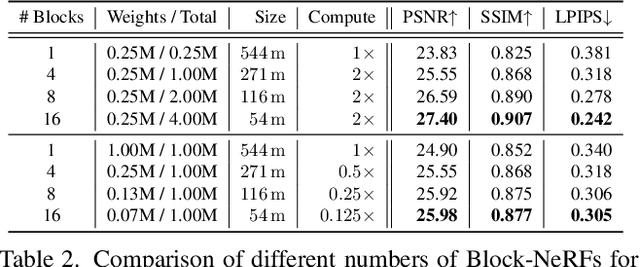
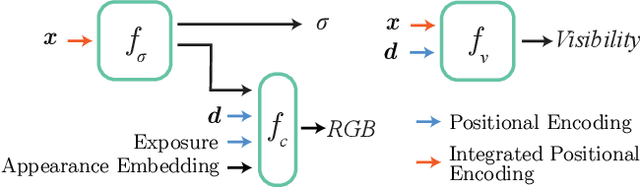
We present Block-NeRF, a variant of Neural Radiance Fields that can represent large-scale environments. Specifically, we demonstrate that when scaling NeRF to render city-scale scenes spanning multiple blocks, it is vital to decompose the scene into individually trained NeRFs. This decomposition decouples rendering time from scene size, enables rendering to scale to arbitrarily large environments, and allows per-block updates of the environment. We adopt several architectural changes to make NeRF robust to data captured over months under different environmental conditions. We add appearance embeddings, learned pose refinement, and controllable exposure to each individual NeRF, and introduce a procedure for aligning appearance between adjacent NeRFs so that they can be seamlessly combined. We build a grid of Block-NeRFs from 2.8 million images to create the largest neural scene representation to date, capable of rendering an entire neighborhood of San Francisco.
Fast and High-Quality Image Denoising via Malleable Convolutions
Jan 04, 2022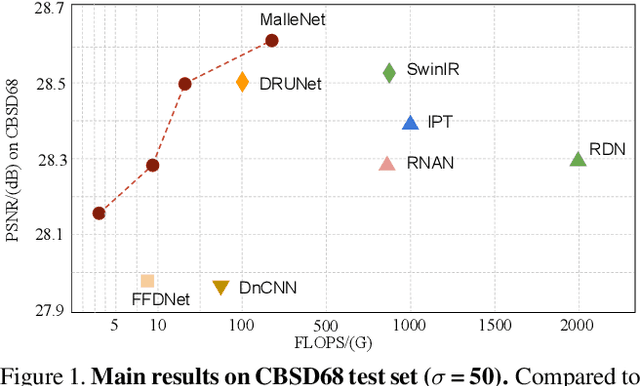
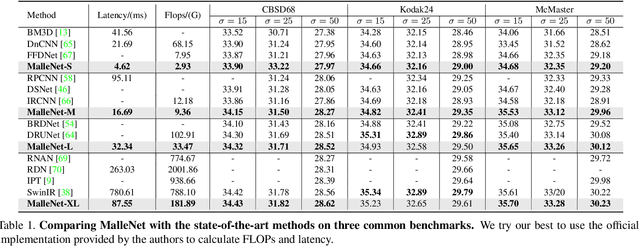
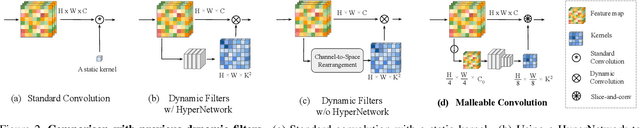
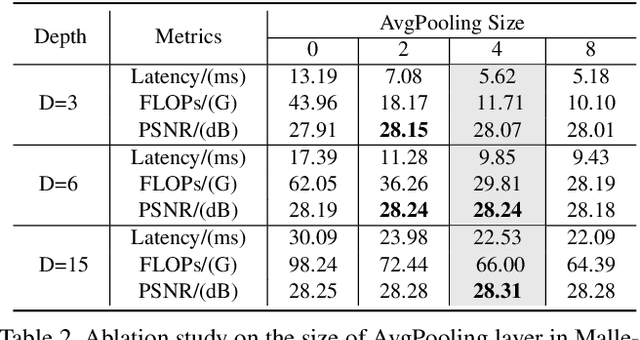
Many image processing networks apply a single set of static convolutional kernels across the entire input image, which is sub-optimal for natural images, as they often consist of heterogeneous visual patterns. Recent works in classification, segmentation, and image restoration have demonstrated that dynamic kernels outperform static kernels at modeling local image statistics. However, these works often adopt per-pixel convolution kernels, which introduce high memory and computation costs. To achieve spatial-varying processing without significant overhead, we present Malleable Convolution (MalleConv), as an efficient variant of dynamic convolution. The weights of MalleConv are dynamically produced by an efficient predictor network capable of generating content-dependent outputs at specific spatial locations. Unlike previous works, MalleConv generates a much smaller set of spatially-varying kernels from input, which enlarges the network's receptive field and significantly reduces computational and memory costs. These kernels are then applied to a full-resolution feature map through an efficient slice-and-conv operator with minimum memory overhead. We further build an efficient denoising network using MalleConv, coined as MalleNet. It achieves high quality results without very deep architecture, e.g., reaching 8.91x faster speed compared to the best performed denoising algorithms (SwinIR), while maintaining similar performance. We also show that a single MalleConv added to a standard convolution-based backbone can contribute significantly to reducing the computational cost or boosting image quality at a similar cost. Project page: https://yifanjiang.net/MalleConv.html
Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
Dec 07, 2021
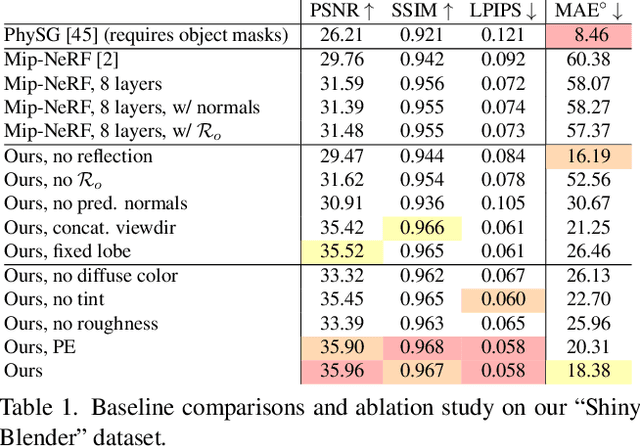
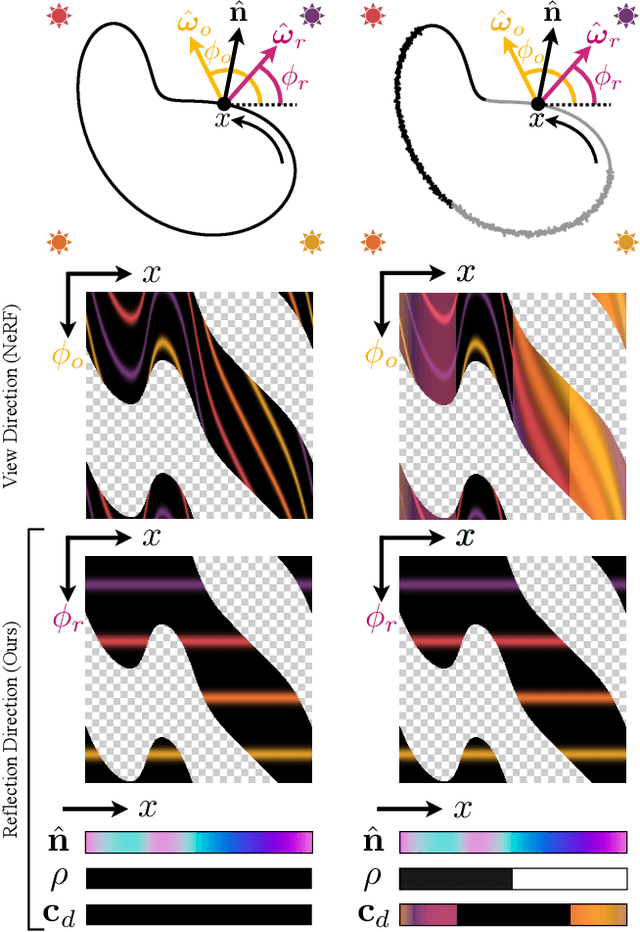
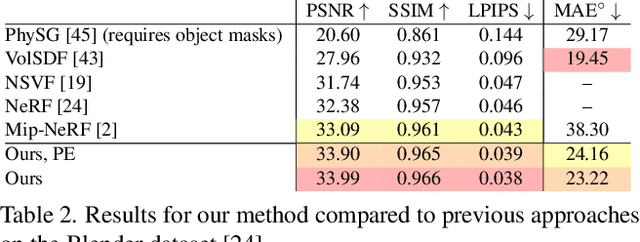
Neural Radiance Fields (NeRF) is a popular view synthesis technique that represents a scene as a continuous volumetric function, parameterized by multilayer perceptrons that provide the volume density and view-dependent emitted radiance at each location. While NeRF-based techniques excel at representing fine geometric structures with smoothly varying view-dependent appearance, they often fail to accurately capture and reproduce the appearance of glossy surfaces. We address this limitation by introducing Ref-NeRF, which replaces NeRF's parameterization of view-dependent outgoing radiance with a representation of reflected radiance and structures this function using a collection of spatially-varying scene properties. We show that together with a regularizer on normal vectors, our model significantly improves the realism and accuracy of specular reflections. Furthermore, we show that our model's internal representation of outgoing radiance is interpretable and useful for scene editing.