 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuted: Multilingual Targeted Offensive Speech Identification and Visualization
Dec 18, 2023



Offensive language such as hate, abuse, and profanity (HAP) occurs in various content on the web. While previous work has mostly dealt with sentence level annotations, there have been a few recent attempts to identify offensive spans as well. We build upon this work and introduce Muted, a system to identify multilingual HAP content by displaying offensive arguments and their targets using heat maps to indicate their intensity. Muted can leverage any transformer-based HAP-classification model and its attention mechanism out-of-the-box to identify toxic spans, without further fine-tuning. In addition, we use the spaCy library to identify the specific targets and arguments for the words predicted by the attention heatmaps. We present the model's performance on identifying offensive spans and their targets in existing datasets and present new annotations on German text. Finally, we demonstrate our proposed visualization tool on multilingual inputs.
Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
Oct 17, 2023



Despite their remarkable capabilities, large language models (LLMs) often produce responses containing factual inaccuracies due to their sole reliance on the parametric knowledge they encapsulate. Retrieval-Augmented Generation (RAG), an ad hoc approach that augments LMs with retrieval of relevant knowledge, decreases such issues. However, indiscriminately retrieving and incorporating a fixed number of retrieved passages, regardless of whether retrieval is necessary, or passages are relevant, diminishes LM versatility or can lead to unhelpful response generation. We introduce a new framework called Self-Reflective Retrieval-Augmented Generation (Self-RAG) that enhances an LM's quality and factuality through retrieval and self-reflection. Our framework trains a single arbitrary LM that adaptively retrieves passages on-demand, and generates and reflects on retrieved passages and its own generations using special tokens, called reflection tokens. Generating reflection tokens makes the LM controllable during the inference phase, enabling it to tailor its behavior to diverse task requirements. Experiments show that Self-RAG (7B and 13B parameters) significantly outperforms state-of-the-art LLMs and retrieval-augmented models on a diverse set of tasks. Specifically, Self-RAG outperforms ChatGPT and retrieval-augmented Llama2-chat on Open-domain QA, reasoning and fact verification tasks, and it shows significant gains in improving factuality and citation accuracy for long-form generations relative to these models.
Inference-time Re-ranker Relevance Feedback for Neural Information Retrieval
May 19, 2023



Neural information retrieval often adopts a retrieve-and-rerank framework: a bi-encoder network first retrieves K (e.g., 100) candidates that are then re-ranked using a more powerful cross-encoder model to rank the better candidates higher. The re-ranker generally produces better candidate scores than the retriever, but is limited to seeing only the top K retrieved candidates, thus providing no improvements in retrieval performance as measured by Recall@K. In this work, we leverage the re-ranker to also improve retrieval by providing inference-time relevance feedback to the retriever. Concretely, we update the retriever's query representation for a test instance using a lightweight inference-time distillation of the re-ranker's prediction for that instance. The distillation loss is designed to bring the retriever's candidate scores closer to those of the re-ranker. A second retrieval step is then performed with the updated query vector. We empirically show that our approach, which can serve arbitrary retrieve-and-rerank pipelines, significantly improves retrieval recall in multiple domains, languages, and modalities.
UDAPDR: Unsupervised Domain Adaptation via LLM Prompting and Distillation of Rerankers
Mar 01, 2023



Many information retrieval tasks require large labeled datasets for fine-tuning. However, such datasets are often unavailable, and their utility for real-world applications can diminish quickly due to domain shifts. To address this challenge, we develop and motivate a method for using large language models (LLMs) to generate large numbers of synthetic queries cheaply. The method begins by generating a small number of synthetic queries using an expensive LLM. After that, a much less expensive one is used to create large numbers of synthetic queries, which are used to fine-tune a family of reranker models. These rerankers are then distilled into a single efficient retriever for use in the target domain. We show that this technique boosts zero-shot accuracy in long-tail domains, even where only 2K synthetic queries are used for fine-tuning, and that it achieves substantially lower latency than standard reranking methods. We make our end-to-end approach, including our synthetic datasets and replication code, publicly available on Github.
PrimeQA: The Prime Repository for State-of-the-Art Multilingual Question Answering Research and Development
Jan 25, 2023



The field of Question Answering (QA) has made remarkable progress in recent years, thanks to the advent of large pre-trained language models, newer realistic benchmark datasets with leaderboards, and novel algorithms for key components such as retrievers and readers. In this paper, we introduce PRIMEQA: a one-stop and open-source QA repository with an aim to democratize QA re-search and facilitate easy replication of state-of-the-art (SOTA) QA methods. PRIMEQA supports core QA functionalities like retrieval and reading comprehension as well as auxiliary capabilities such as question generation.It has been designed as an end-to-end toolkit for various use cases: building front-end applications, replicating SOTA methods on pub-lic benchmarks, and expanding pre-existing methods. PRIMEQA is available at : https://github.com/primeqa.
Moving Beyond Downstream Task Accuracy for Information Retrieval Benchmarking
Dec 02, 2022



Neural information retrieval (IR) systems have progressed rapidly in recent years, in large part due to the release of publicly available benchmarking tasks. Unfortunately, some dimensions of this progress are illusory: the majority of the popular IR benchmarks today focus exclusively on downstream task accuracy and thus conceal the costs incurred by systems that trade away efficiency for quality. Latency, hardware cost, and other efficiency considerations are paramount to the deployment of IR systems in user-facing settings. We propose that IR benchmarks structure their evaluation methodology to include not only metrics of accuracy, but also efficiency considerations such as a query latency and the corresponding cost budget for a reproducible hardware setting. For the popular IR benchmarks MS MARCO and XOR-TyDi, we show how the best choice of IR system varies according to how these efficiency considerations are chosen and weighed. We hope that future benchmarks will adopt these guidelines toward more holistic IR evaluation.
SPARTAN: Sparse Hierarchical Memory for Parameter-Efficient Transformers
Nov 29, 2022



Fine-tuning pre-trained language models (PLMs) achieves impressive performance on a range of downstream tasks, and their sizes have consequently been getting bigger. Since a different copy of the model is required for each task, this paradigm is infeasible for storage-constrained edge devices like mobile phones. In this paper, we propose SPARTAN, a parameter efficient (PE) and computationally fast architecture for edge devices that adds hierarchically organized sparse memory after each Transformer layer. SPARTAN freezes the PLM parameters and fine-tunes only its memory, thus significantly reducing storage costs by re-using the PLM backbone for different tasks. SPARTAN contains two levels of memory, with only a sparse subset of parents being chosen in the first level for each input, and children cells corresponding to those parents being used to compute an output representation. This sparsity combined with other architecture optimizations improves SPARTAN's throughput by over 90% during inference on a Raspberry Pi 4 when compared to PE baselines (adapters) while also outperforming the latter by 0.1 points on the GLUE benchmark. Further, it can be trained 34% faster in a few-shot setting, while performing within 0.9 points of adapters. Qualitative analysis shows that different parent cells in SPARTAN specialize in different topics, thus dividing responsibility efficiently.
Zero-Shot Dynamic Quantization for Transformer Inference
Nov 17, 2022


We introduce a novel run-time method for significantly reducing the accuracy loss associated with quantizing BERT-like models to 8-bit integers. Existing methods for quantizing models either modify the training procedure,or they require an additional calibration step to adjust parameters that also requires a selected held-out dataset. Our method permits taking advantage of quantization without the need for these adjustments. We present results on several NLP tasks demonstrating the usefulness of this technique.
GAAMA 2.0: An Integrated System that Answers Boolean and Extractive Questions
Jun 21, 2022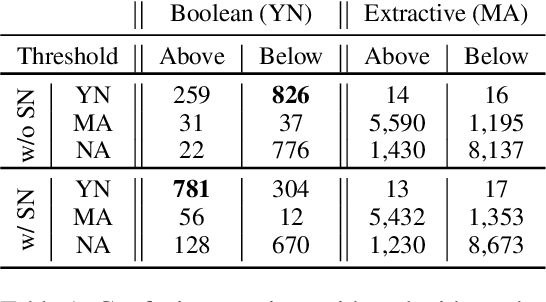
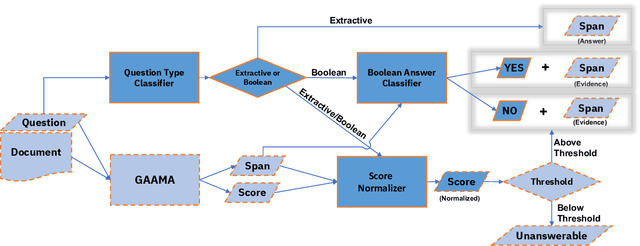


Recent machine reading comprehension datasets include extractive and boolean questions but current approaches do not offer integrated support for answering both question types. We present a multilingual machine reading comprehension system and front-end demo that handles boolean questions by providing both a YES/NO answer and highlighting supporting evidence, and handles extractive questions by highlighting the answer in the passage. Our system, GAAMA 2.0, is ranked first on the Tydi QA leaderboard at the time of this writing. We contrast two different implementations of our approach. The first includes several independent stacks of transformers allowing easy deployment of each component. The second is a single stack of transformers utilizing adapters to reduce GPU memory footprint in a resource-constrained environment.
Task Transfer and Domain Adaptation for Zero-Shot Question Answering
Jun 14, 2022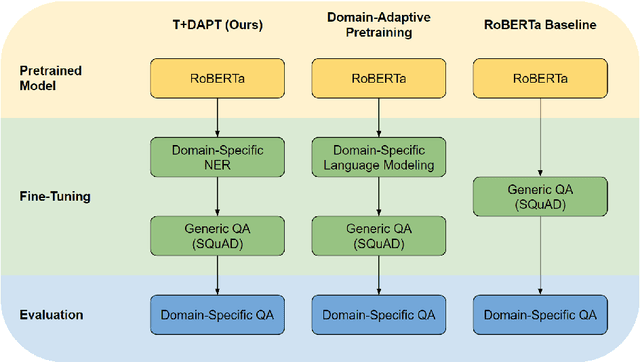

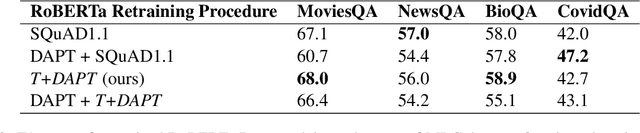

Pretrained language models have shown success in various areas of natural language processing, including reading comprehension tasks. However, when applying machine learning methods to new domains, labeled data may not always be available. To address this, we use supervised pretraining on source-domain data to reduce sample complexity on domain-specific downstream tasks. We evaluate zero-shot performance on domain-specific reading comprehension tasks by combining task transfer with domain adaptation to fine-tune a pretrained model with no labelled data from the target task. Our approach outperforms Domain-Adaptive Pretraining on downstream domain-specific reading comprehension tasks in 3 out of 4 domains.