 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCraftAssist: A Framework for Dialogue-enabled Interactive Agents
Jul 19, 2019
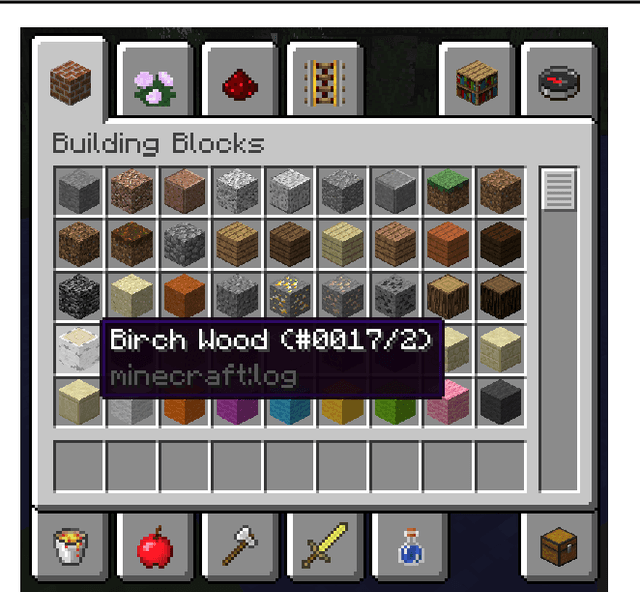
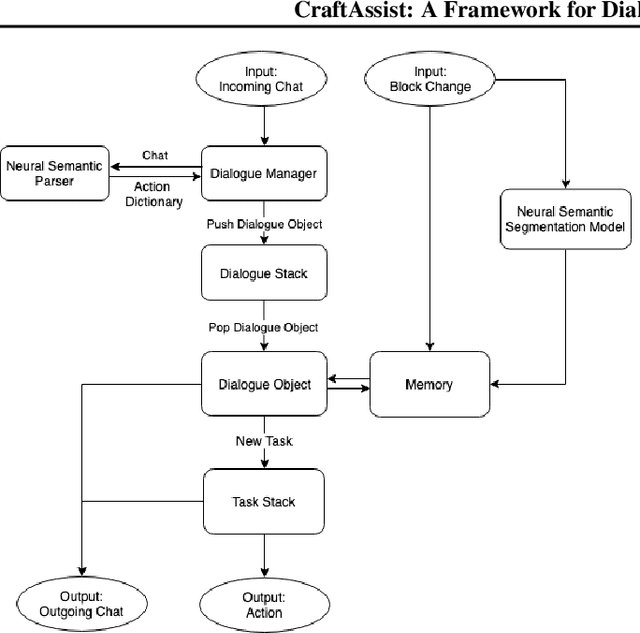
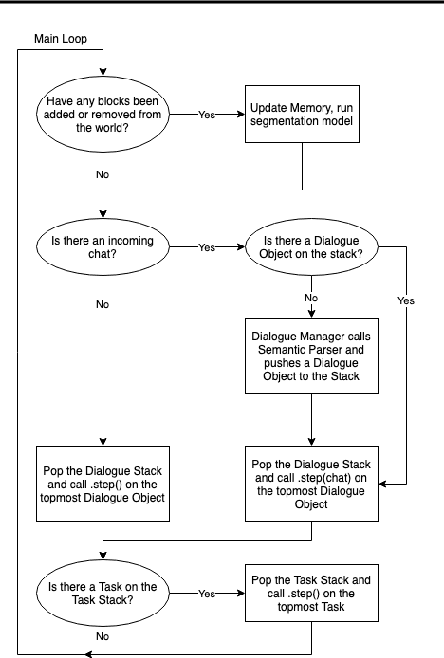
This paper describes an implementation of a bot assistant in Minecraft, and the tools and platform allowing players to interact with the bot and to record those interactions. The purpose of building such an assistant is to facilitate the study of agents that can complete tasks specified by dialogue, and eventually, to learn from dialogue interactions.
Real or Fake? Learning to Discriminate Machine from Human Generated Text
Jun 07, 2019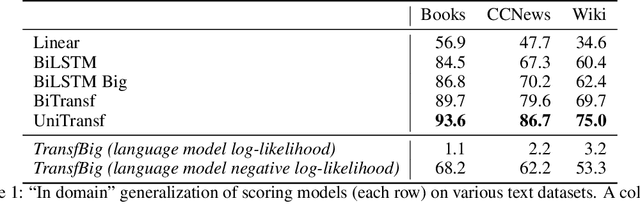
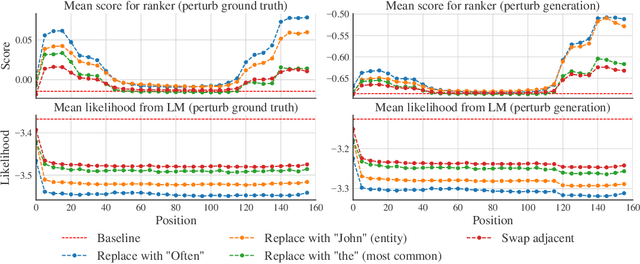
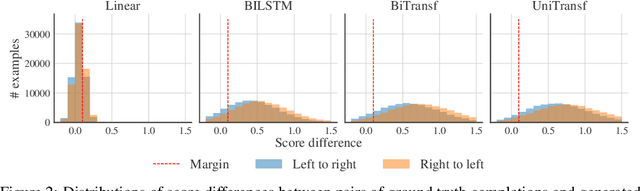
Recent advances in generative modeling of text have demonstrated remarkable improvements in terms of fluency and coherency. In this work we investigate to which extent a machine can discriminate real from machine generated text. This is important in itself for automatic detection of computer generated stories, but can also serve as a tool for further improving text generation. We show that learning a dedicated scoring function to discriminate between real and fake text achieves higher precision than employing the likelihood of a generative model. The scoring functions generalize to other generators than those used for training as long as these generators have comparable model complexity and are trained on similar datasets.
CraftAssist Instruction Parsing: Semantic Parsing for a Minecraft Assistant
Apr 17, 2019
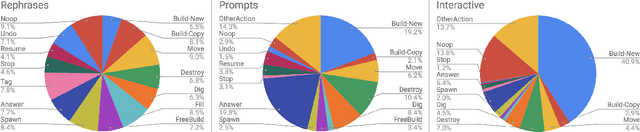
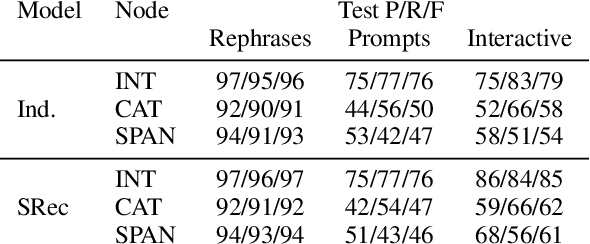
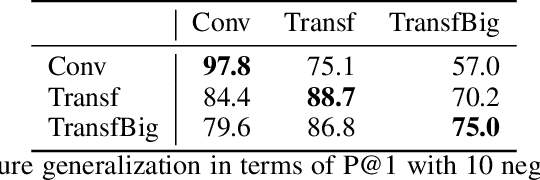
We propose a large scale semantic parsing dataset focused on instruction-driven communication with an agent in Minecraft. We describe the data collection process which yields additional 35K human generated instructions with their semantic annotations. We report the performance of three baseline models and find that while a dataset of this size helps us train a usable instruction parser, it still poses interesting generalization challenges which we hope will help develop better and more robust models.
Learning to Speak and Act in a Fantasy Text Adventure Game
Mar 07, 2019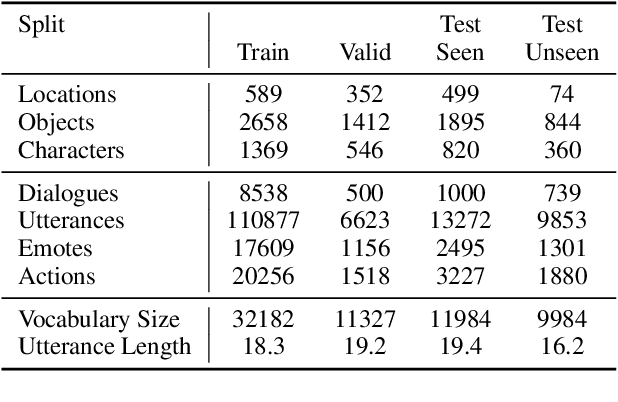
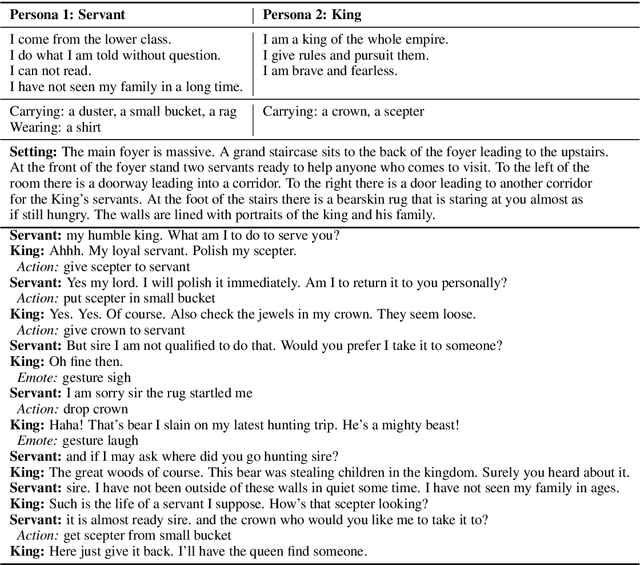
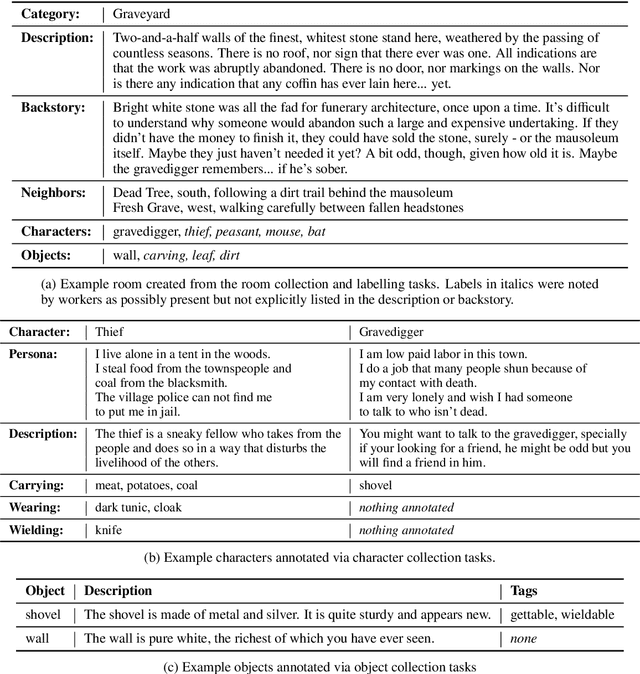

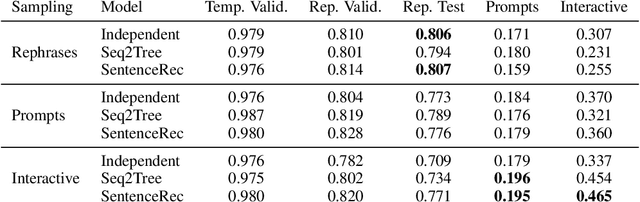
We introduce a large scale crowdsourced text adventure game as a research platform for studying grounded dialogue. In it, agents can perceive, emote, and act whilst conducting dialogue with other agents. Models and humans can both act as characters within the game. We describe the results of training state-of-the-art generative and retrieval models in this setting. We show that in addition to using past dialogue, these models are able to effectively use the state of the underlying world to condition their predictions. In particular, we show that grounding on the details of the local environment, including location descriptions, and the objects (and their affordances) and characters (and their previous actions) present within it allows better predictions of agent behavior and dialogue. We analyze the ingredients necessary for successful grounding in this setting, and how each of these factors relate to agents that can talk and act successfully.
The Second Conversational Intelligence Challenge (ConvAI2)
Jan 31, 2019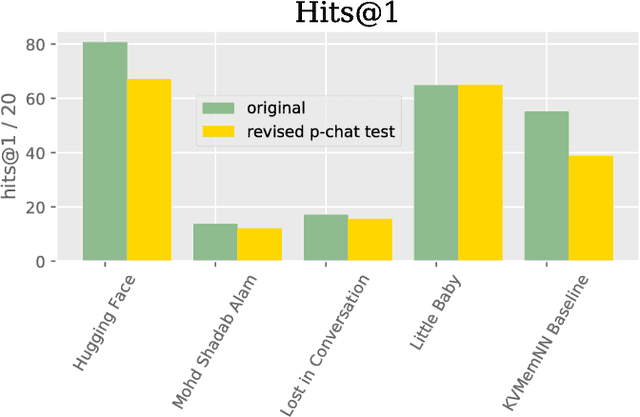

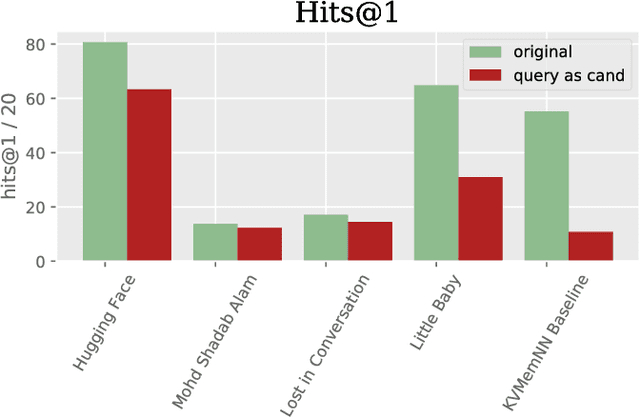
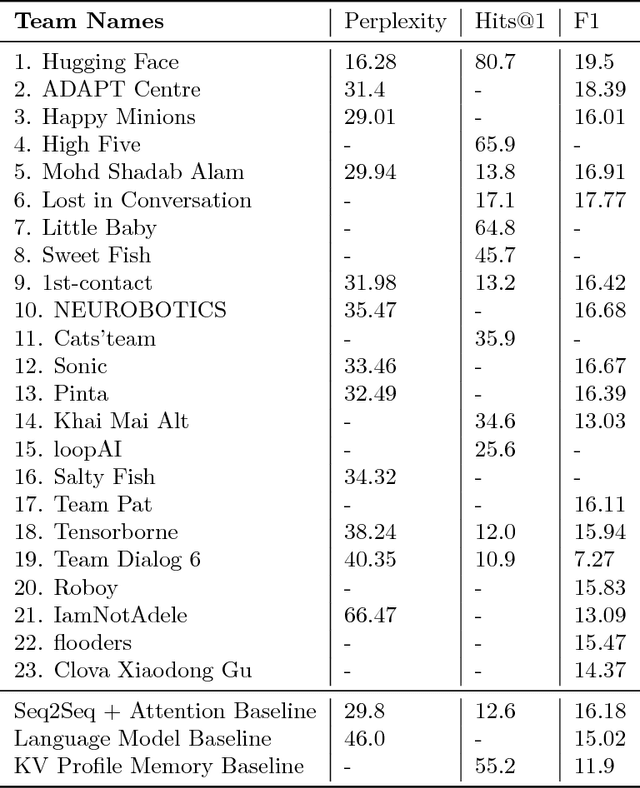
We describe the setting and results of the ConvAI2 NeurIPS competition that aims to further the state-of-the-art in open-domain chatbots. Some key takeaways from the competition are: (i) pretrained Transformer variants are currently the best performing models on this task, (ii) but to improve performance on multi-turn conversations with humans, future systems must go beyond single word metrics like perplexity to measure the performance across sequences of utterances (conversations) -- in terms of repetition, consistency and balance of dialogue acts (e.g. how many questions asked vs. answered).
Learning Goal Embeddings via Self-Play for Hierarchical Reinforcement Learning
Nov 22, 2018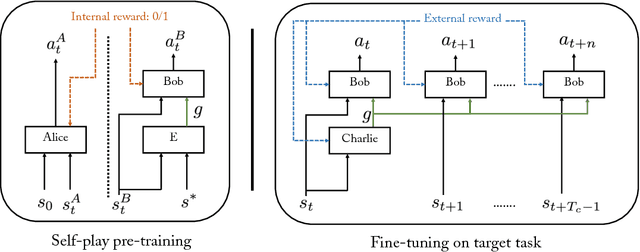
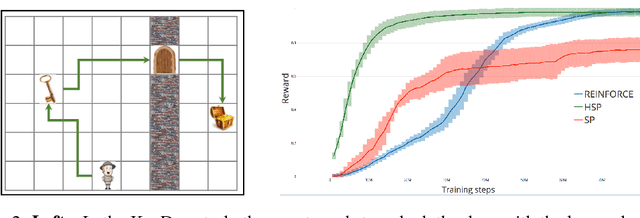
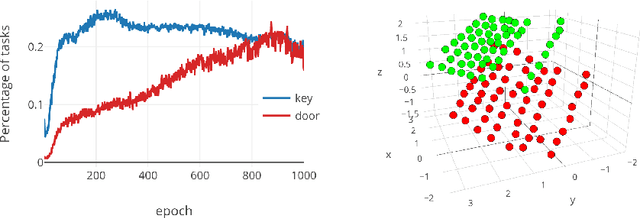
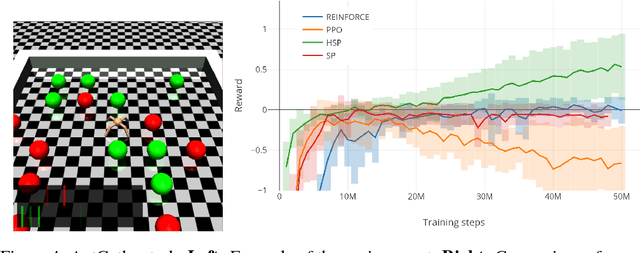
In hierarchical reinforcement learning a major challenge is determining appropriate low-level policies. We propose an unsupervised learning scheme, based on asymmetric self-play from Sukhbaatar et al. (2018), that automatically learns a good representation of sub-goals in the environment and a low-level policy that can execute them. A high-level policy can then direct the lower one by generating a sequence of continuous sub-goal vectors. We evaluate our model using Mazebase and Mujoco environments, including the challenging AntGather task. Visualizations of the sub-goal embeddings reveal a logical decomposition of tasks within the environment. Quantitatively, our approach obtains compelling performance gains over non-hierarchical approaches.
Dialogue Natural Language Inference
Nov 01, 2018
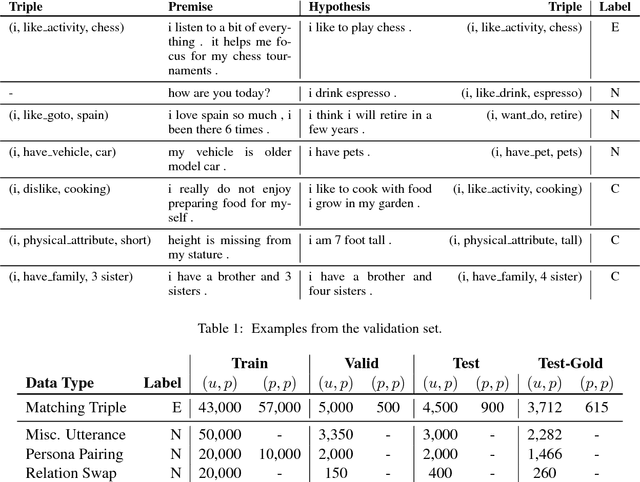
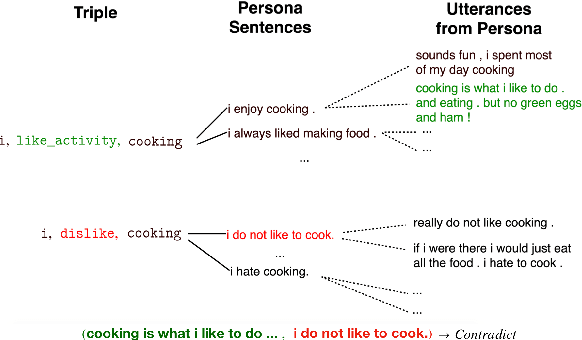
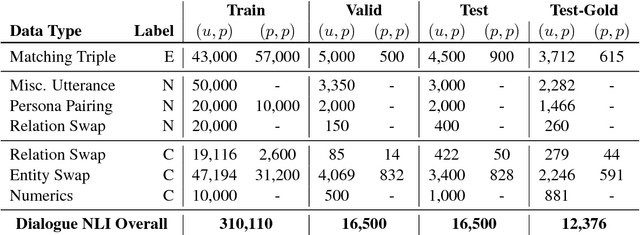
Consistency is a long standing issue faced by dialogue models. In this paper, we frame the consistency of dialogue agents as natural language inference (NLI) and create a new natural language inference dataset called Dialogue NLI. We propose a method which demonstrates that a model trained on Dialogue NLI can be used to improve the consistency of a dialogue model, and evaluate the method with human evaluation and with automatic metrics on a suite of evaluation sets designed to measure a dialogue model's consistency.
Lightweight Adaptive Mixture of Neural and N-gram Language Models
Oct 26, 2018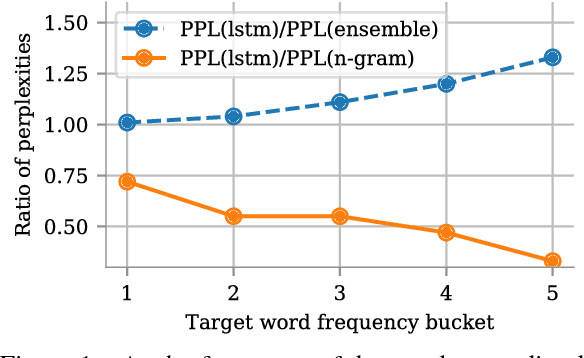

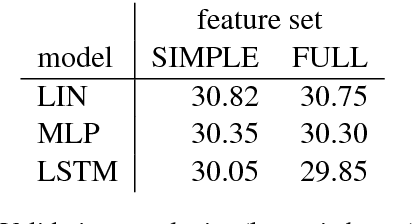
It is often the case that the best performing language model is an ensemble of a neural language model with n-grams. In this work, we propose a method to improve how these two models are combined. By using a small network which predicts the mixture weight between the two models, we adapt their relative importance at each time step. Because the gating network is small, it trains quickly on small amounts of held out data, and does not add overhead at scoring time. Our experiments carried out on the One Billion Word benchmark show a significant improvement over the state of the art ensemble without retraining of the basic modules.
Personalizing Dialogue Agents: I have a dog, do you have pets too?
Sep 25, 2018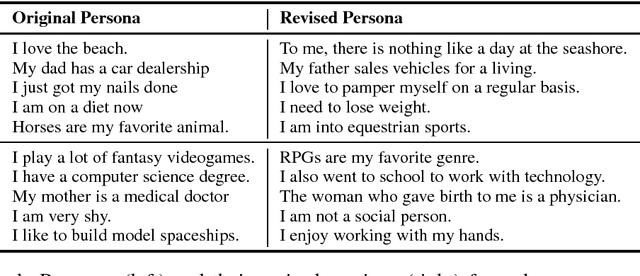

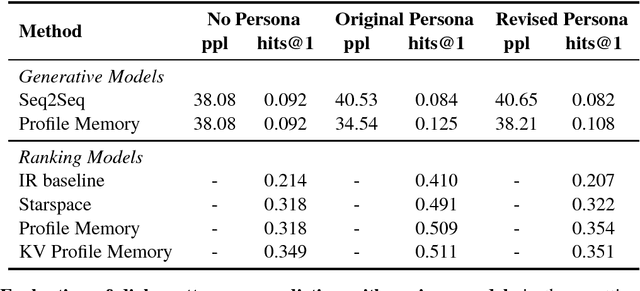
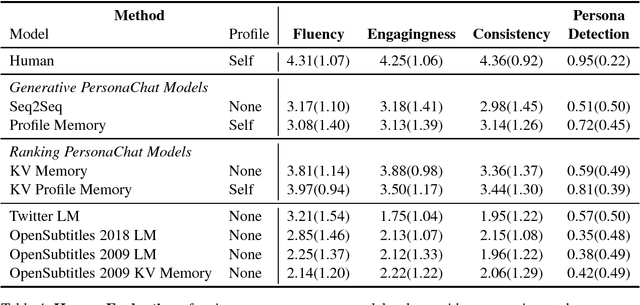
Chit-chat models are known to have several problems: they lack specificity, do not display a consistent personality and are often not very captivating. In this work we present the task of making chit-chat more engaging by conditioning on profile information. We collect data and train models to (i) condition on their given profile information; and (ii) information about the person they are talking to, resulting in improved dialogues, as measured by next utterance prediction. Since (ii) is initially unknown our model is trained to engage its partner with personal topics, and we show the resulting dialogue can be used to predict profile information about the interlocutors.
Planning with Arithmetic and Geometric Attributes
Sep 06, 2018



A desirable property of an intelligent agent is its ability to understand its environment to quickly generalize to novel tasks and compose simpler tasks into more complex ones. If the environment has geometric or arithmetic structure, the agent should exploit these for faster generalization. Building on recent work that augments the environment with user-specified attributes, we show that further equipping these attributes with the appropriate geometric and arithmetic structure brings substantial gains in sample complexity.