 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoxtral TTS
Mar 26, 2026We introduce Voxtral TTS, an expressive multilingual text-to-speech model that generates natural speech from as little as 3 seconds of reference audio. Voxtral TTS adopts a hybrid architecture that combines auto-regressive generation of semantic speech tokens with flow-matching for acoustic tokens. These tokens are encoded and decoded with Voxtral Codec, a speech tokenizer trained from scratch with a hybrid VQ-FSQ quantization scheme. In human evaluations conducted by native speakers, Voxtral TTS is preferred for multilingual voice cloning due to its naturalness and expressivity, achieving a 68.4\% win rate over ElevenLabs Flash v2.5. We release the model weights under a CC BY-NC license.
Voxtral Realtime
Feb 11, 2026We introduce Voxtral Realtime, a natively streaming automatic speech recognition model that matches offline transcription quality at sub-second latency. Unlike approaches that adapt offline models through chunking or sliding windows, Voxtral Realtime is trained end-to-end for streaming, with explicit alignment between audio and text streams. Our architecture builds on the Delayed Streams Modeling framework, introducing a new causal audio encoder and Ada RMS-Norm for improved delay conditioning. We scale pretraining to a large-scale dataset spanning 13 languages. At a delay of 480ms, Voxtral Realtime achieves performance on par with Whisper, the most widely deployed offline transcription system. We release the model weights under the Apache 2.0 license.
Build it Break it Fix it for Dialogue Safety: Robustness from Adversarial Human Attack
Aug 17, 2019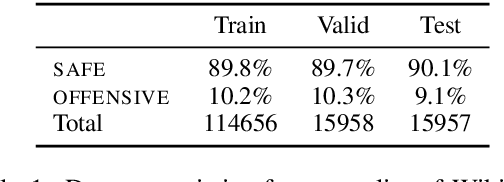
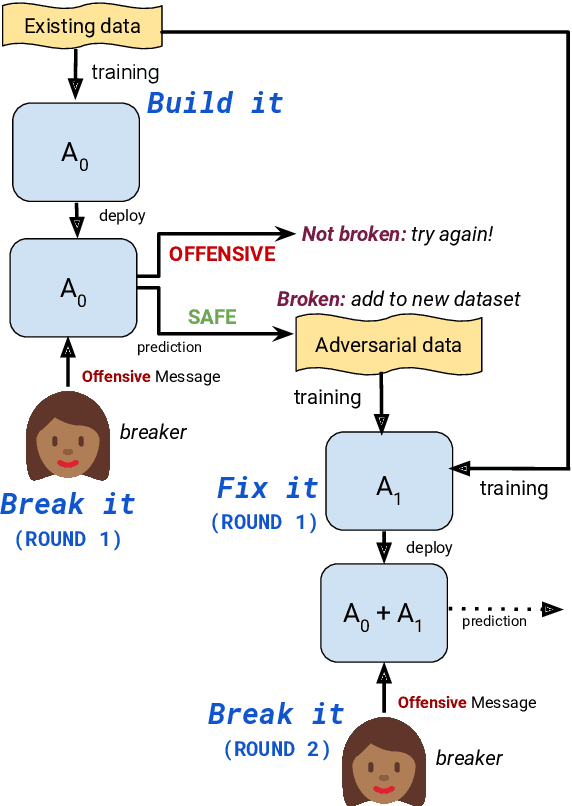


The detection of offensive language in the context of a dialogue has become an increasingly important application of natural language processing. The detection of trolls in public forums (Gal\'an-Garc\'ia et al., 2016), and the deployment of chatbots in the public domain (Wolf et al., 2017) are two examples that show the necessity of guarding against adversarially offensive behavior on the part of humans. In this work, we develop a training scheme for a model to become robust to such human attacks by an iterative build it, break it, fix it strategy with humans and models in the loop. In detailed experiments we show this approach is considerably more robust than previous systems. Further, we show that offensive language used within a conversation critically depends on the dialogue context, and cannot be viewed as a single sentence offensive detection task as in most previous work. Our newly collected tasks and methods will be made open source and publicly available.
Real-time Inference in Multi-sentence Tasks with Deep Pretrained Transformers
Apr 22, 2019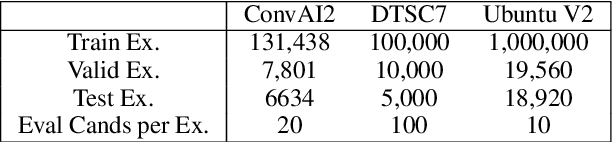
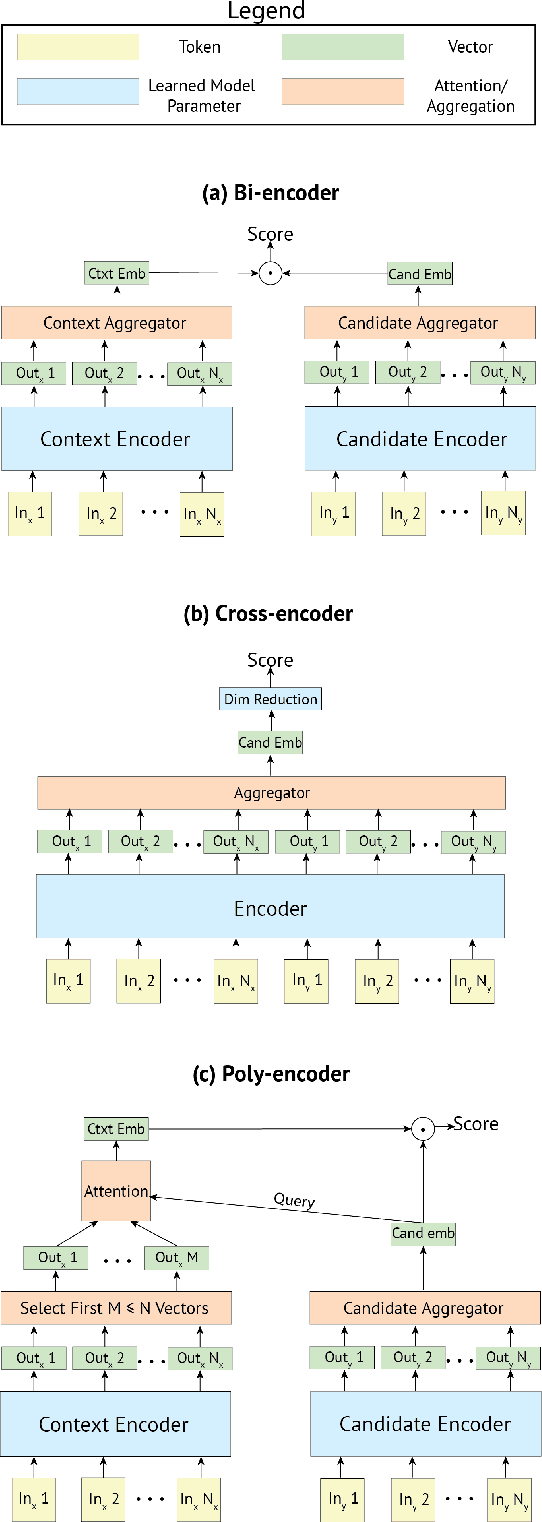

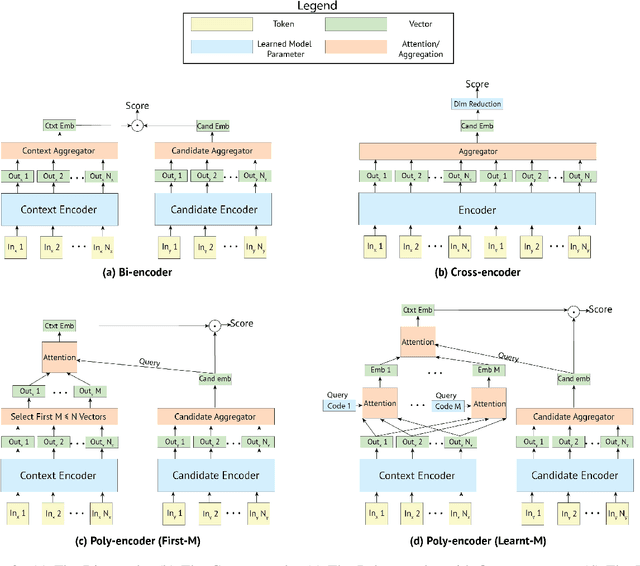
The use of deep pretrained bidirectional transformers has led to remarkable progress in learning multi-sentence representations for downstream language understanding tasks (Devlin et al., 2018). For tasks that make pairwise comparisons, e.g. matching a given context with a corresponding response, two approaches have permeated the literature. A Cross-encoder performs full self-attention over the pair; a Bi-encoder performs self-attention for each sequence separately, and the final representation is a function of the pair. While Cross-encoders nearly always outperform Bi-encoders on various tasks, both in our work and others' (Urbanek et al., 2019), they are orders of magnitude slower, which hampers their ability to perform real-time inference. In this work, we develop a new architecture, the Poly-encoder, that is designed to approach the performance of the Cross-encoder while maintaining reasonable computation time. Additionally, we explore two pretraining schemes with different datasets to determine how these affect the performance on our chosen dialogue tasks: ConvAI2 and DSTC7 Track 1. We show that our models achieve state-of-the-art results on both tasks; that the Poly-encoder is a suitable replacement for Bi-encoders and Cross-encoders; and that even better results can be obtained by pretraining on a large dialogue dataset.
Learning to Speak and Act in a Fantasy Text Adventure Game
Mar 07, 2019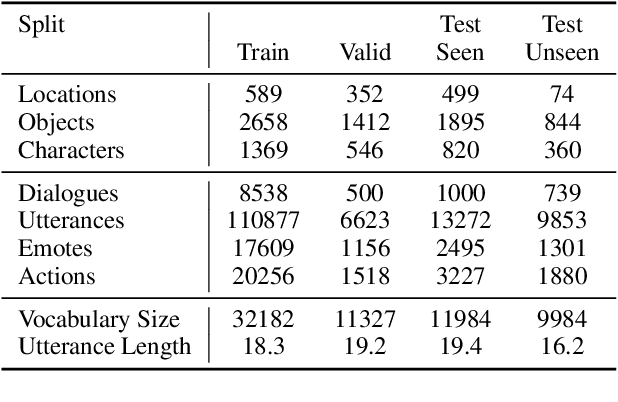
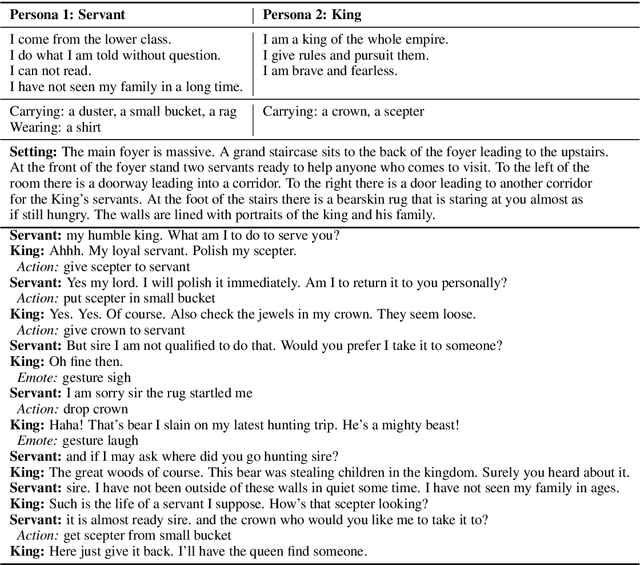
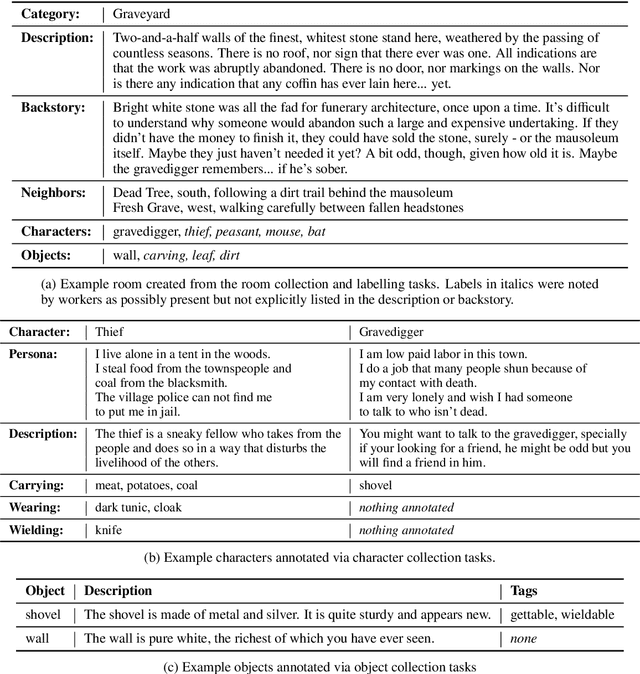

We introduce a large scale crowdsourced text adventure game as a research platform for studying grounded dialogue. In it, agents can perceive, emote, and act whilst conducting dialogue with other agents. Models and humans can both act as characters within the game. We describe the results of training state-of-the-art generative and retrieval models in this setting. We show that in addition to using past dialogue, these models are able to effectively use the state of the underlying world to condition their predictions. In particular, we show that grounding on the details of the local environment, including location descriptions, and the objects (and their affordances) and characters (and their previous actions) present within it allows better predictions of agent behavior and dialogue. We analyze the ingredients necessary for successful grounding in this setting, and how each of these factors relate to agents that can talk and act successfully.
Reference-less Quality Estimation of Text Simplification Systems
Jan 30, 2019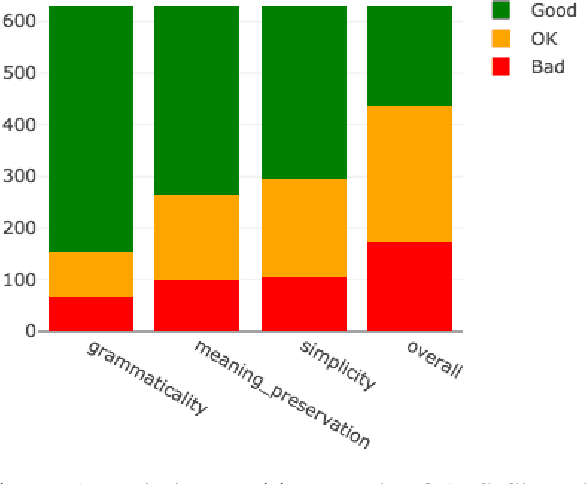
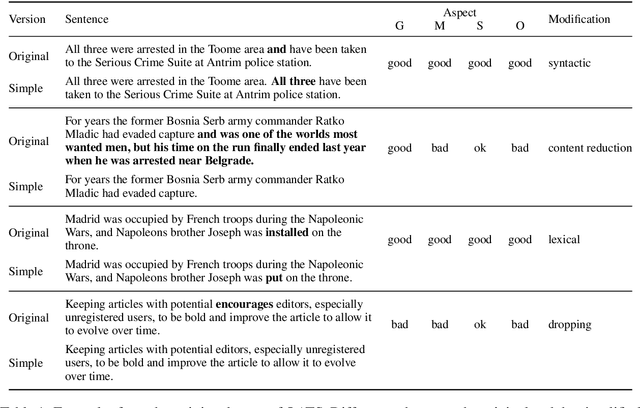
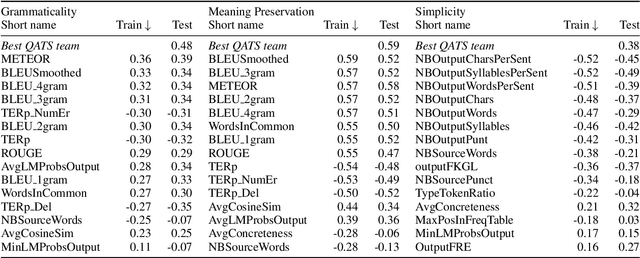
The evaluation of text simplification (TS) systems remains an open challenge. As the task has common points with machine translation (MT), TS is often evaluated using MT metrics such as BLEU. However, such metrics require high quality reference data, which is rarely available for TS. TS has the advantage over MT of being a monolingual task, which allows for direct comparisons to be made between the simplified text and its original version. In this paper, we compare multiple approaches to reference-less quality estimation of sentence-level text simplification systems, based on the dataset used for the QATS 2016 shared task. We distinguish three different dimensions: gram-maticality, meaning preservation and simplicity. We show that n-gram-based MT metrics such as BLEU and METEOR correlate the most with human judgment of grammaticality and meaning preservation, whereas simplicity is best evaluated by basic length-based metrics.
Engaging Image Chat: Modeling Personality in Grounded Dialogue
Nov 02, 2018
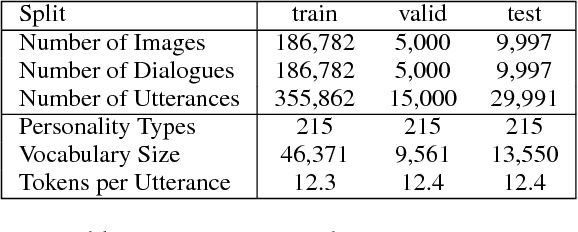
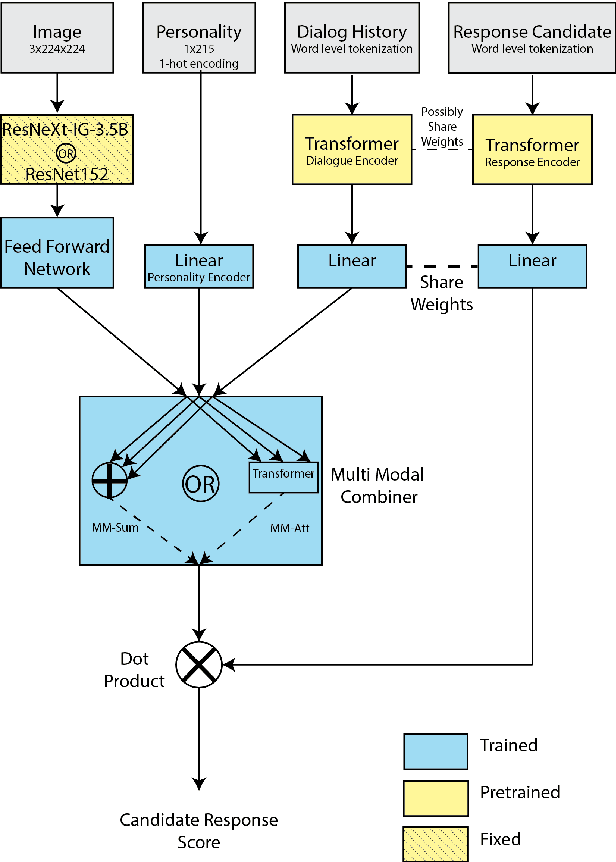

To achieve the long-term goal of machines being able to engage humans in conversation, our models should be engaging. We focus on communication grounded in images, whereby a dialogue is conducted based on a given photo, a setup that is naturally engaging to humans (Hu et al., 2014). We collect a large dataset of grounded human-human conversations, where humans are asked to play the role of a given personality, as the use of personality in conversation has also been shown to be engaging (Shuster et al., 2018). Our dataset, Image-Chat, consists of 202k dialogues and 401k utterances over 202k images using 215 possible personality traits. We then design a set of natural architectures using state-of-the-art image and text representations, considering various ways to fuse the components. Automatic metrics and human evaluations show the efficacy of approach, in particular where our best performing model is preferred over human conversationalists 47.7% of the time
Engaging Image Captioning Via Personality
Oct 25, 2018
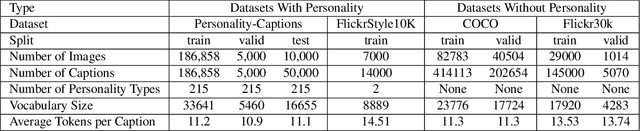
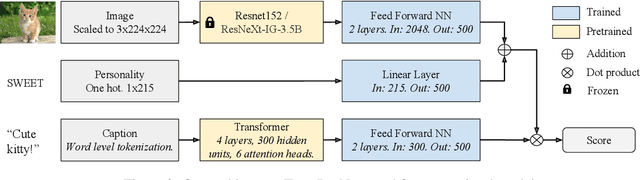
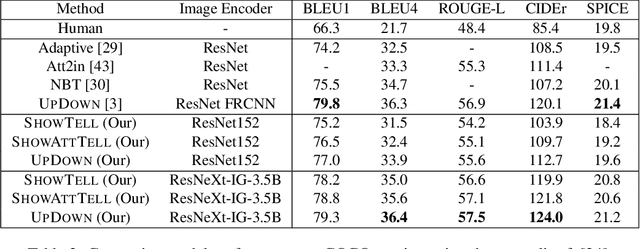
Standard image captioning tasks such as COCO and Flickr30k are factual, neutral in tone and (to a human) state the obvious (e.g., "a man playing a guitar"). While such tasks are useful to verify that a machine understands the content of an image, they are not engaging to humans as captions. With this in mind we define a new task, Personality-Captions, where the goal is to be as engaging to humans as possible by incorporating controllable style and personality traits. We collect and release a large dataset of 201,858 of such captions conditioned over 215 possible traits. We build models that combine existing work from (i) sentence representations (Mazare et al., 2018) with Transformers trained on 1.7 billion dialogue examples; and (ii) image representations (Mahajan et al., 2018) with ResNets trained on 3.5 billion social media images. We obtain state-of-the-art performance on Flickr30k and COCO, and strong performance on our new task. Finally, online evaluations validate that our task and models are engaging to humans, with our best model close to human performance.
Training Millions of Personalized Dialogue Agents
Sep 06, 2018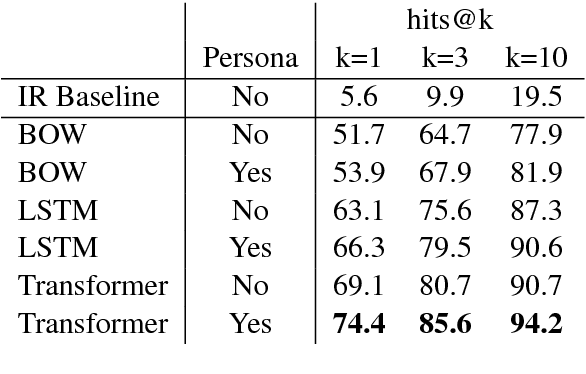
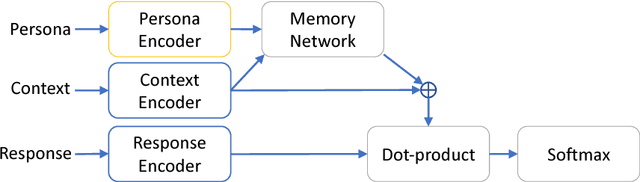
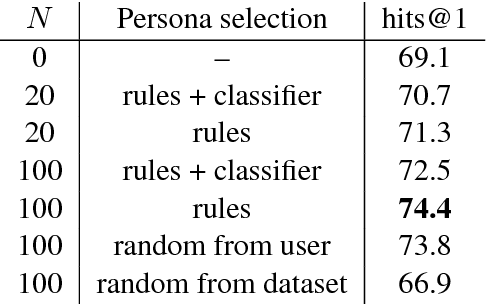
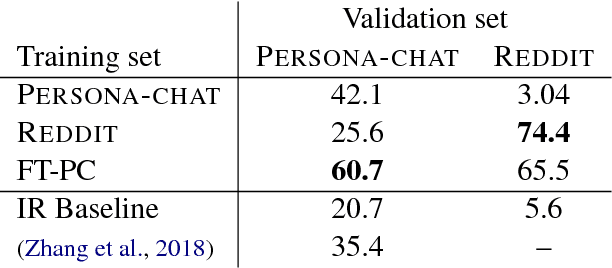
Current dialogue systems are not very engaging for users, especially when trained end-to-end without relying on proactive reengaging scripted strategies. Zhang et al. (2018) showed that the engagement level of end-to-end dialogue models increases when conditioning them on text personas providing some personalized back-story to the model. However, the dataset used in Zhang et al. (2018) is synthetic and of limited size as it contains around 1k different personas. In this paper we introduce a new dataset providing 5 million personas and 700 million persona-based dialogues. Our experiments show that, at this scale, training using personas still improves the performance of end-to-end systems. In addition, we show that other tasks benefit from the wide coverage of our dataset by fine-tuning our model on the data from Zhang et al. (2018) and achieving state-of-the-art results.
Multimodal Attribute Extraction
Nov 29, 2017
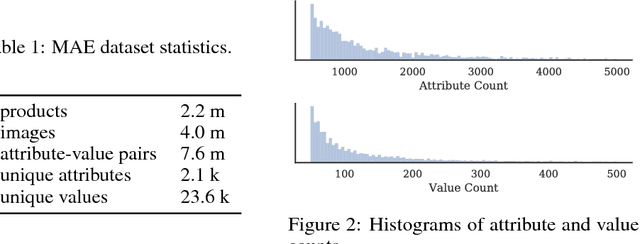
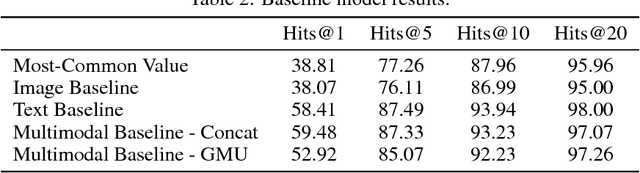
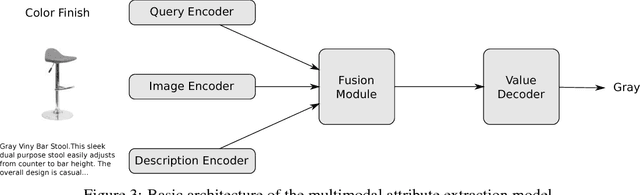
The broad goal of information extraction is to derive structured information from unstructured data. However, most existing methods focus solely on text, ignoring other types of unstructured data such as images, video and audio which comprise an increasing portion of the information on the web. To address this shortcoming, we propose the task of multimodal attribute extraction. Given a collection of unstructured and semi-structured contextual information about an entity (such as a textual description, or visual depictions) the task is to extract the entity's underlying attributes. In this paper, we provide a dataset containing mixed-media data for over 2 million product items along with 7 million attribute-value pairs describing the items which can be used to train attribute extractors in a weakly supervised manner. We provide a variety of baselines which demonstrate the relative effectiveness of the individual modes of information towards solving the task, as well as study human performance.