 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Robustness Limits of SoTA Vision Models to Natural Variation
Oct 24, 2022Recent state-of-the-art vision models introduced new architectures, learning paradigms, and larger pretraining data, leading to impressive performance on tasks such as classification. While previous generations of vision models were shown to lack robustness to factors such as pose, it's unclear the extent to which this next generation of models are more robust. To study this question, we develop a dataset of more than 7 million images with controlled changes in pose, position, background, lighting, and size. We study not only how robust recent state-of-the-art models are, but also the extent to which models can generalize variation in factors when they're present during training. We consider a catalog of recent vision models, including vision transformers (ViT), self-supervised models such as masked autoencoders (MAE), and models trained on larger datasets such as CLIP. We find out-of-the-box, even today's best models are not robust to common changes in pose, size, and background. When some samples varied during training, we found models required a significant portion of diversity to generalize -- though eventually robustness did improve. When diversity is only seen for some classes however, we found models did not generalize to other classes, unless the classes were very similar to those seen varying during training. We hope our work will shed further light on the blind spots of SoTA models and spur the development of more robust vision models.
Trade-offs of Local SGD at Scale: An Empirical Study
Oct 15, 2021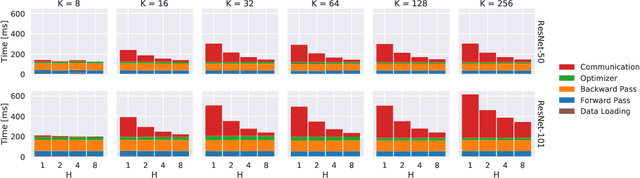
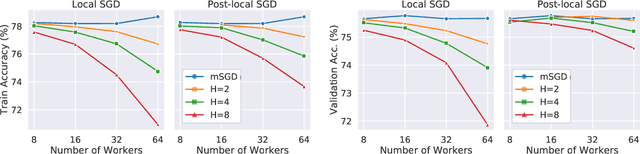
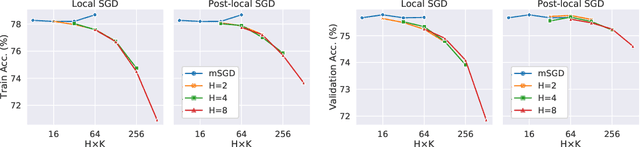
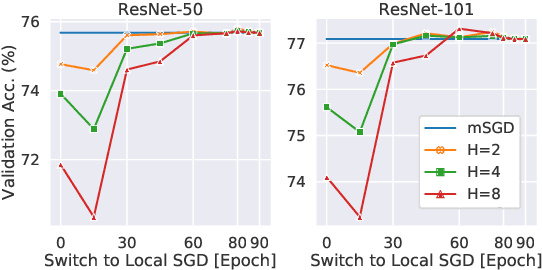
As datasets and models become increasingly large, distributed training has become a necessary component to allow deep neural networks to train in reasonable amounts of time. However, distributed training can have substantial communication overhead that hinders its scalability. One strategy for reducing this overhead is to perform multiple unsynchronized SGD steps independently on each worker between synchronization steps, a technique known as local SGD. We conduct a comprehensive empirical study of local SGD and related methods on a large-scale image classification task. We find that performing local SGD comes at a price: lower communication costs (and thereby faster training) are accompanied by lower accuracy. This finding is in contrast from the smaller-scale experiments in prior work, suggesting that local SGD encounters challenges at scale. We further show that incorporating the slow momentum framework of Wang et al. (2020) consistently improves accuracy without requiring additional communication, hinting at future directions for potentially escaping this trade-off.
Transformed CNNs: recasting pre-trained convolutional layers with self-attention
Jun 10, 2021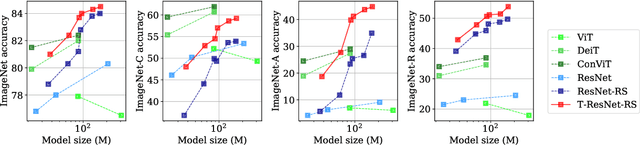
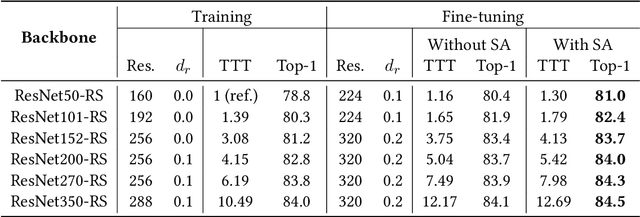
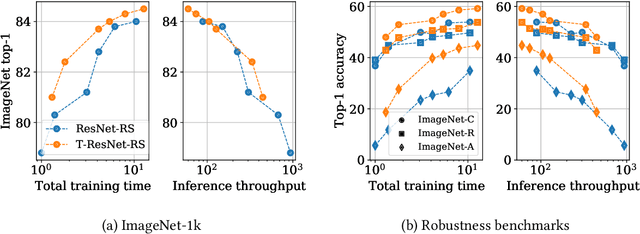
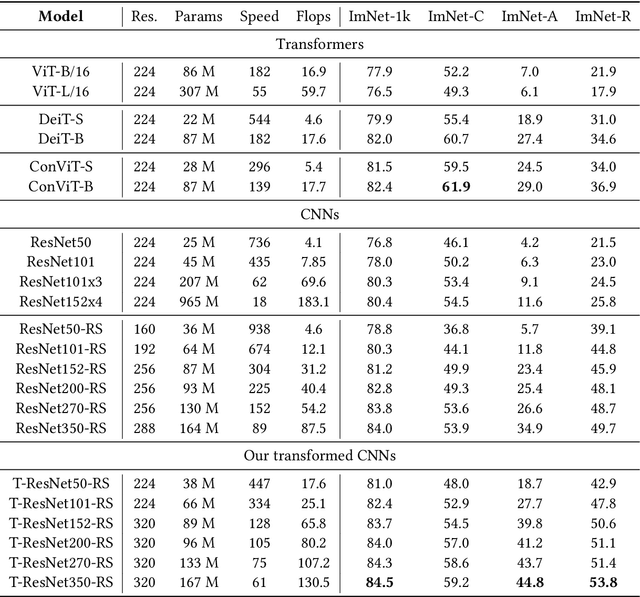
Vision Transformers (ViT) have recently emerged as a powerful alternative to convolutional networks (CNNs). Although hybrid models attempt to bridge the gap between these two architectures, the self-attention layers they rely on induce a strong computational bottleneck, especially at large spatial resolutions. In this work, we explore the idea of reducing the time spent training these layers by initializing them as convolutional layers. This enables us to transition smoothly from any pre-trained CNN to its functionally identical hybrid model, called Transformed CNN (T-CNN). With only 50 epochs of fine-tuning, the resulting T-CNNs demonstrate significant performance gains over the CNN (+2.2% top-1 on ImageNet-1k for a ResNet50-RS) as well as substantially improved robustness (+11% top-1 on ImageNet-C). We analyze the representations learnt by the T-CNN, providing deeper insights into the fruitful interplay between convolutions and self-attention. Finally, we experiment initializing the T-CNN from a partially trained CNN, and find that it reaches better performance than the corresponding hybrid model trained from scratch, while reducing training time.
ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases
Mar 19, 2021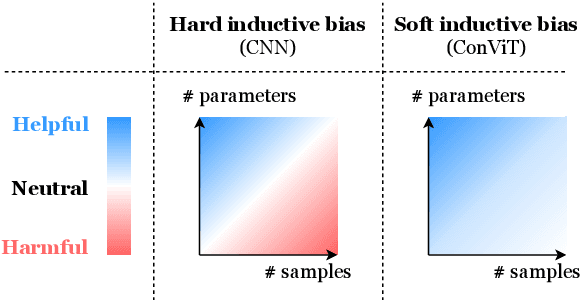
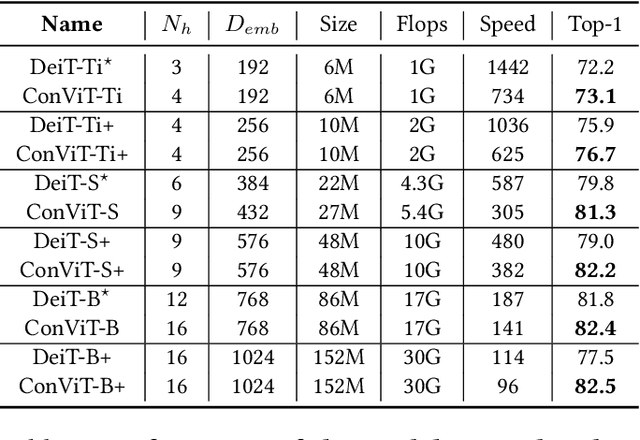
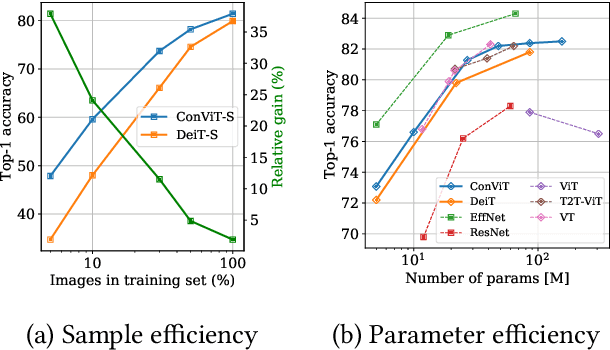
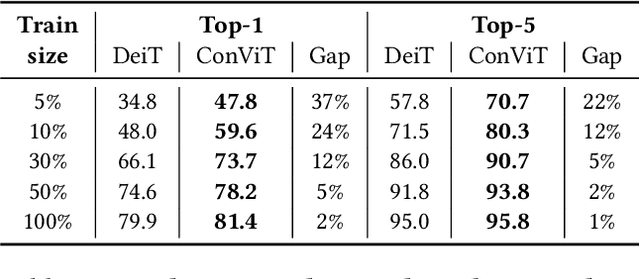
Convolutional architectures have proven extremely successful for vision tasks. Their hard inductive biases enable sample-efficient learning, but come at the cost of a potentially lower performance ceiling. Vision Transformers (ViTs) rely on more flexible self-attention layers, and have recently outperformed CNNs for image classification. However, they require costly pre-training on large external datasets or distillation from pre-trained convolutional networks. In this paper, we ask the following question: is it possible to combine the strengths of these two architectures while avoiding their respective limitations? To this end, we introduce gated positional self-attention (GPSA), a form of positional self-attention which can be equipped with a "soft" convolutional inductive bias. We initialize the GPSA layers to mimic the locality of convolutional layers, then give each attention head the freedom to escape locality by adjusting a gating parameter regulating the attention paid to position versus content information. The resulting convolutional-like ViT architecture, ConViT, outperforms the DeiT on ImageNet, while offering a much improved sample efficiency. We further investigate the role of locality in learning by first quantifying how it is encouraged in vanilla self-attention layers, then analyzing how it is escaped in GPSA layers. We conclude by presenting various ablations to better understand the success of the ConViT. Our code and models are released publicly.
Towards falsifiable interpretability research
Oct 22, 2020Methods for understanding the decisions of and mechanisms underlying deep neural networks (DNNs) typically rely on building intuition by emphasizing sensory or semantic features of individual examples. For instance, methods aim to visualize the components of an input which are "important" to a network's decision, or to measure the semantic properties of single neurons. Here, we argue that interpretability research suffers from an over-reliance on intuition-based approaches that risk-and in some cases have caused-illusory progress and misleading conclusions. We identify a set of limitations that we argue impede meaningful progress in interpretability research, and examine two popular classes of interpretability methods-saliency and single-neuron-based approaches-that serve as case studies for how overreliance on intuition and lack of falsifiability can undermine interpretability research. To address these concerns, we propose a strategy to address these impediments in the form of a framework for strongly falsifiable interpretability research. We encourage researchers to use their intuitions as a starting point to develop and test clear, falsifiable hypotheses, and hope that our framework yields robust, evidence-based interpretability methods that generate meaningful advances in our understanding of DNNs.
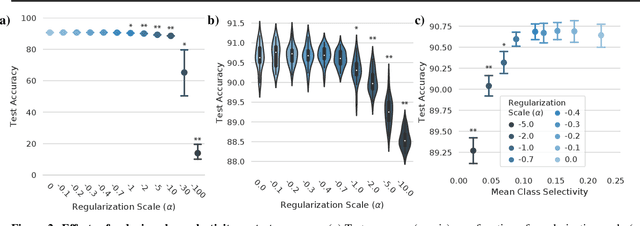
Linking average- and worst-case perturbation robustness via class selectivity and dimensionality
Oct 14, 2020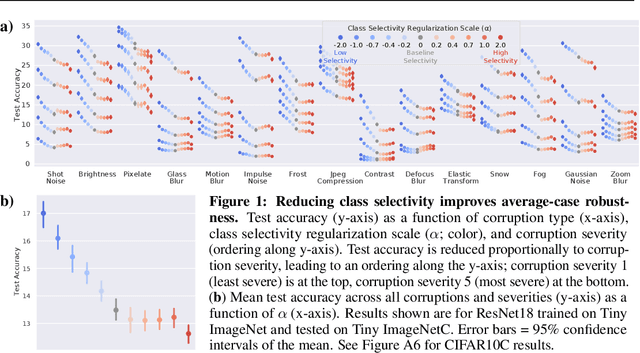
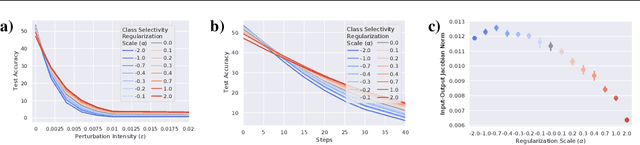
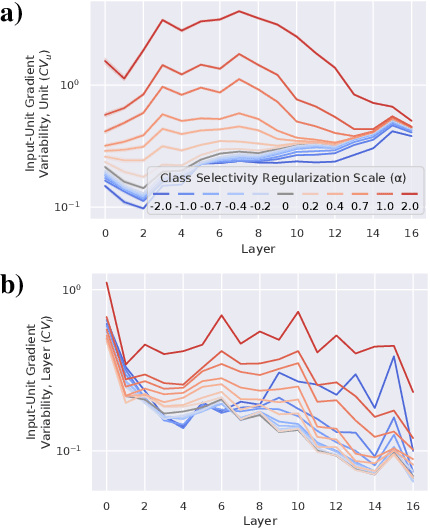
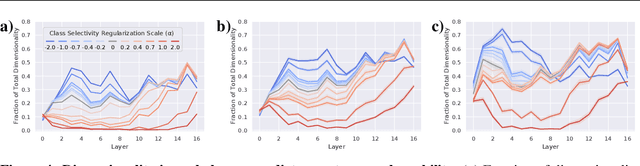
Representational sparsity is known to affect robustness to input perturbations in deep neural networks (DNNs), but less is known about how the semantic content of representations affects robustness. Class selectivity-the variability of a unit's responses across data classes or dimensions-is one way of quantifying the sparsity of semantic representations. Given recent evidence that class selectivity may not be necessary for, and can even impair generalization, we investigated whether it also confers robustness (or vulnerability) to perturbations of input data. We found that class selectivity leads to increased vulnerability to average-case (naturalistic) perturbations in ResNet18 and ResNet20, as measured using Tiny ImageNetC and CIFAR10C, respectively. Networks regularized to have lower levels of class selectivity are more robust to average-case perturbations, while networks with higher class selectivity are more vulnerable. In contrast, we found that class selectivity increases robustness to worst-case (i.e. white box adversarial) perturbations, suggesting that while decreasing class selectivity is helpful for average-case robustness, it is harmful for worst-case robustness. To explain this difference, we studied the dimensionality of the networks' representations: we found that the dimensionality of early-layer representations is inversely proportional to a network's class selectivity, and that adversarial samples cause a larger increase in early-layer dimensionality than corrupted samples. We also found that the input-unit gradient was more variable across samples and units in high-selectivity networks compared to low-selectivity networks. These results lead to the conclusion that units participate more consistently in low-selectivity regimes compared to high-selectivity regimes, effectively creating a larger attack surface and hence vulnerability to worst-case perturbations.
CURI: A Benchmark for Productive Concept Learning Under Uncertainty
Oct 06, 2020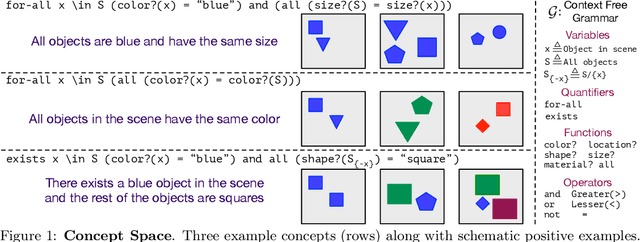
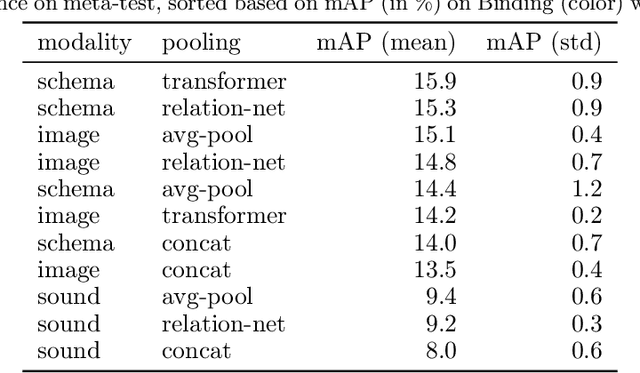
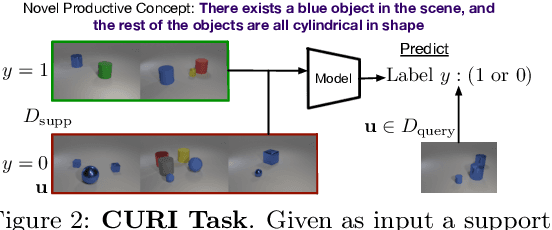
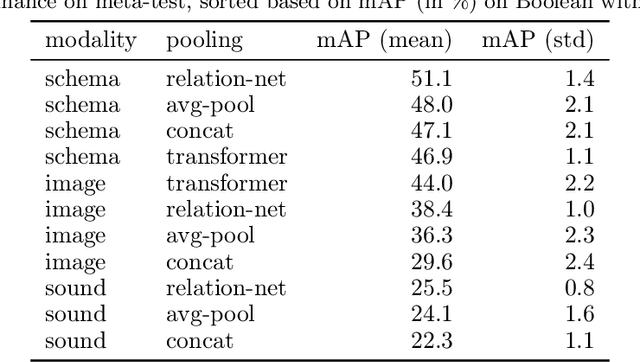
Humans can learn and reason under substantial uncertainty in a space of infinitely many concepts, including structured relational concepts ("a scene with objects that have the same color") and ad-hoc categories defined through goals ("objects that could fall on one's head"). In contrast, standard classification benchmarks: 1) consider only a fixed set of category labels, 2) do not evaluate compositional concept learning and 3) do not explicitly capture a notion of reasoning under uncertainty. We introduce a new few-shot, meta-learning benchmark, Compositional Reasoning Under Uncertainty (CURI) to bridge this gap. CURI evaluates different aspects of productive and systematic generalization, including abstract understandings of disentangling, productive generalization, learning boolean operations, variable binding, etc. Importantly, it also defines a model-independent "compositionality gap" to evaluate the difficulty of generalizing out-of-distribution along each of these axes. Extensive evaluations across a range of modeling choices spanning different modalities (image, schemas, and sounds), splits, privileged auxiliary concept information, and choices of negatives reveal substantial scope for modeling advances on the proposed task. All code and datasets will be available online.
Analyzing Visual Representations in Embodied Navigation Tasks
Mar 12, 2020
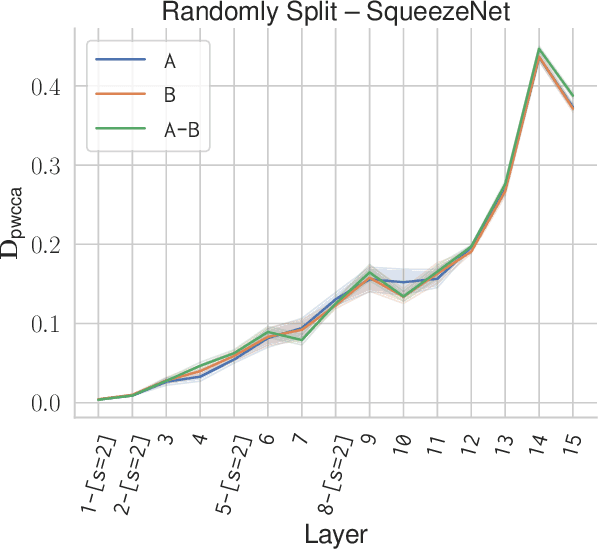
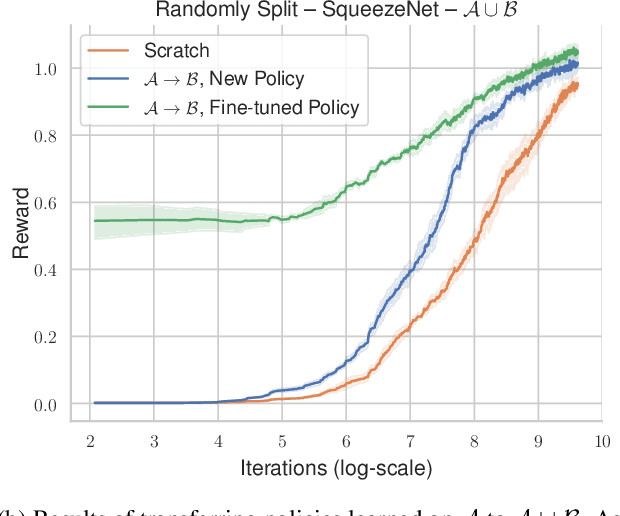
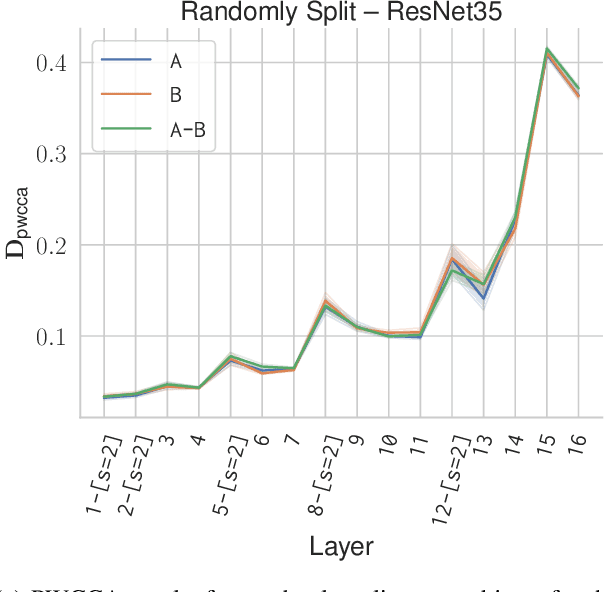
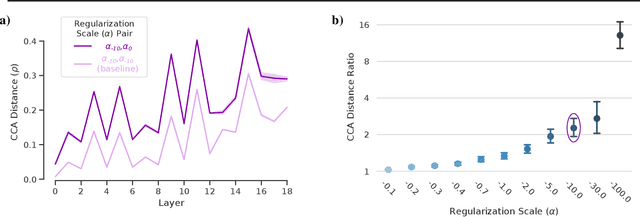
Recent advances in deep reinforcement learning require a large amount of training data and generally result in representations that are often over specialized to the target task. In this work, we present a methodology to study the underlying potential causes for this specialization. We use the recently proposed projection weighted Canonical Correlation Analysis (PWCCA) to measure the similarity of visual representations learned in the same environment by performing different tasks. We then leverage our proposed methodology to examine the task dependence of visual representations learned on related but distinct embodied navigation tasks. Surprisingly, we find that slight differences in task have no measurable effect on the visual representation for both SqueezeNet and ResNet architectures. We then empirically demonstrate that visual representations learned on one task can be effectively transferred to a different task.
Selectivity considered harmful: evaluating the causal impact of class selectivity in DNNs
Mar 03, 2020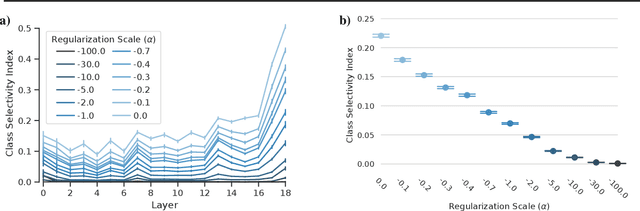
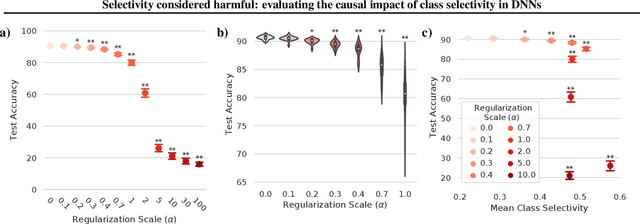
Class selectivity, typically defined as how different a neuron's responses are across different classes of stimuli or data samples, is a common metric used to interpret the function of individual neurons in biological and artificial neural networks. However, it remains an open question whether it is necessary and/or sufficient for deep neural networks (DNNs) to learn class selectivity in individual units. In order to investigate the causal impact of class selectivity on network function, we directly regularize for or against class selectivity. Using this regularizer, we were able to reduce mean class selectivity across units in convolutional neural networks by a factor of 2.5 with no impact on test accuracy, and reduce it nearly to zero with only a small ($\sim$2%) change in test accuracy. In contrast, increasing class selectivity beyond the levels naturally learned during training had rapid and disastrous effects on test accuracy. These results indicate that class selectivity in individual units is neither neither sufficient nor strictly necessary for DNN performance, and more generally encourage caution when focusing on the properties of single units as representative of the mechanisms by which DNNs function.
Representation Learning Through Latent Canonicalizations
Feb 26, 2020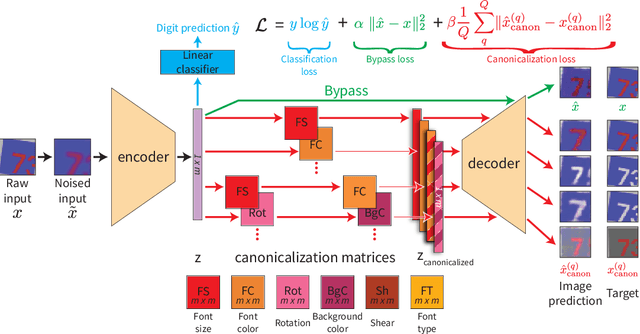
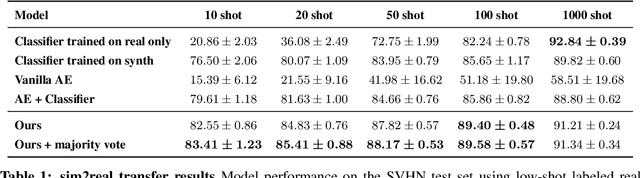

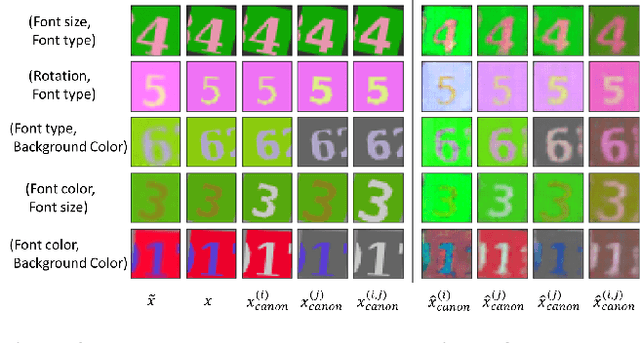
We seek to learn a representation on a large annotated data source that generalizes to a target domain using limited new supervision. Many prior approaches to this problem have focused on learning "disentangled" representations so that as individual factors vary in a new domain, only a portion of the representation need be updated. In this work, we seek the generalization power of disentangled representations, but relax the requirement of explicit latent disentanglement and instead encourage linearity of individual factors of variation by requiring them to be manipulable by learned linear transformations. We dub these transformations latent canonicalizers, as they aim to modify the value of a factor to a pre-determined (but arbitrary) canonical value (e.g., recoloring the image foreground to black). Assuming a source domain with access to meta-labels specifying the factors of variation within an image, we demonstrate experimentally that our method helps reduce the number of observations needed to generalize to a similar target domain when compared to a number of supervised baselines.