 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Paralinguistic Speech Representations Using Self-Supervised Conformers
Oct 09, 2021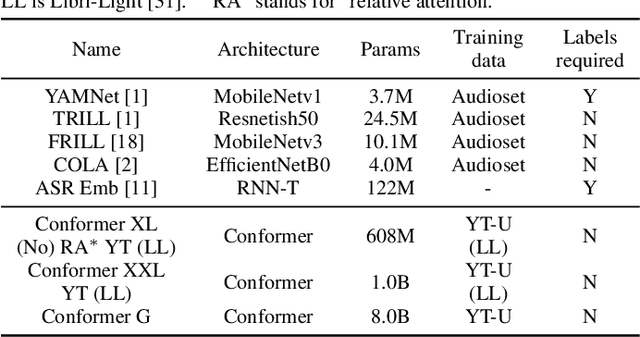
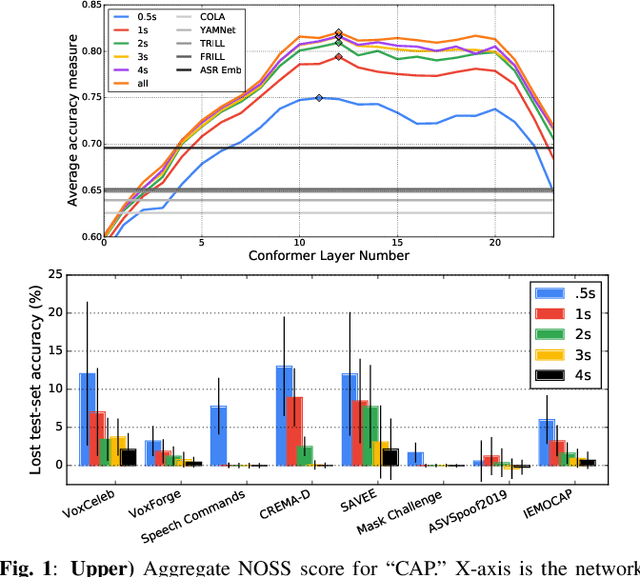
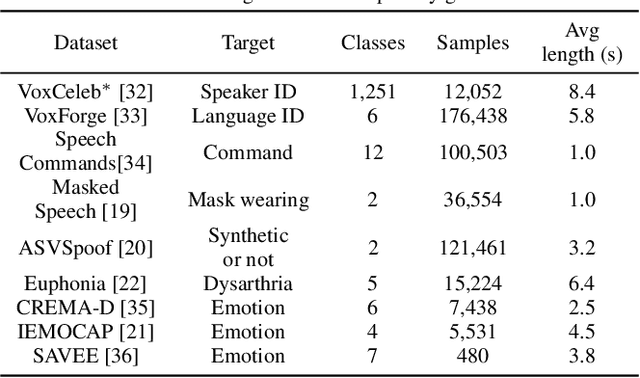
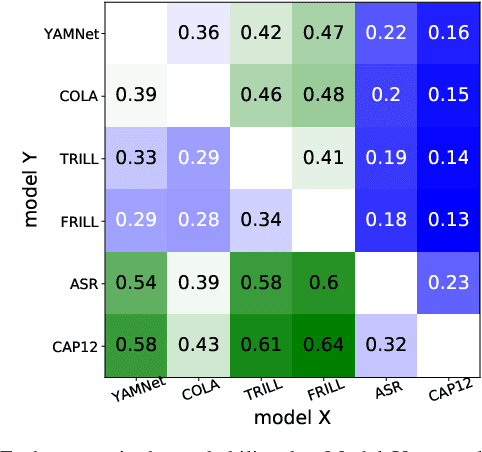
Many speech applications require understanding aspects beyond the words being spoken, such as recognizing emotion, detecting whether the speaker is wearing a mask, or distinguishing real from synthetic speech. In this work, we introduce a new state-of-the-art paralinguistic representation derived from large-scale, fully self-supervised training of a 600M+ parameter Conformer-based architecture. We benchmark on a diverse set of speech tasks and demonstrate that simple linear classifiers trained on top of our time-averaged representation outperform nearly all previous results, in some cases by large margins. Our analyses of context-window size demonstrate that, surprisingly, 2 second context-windows achieve 98% the performance of the Conformers that use the full long-term context. Furthermore, while the best per-task representations are extracted internally in the network, stable performance across several layers allows a single universal representation to reach near optimal performance on all tasks.
BigSSL: Exploring the Frontier of Large-Scale Semi-Supervised Learning for Automatic Speech Recognition
Oct 01, 2021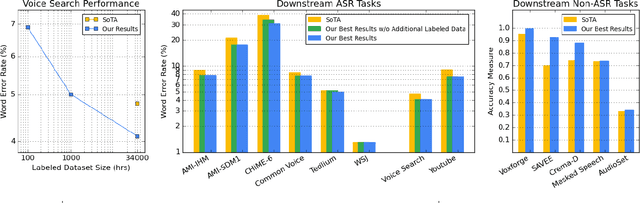
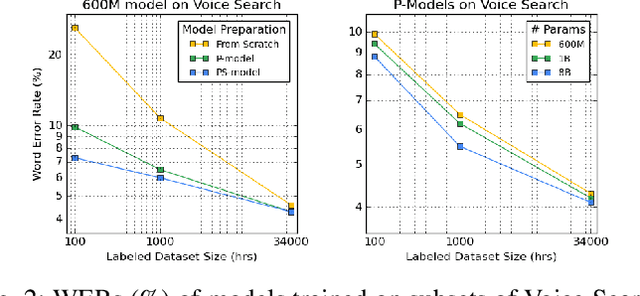
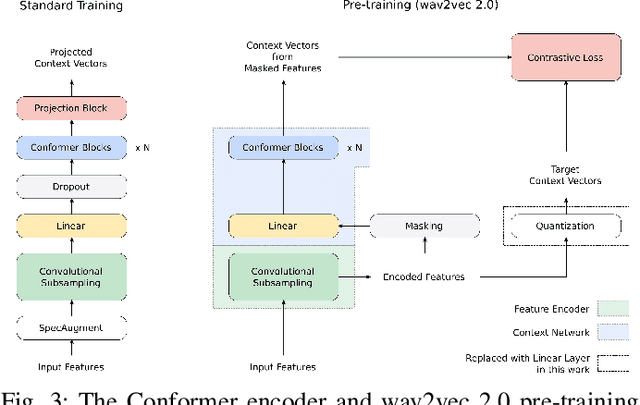
We summarize the results of a host of efforts using giant automatic speech recognition (ASR) models pre-trained using large, diverse unlabeled datasets containing approximately a million hours of audio. We find that the combination of pre-training, self-training and scaling up model size greatly increases data efficiency, even for extremely large tasks with tens of thousands of hours of labeled data. In particular, on an ASR task with 34k hours of labeled data, by fine-tuning an 8 billion parameter pre-trained Conformer model we can match state-of-the-art (SoTA) performance with only 3% of the training data and significantly improve SoTA with the full training set. We also report on the universal benefits gained from using big pre-trained and self-trained models for a large set of downstream tasks that cover a wide range of speech domains and span multiple orders of magnitudes of dataset sizes, including obtaining SoTA performance on many public benchmarks. In addition, we utilize the learned representation of pre-trained networks to achieve SoTA results on non-ASR tasks.
Attention Bottlenecks for Multimodal Fusion
Jun 30, 2021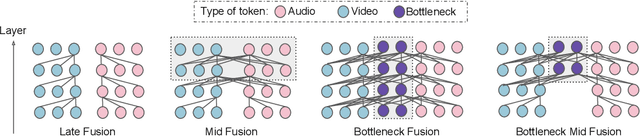
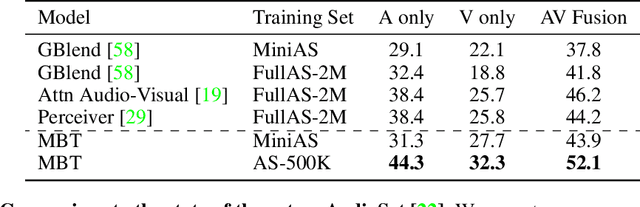
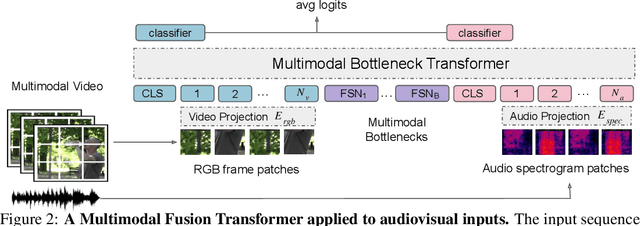
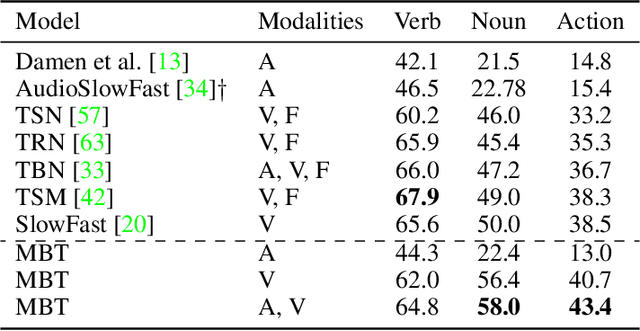
Humans perceive the world by concurrently processing and fusing high-dimensional inputs from multiple modalities such as vision and audio. Machine perception models, in stark contrast, are typically modality-specific and optimised for unimodal benchmarks, and hence late-stage fusion of final representations or predictions from each modality (`late-fusion') is still a dominant paradigm for multimodal video classification. Instead, we introduce a novel transformer based architecture that uses `fusion bottlenecks' for modality fusion at multiple layers. Compared to traditional pairwise self-attention, our model forces information between different modalities to pass through a small number of bottleneck latents, requiring the model to collate and condense the most relevant information in each modality and only share what is necessary. We find that such a strategy improves fusion performance, at the same time reducing computational cost. We conduct thorough ablation studies, and achieve state-of-the-art results on multiple audio-visual classification benchmarks including Audioset, Epic-Kitchens and VGGSound. All code and models will be released.
Sparse, Efficient, and Semantic Mixture Invariant Training: Taming In-the-Wild Unsupervised Sound Separation
Jun 01, 2021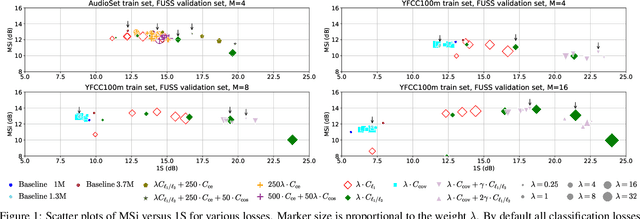
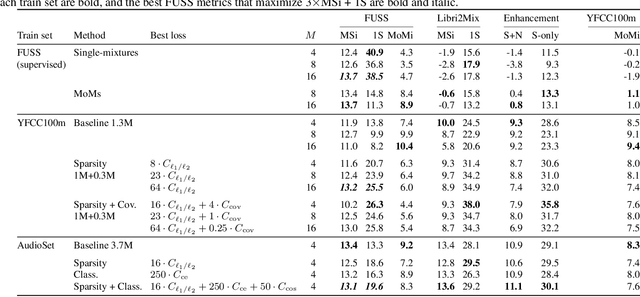
Supervised neural network training has led to significant progress on single-channel sound separation. This approach relies on ground truth isolated sources, which precludes scaling to widely available mixture data and limits progress on open-domain tasks. The recent mixture invariant training (MixIT) method enables training on in-the wild data; however, it suffers from two outstanding problems. First, it produces models which tend to over-separate, producing more output sources than are present in the input. Second, the exponential computational complexity of the MixIT loss limits the number of feasible output sources. These problems interact: increasing the number of output sources exacerbates over-separation. In this paper we address both issues. To combat over-separation we introduce new losses: sparsity losses that favor fewer output sources and a covariance loss that discourages correlated outputs. We also experiment with a semantic classification loss by predicting weak class labels for each mixture. To extend MixIT to larger numbers of sources, we introduce an efficient approximation using a fast least-squares solution, projected onto the MixIT constraint set. Our experiments show that the proposed losses curtail over-separation and improve overall performance. The best performance is achieved using larger numbers of output sources, enabled by our efficient MixIT loss, combined with sparsity losses to prevent over-separation. On the FUSS test set, we achieve over 13 dB in multi-source SI-SNR improvement, while boosting single-source reconstruction SI-SNR by over 17 dB.
The Benefit Of Temporally-Strong Labels In Audio Event Classification
May 14, 2021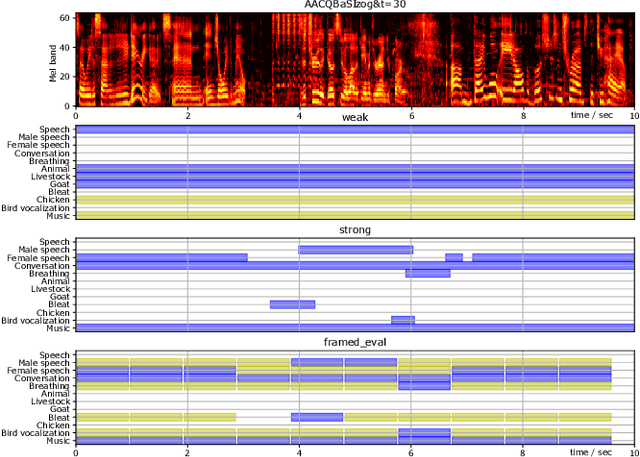
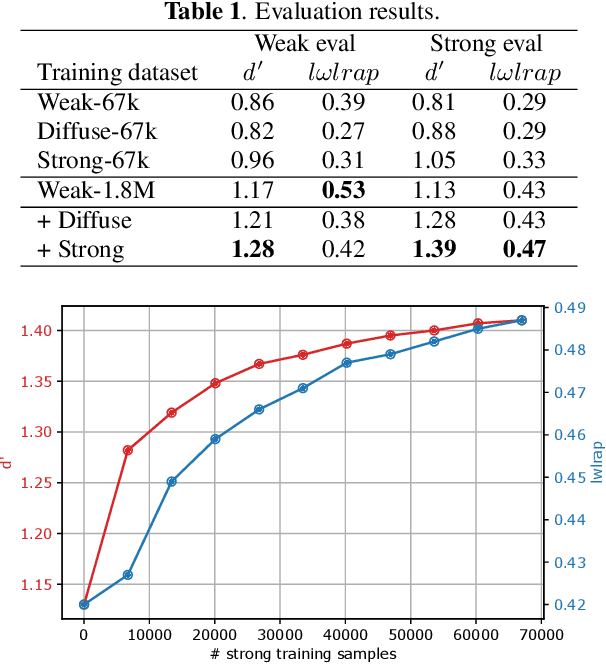
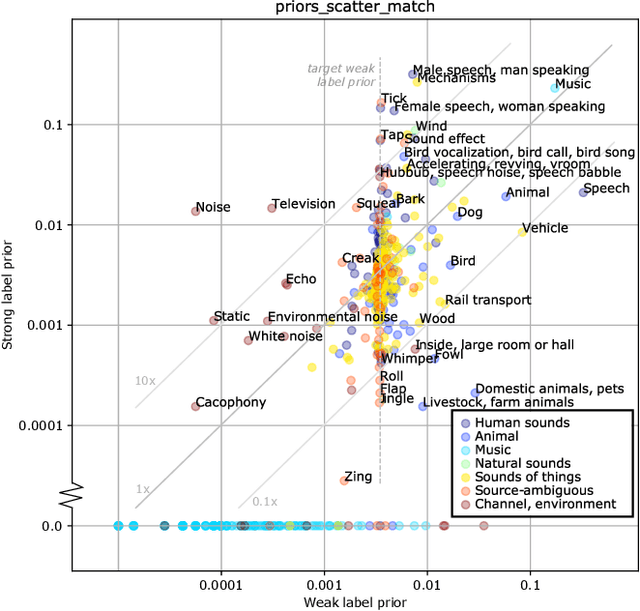
To reveal the importance of temporal precision in ground truth audio event labels, we collected precise (~0.1 sec resolution) "strong" labels for a portion of the AudioSet dataset. We devised a temporally strong evaluation set (including explicit negatives of varying difficulty) and a small strong-labeled training subset of 67k clips (compared to the original dataset's 1.8M clips labeled at 10 sec resolution). We show that fine-tuning with a mix of weak and strongly labeled data can substantially improve classifier performance, even when evaluated using only the original weak labels. For a ResNet50 architecture, d' on the strong evaluation data including explicit negatives improves from 1.13 to 1.41. The new labels are available as an update to AudioSet.
Self-Supervised Learning from Automatically Separated Sound Scenes
May 05, 2021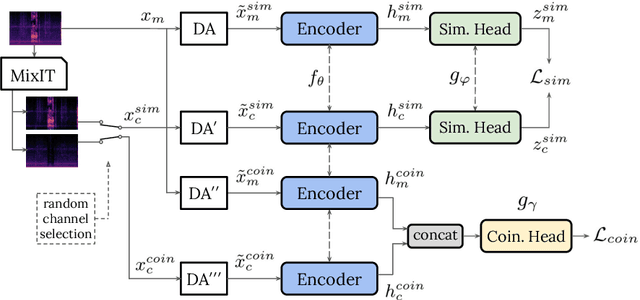
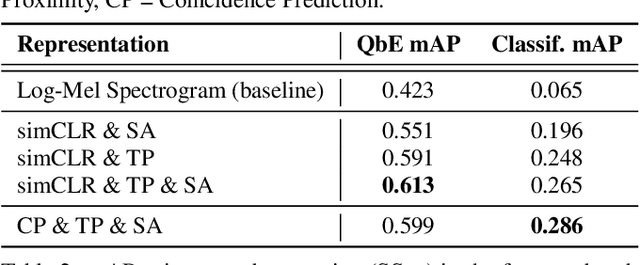

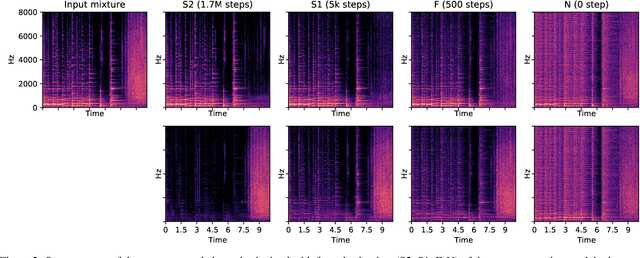
Real-world sound scenes consist of time-varying collections of sound sources, each generating characteristic sound events that are mixed together in audio recordings. The association of these constituent sound events with their mixture and each other is semantically constrained: the sound scene contains the union of source classes and not all classes naturally co-occur. With this motivation, this paper explores the use of unsupervised automatic sound separation to decompose unlabeled sound scenes into multiple semantically-linked views for use in self-supervised contrastive learning. We find that learning to associate input mixtures with their automatically separated outputs yields stronger representations than past approaches that use the mixtures alone. Further, we discover that optimal source separation is not required for successful contrastive learning by demonstrating that a range of separation system convergence states all lead to useful and often complementary example transformations. Our best system incorporates these unsupervised separation models into a single augmentation front-end and jointly optimizes similarity maximization and coincidence prediction objectives across the views. The result is an unsupervised audio representation that rivals state-of-the-art alternatives on the established shallow AudioSet classification benchmark.
Into the Wild with AudioScope: Unsupervised Audio-Visual Separation of On-Screen Sounds
Nov 02, 2020
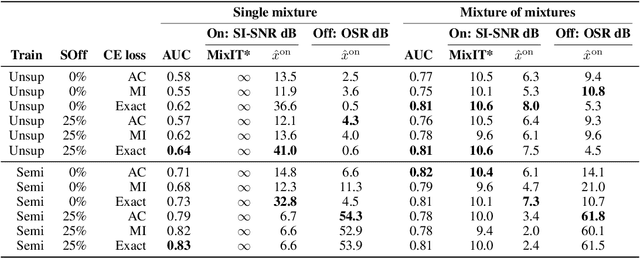
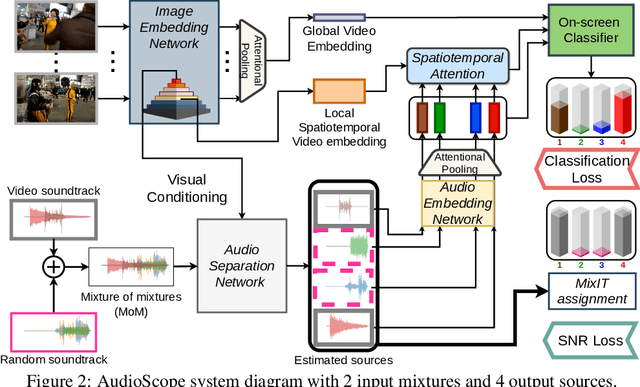
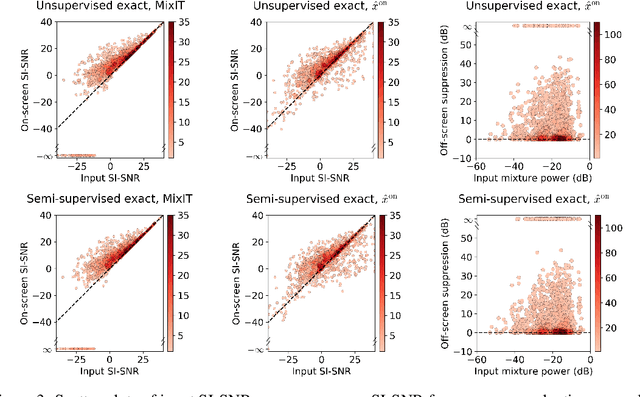
Recent progress in deep learning has enabled many advances in sound separation and visual scene understanding. However, extracting sound sources which are apparent in natural videos remains an open problem. In this work, we present AudioScope, a novel audio-visual sound separation framework that can be trained without supervision to isolate on-screen sound sources from real in-the-wild videos. Prior audio-visual separation work assumed artificial limitations on the domain of sound classes (e.g., to speech or music), constrained the number of sources, and required strong sound separation or visual segmentation labels. AudioScope overcomes these limitations, operating on an open domain of sounds, with variable numbers of sources, and without labels or prior visual segmentation. The training procedure for AudioScope uses mixture invariant training (MixIT) to separate synthetic mixtures of mixtures (MoMs) into individual sources, where noisy labels for mixtures are provided by an unsupervised audio-visual coincidence model. Using the noisy labels, along with attention between video and audio features, AudioScope learns to identify audio-visual similarity and to suppress off-screen sounds. We demonstrate the effectiveness of our approach using a dataset of video clips extracted from open-domain YFCC100m video data. This dataset contains a wide diversity of sound classes recorded in unconstrained conditions, making the application of previous methods unsuitable. For evaluation and semi-supervised experiments, we collected human labels for presence of on-screen and off-screen sounds on a small subset of clips.
Addressing Missing Labels in Large-scale Sound Event Recognition using a Teacher-student Framework with Loss Masking
May 02, 2020
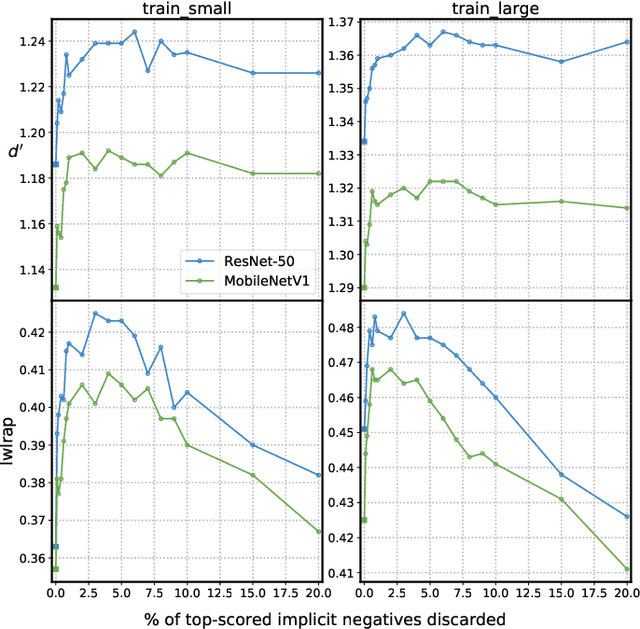
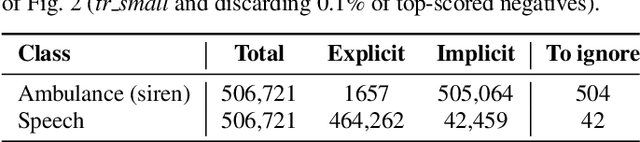
The study of label noise in sound event recognition has recently gained attention with the advent of larger and noisier datasets. This work addresses the problem of missing labels, one of the big weaknesses of large audio datasets, and one of the most conspicuous issues for AudioSet. We propose a simple and model-agnostic method based on a teacher-student framework with loss masking to first identify the most critical missing label candidates, and then ignore their contribution during the learning process. We find that a simple optimisation of the training label set improves recognition performance without additional compute. We discover that most of the improvement comes from ignoring a critical tiny portion of the missing labels. We also show that the damage done by missing labels is larger as the training set gets smaller, yet it can still be observed even when training with massive amounts of audio. We believe these insights can generalize to other large-scale datasets.
Towards Learning a Universal Non-Semantic Representation of Speech
Mar 02, 2020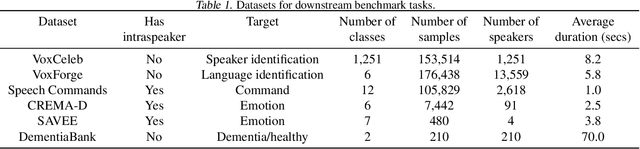
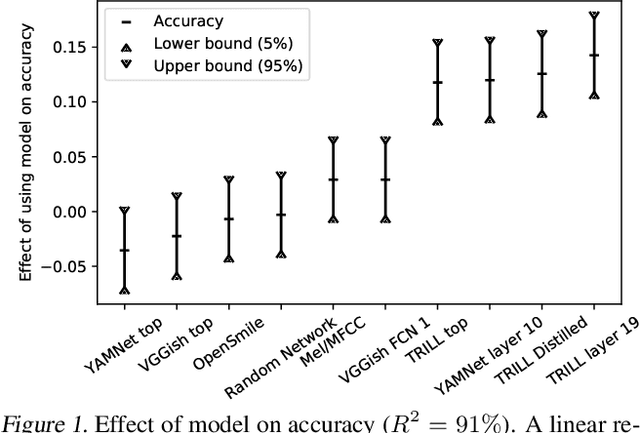
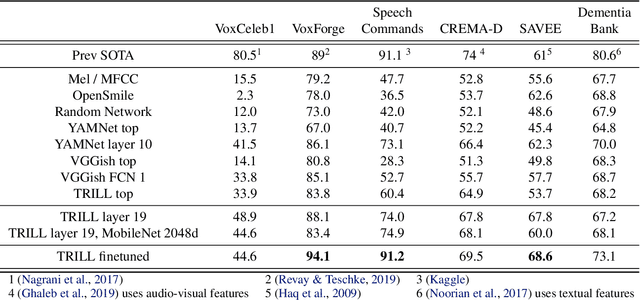
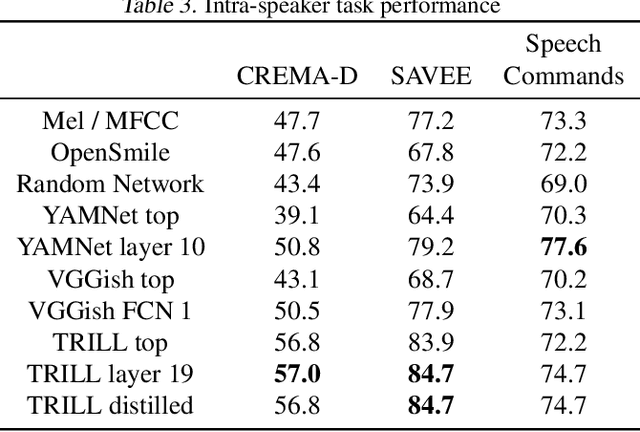
The ultimate goal of transfer learning is to reduce labeled data requirements by exploiting a pre-existing embedding model trained for different datasets or tasks. While significant progress has been made in the visual and language domains, the speech community has yet to identify a strategy with wide-reaching applicability across tasks. This paper describes a representation of speech based on an unsupervised triplet-loss objective, which exceeds state-of-the-art performance on a number of transfer learning tasks drawn from the non-semantic speech domain. The embedding is trained on a publicly available dataset, and it is tested on a variety of low-resource downstream tasks, including personalization tasks and medical domain. The model will be publicly released.
Improving Universal Sound Separation Using Sound Classification
Nov 18, 2019
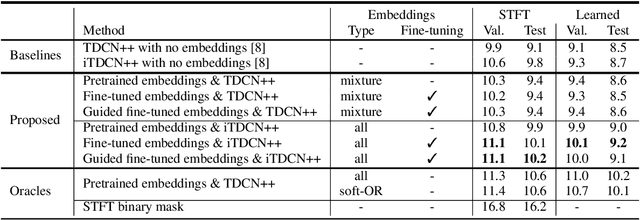
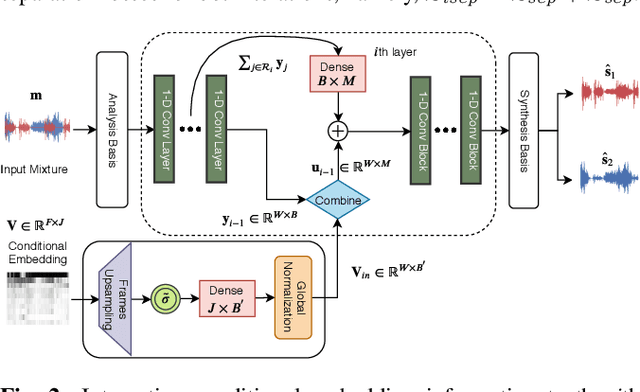
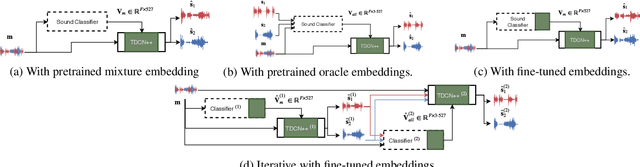
Deep learning approaches have recently achieved impressive performance on both audio source separation and sound classification. Most audio source separation approaches focus only on separating sources belonging to a restricted domain of source classes, such as speech and music. However, recent work has demonstrated the possibility of "universal sound separation", which aims to separate acoustic sources from an open domain, regardless of their class. In this paper, we utilize the semantic information learned by sound classifier networks trained on a vast amount of diverse sounds to improve universal sound separation. In particular, we show that semantic embeddings extracted from a sound classifier can be used to condition a separation network, providing it with useful additional information. This approach is especially useful in an iterative setup, where source estimates from an initial separation stage and their corresponding classifier-derived embeddings are fed to a second separation network. By performing a thorough hyperparameter search consisting of over a thousand experiments, we find that classifier embeddings from clean sources provide nearly one dB of SNR gain, and our best iterative models achieve a significant fraction of this oracle performance, establishing a new state-of-the-art for universal sound separation.