 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLAC: Latent Action Composition for Skeleton-based Action Segmentation
Aug 31, 2023Skeleton-based action segmentation requires recognizing composable actions in untrimmed videos. Current approaches decouple this problem by first extracting local visual features from skeleton sequences and then processing them by a temporal model to classify frame-wise actions. However, their performances remain limited as the visual features cannot sufficiently express composable actions. In this context, we propose Latent Action Composition (LAC), a novel self-supervised framework aiming at learning from synthesized composable motions for skeleton-based action segmentation. LAC is composed of a novel generation module towards synthesizing new sequences. Specifically, we design a linear latent space in the generator to represent primitive motion. New composed motions can be synthesized by simply performing arithmetic operations on latent representations of multiple input skeleton sequences. LAC leverages such synthesized sequences, which have large diversity and complexity, for learning visual representations of skeletons in both sequence and frame spaces via contrastive learning. The resulting visual encoder has a high expressive power and can be effectively transferred onto action segmentation tasks by end-to-end fine-tuning without the need for additional temporal models. We conduct a study focusing on transfer-learning and we show that representations learned from pre-trained LAC outperform the state-of-the-art by a large margin on TSU, Charades, PKU-MMD datasets.
Attending Generalizability in Course of Deep Fake Detection by Exploring Multi-task Learning
Aug 25, 2023



This work explores various ways of exploring multi-task learning (MTL) techniques aimed at classifying videos as original or manipulated in cross-manipulation scenario to attend generalizability in deep fake scenario. The dataset used in our evaluation is FaceForensics++, which features 1000 original videos manipulated by four different techniques, with a total of 5000 videos. We conduct extensive experiments on multi-task learning and contrastive techniques, which are well studied in literature for their generalization benefits. It can be concluded that the proposed detection model is quite generalized, i.e., accurately detects manipulation methods not encountered during training as compared to the state-of-the-art.
Self-Supervised Video Representation Learning via Latent Time Navigation
May 10, 2023



Self-supervised video representation learning aimed at maximizing similarity between different temporal segments of one video, in order to enforce feature persistence over time. This leads to loss of pertinent information related to temporal relationships, rendering actions such as `enter' and `leave' to be indistinguishable. To mitigate this limitation, we propose Latent Time Navigation (LTN), a time-parameterized contrastive learning strategy that is streamlined to capture fine-grained motions. Specifically, we maximize the representation similarity between different video segments from one video, while maintaining their representations time-aware along a subspace of the latent representation code including an orthogonal basis to represent temporal changes. Our extensive experimental analysis suggests that learning video representations by LTN consistently improves performance of action classification in fine-grained and human-oriented tasks (e.g., on Toyota Smarthome dataset). In addition, we demonstrate that our proposed model, when pre-trained on Kinetics-400, generalizes well onto the unseen real world video benchmark datasets UCF101 and HMDB51, achieving state-of-the-art performance in action recognition.
LEO: Generative Latent Image Animator for Human Video Synthesis
May 06, 2023Spatio-temporal coherency is a major challenge in synthesizing high quality videos, particularly in synthesizing human videos that contain rich global and local deformations. To resolve this challenge, previous approaches have resorted to different features in the generation process aimed at representing appearance and motion. However, in the absence of strict mechanisms to guarantee such disentanglement, a separation of motion from appearance has remained challenging, resulting in spatial distortions and temporal jittering that break the spatio-temporal coherency. Motivated by this, we here propose LEO, a novel framework for human video synthesis, placing emphasis on spatio-temporal coherency. Our key idea is to represent motion as a sequence of flow maps in the generation process, which inherently isolate motion from appearance. We implement this idea via a flow-based image animator and a Latent Motion Diffusion Model (LMDM). The former bridges a space of motion codes with the space of flow maps, and synthesizes video frames in a warp-and-inpaint manner. LMDM learns to capture motion prior in the training data by synthesizing sequences of motion codes. Extensive quantitative and qualitative analysis suggests that LEO significantly improves coherent synthesis of human videos over previous methods on the datasets TaichiHD, FaceForensics and CelebV-HQ. In addition, the effective disentanglement of appearance and motion in LEO allows for two additional tasks, namely infinite-length human video synthesis, as well as content-preserving video editing.
Learning Invariance from Generated Variance for Unsupervised Person Re-identification
Jan 02, 2023This work focuses on unsupervised representation learning in person re-identification (ReID). Recent self-supervised contrastive learning methods learn invariance by maximizing the representation similarity between two augmented views of a same image. However, traditional data augmentation may bring to the fore undesirable distortions on identity features, which is not always favorable in id-sensitive ReID tasks. In this paper, we propose to replace traditional data augmentation with a generative adversarial network (GAN) that is targeted to generate augmented views for contrastive learning. A 3D mesh guided person image generator is proposed to disentangle a person image into id-related and id-unrelated features. Deviating from previous GAN-based ReID methods that only work in id-unrelated space (pose and camera style), we conduct GAN-based augmentation on both id-unrelated and id-related features. We further propose specific contrastive losses to help our network learn invariance from id-unrelated and id-related augmentations. By jointly training the generative and the contrastive modules, our method achieves new state-of-the-art unsupervised person ReID performance on mainstream large-scale benchmarks.
Synthetic Data in Human Analysis: A Survey
Aug 19, 2022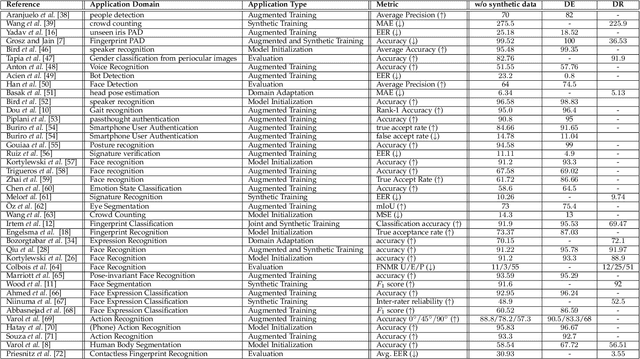



Deep neural networks have become prevalent in human analysis, boosting the performance of applications, such as biometric recognition, action recognition, as well as person re-identification. However, the performance of such networks scales with the available training data. In human analysis, the demand for large-scale datasets poses a severe challenge, as data collection is tedious, time-expensive, costly and must comply with data protection laws. Current research investigates the generation of \textit{synthetic data} as an efficient and privacy-ensuring alternative to collecting real data in the field. This survey introduces the basic definitions and methodologies, essential when generating and employing synthetic data for human analysis. We conduct a survey that summarises current state-of-the-art methods and the main benefits of using synthetic data. We also provide an overview of publicly available synthetic datasets and generation models. Finally, we discuss limitations, as well as open research problems in this field. This survey is intended for researchers and practitioners in the field of human analysis.
Latent Image Animator: Learning to Animate Images via Latent Space Navigation
Mar 17, 2022

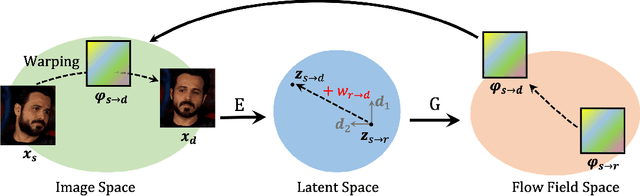
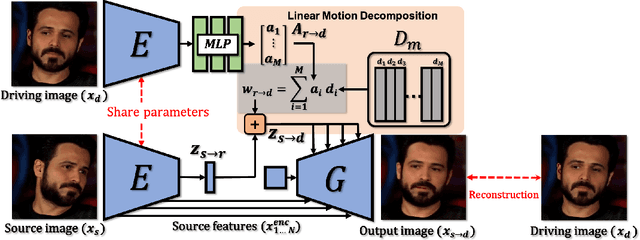
Due to the remarkable progress of deep generative models, animating images has become increasingly efficient, whereas associated results have become increasingly realistic. Current animation-approaches commonly exploit structure representation extracted from driving videos. Such structure representation is instrumental in transferring motion from driving videos to still images. However, such approaches fail in case the source image and driving video encompass large appearance variation. Moreover, the extraction of structure information requires additional modules that endow the animation-model with increased complexity. Deviating from such models, we here introduce the Latent Image Animator (LIA), a self-supervised autoencoder that evades need for structure representation. LIA is streamlined to animate images by linear navigation in the latent space. Specifically, motion in generated video is constructed by linear displacement of codes in the latent space. Towards this, we learn a set of orthogonal motion directions simultaneously, and use their linear combination, in order to represent any displacement in the latent space. Extensive quantitative and qualitative analysis suggests that our model systematically and significantly outperforms state-of-art methods on VoxCeleb, Taichi and TED-talk datasets w.r.t. generated quality.
Beyond the Visible: A Survey on Cross-spectral Face Recognition
Jan 12, 2022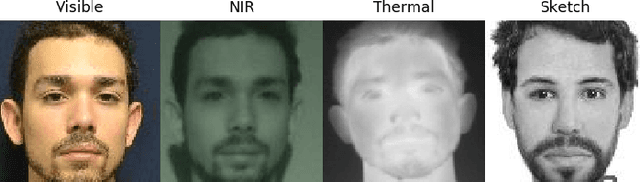
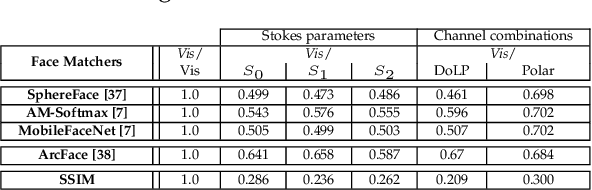
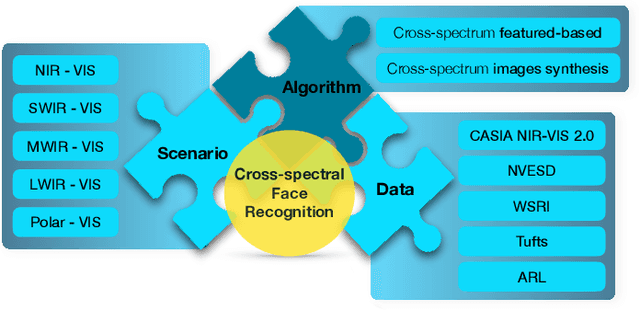
Cross-spectral face recognition (CFR) is aimed at recognizing individuals, where compared face images stem from different sensing modalities, for example infrared vs. visible. While CFR is inherently more challenging than classical face recognition due to significant variation in facial appearance associated to a modality gap, it is superior in scenarios with limited or challenging illumination, as well as in the presence of presentation attacks. Recent advances in artificial intelligence related to convolutional neural networks (CNNs) have brought to the fore a significant performance improvement in CFR. Motivated by this, the contributions of this survey are three-fold. We provide an overview of CFR, targeted to compare face images captured in different spectra, by firstly formalizing CFR and then presenting concrete related applications. Secondly, we explore suitable spectral bands for recognition and discuss recent CFR-methods, placing emphasis on deep neural networks. In particular we revisit techniques that have been proposed to extract and compare heterogeneous features, as well as datasets. We enumerate strengths and limitations of different spectra and associated algorithms. Finally, we discuss research challenges and future lines of research.
UNIK: A Unified Framework for Real-world Skeleton-based Action Recognition
Jul 19, 2021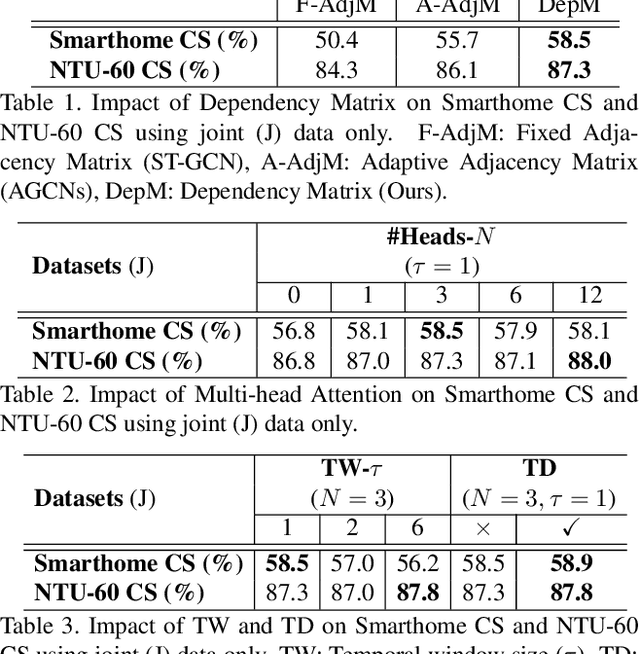
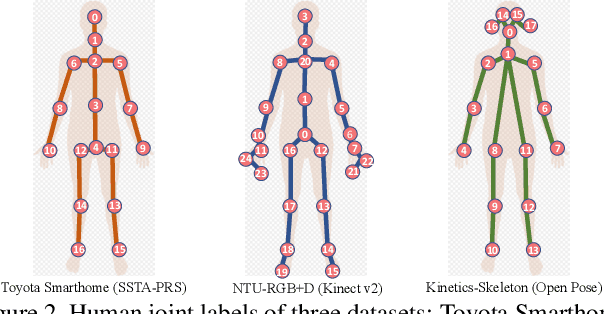
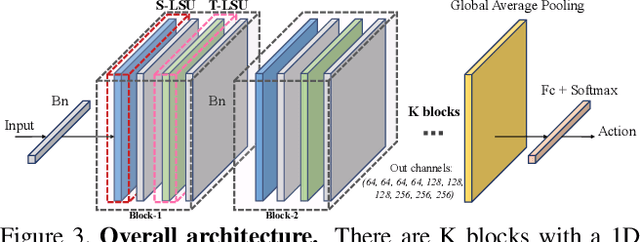
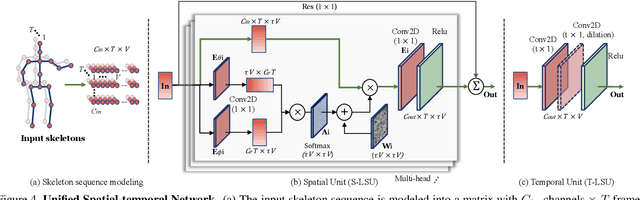
Action recognition based on skeleton data has recently witnessed increasing attention and progress. State-of-the-art approaches adopting Graph Convolutional networks (GCNs) can effectively extract features on human skeletons relying on the pre-defined human topology. Despite associated progress, GCN-based methods have difficulties to generalize across domains, especially with different human topological structures. In this context, we introduce UNIK, a novel skeleton-based action recognition method that is not only effective to learn spatio-temporal features on human skeleton sequences but also able to generalize across datasets. This is achieved by learning an optimal dependency matrix from the uniform distribution based on a multi-head attention mechanism. Subsequently, to study the cross-domain generalizability of skeleton-based action recognition in real-world videos, we re-evaluate state-of-the-art approaches as well as the proposed UNIK in light of a novel Posetics dataset. This dataset is created from Kinetics-400 videos by estimating, refining and filtering poses. We provide an analysis on how much performance improves on smaller benchmark datasets after pre-training on Posetics for the action classification task. Experimental results show that the proposed UNIK, with pre-training on Posetics, generalizes well and outperforms state-of-the-art when transferred onto four target action classification datasets: Toyota Smarthome, Penn Action, NTU-RGB+D 60 and NTU-RGB+D 120.
Sensor-invariant Fingerprint ROI Segmentation Using Recurrent Adversarial Learning
Jul 03, 2021
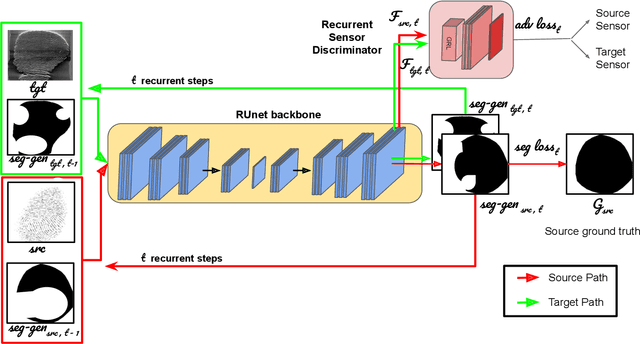

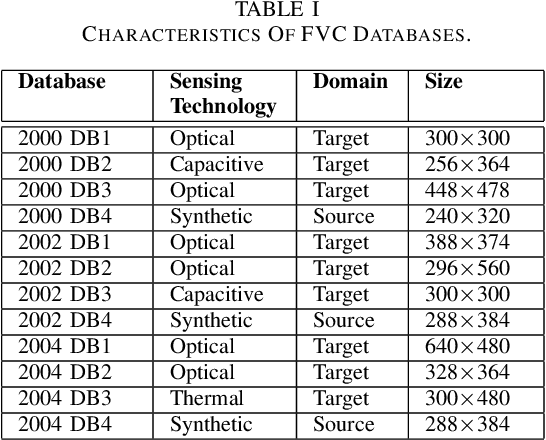
A fingerprint region of interest (roi) segmentation algorithm is designed to separate the foreground fingerprint from the background noise. All the learning based state-of-the-art fingerprint roi segmentation algorithms proposed in the literature are benchmarked on scenarios when both training and testing databases consist of fingerprint images acquired from the same sensors. However, when testing is conducted on a different sensor, the segmentation performance obtained is often unsatisfactory. As a result, every time a new fingerprint sensor is used for testing, the fingerprint roi segmentation model needs to be re-trained with the fingerprint image acquired from the new sensor and its corresponding manually marked ROI. Manually marking fingerprint ROI is expensive because firstly, it is time consuming and more importantly, requires domain expertise. In order to save the human effort in generating annotations required by state-of-the-art, we propose a fingerprint roi segmentation model which aligns the features of fingerprint images derived from the unseen sensor such that they are similar to the ones obtained from the fingerprints whose ground truth roi masks are available for training. Specifically, we propose a recurrent adversarial learning based feature alignment network that helps the fingerprint roi segmentation model to learn sensor-invariant features. Consequently, sensor-invariant features learnt by the proposed roi segmentation model help it to achieve improved segmentation performance on fingerprints acquired from the new sensor. Experiments on publicly available FVC databases demonstrate the efficacy of the proposed work.
* IJCNN 2021 (Accepted)