 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models
Jan 20, 2022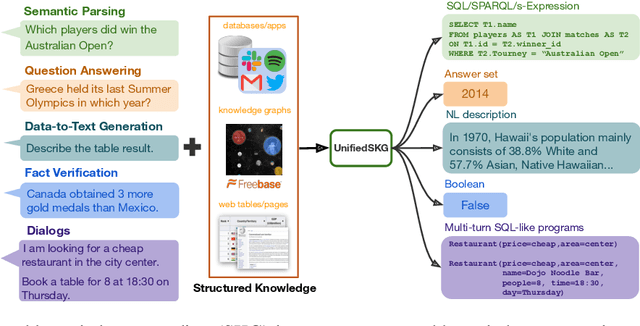
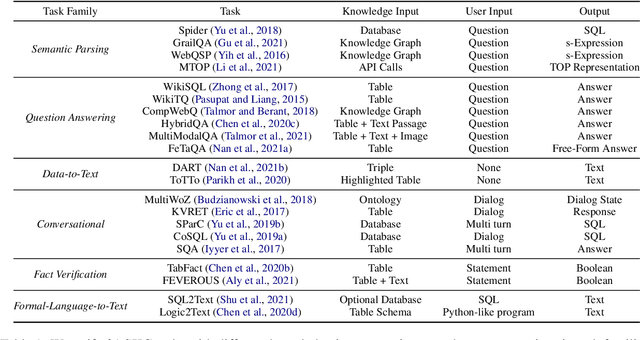
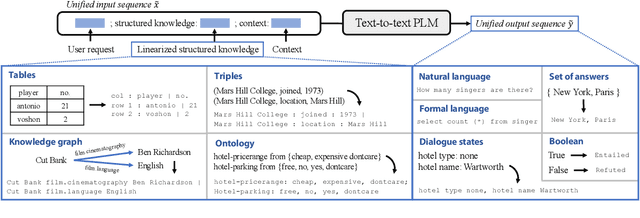
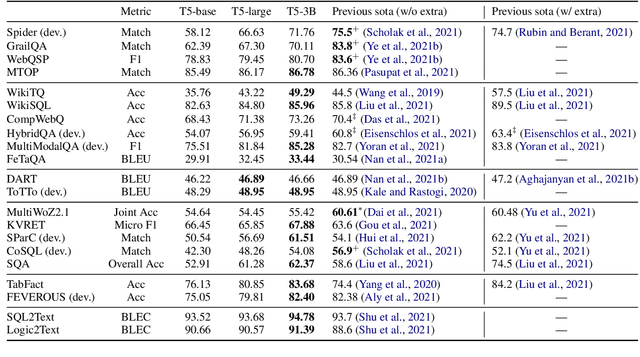
Structured knowledge grounding (SKG) leverages structured knowledge to complete user requests, such as semantic parsing over databases and question answering over knowledge bases. Since the inputs and outputs of SKG tasks are heterogeneous, they have been studied separately by different communities, which limits systematic and compatible research on SKG. In this paper, we overcome this limitation by proposing the SKG framework, which unifies 21 SKG tasks into a text-to-text format, aiming to promote systematic SKG research, instead of being exclusive to a single task, domain, or dataset. We use UnifiedSKG to benchmark T5 with different sizes and show that T5, with simple modifications when necessary, achieves state-of-the-art performance on almost all of the 21 tasks. We further demonstrate that multi-task prefix-tuning improves the performance on most tasks, largely improving the overall performance. UnifiedSKG also facilitates the investigation of zero-shot and few-shot learning, and we show that T0, GPT-3, and Codex struggle in zero-shot and few-shot learning for SKG. We also use UnifiedSKG to conduct a series of controlled experiments on structured knowledge encoding variants across SKG tasks. UnifiedSKG is easily extensible to more tasks, and it is open-sourced at https://github.com/hkunlp/unifiedskg Latest collections at https://unifiedskg.com.
Summ^N: A Multi-Stage Summarization Framework for Long Input Dialogues and Documents
Oct 16, 2021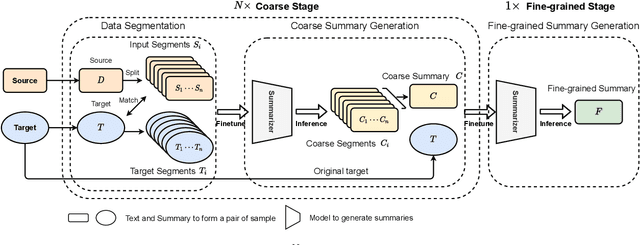
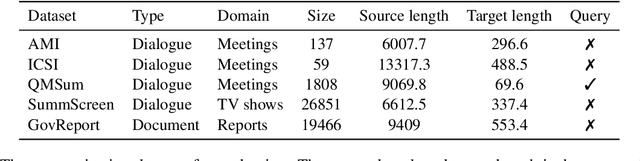
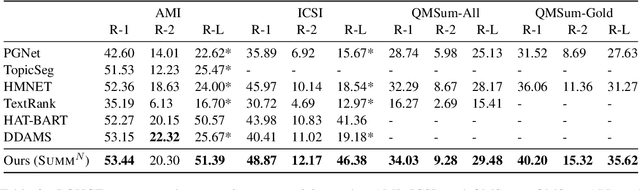
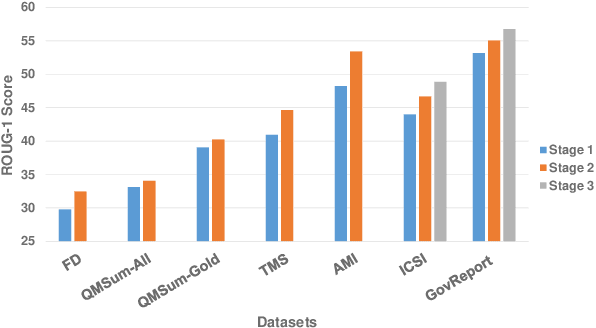
Text summarization is an essential task to help readers capture salient information from documents, news, interviews, and meetings. However, most state-of-the-art pretrained language models are unable to efficiently process long text commonly seen in the summarization problem domain. In this paper, we propose Summ^N, a simple, flexible, and effective multi-stage framework for input texts that are longer than the maximum context lengths of typical pretrained LMs. Summ^N first generates the coarse summary in multiple stages and then produces the final fine-grained summary based on them. The framework can process input text of arbitrary length by adjusting the number of stages while keeping the LM context size fixed. Moreover, it can deal with both documents and dialogues and can be used on top of any underlying backbone abstractive summarization model. Our experiments demonstrate that Summ^N significantly outperforms previous state-of-the-art methods by improving ROUGE scores on three long meeting summarization datasets AMI, ICSI, and QMSum, two long TV series datasets from SummScreen, and a newly proposed long document summarization dataset GovReport. Our data and code are available at https://github.com/chatc/Summ-N.
DYLE: Dynamic Latent Extraction for Abstractive Long-Input Summarization
Oct 15, 2021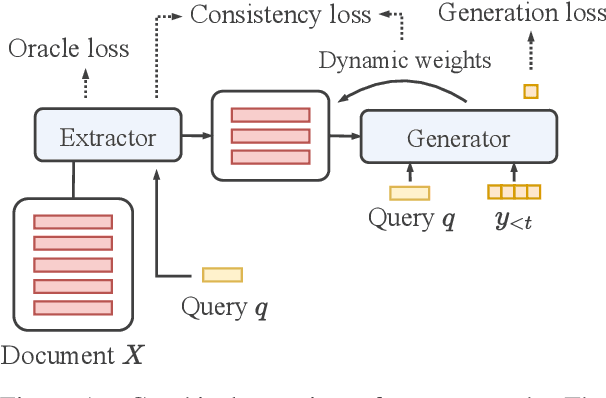
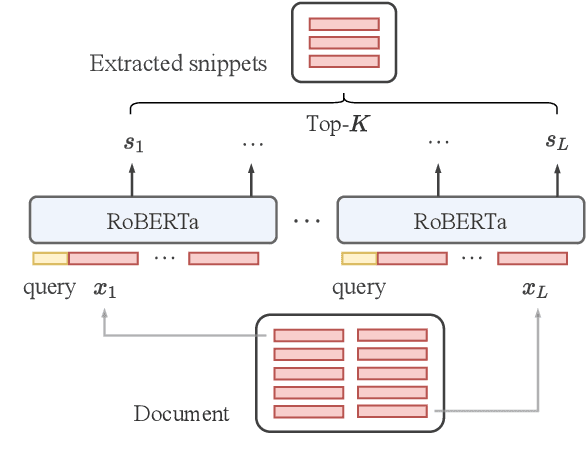
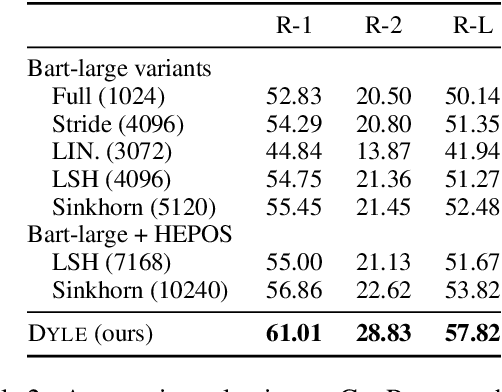
Transformer-based models have achieved state-of-the-art performance on short text summarization. However, they still struggle with long-input summarization. In this paper, we present a new approach for long-input summarization: Dynamic Latent Extraction for Abstractive Summarization. We jointly train an extractor with an abstractor and treat the extracted text snippets as the latent variable. We propose extractive oracles to provide the extractor with a strong learning signal. We introduce consistency loss, which encourages the extractor to approximate the averaged dynamic weights predicted by the generator. We conduct extensive tests on two long-input summarization datasets, GovReport (document) and QMSum (dialogue). Our model significantly outperforms the current state-of-the-art, including a 6.21 ROUGE-2 improvement on GovReport and a 2.13 ROUGE-1 improvement on QMSum. Further analysis shows that the dynamic weights make our generation process highly interpretable. Our code will be publicly available upon publication.
SummerTime: Text Summarization Toolkit for Non-experts
Sep 10, 2021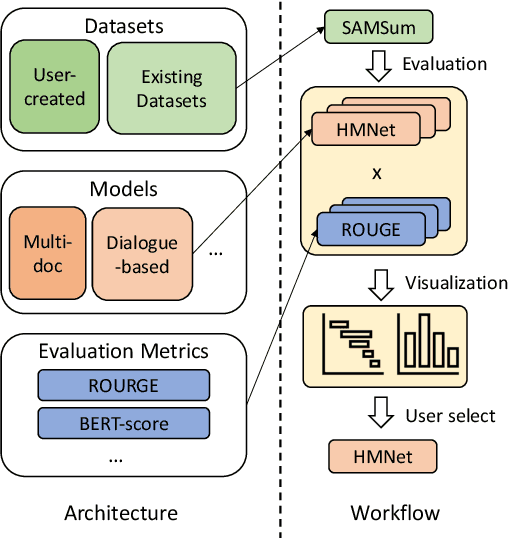
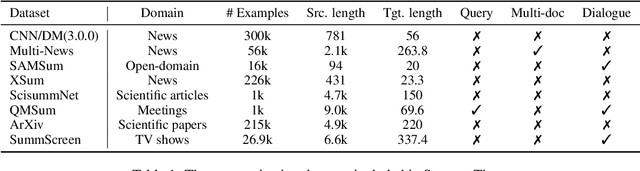

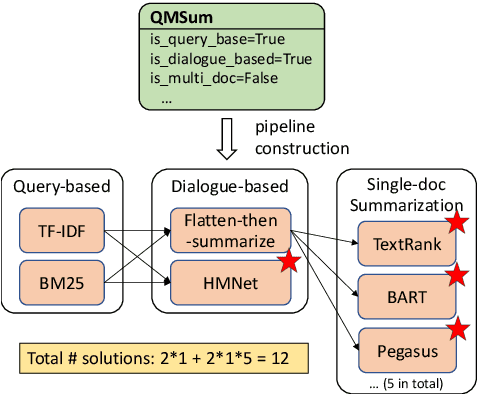
Recent advances in summarization provide models that can generate summaries of higher quality. Such models now exist for a number of summarization tasks, including query-based summarization, dialogue summarization, and multi-document summarization. While such models and tasks are rapidly growing in the research field, it has also become challenging for non-experts to keep track of them. To make summarization methods more accessible to a wider audience, we develop SummerTime by rethinking the summarization task from the perspective of an NLP non-expert. SummerTime is a complete toolkit for text summarization, including various models, datasets and evaluation metrics, for a full spectrum of summarization-related tasks. SummerTime integrates with libraries designed for NLP researchers, and enables users with easy-to-use APIs. With SummerTime, users can locate pipeline solutions and search for the best model with their own data, and visualize the differences, all with a few lines of code. We also provide explanations for models and evaluation metrics to help users understand the model behaviors and select models that best suit their needs. Our library, along with a notebook demo, is available at https://github.com/Yale-LILY/SummerTime.
An Exploratory Study on Long Dialogue Summarization: What Works and What's Next
Sep 10, 2021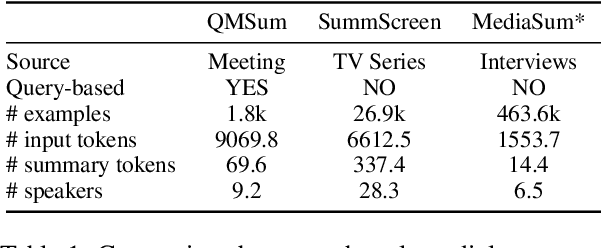
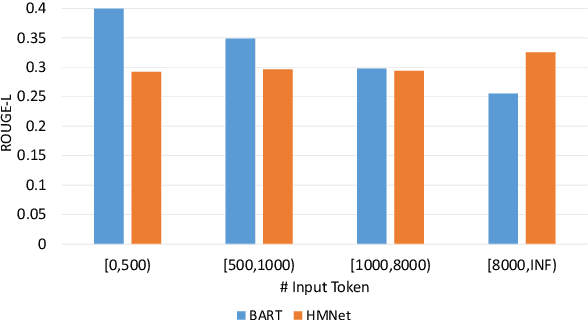
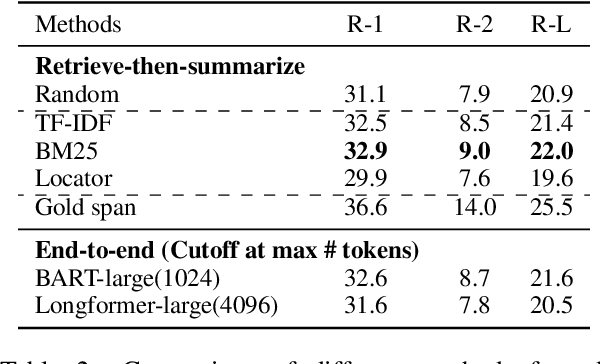
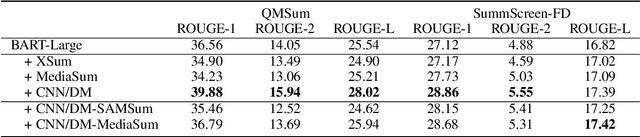
Dialogue summarization helps readers capture salient information from long conversations in meetings, interviews, and TV series. However, real-world dialogues pose a great challenge to current summarization models, as the dialogue length typically exceeds the input limits imposed by recent transformer-based pre-trained models, and the interactive nature of dialogues makes relevant information more context-dependent and sparsely distributed than news articles. In this work, we perform a comprehensive study on long dialogue summarization by investigating three strategies to deal with the lengthy input problem and locate relevant information: (1) extended transformer models such as Longformer, (2) retrieve-then-summarize pipeline models with several dialogue utterance retrieval methods, and (3) hierarchical dialogue encoding models such as HMNet. Our experimental results on three long dialogue datasets (QMSum, MediaSum, SummScreen) show that the retrieve-then-summarize pipeline models yield the best performance. We also demonstrate that the summary quality can be further improved with a stronger retrieval model and pretraining on proper external summarization datasets.
Mitigating False-Negative Contexts in Multi-document QuestionAnswering with Retrieval Marginalization
Mar 22, 2021


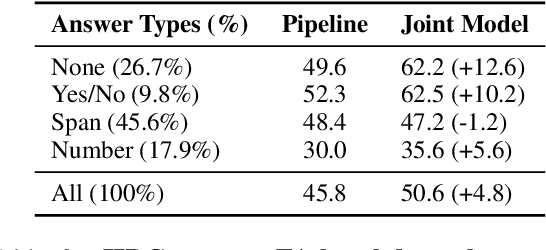
Question Answering (QA) tasks requiring information from multiple documents often rely on a retrieval model to identify relevant information from which the reasoning model can derive an answer. The retrieval model is typically trained to maximize the likelihood of the labeled supporting evidence. However, when retrieving from large text corpora such as Wikipedia, the correct answer can often be obtained from multiple evidence candidates, not all of them labeled as positive, thus rendering the training signal weak and noisy. The problem is exacerbated when the questions are unanswerable or the answers are boolean, since the models cannot rely on lexical overlap to map answers to supporting evidences. We develop a new parameterization of set-valued retrieval that properly handles unanswerable queries, and we show that marginalizing over this set during training allows a model to mitigate false negatives in annotated supporting evidences. We test our method with two multi-document QA datasets, IIRC and HotpotQA. On IIRC, we show that joint modeling with marginalization on alternative contexts improves model performance by 5.5 F1 points and achieves a new state-of-the-art performance of 50.6 F1. We also show that marginalization results in 0.9 to 1.6 QA F1 improvement on HotpotQA in various settings.
Merging Weak and Active Supervision for Semantic Parsing
Nov 29, 2019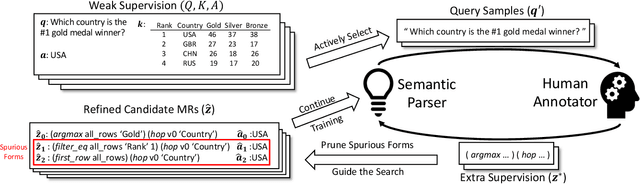

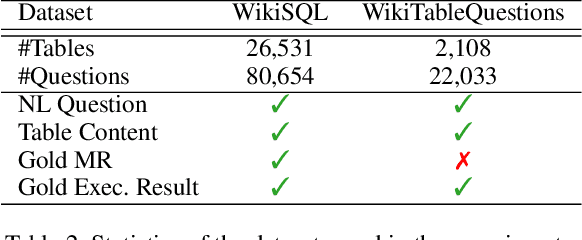
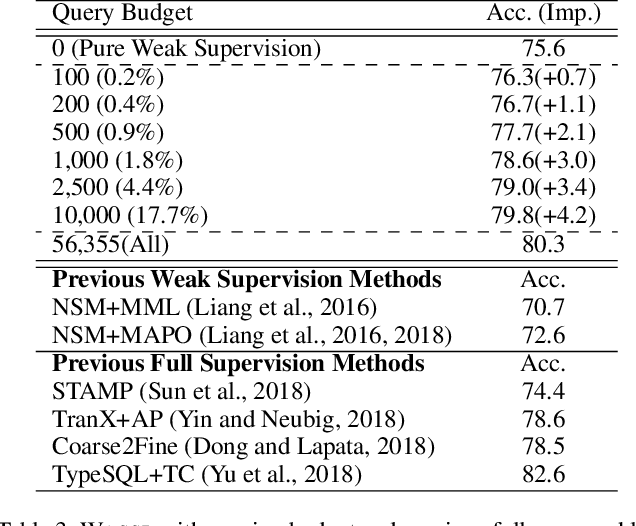
A semantic parser maps natural language commands (NLs) from the users to executable meaning representations (MRs), which are later executed in certain environment to obtain user-desired results. The fully-supervised training of such parser requires NL/MR pairs, annotated by domain experts, which makes them expensive to collect. However, weakly-supervised semantic parsers are learnt only from pairs of NL and expected execution results, leaving the MRs latent. While weak supervision is cheaper to acquire, learning from this input poses difficulties. It demands that parsers search a large space with a very weak learning signal and it is hard to avoid spurious MRs that achieve the correct answer in the wrong way. These factors lead to a performance gap between parsers trained in weakly- and fully-supervised setting. To bridge this gap, we examine the intersection between weak supervision and active learning, which allows the learner to actively select examples and query for manual annotations as extra supervision to improve the model trained under weak supervision. We study different active learning heuristics for selecting examples to query, and various forms of extra supervision for such queries. We evaluate the effectiveness of our method on two different datasets. Experiments on the WikiSQL show that by annotating only 1.8% of examples, we improve over a state-of-the-art weakly-supervised baseline by 6.4%, achieving an accuracy of 79.0%, which is only 1.3% away from the model trained with full supervision. Experiments on WikiTableQuestions with human annotators show that our method can improve the performance with only 100 active queries, especially for weakly-supervised parsers learnt from a cold start.