 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating False-Negative Contexts in Multi-document QuestionAnswering with Retrieval Marginalization
Paper and Code



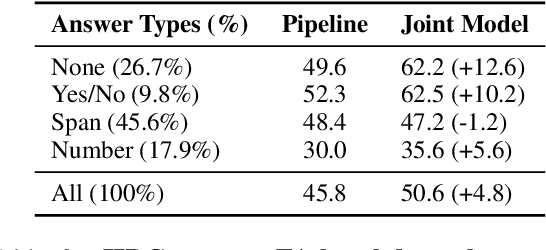
Question Answering (QA) tasks requiring information from multiple documents often rely on a retrieval model to identify relevant information from which the reasoning model can derive an answer. The retrieval model is typically trained to maximize the likelihood of the labeled supporting evidence. However, when retrieving from large text corpora such as Wikipedia, the correct answer can often be obtained from multiple evidence candidates, not all of them labeled as positive, thus rendering the training signal weak and noisy. The problem is exacerbated when the questions are unanswerable or the answers are boolean, since the models cannot rely on lexical overlap to map answers to supporting evidences. We develop a new parameterization of set-valued retrieval that properly handles unanswerable queries, and we show that marginalizing over this set during training allows a model to mitigate false negatives in annotated supporting evidences. We test our method with two multi-document QA datasets, IIRC and HotpotQA. On IIRC, we show that joint modeling with marginalization on alternative contexts improves model performance by 5.5 F1 points and achieves a new state-of-the-art performance of 50.6 F1. We also show that marginalization results in 0.9 to 1.6 QA F1 improvement on HotpotQA in various settings.