 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparison of Techniques for Language Model Integration in Encoder-Decoder Speech Recognition
Jul 27, 2018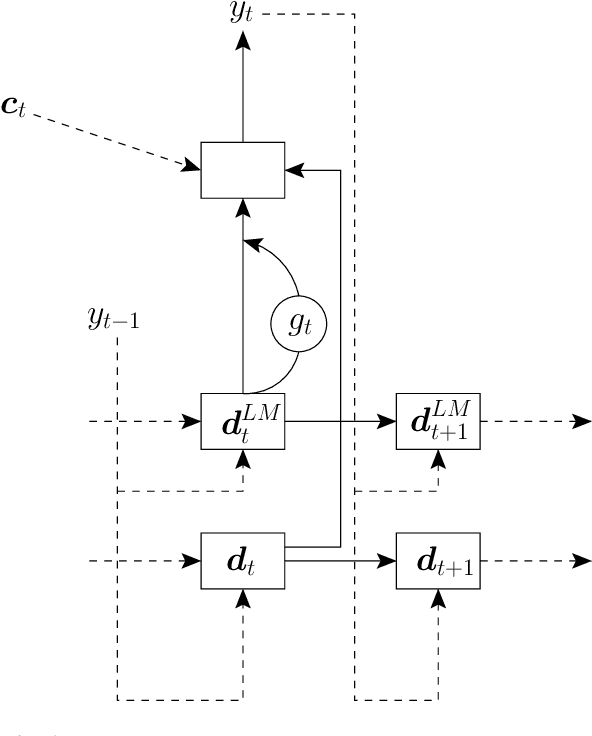
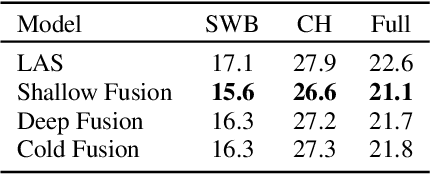
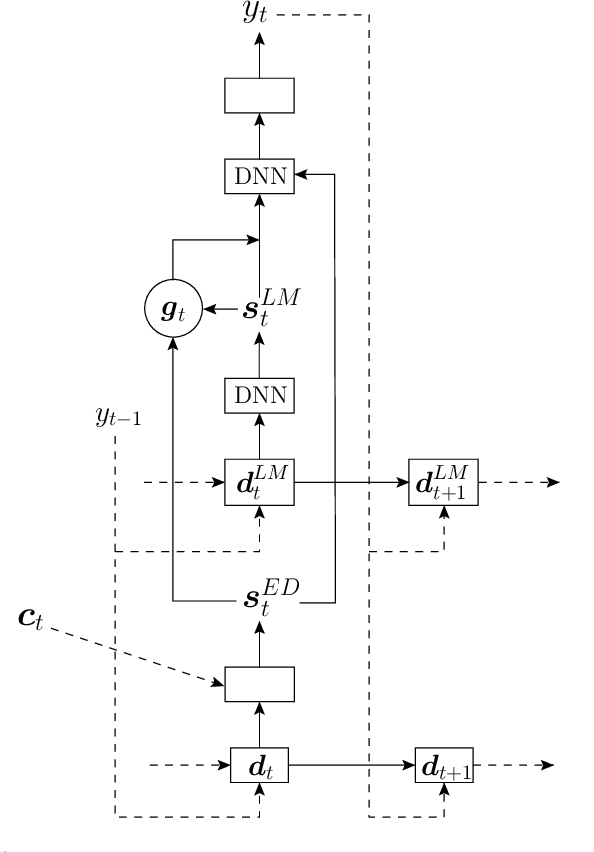

Attention-based recurrent neural encoder-decoder models present an elegant solution to the automatic speech recognition problem. This approach folds the acoustic model, pronunciation model, and language model into a single network and requires only a parallel corpus of speech and text for training. However, unlike in conventional approaches that combine separate acoustic and language models, it is not clear how to use additional (unpaired) text. While there has been previous work on methods addressing this problem, a thorough comparison among methods is still lacking. In this paper, we compare a suite of past methods and some of our own proposed methods for using unpaired text data to improve encoder-decoder models. For evaluation, we use the medium-sized Switchboard data set and the large-scale Google voice search and dictation data sets. Our results confirm the benefits of using unpaired text across a range of methods and data sets. Surprisingly, for first-pass decoding, the rather simple approach of shallow fusion performs best across data sets. However, for Google data sets we find that cold fusion has a lower oracle error rate and outperforms other approaches after second-pass rescoring on the Google voice search data set.
Speech recognition for medical conversations
Jun 20, 2018
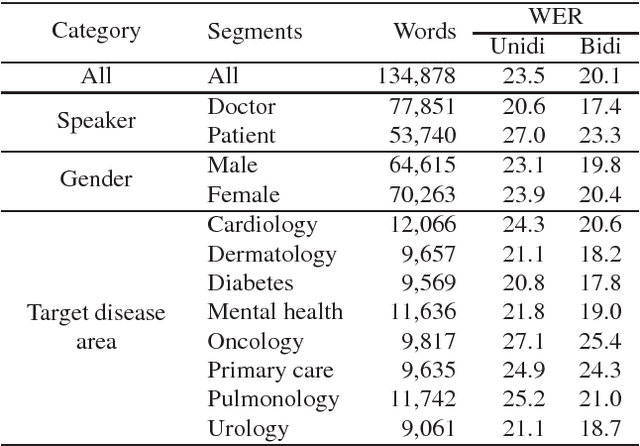
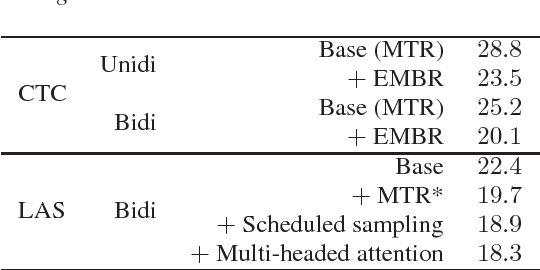
In this work we explored building automatic speech recognition models for transcribing doctor patient conversation. We collected a large scale dataset of clinical conversations ($14,000$ hr), designed the task to represent the real word scenario, and explored several alignment approaches to iteratively improve data quality. We explored both CTC and LAS systems for building speech recognition models. The LAS was more resilient to noisy data and CTC required more data clean up. A detailed analysis is provided for understanding the performance for clinical tasks. Our analysis showed the speech recognition models performed well on important medical utterances, while errors occurred in causal conversations. Overall we believe the resulting models can provide reasonable quality in practice.
State-of-the-art Speech Recognition With Sequence-to-Sequence Models
Feb 23, 2018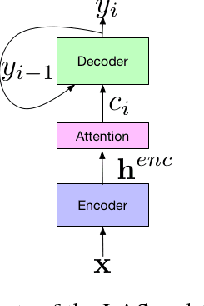
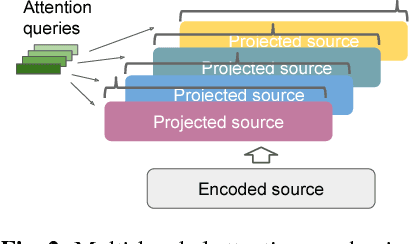
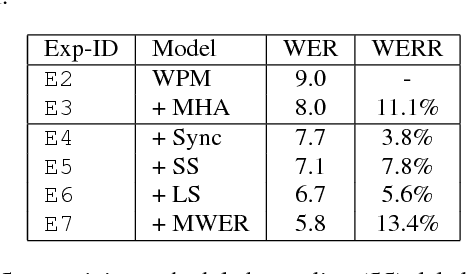
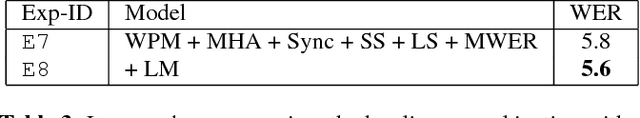
Attention-based encoder-decoder architectures such as Listen, Attend, and Spell (LAS), subsume the acoustic, pronunciation and language model components of a traditional automatic speech recognition (ASR) system into a single neural network. In previous work, we have shown that such architectures are comparable to state-of-theart ASR systems on dictation tasks, but it was not clear if such architectures would be practical for more challenging tasks such as voice search. In this work, we explore a variety of structural and optimization improvements to our LAS model which significantly improve performance. On the structural side, we show that word piece models can be used instead of graphemes. We also introduce a multi-head attention architecture, which offers improvements over the commonly-used single-head attention. On the optimization side, we explore synchronous training, scheduled sampling, label smoothing, and minimum word error rate optimization, which are all shown to improve accuracy. We present results with a unidirectional LSTM encoder for streaming recognition. On a 12, 500 hour voice search task, we find that the proposed changes improve the WER from 9.2% to 5.6%, while the best conventional system achieves 6.7%; on a dictation task our model achieves a WER of 4.1% compared to 5% for the conventional system.
An analysis of incorporating an external language model into a sequence-to-sequence model
Dec 06, 2017

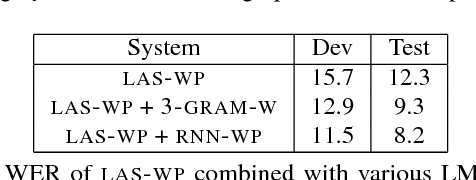

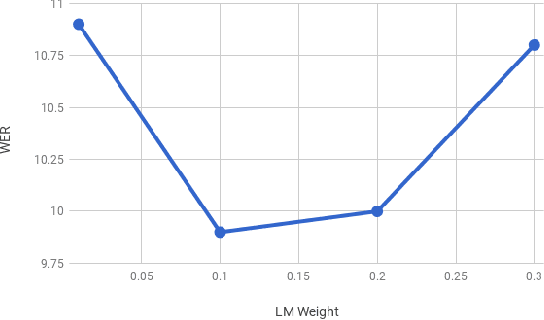
Attention-based sequence-to-sequence models for automatic speech recognition jointly train an acoustic model, language model, and alignment mechanism. Thus, the language model component is only trained on transcribed audio-text pairs. This leads to the use of shallow fusion with an external language model at inference time. Shallow fusion refers to log-linear interpolation with a separately trained language model at each step of the beam search. In this work, we investigate the behavior of shallow fusion across a range of conditions: different types of language models, different decoding units, and different tasks. On Google Voice Search, we demonstrate that the use of shallow fusion with a neural LM with wordpieces yields a 9.1% relative word error rate reduction (WERR) over our competitive attention-based sequence-to-sequence model, obviating the need for second-pass rescoring.
No Need for a Lexicon? Evaluating the Value of the Pronunciation Lexica in End-to-End Models
Dec 05, 2017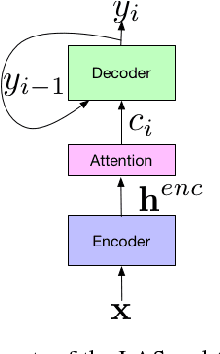


For decades, context-dependent phonemes have been the dominant sub-word unit for conventional acoustic modeling systems. This status quo has begun to be challenged recently by end-to-end models which seek to combine acoustic, pronunciation, and language model components into a single neural network. Such systems, which typically predict graphemes or words, simplify the recognition process since they remove the need for a separate expert-curated pronunciation lexicon to map from phoneme-based units to words. However, there has been little previous work comparing phoneme-based versus grapheme-based sub-word units in the end-to-end modeling framework, to determine whether the gains from such approaches are primarily due to the new probabilistic model, or from the joint learning of the various components with grapheme-based units. In this work, we conduct detailed experiments which are aimed at quantifying the value of phoneme-based pronunciation lexica in the context of end-to-end models. We examine phoneme-based end-to-end models, which are contrasted against grapheme-based ones on a large vocabulary English Voice-search task, where we find that graphemes do indeed outperform phonemes. We also compare grapheme and phoneme-based approaches on a multi-dialect English task, which once again confirm the superiority of graphemes, greatly simplifying the system for recognizing multiple dialects.
Minimum Word Error Rate Training for Attention-based Sequence-to-Sequence Models
Dec 05, 2017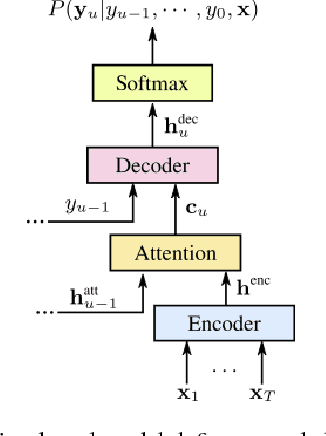
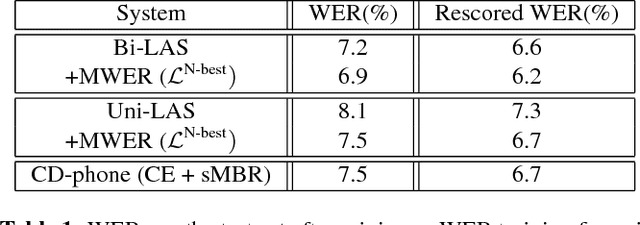

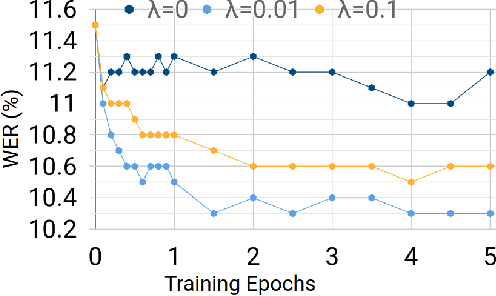
Sequence-to-sequence models, such as attention-based models in automatic speech recognition (ASR), are typically trained to optimize the cross-entropy criterion which corresponds to improving the log-likelihood of the data. However, system performance is usually measured in terms of word error rate (WER), not log-likelihood. Traditional ASR systems benefit from discriminative sequence training which optimizes criteria such as the state-level minimum Bayes risk (sMBR) which are more closely related to WER. In the present work, we explore techniques to train attention-based models to directly minimize expected word error rate. We consider two loss functions which approximate the expected number of word errors: either by sampling from the model, or by using N-best lists of decoded hypotheses, which we find to be more effective than the sampling-based method. In experimental evaluations, we find that the proposed training procedure improves performance by up to 8.2% relative to the baseline system. This allows us to train grapheme-based, uni-directional attention-based models which match the performance of a traditional, state-of-the-art, discriminative sequence-trained system on a mobile voice-search task.
Improving the Performance of Online Neural Transducer Models
Dec 05, 2017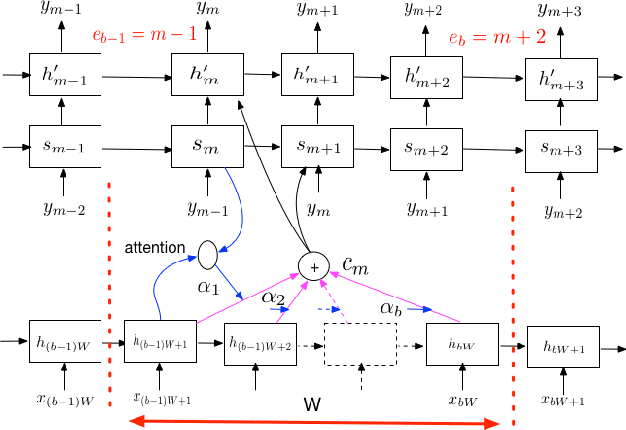
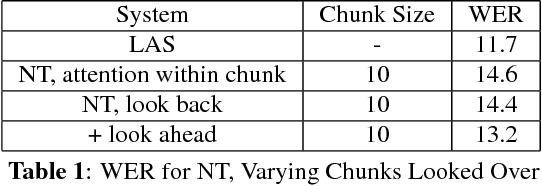
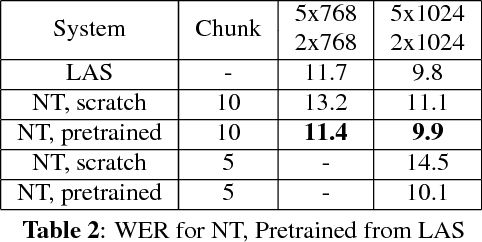
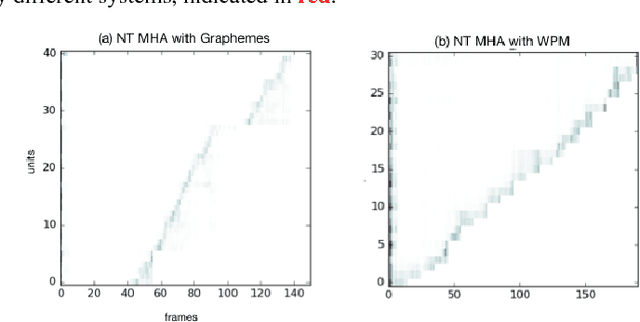
Having a sequence-to-sequence model which can operate in an online fashion is important for streaming applications such as Voice Search. Neural transducer is a streaming sequence-to-sequence model, but has shown a significant degradation in performance compared to non-streaming models such as Listen, Attend and Spell (LAS). In this paper, we present various improvements to NT. Specifically, we look at increasing the window over which NT computes attention, mainly by looking backwards in time so the model still remains online. In addition, we explore initializing a NT model from a LAS-trained model so that it is guided with a better alignment. Finally, we explore including stronger language models such as using wordpiece models, and applying an external LM during the beam search. On a Voice Search task, we find with these improvements we can get NT to match the performance of LAS.
Adversarial Evaluation of Dialogue Models
Jan 27, 2017

The recent application of RNN encoder-decoder models has resulted in substantial progress in fully data-driven dialogue systems, but evaluation remains a challenge. An adversarial loss could be a way to directly evaluate the extent to which generated dialogue responses sound like they came from a human. This could reduce the need for human evaluation, while more directly evaluating on a generative task. In this work, we investigate this idea by training an RNN to discriminate a dialogue model's samples from human-generated samples. Although we find some evidence this setup could be viable, we also note that many issues remain in its practical application. We discuss both aspects and conclude that future work is warranted.
Smart Reply: Automated Response Suggestion for Email
Jun 15, 2016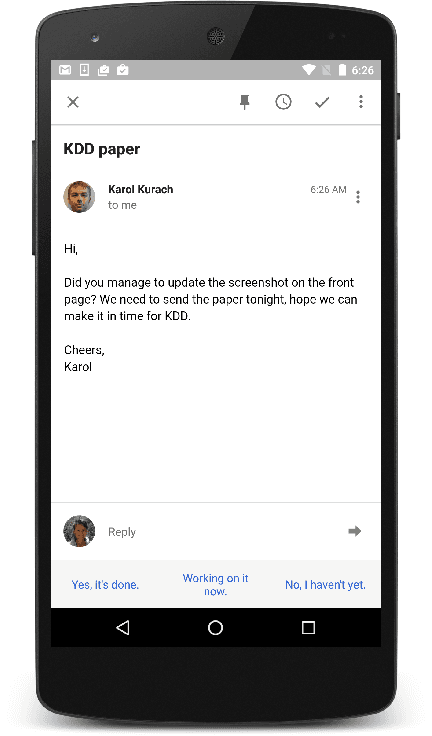
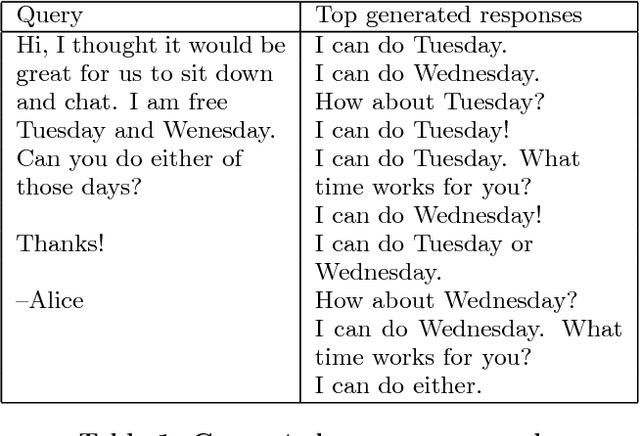
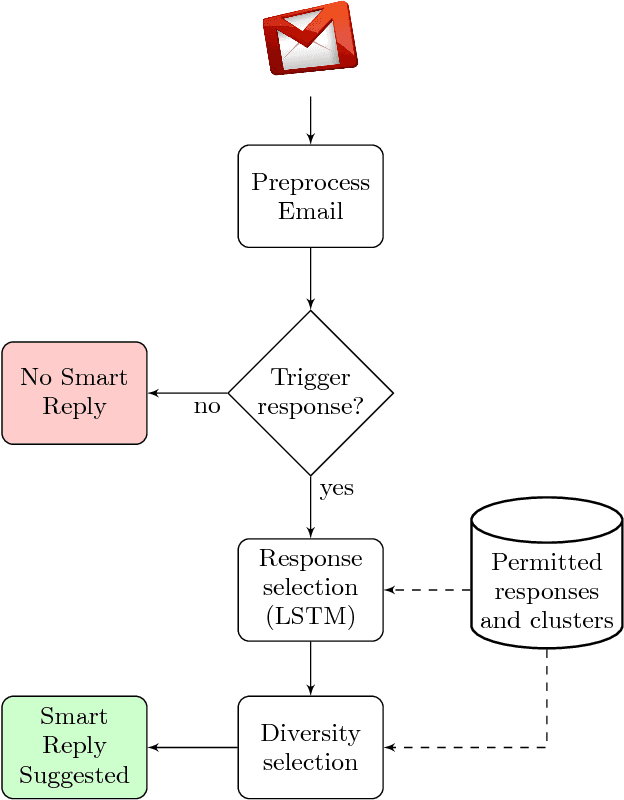

In this paper we propose and investigate a novel end-to-end method for automatically generating short email responses, called Smart Reply. It generates semantically diverse suggestions that can be used as complete email responses with just one tap on mobile. The system is currently used in Inbox by Gmail and is responsible for assisting with 10% of all mobile responses. It is designed to work at very high throughput and process hundreds of millions of messages daily. The system exploits state-of-the-art, large-scale deep learning. We describe the architecture of the system as well as the challenges that we faced while building it, like response diversity and scalability. We also introduce a new method for semantic clustering of user-generated content that requires only a modest amount of explicitly labeled data.