 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
Feb 24, 2021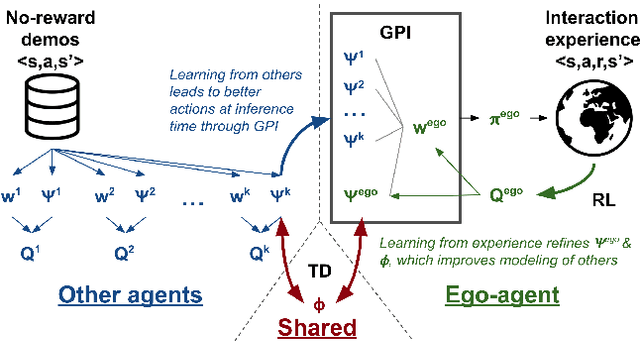
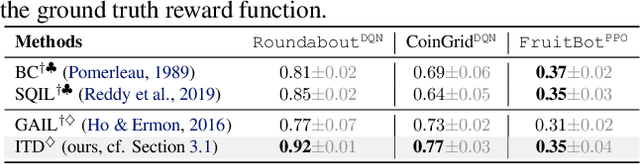

We study reinforcement learning (RL) with no-reward demonstrations, a setting in which an RL agent has access to additional data from the interaction of other agents with the same environment. However, it has no access to the rewards or goals of these agents, and their objectives and levels of expertise may vary widely. These assumptions are common in multi-agent settings, such as autonomous driving. To effectively use this data, we turn to the framework of successor features. This allows us to disentangle shared features and dynamics of the environment from agent-specific rewards and policies. We propose a multi-task inverse reinforcement learning (IRL) algorithm, called \emph{inverse temporal difference learning} (ITD), that learns shared state features, alongside per-agent successor features and preference vectors, purely from demonstrations without reward labels. We further show how to seamlessly integrate ITD with learning from online environment interactions, arriving at a novel algorithm for reinforcement learning with demonstrations, called $\Psi \Phi$-learning (pronounced `Sci-Fi'). We provide empirical evidence for the effectiveness of $\Psi \Phi$-learning as a method for improving RL, IRL, imitation, and few-shot transfer, and derive worst-case bounds for its performance in zero-shot transfer to new tasks.
Can Autonomous Vehicles Identify, Recover From, and Adapt to Distribution Shifts?
Jun 26, 2020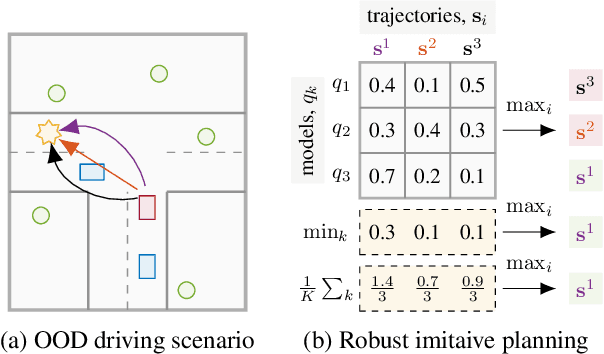


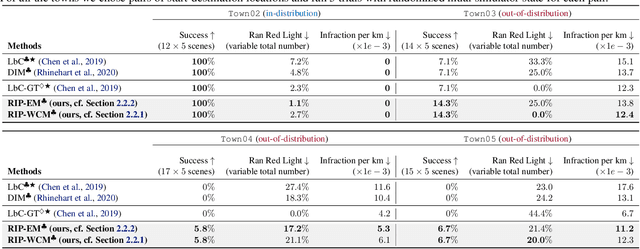
Out-of-training-distribution (OOD) scenarios are a common challenge of learning agents at deployment, typically leading to arbitrary deductions and poorly-informed decisions. In principle, detection of and adaptation to OOD scenes can mitigate their adverse effects. In this paper, we highlight the limitations of current approaches to novel driving scenes and propose an epistemic uncertainty-aware planning method, called \emph{robust imitative planning} (RIP). Our method can detect and recover from some distribution shifts, reducing the overconfident and catastrophic extrapolations in OOD scenes. If the model's uncertainty is too great to suggest a safe course of action, the model can instead query the expert driver for feedback, enabling sample-efficient online adaptation, a variant of our method we term \emph{adaptive robust imitative planning} (AdaRIP). Our methods outperform current state-of-the-art approaches in the nuScenes \emph{prediction} challenge, but since no benchmark evaluating OOD detection and adaption currently exists to assess \emph{control}, we introduce an autonomous car novel-scene benchmark, \texttt{CARNOVEL}, to evaluate the robustness of driving agents to a suite of tasks with distribution shifts.
Uncertainty Evaluation Metric for Brain Tumour Segmentation
May 28, 2020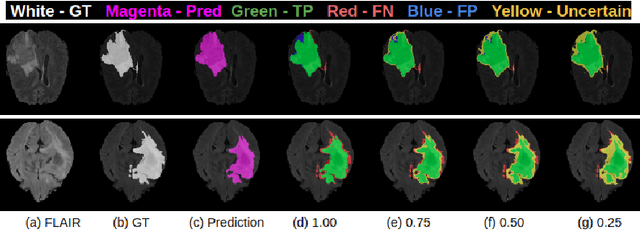
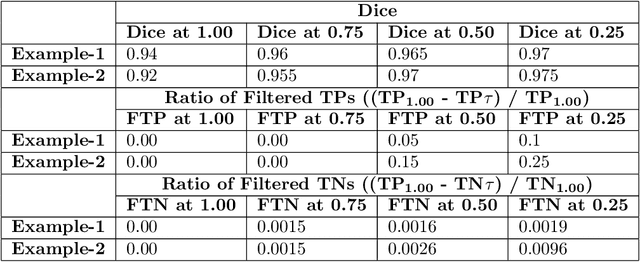
In this paper, we develop a metric designed to assess and rank uncertainty measures for the task of brain tumour sub-tissue segmentation in the BraTS 2019 sub-challenge on uncertainty quantification. The metric is designed to: (1) reward uncertainty measures where high confidence is assigned to correct assertions, and where incorrect assertions are assigned low confidence and (2) penalize measures that have higher percentages of under-confident correct assertions. Here, the workings of the components of the metric are explored based on a number of popular uncertainty measures evaluated on the BraTS 2019 dataset.
Invariant Causal Prediction for Block MDPs
Mar 12, 2020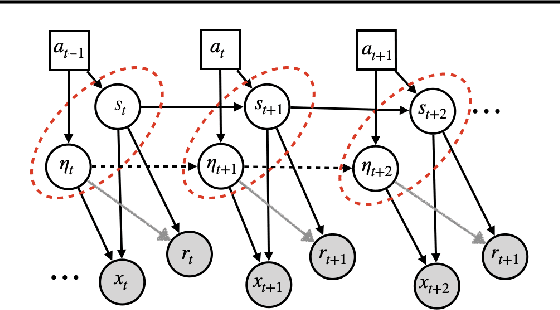
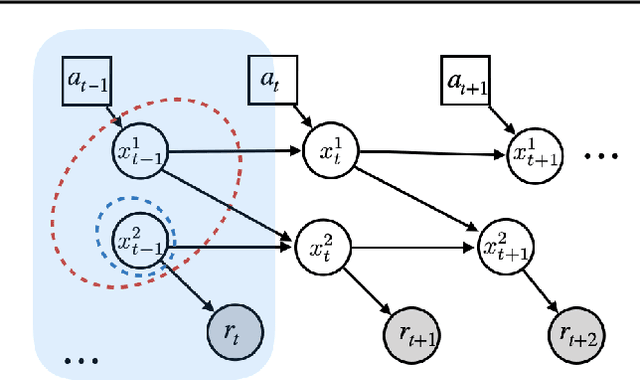
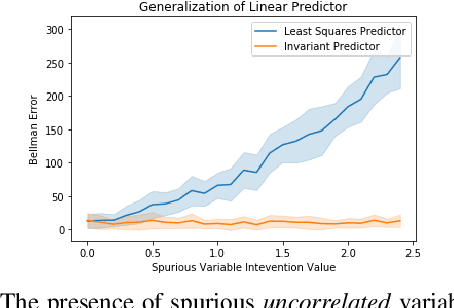
Generalization across environments is critical to the successful application of reinforcement learning algorithms to real-world challenges. In this paper, we consider the problem of learning abstractions that generalize in block MDPs, families of environments with a shared latent state space and dynamics structure over that latent space, but varying observations. We leverage tools from causal inference to propose a method of invariant prediction to learn model-irrelevance state abstractions (MISA) that generalize to novel observations in the multi-environment setting. We prove that for certain classes of environments, this approach outputs with high probability a state abstraction corresponding to the causal feature set with respect to the return. We further provide more general bounds on model error and generalization error in the multi-environment setting, in the process showing a connection between causal variable selection and the state abstraction framework for MDPs. We give empirical evidence that our methods work in both linear and nonlinear settings, attaining improved generalization over single- and multi-task baselines.
A Systematic Comparison of Bayesian Deep Learning Robustness in Diabetic Retinopathy Tasks
Dec 22, 2019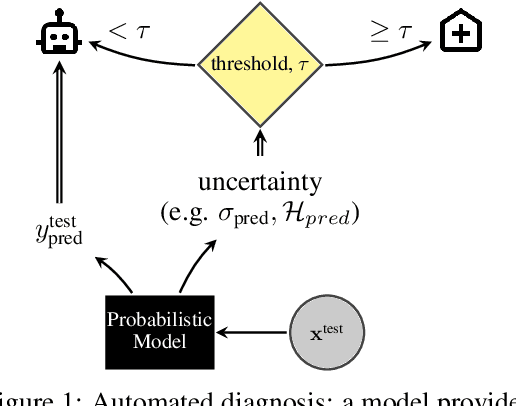
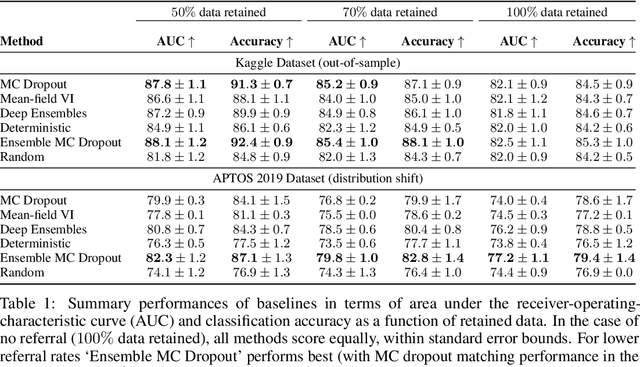
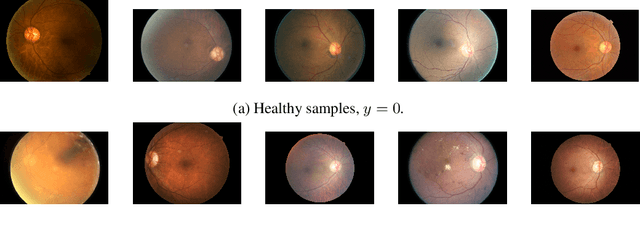
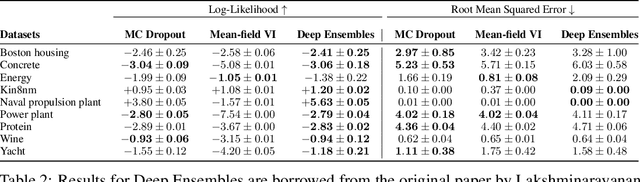
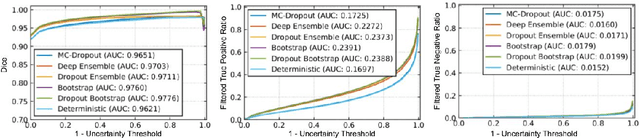
Evaluation of Bayesian deep learning (BDL) methods is challenging. We often seek to evaluate the methods' robustness and scalability, assessing whether new tools give `better' uncertainty estimates than old ones. These evaluations are paramount for practitioners when choosing BDL tools on-top of which they build their applications. Current popular evaluations of BDL methods, such as the UCI experiments, are lacking: Methods that excel with these experiments often fail when used in application such as medical or automotive, suggesting a pertinent need for new benchmarks in the field. We propose a new BDL benchmark with a diverse set of tasks, inspired by a real-world medical imaging application on \emph{diabetic retinopathy diagnosis}. Visual inputs (512x512 RGB images of retinas) are considered, where model uncertainty is used for medical pre-screening---i.e. to refer patients to an expert when model diagnosis is uncertain. Methods are then ranked according to metrics derived from expert-domain to reflect real-world use of model uncertainty in automated diagnosis. We develop multiple tasks that fall under this application, including out-of-distribution detection and robustness to distribution shift. We then perform a systematic comparison of well-tuned BDL techniques on the various tasks. From our comparison we conclude that some current techniques which solve benchmarks such as UCI `overfit' their uncertainty to the dataset---when evaluated on our benchmark these underperform in comparison to simpler baselines. The code for the benchmark, its baselines, and a simple API for evaluating new BDL tools are made available at https://github.com/oatml/bdl-benchmarks.
Reinforcement Learning for Portfolio Management
Sep 12, 2019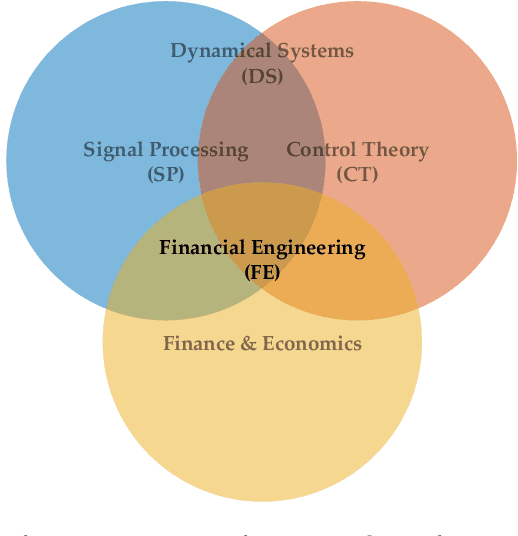
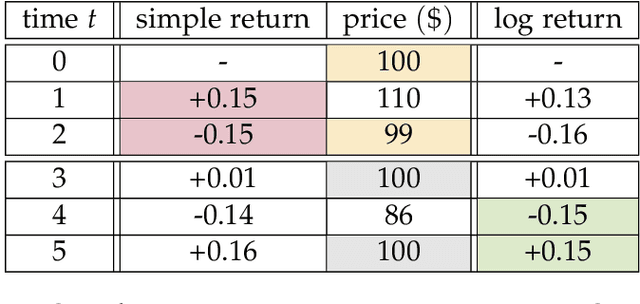
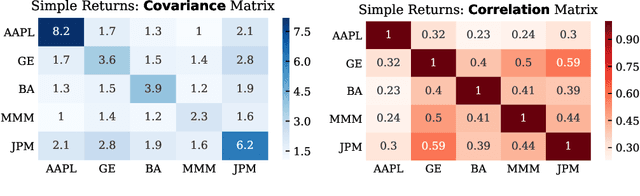
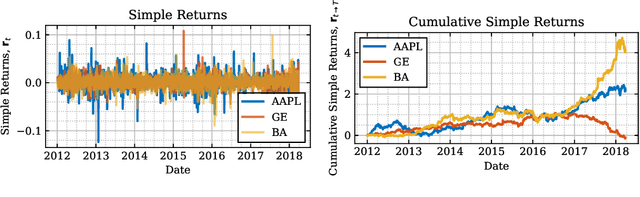
In this thesis, we develop a comprehensive account of the expressive power, modelling efficiency, and performance advantages of so-called trading agents (i.e., Deep Soft Recurrent Q-Network (DSRQN) and Mixture of Score Machines (MSM)), based on both traditional system identification (model-based approach) as well as on context-independent agents (model-free approach). The analysis provides conclusive support for the ability of model-free reinforcement learning methods to act as universal trading agents, which are not only capable of reducing the computational and memory complexity (owing to their linear scaling with the size of the universe), but also serve as generalizing strategies across assets and markets, regardless of the trading universe on which they have been trained. The relatively low volume of daily returns in financial market data is addressed via data augmentation (a generative approach) and a choice of pre-training strategies, both of which are validated against current state-of-the-art models. For rigour, a risk-sensitive framework which includes transaction costs is considered, and its performance advantages are demonstrated in a variety of scenarios, from synthetic time-series (sinusoidal, sawtooth and chirp waves), simulated market series (surrogate data based), through to real market data (S\&P 500 and EURO STOXX 50). The analysis and simulations confirm the superiority of universal model-free reinforcement learning agents over current portfolio management model in asset allocation strategies, with the achieved performance advantage of as much as 9.2\% in annualized cumulative returns and 13.4\% in annualized Sharpe Ratio.
Generalizing from a few environments in safety-critical reinforcement learning
Jul 02, 2019


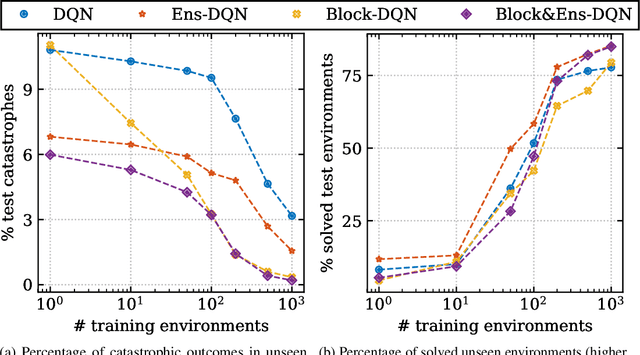
Before deploying autonomous agents in the real world, we need to be confident they will perform safely in novel situations. Ideally, we would expose agents to a very wide range of situations during training, allowing them to learn about every possible danger, but this is often impractical. This paper investigates safety and generalization from a limited number of training environments in deep reinforcement learning (RL). We find RL algorithms can fail dangerously on unseen test environments even when performing perfectly on training environments. Firstly, in a gridworld setting, we show that catastrophes can be significantly reduced with simple modifications, including ensemble model averaging and the use of a blocking classifier. In the more challenging CoinRun environment we find similar methods do not significantly reduce catastrophes. However, we do find that the uncertainty information from the ensemble is useful for predicting whether a catastrophe will occur within a few steps and hence whether human intervention should be requested.
Towards Inverse Reinforcement Learning for Limit Order Book Dynamics
Jun 11, 2019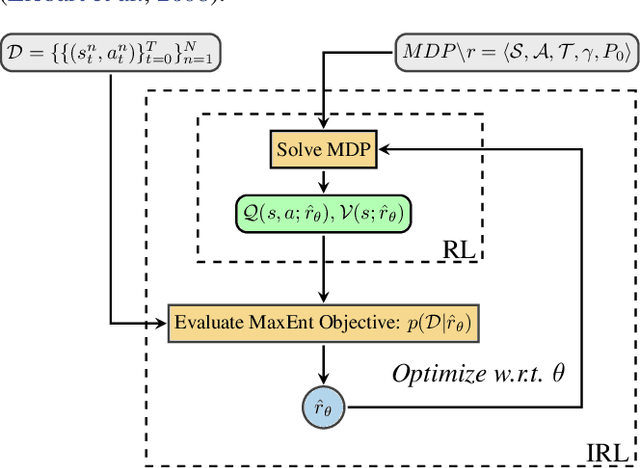
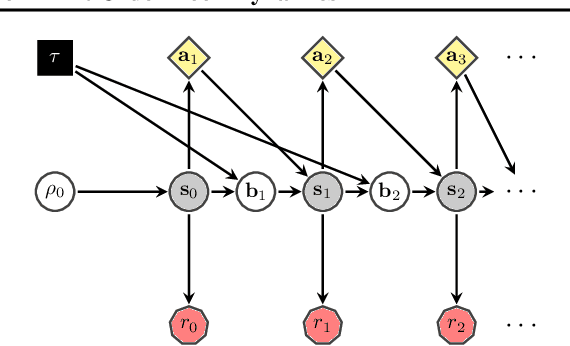
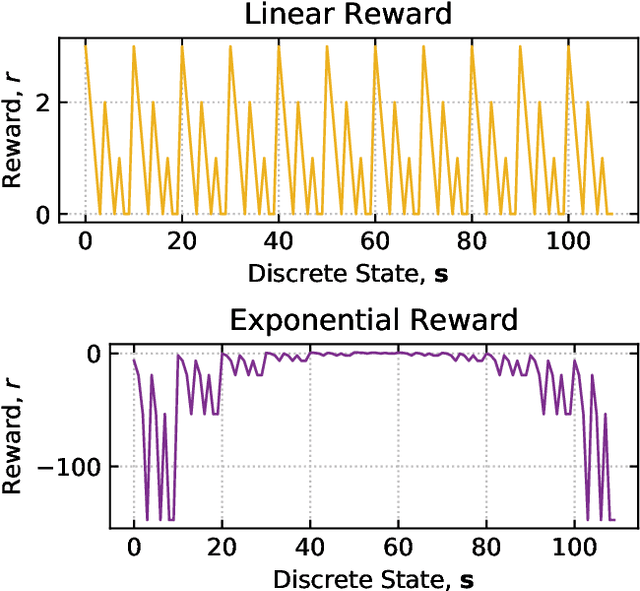
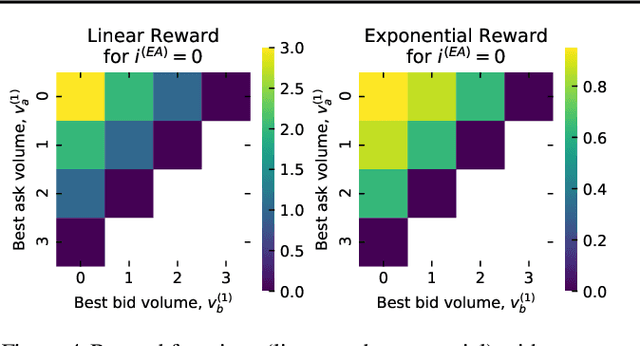
Multi-agent learning is a promising method to simulate aggregate competitive behaviour in finance. Learning expert agents' reward functions through their external demonstrations is hence particularly relevant for subsequent design of realistic agent-based simulations. Inverse Reinforcement Learning (IRL) aims at acquiring such reward functions through inference, allowing to generalize the resulting policy to states not observed in the past. This paper investigates whether IRL can infer such rewards from agents within real financial stochastic environments: limit order books (LOB). We introduce a simple one-level LOB, where the interactions of a number of stochastic agents and an expert trading agent are modelled as a Markov decision process. We consider two cases for the expert's reward: either a simple linear function of state features; or a complex, more realistic non-linear function. Given the expert agent's demonstrations, we attempt to discover their strategy by modelling their latent reward function using linear and Gaussian process (GP) regressors from previous literature, and our own approach through Bayesian neural networks (BNN). While the three methods can learn the linear case, only the GP-based and our proposed BNN methods are able to discover the non-linear reward case. Our BNN IRL algorithm outperforms the other two approaches as the number of samples increases. These results illustrate that complex behaviours, induced by non-linear reward functions amid agent-based stochastic scenarios, can be deduced through inference, encouraging the use of inverse reinforcement learning for opponent-modelling in multi-agent systems.