 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQaNER: Prompting Question Answering Models for Few-shot Named Entity Recognition
Mar 04, 2022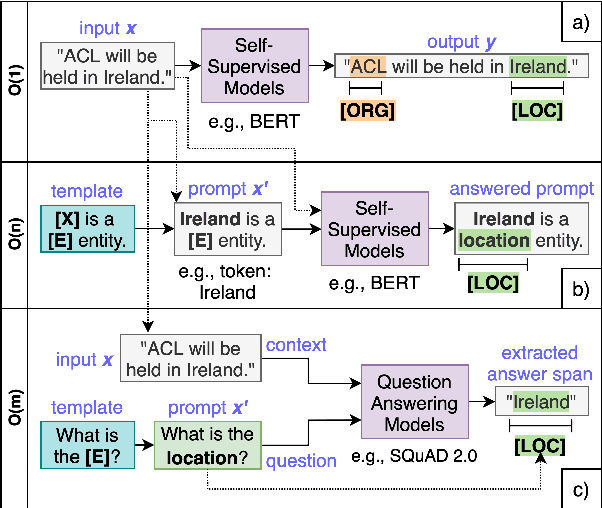

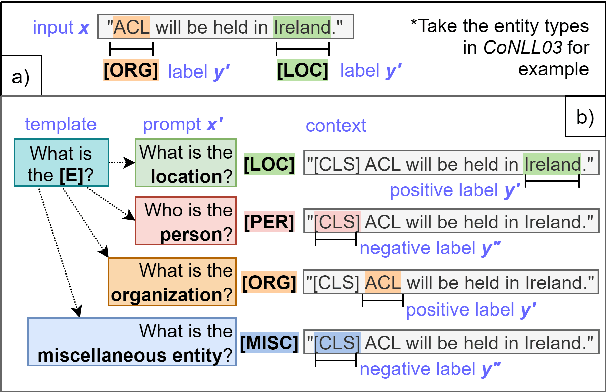
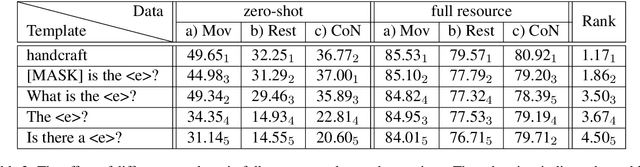
Recently, prompt-based learning for pre-trained language models has succeeded in few-shot Named Entity Recognition (NER) by exploiting prompts as task guidance to increase label efficiency. However, previous prompt-based methods for few-shot NER have limitations such as a higher computational complexity, poor zero-shot ability, requiring manual prompt engineering, or lack of prompt robustness. In this work, we address these shortcomings by proposing a new prompt-based learning NER method with Question Answering (QA), called QaNER. Our approach includes 1) a refined strategy for converting NER problems into the QA formulation; 2) NER prompt generation for QA models; 3) prompt-based tuning with QA models on a few annotated NER examples; 4) zero-shot NER by prompting the QA model. Comparing the proposed approach with previous methods, QaNER is faster at inference, insensitive to the prompt quality, and robust to hyper-parameters, as well as demonstrating significantly better low-resource performance and zero-shot capability.
Don't speak too fast: The impact of data bias on self-supervised speech models
Oct 15, 2021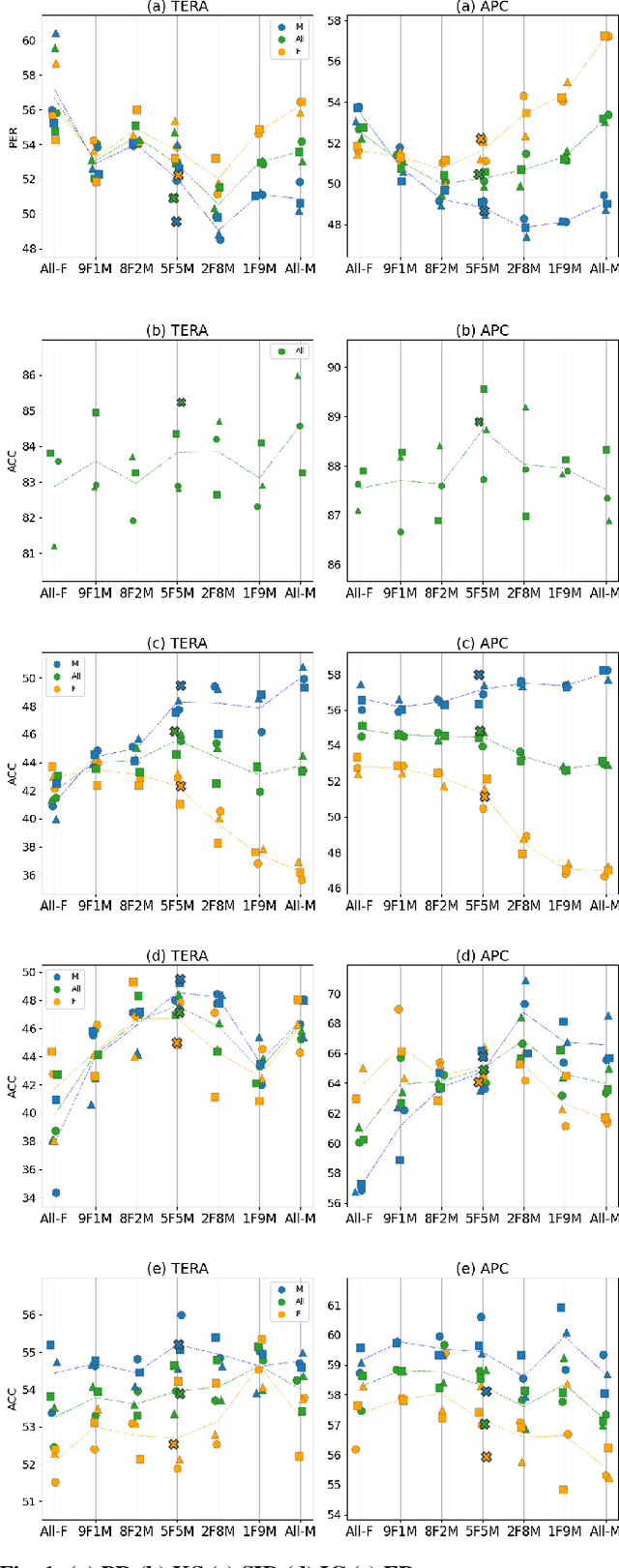
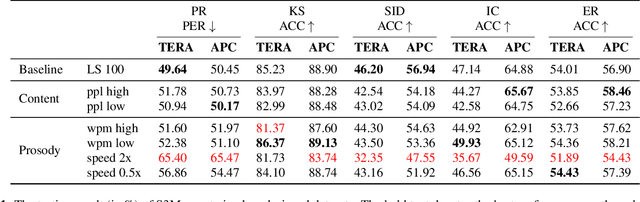
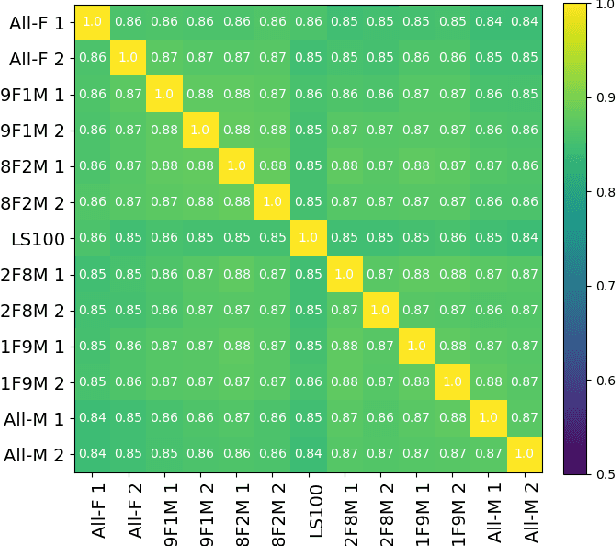
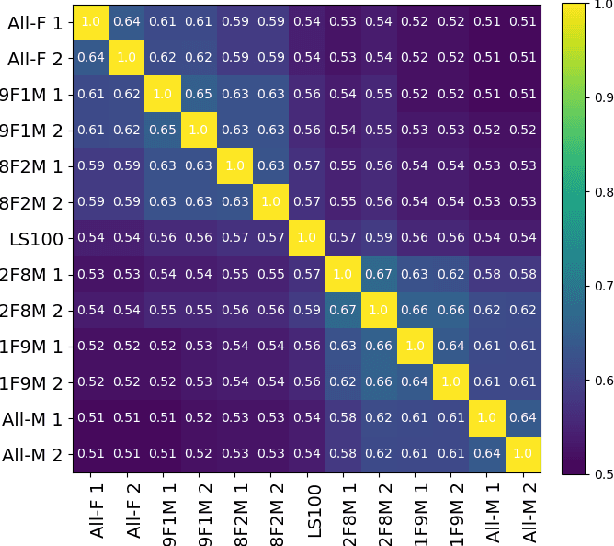
Self-supervised Speech Models (S3Ms) have been proven successful in many speech downstream tasks, like ASR. However, how pre-training data affects S3Ms' downstream behavior remains an unexplored issue. In this paper, we study how pre-training data affects S3Ms by pre-training models on biased datasets targeting different factors of speech, including gender, content, and prosody, and evaluate these pre-trained S3Ms on selected downstream tasks in SUPERB Benchmark. Our experiments show that S3Ms have tolerance toward gender bias. Moreover, we find that the content of speech has little impact on the performance of S3Ms across downstream tasks, but S3Ms do show a preference toward a slower speech rate.
Improving the Adversarial Robustness for Speaker Verification by Self-Supervised Learning
Jun 14, 2021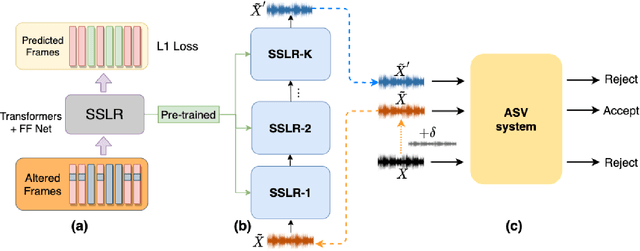
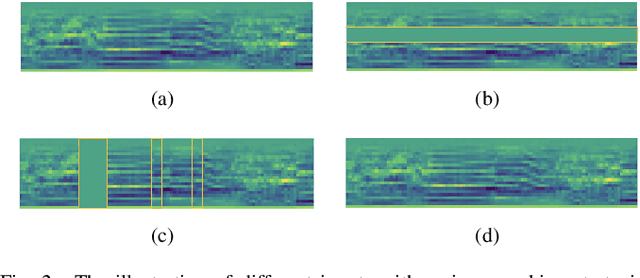
Previous works have shown that automatic speaker verification (ASV) is seriously vulnerable to malicious spoofing attacks, such as replay, synthetic speech, and recently emerged adversarial attacks. Great efforts have been dedicated to defending ASV against replay and synthetic speech; however, only a few approaches have been explored to deal with adversarial attacks. All the existing approaches to tackle adversarial attacks for ASV require the knowledge for adversarial samples generation, but it is impractical for defenders to know the exact attack algorithms that are applied by the in-the-wild attackers. This work is among the first to perform adversarial defense for ASV without knowing the specific attack algorithms. Inspired by self-supervised learning models (SSLMs) that possess the merits of alleviating the superficial noise in the inputs and reconstructing clean samples from the interrupted ones, this work regards adversarial perturbations as one kind of noise and conducts adversarial defense for ASV by SSLMs. Specifically, we propose to perform adversarial defense from two perspectives: 1) adversarial perturbation purification and 2) adversarial perturbation detection. Experimental results show that our detection module effectively shields the ASV by detecting adversarial samples with an accuracy of around 80%. Moreover, since there is no common metric for evaluating the adversarial defense performance for ASV, this work also formalizes evaluation metrics for adversarial defense considering both purification and detection based approaches into account. We sincerely encourage future works to benchmark their approaches based on the proposed evaluation framework.
SUPERB: Speech processing Universal PERformance Benchmark
May 03, 2021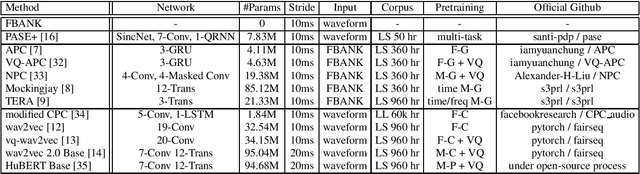
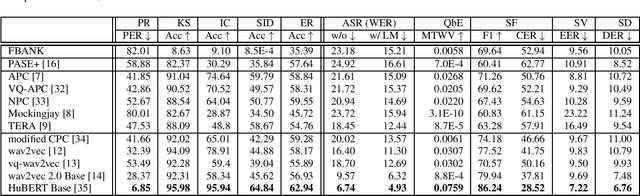
Self-supervised learning (SSL) has proven vital for advancing research in natural language processing (NLP) and computer vision (CV). The paradigm pretrains a shared model on large volumes of unlabeled data and achieves state-of-the-art (SOTA) for various tasks with minimal adaptation. However, the speech processing community lacks a similar setup to systematically explore the paradigm. To bridge this gap, we introduce Speech processing Universal PERformance Benchmark (SUPERB). SUPERB is a leaderboard to benchmark the performance of a shared model across a wide range of speech processing tasks with minimal architecture changes and labeled data. Among multiple usages of the shared model, we especially focus on extracting the representation learned from SSL due to its preferable re-usability. We present a simple framework to solve SUPERB tasks by learning task-specialized lightweight prediction heads on top of the frozen shared model. Our results demonstrate that the framework is promising as SSL representations show competitive generalizability and accessibility across SUPERB tasks. We release SUPERB as a challenge with a leaderboard and a benchmark toolkit to fuel the research in representation learning and general speech processing.
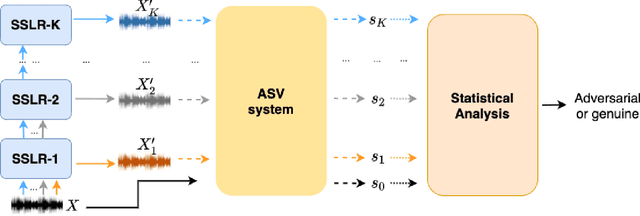
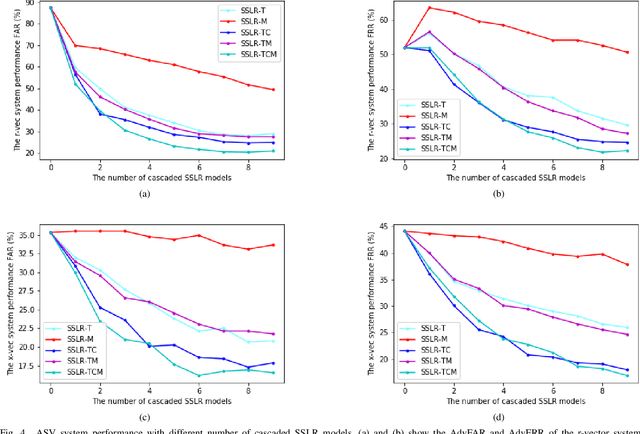
Adversarial defense for automatic speaker verification by cascaded self-supervised learning models
Feb 14, 2021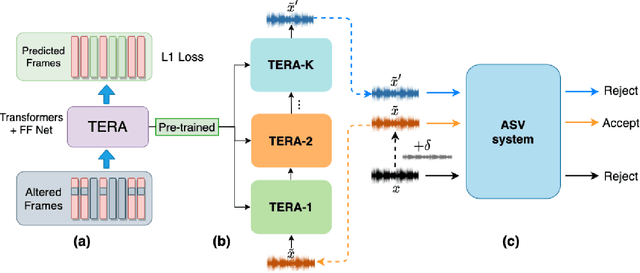
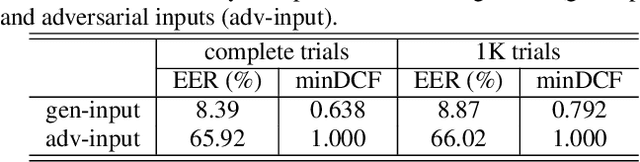
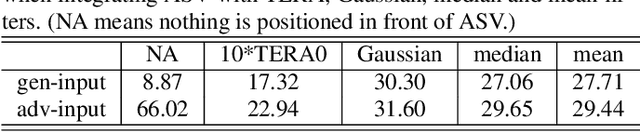
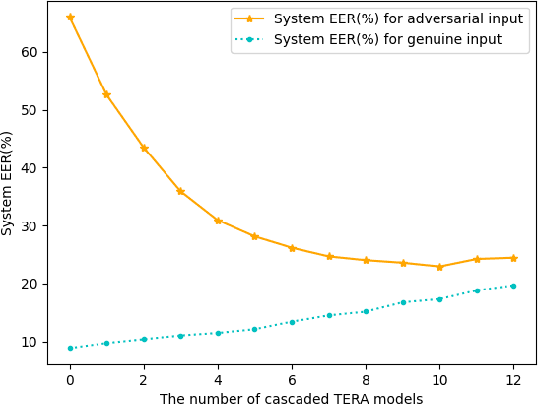
Automatic speaker verification (ASV) is one of the core technologies in biometric identification. With the ubiquitous usage of ASV systems in safety-critical applications, more and more malicious attackers attempt to launch adversarial attacks at ASV systems. In the midst of the arms race between attack and defense in ASV, how to effectively improve the robustness of ASV against adversarial attacks remains an open question. We note that the self-supervised learning models possess the ability to mitigate superficial perturbations in the input after pretraining. Hence, with the goal of effective defense in ASV against adversarial attacks, we propose a standard and attack-agnostic method based on cascaded self-supervised learning models to purify the adversarial perturbations. Experimental results demonstrate that the proposed method achieves effective defense performance and can successfully counter adversarial attacks in scenarios where attackers may either be aware or unaware of the self-supervised learning models.
TERA: Self-Supervised Learning of Transformer Encoder Representation for Speech
Jul 12, 2020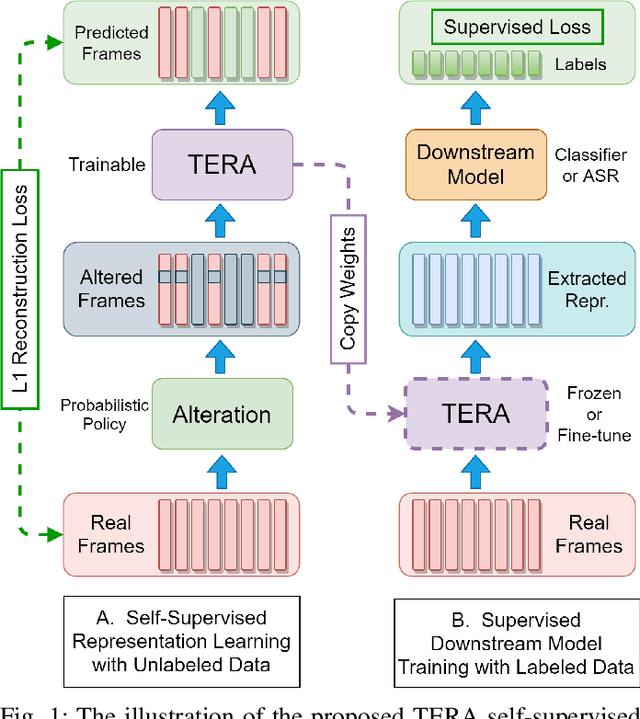
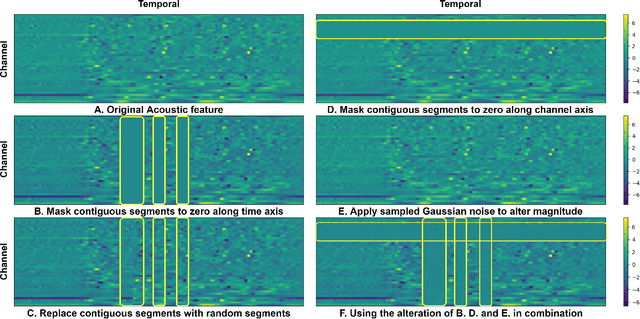
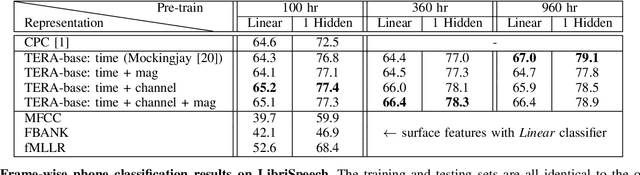
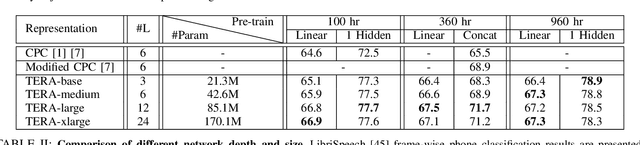
We introduce a self-supervised speech pre-training method called TERA, which stands for Transformer Encoder Representations from Alteration. Recent approaches often learn through the formulation of a single auxiliary task like contrastive prediction, autoregressive prediction, or masked reconstruction. Unlike previous approaches, we use a multi-target auxiliary task to pre-train Transformer Encoders on a large amount of unlabeled speech. The model learns through the reconstruction of acoustic frames from its altered counterpart, where we use a stochastic policy to alter along three dimensions: temporal, channel, and magnitude. TERA can be used to extract speech representations or fine-tune with downstream models. We evaluate TERA on several downstream tasks, including phoneme classification, speaker recognition, and speech recognition. TERA achieved strong performance on these tasks by improving upon surface features and outperforming previous methods. In our experiments, we show that through alteration along different dimensions, the model learns to encode distinct aspects of speech. We explore different knowledge transfer methods to incorporate the pre-trained model with downstream models. Furthermore, we show that the proposed method can be easily transferred to another dataset not used in pre-training.
Understanding Self-Attention of Self-Supervised Audio Transformers
Jun 05, 2020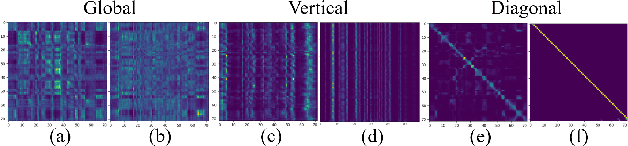
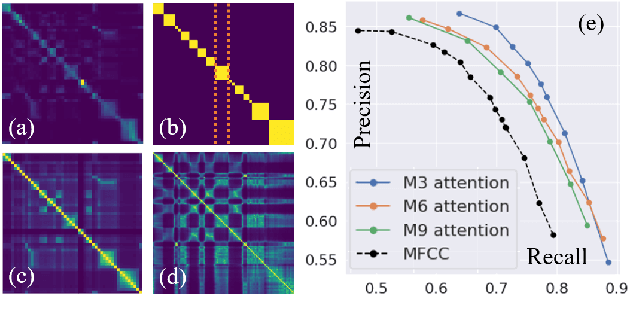
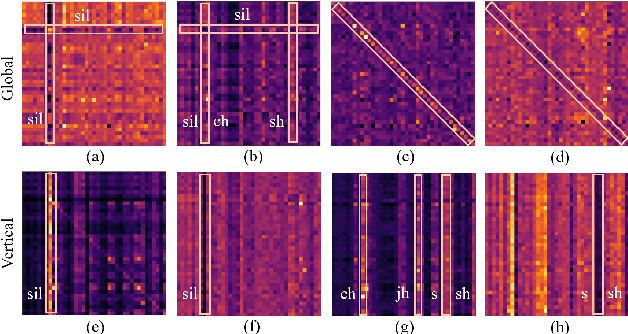
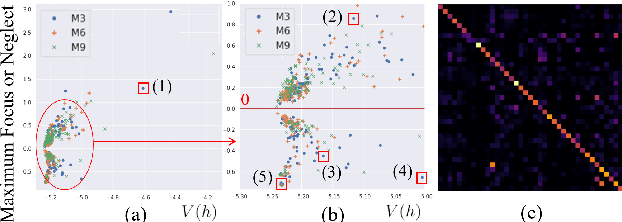
Self-supervised Audio Transformers (SAT) enable great success in many downstream speech applications like ASR, but how they work has not been widely explored yet. In this work, we present multiple strategies for the analysis of attention mechanisms in SAT. We categorize attentions into explainable categories, where we discover each category possesses its own unique functionality. We provide a visualization tool for understanding multi-head self-attention, importance ranking strategies for identifying critical attention, and attention refinement techniques to improve model performance.
Defense for Black-box Attacks on Anti-spoofing Models by Self-Supervised Learning
Jun 05, 2020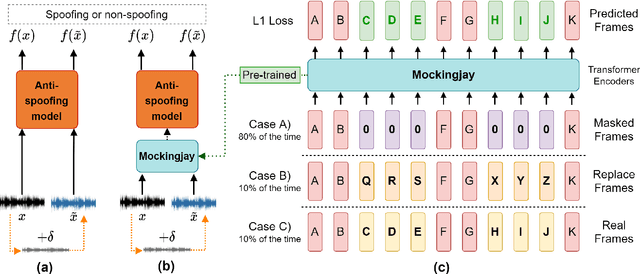
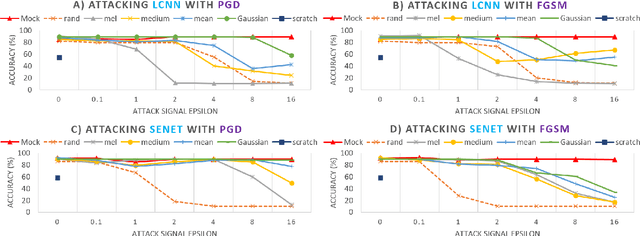
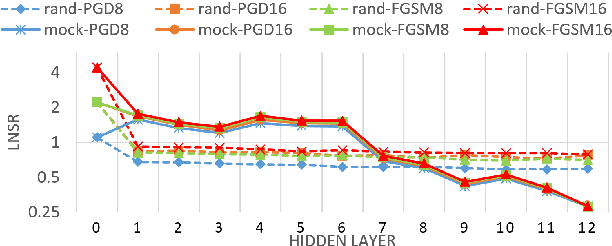
High-performance anti-spoofing models for automatic speaker verification (ASV), have been widely used to protect ASV by identifying and filtering spoofing audio that is deliberately generated by text-to-speech, voice conversion, audio replay, etc. However, it has been shown that high-performance anti-spoofing models are vulnerable to adversarial attacks. Adversarial attacks, that are indistinguishable from original data but result in the incorrect predictions, are dangerous for anti-spoofing models and not in dispute we should detect them at any cost. To explore this issue, we proposed to employ Mockingjay, a self-supervised learning based model, to protect anti-spoofing models against adversarial attacks in the black-box scenario. Self-supervised learning models are effective in improving downstream task performance like phone classification or ASR. However, their effect in defense for adversarial attacks has not been explored yet. In this work, we explore the robustness of self-supervised learned high-level representations by using them in the defense against adversarial attacks. A layerwise noise to signal ratio (LNSR) is proposed to quantize and measure the effectiveness of deep models in countering adversarial noise. Experimental results on the ASVspoof 2019 dataset demonstrate that high-level representations extracted by Mockingjay can prevent the transferability of adversarial examples, and successfully counter black-box attacks.
Towards Robust Neural Vocoding for Speech Generation: A Survey
Dec 05, 2019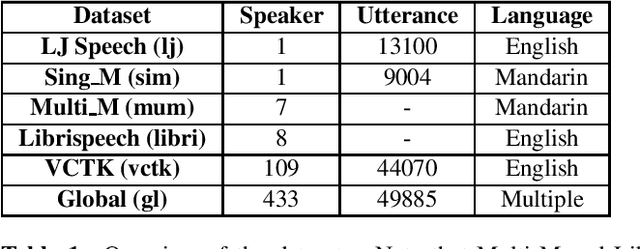

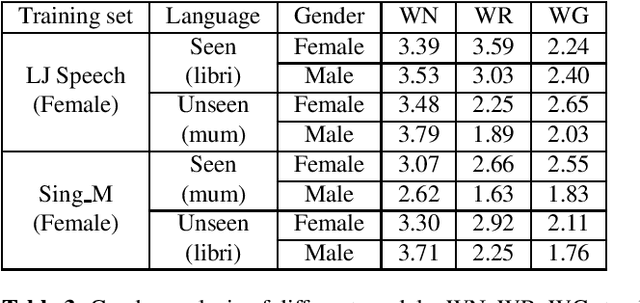
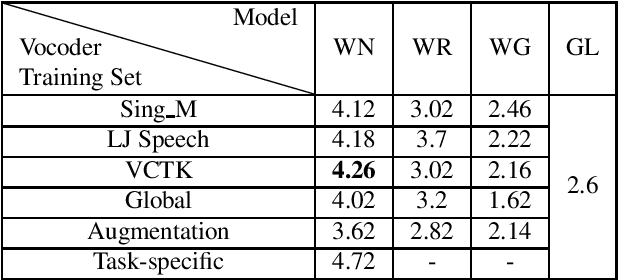
Recently, neural vocoders have been widely used in speech synthesis tasks, including text-to-speech and voice conversion. However, in the encounter of data distribution mismatch between training and inference, neural vocoders trained on real data often degrade in voice quality for unseen scenarios. In this paper, we train three commonly used neural vocoders, including WaveNet, WaveRNN, and WaveGlow, alternately on five different datasets. To study the robustness of neural vocoders, we evaluate the models using acoustic features from seen/unseen speakers, seen/unseen languages, a text-to-speech model, and a voice conversion model. In this work, we found that WaveNet is more robust than WaveRNN, especially in the face of inconsistency between training and testing data. Through our experiments, we show that WaveNet is more suitable for text-to-speech models, and WaveRNN more suitable for voice conversion applications. Furthermore, we present results with considerable reference value of subjective human evaluation for future studies.
Mockingjay: Unsupervised Speech Representation Learning with Deep Bidirectional Transformer Encoders
Oct 25, 2019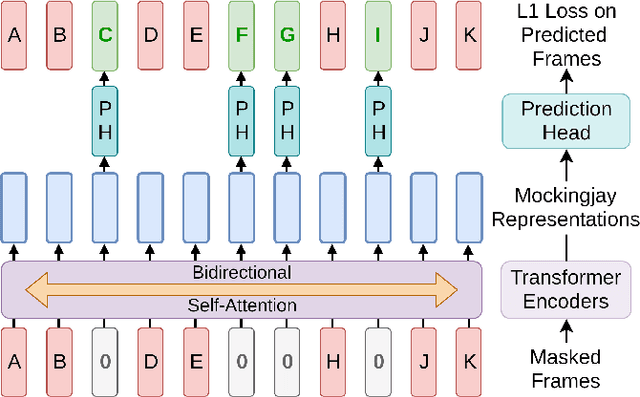
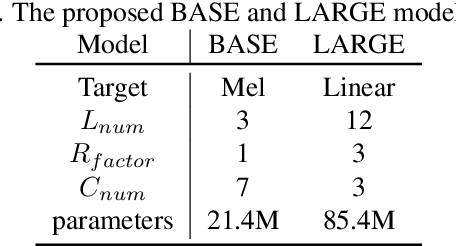
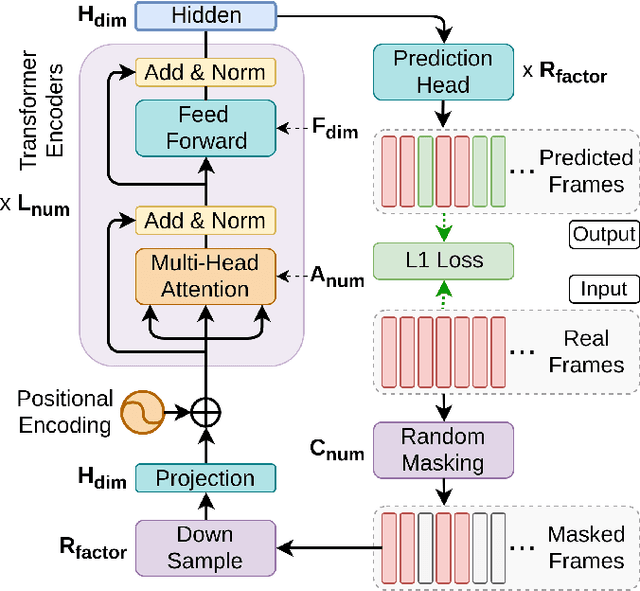
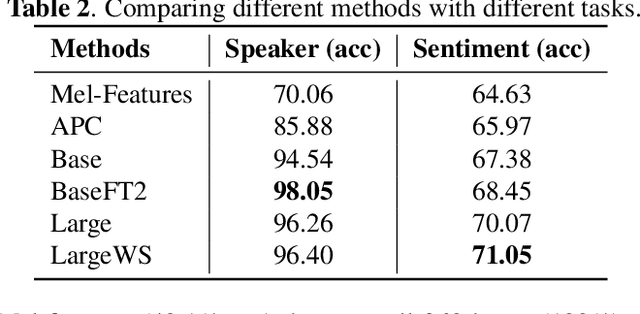
We present Mockingjay as a new speech representation learning approach, where bidirectional Transformer encoders are pre-trained on a large amount of unlabeled speech. Previous speech representation methods learn through conditioning on past frames and predicting information about future frames. Whereas Mockingjay is designed to predict the current frame through jointly conditioning on both past and future contexts. The Mockingjay representation improves performance for a wide range of downstream tasks, including phoneme classification, speaker recognition, and sentiment classification on spoken content, while outperforming other approaches. Mockingjay is empirically powerful and can be fine-tuned with downstream models, with only 2 epochs we further improve performance dramatically. In a low resource setting with only 0.1% of labeled data, we outperform the result of Mel-features that uses all 100% labeled data.