 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-end Tracking with a Multi-query Transformer
Oct 26, 2022



Multiple-object tracking (MOT) is a challenging task that requires simultaneous reasoning about location, appearance, and identity of the objects in the scene over time. Our aim in this paper is to move beyond tracking-by-detection approaches, that perform well on datasets where the object classes are known, to class-agnostic tracking that performs well also for unknown object classes.To this end, we make the following three contributions: first, we introduce {\em semantic detector queries} that enable an object to be localized by specifying its approximate position, or its appearance, or both; second, we use these queries within an auto-regressive framework for tracking, and propose a multi-query tracking transformer (\textit{MQT}) model for simultaneous tracking and appearance-based re-identification (reID) based on the transformer architecture with deformable attention. This formulation allows the tracker to operate in a class-agnostic manner, and the model can be trained end-to-end; finally, we demonstrate that \textit{MQT} performs competitively on standard MOT benchmarks, outperforms all baselines on generalised-MOT, and generalises well to a much harder tracking problems such as tracking any object on the TAO dataset.
A Tri-Layer Plugin to Improve Occluded Detection
Oct 18, 2022

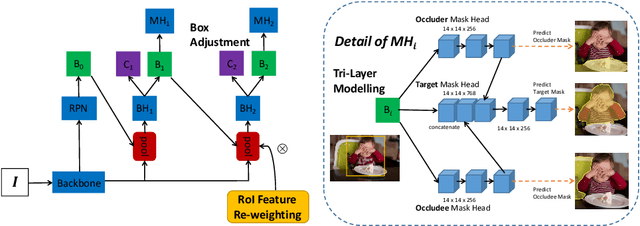
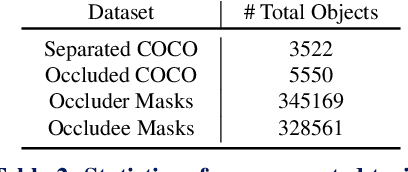
Detecting occluded objects still remains a challenge for state-of-the-art object detectors. The objective of this work is to improve the detection for such objects, and thereby improve the overall performance of a modern object detector. To this end we make the following four contributions: (1) We propose a simple 'plugin' module for the detection head of two-stage object detectors to improve the recall of partially occluded objects. The module predicts a tri-layer of segmentation masks for the target object, the occluder and the occludee, and by doing so is able to better predict the mask of the target object. (2) We propose a scalable pipeline for generating training data for the module by using amodal completion of existing object detection and instance segmentation training datasets to establish occlusion relationships. (3) We also establish a COCO evaluation dataset to measure the recall performance of partially occluded and separated objects. (4) We show that the plugin module inserted into a two-stage detector can boost the performance significantly, by only fine-tuning the detection head, and with additional improvements if the entire architecture is fine-tuned. COCO results are reported for Mask R-CNN with Swin-T or Swin-S backbones, and Cascade Mask R-CNN with a Swin-B backbone.
Sparse in Space and Time: Audio-visual Synchronisation with Trainable Selectors
Oct 13, 2022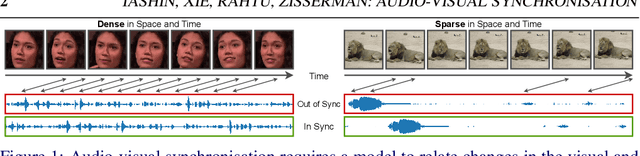

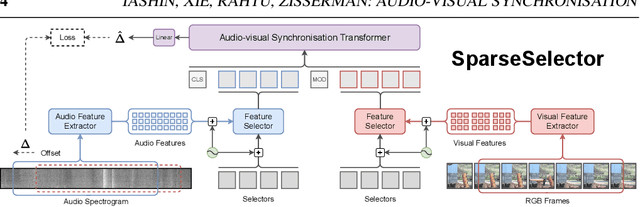
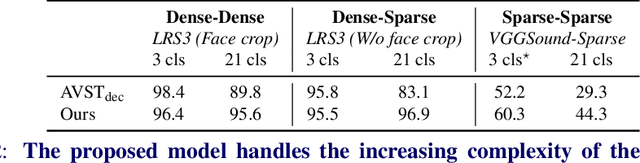
The objective of this paper is audio-visual synchronisation of general videos 'in the wild'. For such videos, the events that may be harnessed for synchronisation cues may be spatially small and may occur only infrequently during a many seconds-long video clip, i.e. the synchronisation signal is 'sparse in space and time'. This contrasts with the case of synchronising videos of talking heads, where audio-visual correspondence is dense in both time and space. We make four contributions: (i) in order to handle longer temporal sequences required for sparse synchronisation signals, we design a multi-modal transformer model that employs 'selectors' to distil the long audio and visual streams into small sequences that are then used to predict the temporal offset between streams. (ii) We identify artefacts that can arise from the compression codecs used for audio and video and can be used by audio-visual models in training to artificially solve the synchronisation task. (iii) We curate a dataset with only sparse in time and space synchronisation signals; and (iv) the effectiveness of the proposed model is shown on both dense and sparse datasets quantitatively and qualitatively. Project page: v-iashin.github.io/SparseSync
Turbo Training with Token Dropout
Oct 10, 2022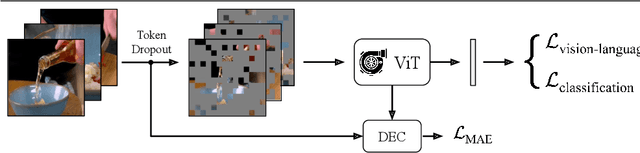
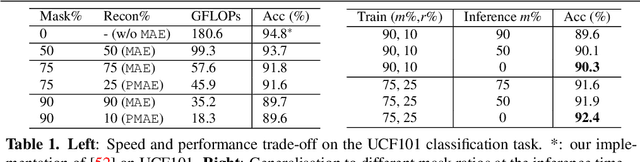
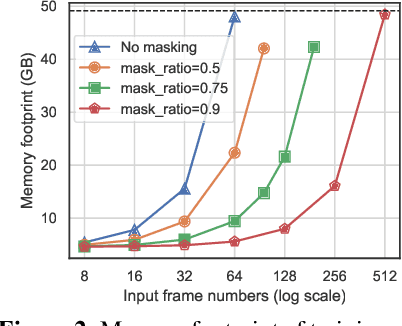
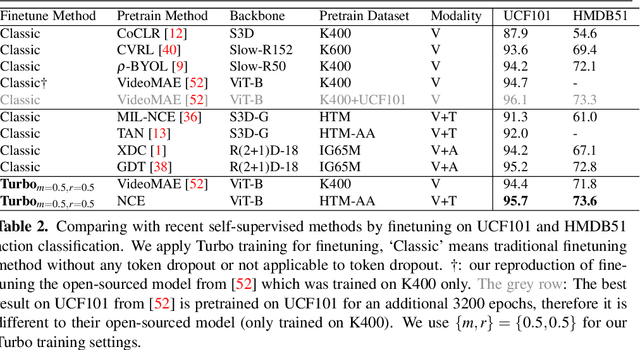
The objective of this paper is an efficient training method for video tasks. We make three contributions: (1) We propose Turbo training, a simple and versatile training paradigm for Transformers on multiple video tasks. (2) We illustrate the advantages of Turbo training on action classification, video-language representation learning, and long-video activity classification, showing that Turbo training can largely maintain competitive performance while achieving almost 4X speed-up and significantly less memory consumption. (3) Turbo training enables long-schedule video-language training and end-to-end long-video training, delivering competitive or superior performance than previous works, which were infeasible to train under limited resources.
Compressed Vision for Efficient Video Understanding
Oct 06, 2022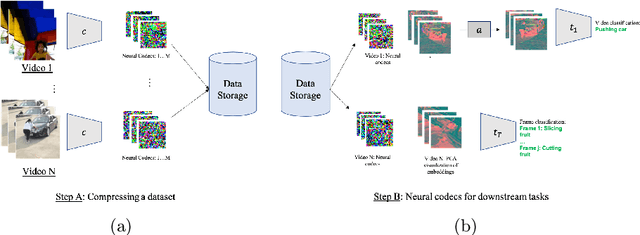
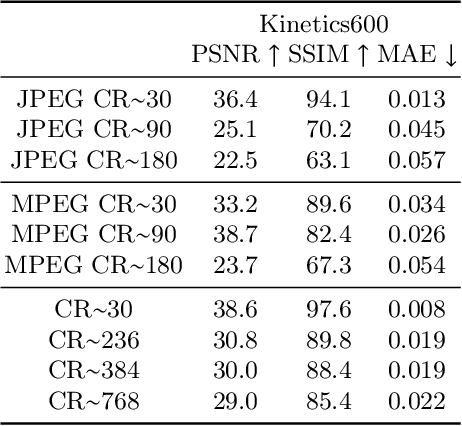
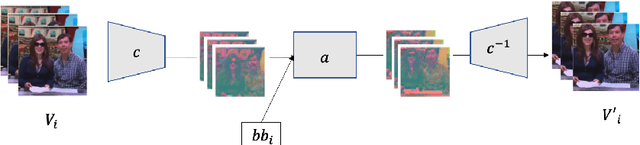

Experience and reasoning occur across multiple temporal scales: milliseconds, seconds, hours or days. The vast majority of computer vision research, however, still focuses on individual images or short videos lasting only a few seconds. This is because handling longer videos require more scalable approaches even to process them. In this work, we propose a framework enabling research on hour-long videos with the same hardware that can now process second-long videos. We replace standard video compression, e.g. JPEG, with neural compression and show that we can directly feed compressed videos as inputs to regular video networks. Operating on compressed videos improves efficiency at all pipeline levels -- data transfer, speed and memory -- making it possible to train models faster and on much longer videos. Processing compressed signals has, however, the downside of precluding standard augmentation techniques if done naively. We address that by introducing a small network that can apply transformations to latent codes corresponding to commonly used augmentations in the original video space. We demonstrate that with our compressed vision pipeline, we can train video models more efficiently on popular benchmarks such as Kinetics600 and COIN. We also perform proof-of-concept experiments with new tasks defined over hour-long videos at standard frame rates. Processing such long videos is impossible without using compressed representation.
The Change You Want to See
Sep 28, 2022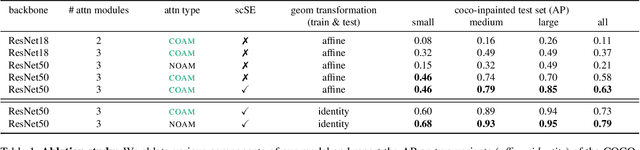
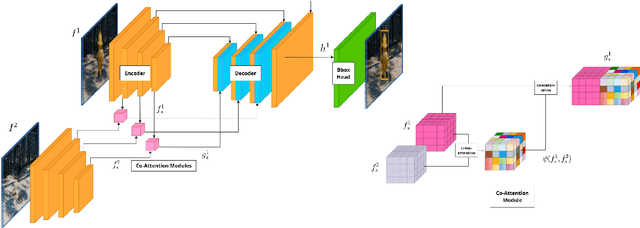

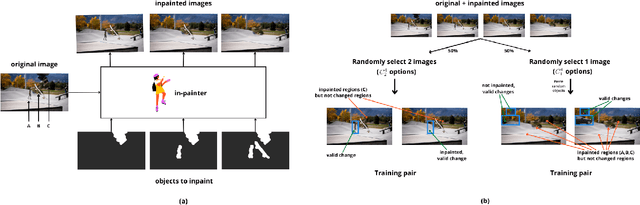
We live in a dynamic world where things change all the time. Given two images of the same scene, being able to automatically detect the changes in them has practical applications in a variety of domains. In this paper, we tackle the change detection problem with the goal of detecting "object-level" changes in an image pair despite differences in their viewpoint and illumination. To this end, we make the following four contributions: (i) we propose a scalable methodology for obtaining a large-scale change detection training dataset by leveraging existing object segmentation benchmarks; (ii) we introduce a co-attention based novel architecture that is able to implicitly determine correspondences between an image pair and find changes in the form of bounding box predictions; (iii) we contribute four evaluation datasets that cover a variety of domains and transformations, including synthetic image changes, real surveillance images of a 3D scene, and synthetic 3D scenes with camera motion; (iv) we evaluate our model on these four datasets and demonstrate zero-shot and beyond training transformation generalization.
CounTR: Transformer-based Generalised Visual Counting
Aug 29, 2022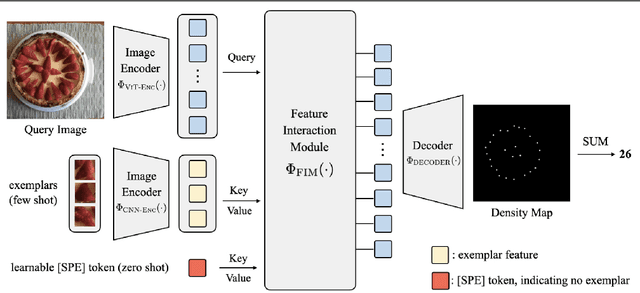
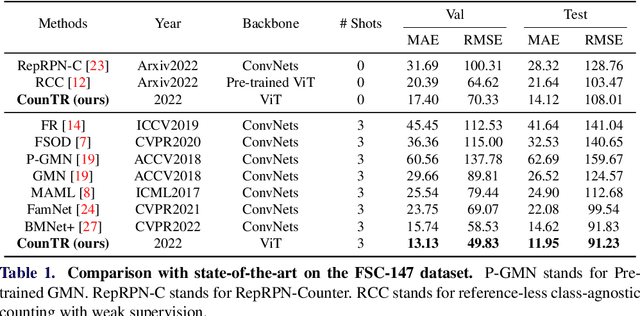

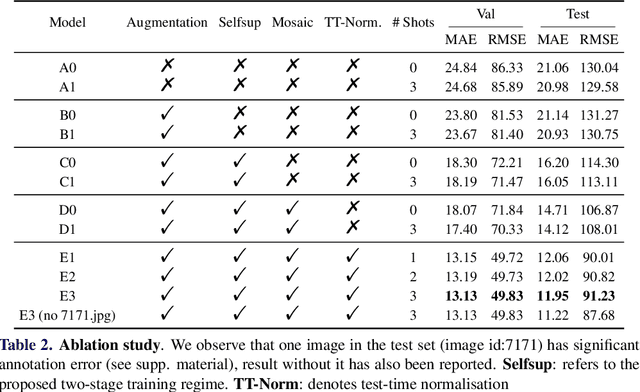
In this paper, we consider the problem of generalised visual object counting, with the goal of developing a computational model for counting the number of objects from arbitrary semantic categories, using arbitrary number of "exemplars", i.e. zero-shot or few-shot counting. To this end, we make the following four contributions: (1) We introduce a novel transformer-based architecture for generalised visual object counting, termed as Counting Transformer (CounTR), which explicitly capture the similarity between image patches or with given "exemplars" with the attention mechanism;(2) We adopt a two-stage training regime, that first pre-trains the model with self-supervised learning, and followed by supervised fine-tuning;(3) We propose a simple, scalable pipeline for synthesizing training images with a large number of instances or that from different semantic categories, explicitly forcing the model to make use of the given "exemplars";(4) We conduct thorough ablation studies on the large-scale counting benchmark, e.g. FSC-147, and demonstrate state-of-the-art performance on both zero and few-shot settings.
Automatic dense annotation of large-vocabulary sign language videos
Aug 04, 2022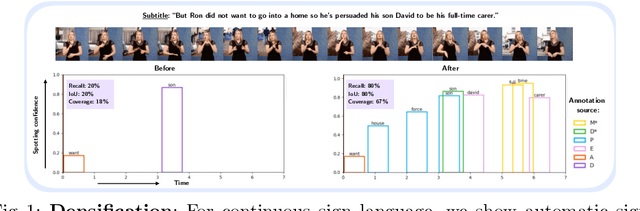

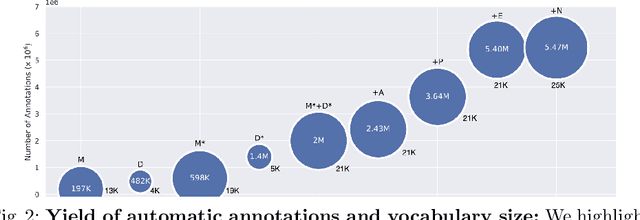
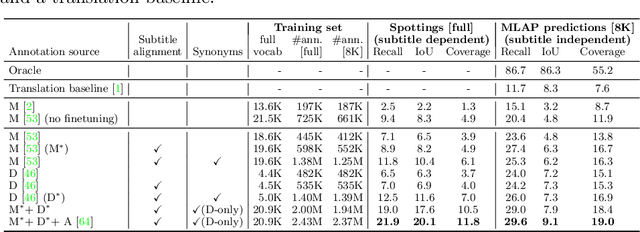
Recently, sign language researchers have turned to sign language interpreted TV broadcasts, comprising (i) a video of continuous signing and (ii) subtitles corresponding to the audio content, as a readily available and large-scale source of training data. One key challenge in the usability of such data is the lack of sign annotations. Previous work exploiting such weakly-aligned data only found sparse correspondences between keywords in the subtitle and individual signs. In this work, we propose a simple, scalable framework to vastly increase the density of automatic annotations. Our contributions are the following: (1) we significantly improve previous annotation methods by making use of synonyms and subtitle-signing alignment; (2) we show the value of pseudo-labelling from a sign recognition model as a way of sign spotting; (3) we propose a novel approach for increasing our annotations of known and unknown classes based on in-domain exemplars; (4) on the BOBSL BSL sign language corpus, we increase the number of confident automatic annotations from 670K to 5M. We make these annotations publicly available to support the sign language research community.
Is an Object-Centric Video Representation Beneficial for Transfer?
Jul 20, 2022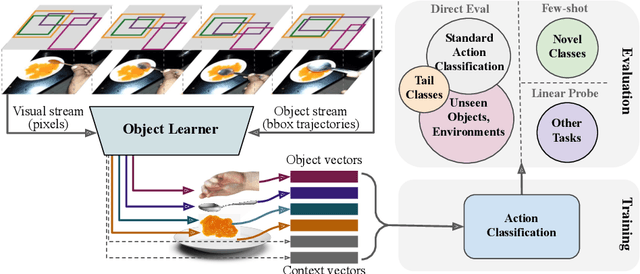
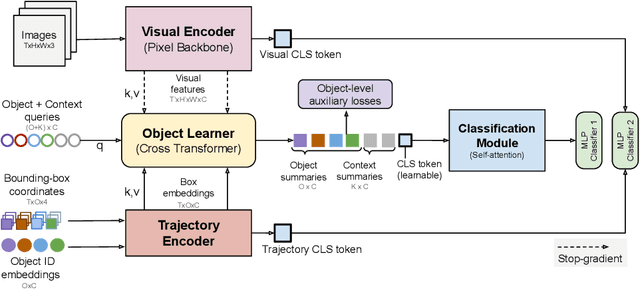
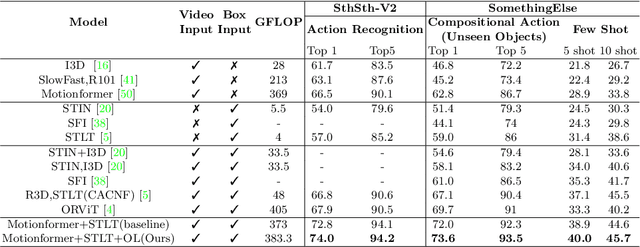
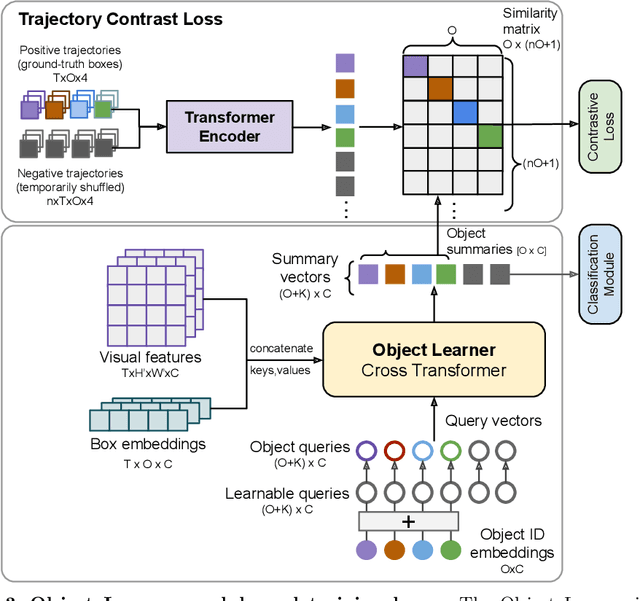
The objective of this work is to learn an object-centric video representation, with the aim of improving transferability to novel tasks, i.e., tasks different from the pre-training task of action classification. To this end, we introduce a new object-centric video recognition model based on a transformer architecture. The model learns a set of object-centric summary vectors for the video, and uses these vectors to fuse the visual and spatio-temporal trajectory `modalities' of the video clip. We also introduce a novel trajectory contrast loss to further enhance objectness in these summary vectors. With experiments on four datasets -- SomethingSomething-V2, SomethingElse, Action Genome and EpicKitchens -- we show that the object-centric model outperforms prior video representations (both object-agnostic and object-aware), when: (1) classifying actions on unseen objects and unseen environments; (2) low-shot learning to novel classes; (3) linear probe to other downstream tasks; as well as (4) for standard action classification.
Segmenting Moving Objects via an Object-Centric Layered Representation
Jul 05, 2022
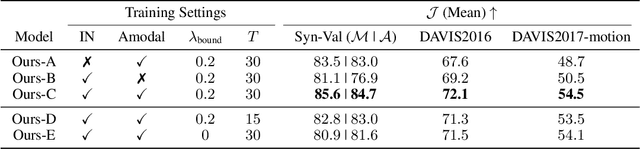
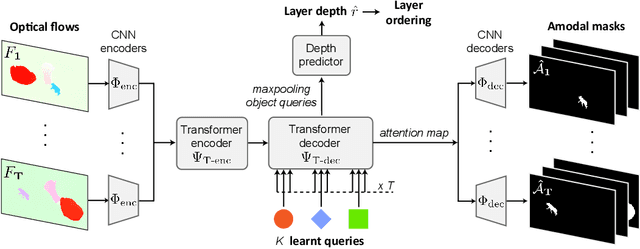
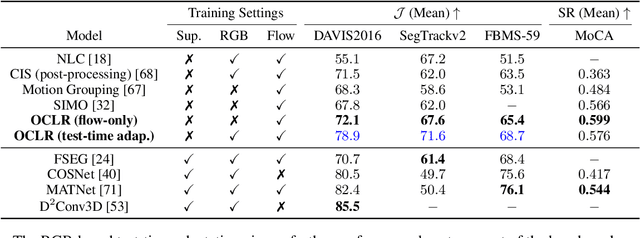
The objective of this paper is a model that is able to discover, track and segment multiple moving objects in a video. We make four contributions: First, we introduce an object-centric segmentation model with a depth-ordered layer representation. This is implemented using a variant of the transformer architecture that ingests optical flow, where each query vector specifies an object and its layer for the entire video. The model can effectively discover multiple moving objects and handle mutual occlusions; Second, we introduce a scalable pipeline for generating synthetic training data with multiple objects, significantly reducing the requirements for labour-intensive annotations, and supporting Sim2Real generalisation; Third, we show that the model is able to learn object permanence and temporal shape consistency, and is able to predict amodal segmentation masks; Fourth, we evaluate the model on standard video segmentation benchmarks, DAVIS, MoCA, SegTrack, FBMS-59, and achieve state-of-the-art unsupervised segmentation performance, even outperforming several supervised approaches. With test-time adaptation, we observe further performance boosts.