 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardiologist-Level Arrhythmia Detection with Convolutional Neural Networks
Jul 06, 2017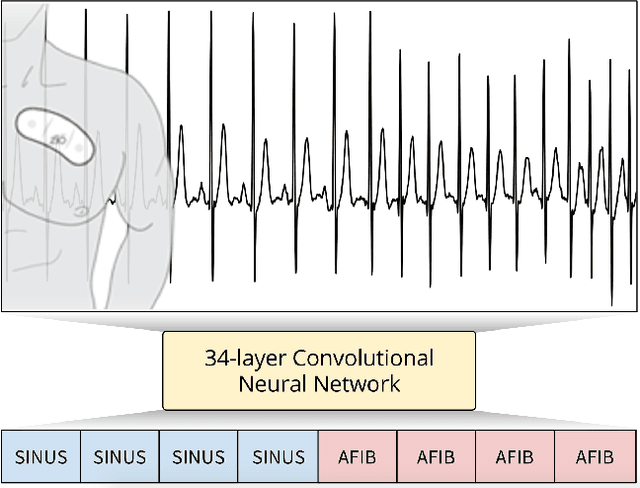
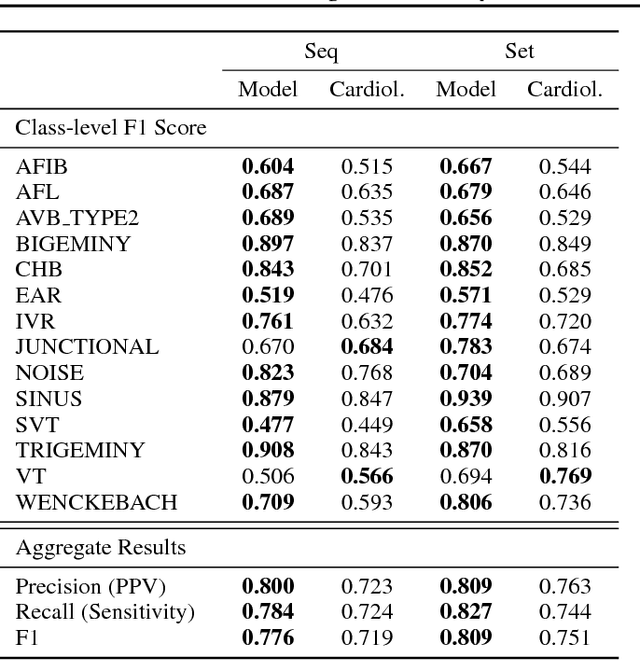
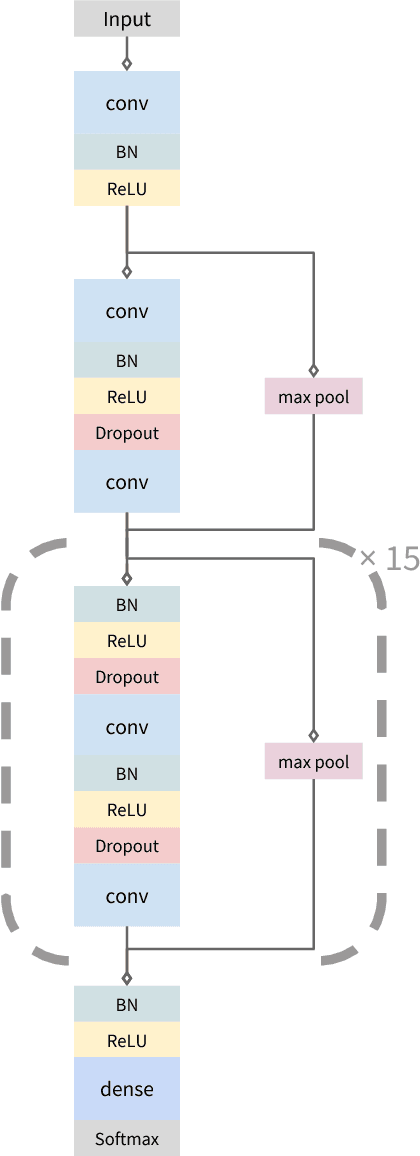
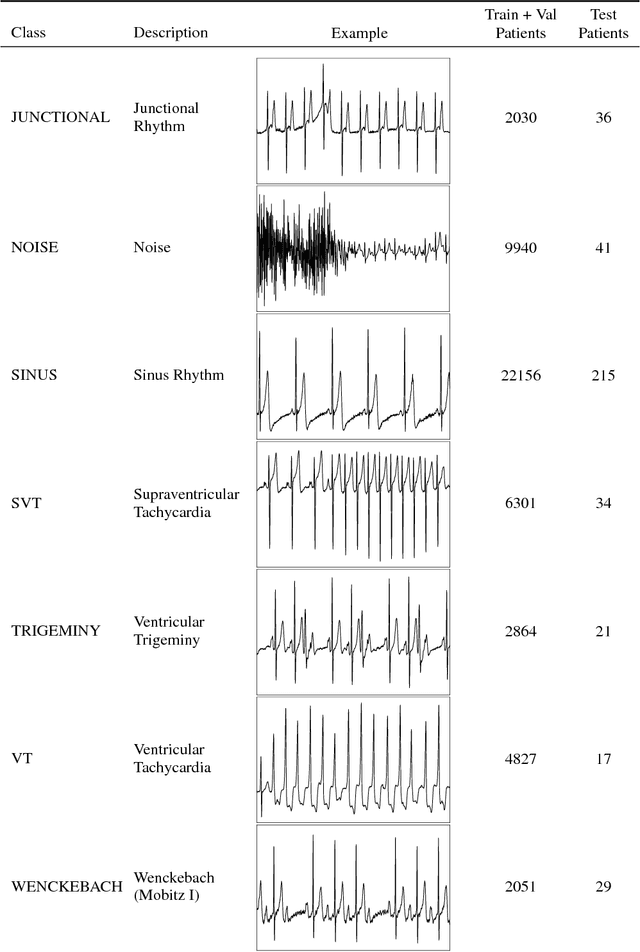
We develop an algorithm which exceeds the performance of board certified cardiologists in detecting a wide range of heart arrhythmias from electrocardiograms recorded with a single-lead wearable monitor. We build a dataset with more than 500 times the number of unique patients than previously studied corpora. On this dataset, we train a 34-layer convolutional neural network which maps a sequence of ECG samples to a sequence of rhythm classes. Committees of board-certified cardiologists annotate a gold standard test set on which we compare the performance of our model to that of 6 other individual cardiologists. We exceed the average cardiologist performance in both recall (sensitivity) and precision (positive predictive value).
Data Noising as Smoothing in Neural Network Language Models
Mar 07, 2017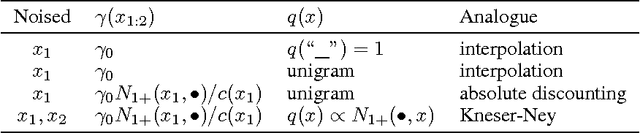
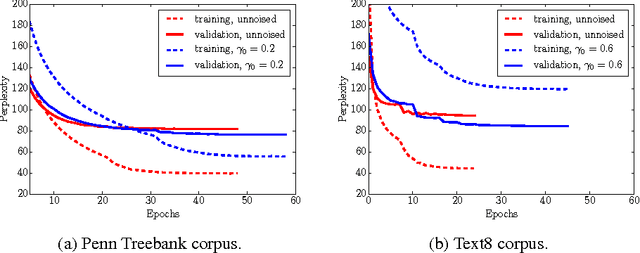
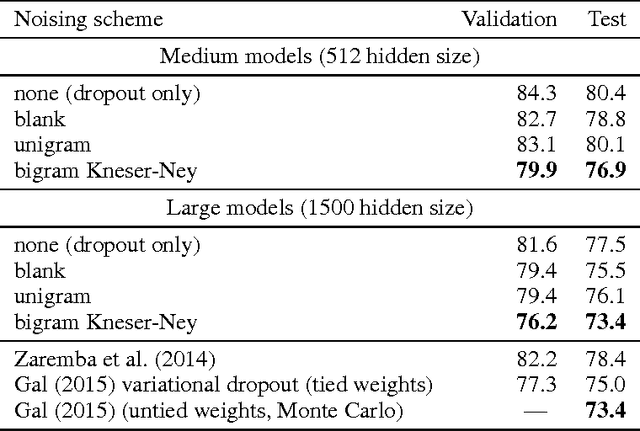
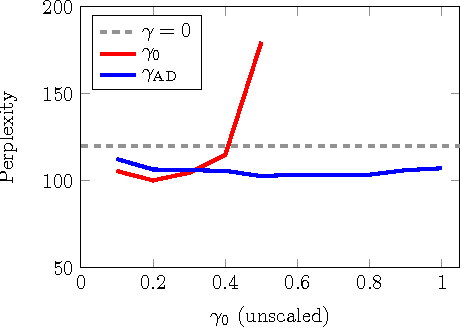
Data noising is an effective technique for regularizing neural network models. While noising is widely adopted in application domains such as vision and speech, commonly used noising primitives have not been developed for discrete sequence-level settings such as language modeling. In this paper, we derive a connection between input noising in neural network language models and smoothing in $n$-gram models. Using this connection, we draw upon ideas from smoothing to develop effective noising schemes. We demonstrate performance gains when applying the proposed schemes to language modeling and machine translation. Finally, we provide empirical analysis validating the relationship between noising and smoothing.
Neural Language Correction with Character-Based Attention
Mar 31, 2016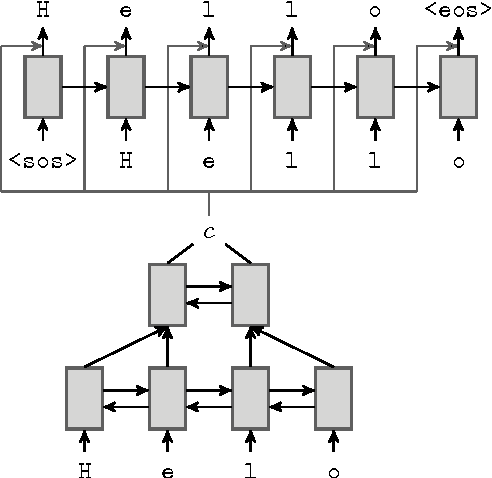


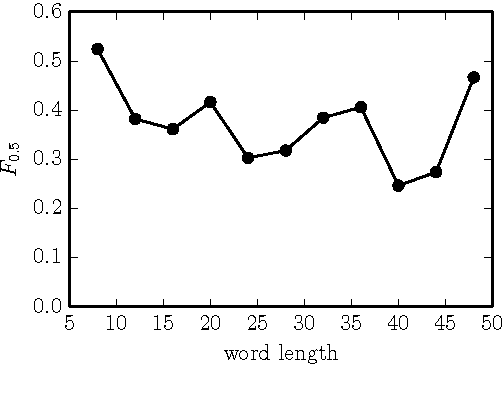
Natural language correction has the potential to help language learners improve their writing skills. While approaches with separate classifiers for different error types have high precision, they do not flexibly handle errors such as redundancy or non-idiomatic phrasing. On the other hand, word and phrase-based machine translation methods are not designed to cope with orthographic errors, and have recently been outpaced by neural models. Motivated by these issues, we present a neural network-based approach to language correction. The core component of our method is an encoder-decoder recurrent neural network with an attention mechanism. By operating at the character level, the network avoids the problem of out-of-vocabulary words. We illustrate the flexibility of our approach on dataset of noisy, user-generated text collected from an English learner forum. When combined with a language model, our method achieves a state-of-the-art $F_{0.5}$-score on the CoNLL 2014 Shared Task. We further demonstrate that training the network on additional data with synthesized errors can improve performance.
An Empirical Evaluation of Deep Learning on Highway Driving
Apr 17, 2015
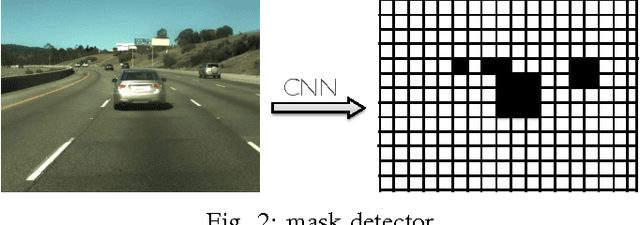
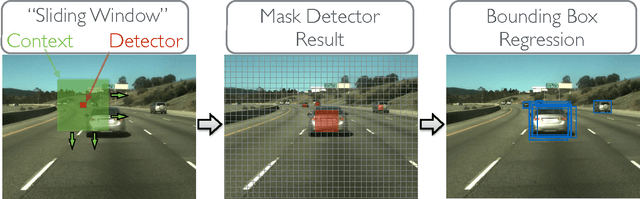
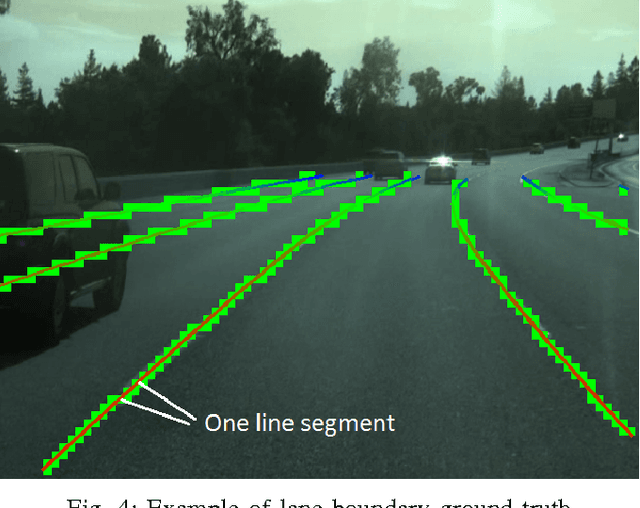
Numerous groups have applied a variety of deep learning techniques to computer vision problems in highway perception scenarios. In this paper, we presented a number of empirical evaluations of recent deep learning advances. Computer vision, combined with deep learning, has the potential to bring about a relatively inexpensive, robust solution to autonomous driving. To prepare deep learning for industry uptake and practical applications, neural networks will require large data sets that represent all possible driving environments and scenarios. We collect a large data set of highway data and apply deep learning and computer vision algorithms to problems such as car and lane detection. We show how existing convolutional neural networks (CNNs) can be used to perform lane and vehicle detection while running at frame rates required for a real-time system. Our results lend credence to the hypothesis that deep learning holds promise for autonomous driving.
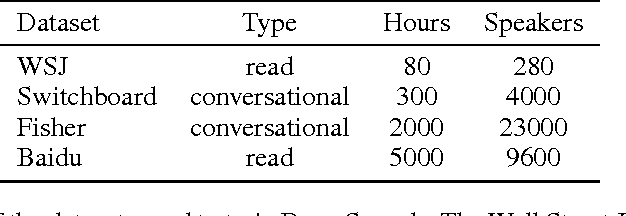
Building DNN Acoustic Models for Large Vocabulary Speech Recognition
Jan 20, 2015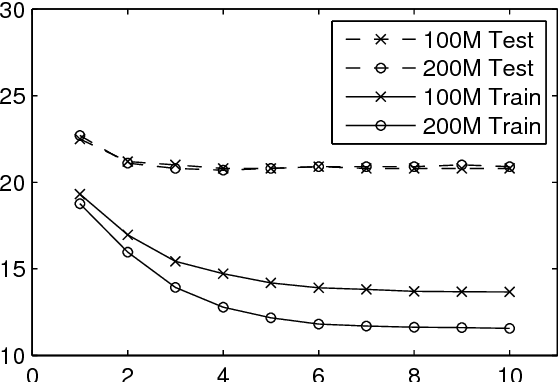

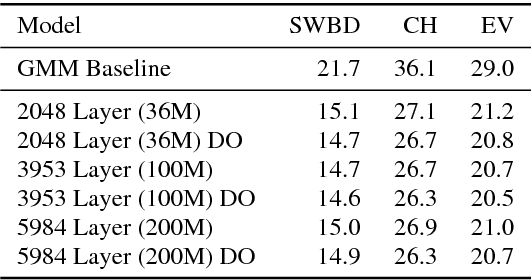

Deep neural networks (DNNs) are now a central component of nearly all state-of-the-art speech recognition systems. Building neural network acoustic models requires several design decisions including network architecture, size, and training loss function. This paper offers an empirical investigation on which aspects of DNN acoustic model design are most important for speech recognition system performance. We report DNN classifier performance and final speech recognizer word error rates, and compare DNNs using several metrics to quantify factors influencing differences in task performance. Our first set of experiments use the standard Switchboard benchmark corpus, which contains approximately 300 hours of conversational telephone speech. We compare standard DNNs to convolutional networks, and present the first experiments using locally-connected, untied neural networks for acoustic modeling. We additionally build systems on a corpus of 2,100 hours of training data by combining the Switchboard and Fisher corpora. This larger corpus allows us to more thoroughly examine performance of large DNN models -- with up to ten times more parameters than those typically used in speech recognition systems. Our results suggest that a relatively simple DNN architecture and optimization technique produces strong results. These findings, along with previous work, help establish a set of best practices for building DNN hybrid speech recognition systems with maximum likelihood training. Our experiments in DNN optimization additionally serve as a case study for training DNNs with discriminative loss functions for speech tasks, as well as DNN classifiers more generally.
Deep Speech: Scaling up end-to-end speech recognition
Dec 19, 2014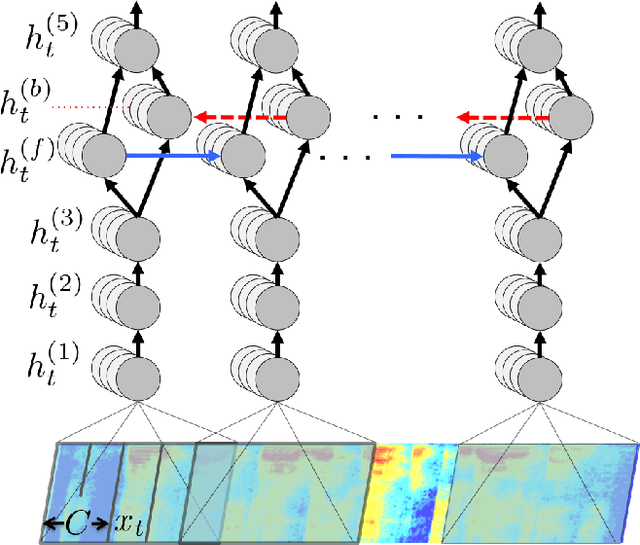


We present a state-of-the-art speech recognition system developed using end-to-end deep learning. Our architecture is significantly simpler than traditional speech systems, which rely on laboriously engineered processing pipelines; these traditional systems also tend to perform poorly when used in noisy environments. In contrast, our system does not need hand-designed components to model background noise, reverberation, or speaker variation, but instead directly learns a function that is robust to such effects. We do not need a phoneme dictionary, nor even the concept of a "phoneme." Key to our approach is a well-optimized RNN training system that uses multiple GPUs, as well as a set of novel data synthesis techniques that allow us to efficiently obtain a large amount of varied data for training. Our system, called Deep Speech, outperforms previously published results on the widely studied Switchboard Hub5'00, achieving 16.0% error on the full test set. Deep Speech also handles challenging noisy environments better than widely used, state-of-the-art commercial speech systems.
First-Pass Large Vocabulary Continuous Speech Recognition using Bi-Directional Recurrent DNNs
Dec 08, 2014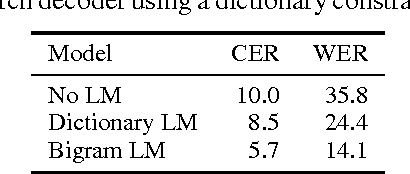

We present a method to perform first-pass large vocabulary continuous speech recognition using only a neural network and language model. Deep neural network acoustic models are now commonplace in HMM-based speech recognition systems, but building such systems is a complex, domain-specific task. Recent work demonstrated the feasibility of discarding the HMM sequence modeling framework by directly predicting transcript text from audio. This paper extends this approach in two ways. First, we demonstrate that a straightforward recurrent neural network architecture can achieve a high level of accuracy. Second, we propose and evaluate a modified prefix-search decoding algorithm. This approach to decoding enables first-pass speech recognition with a language model, completely unaided by the cumbersome infrastructure of HMM-based systems. Experiments on the Wall Street Journal corpus demonstrate fairly competitive word error rates, and the importance of bi-directional network recurrence.
Zero-Shot Learning Through Cross-Modal Transfer
Mar 20, 2013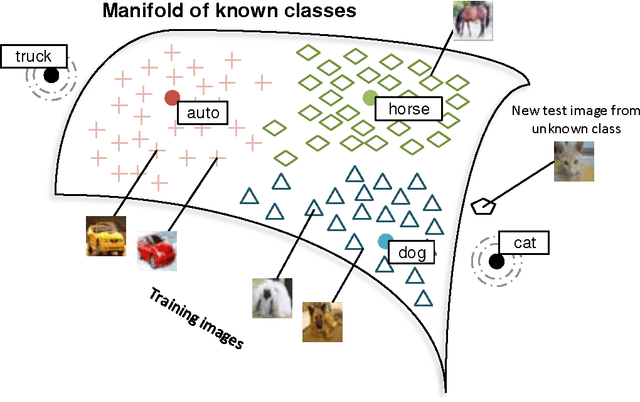
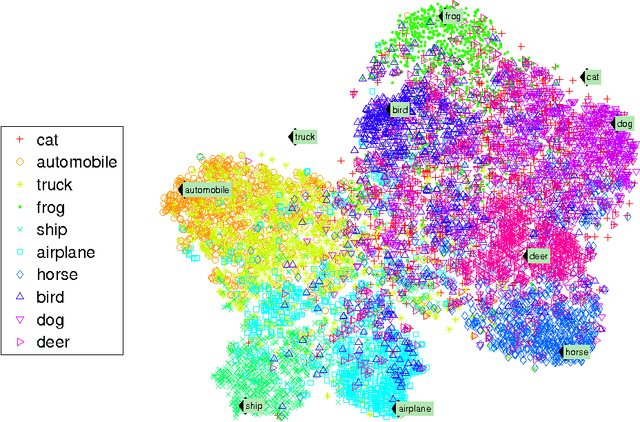
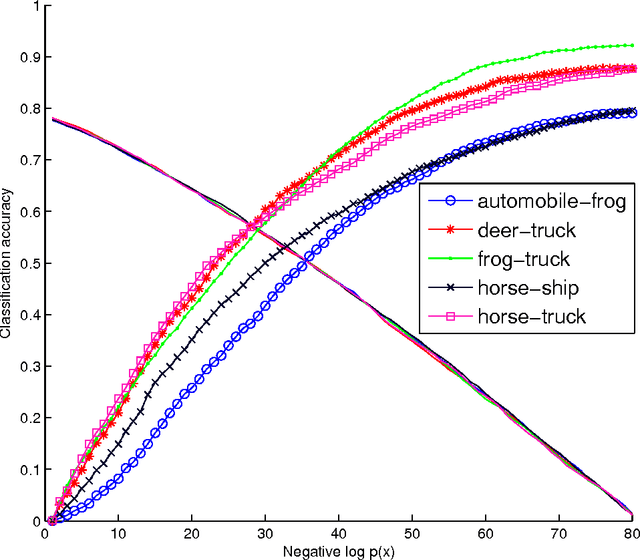
This work introduces a model that can recognize objects in images even if no training data is available for the objects. The only necessary knowledge about the unseen categories comes from unsupervised large text corpora. In our zero-shot framework distributional information in language can be seen as spanning a semantic basis for understanding what objects look like. Most previous zero-shot learning models can only differentiate between unseen classes. In contrast, our model can both obtain state of the art performance on classes that have thousands of training images and obtain reasonable performance on unseen classes. This is achieved by first using outlier detection in the semantic space and then two separate recognition models. Furthermore, our model does not require any manually defined semantic features for either words or images.
Learning New Facts From Knowledge Bases With Neural Tensor Networks and Semantic Word Vectors
Mar 16, 2013Knowledge bases provide applications with the benefit of easily accessible, systematic relational knowledge but often suffer in practice from their incompleteness and lack of knowledge of new entities and relations. Much work has focused on building or extending them by finding patterns in large unannotated text corpora. In contrast, here we mainly aim to complete a knowledge base by predicting additional true relationships between entities, based on generalizations that can be discerned in the given knowledgebase. We introduce a neural tensor network (NTN) model which predicts new relationship entries that can be added to the database. This model can be improved by initializing entity representations with word vectors learned in an unsupervised fashion from text, and when doing this, existing relations can even be queried for entities that were not present in the database. Our model generalizes and outperforms existing models for this problem, and can classify unseen relationships in WordNet with an accuracy of 75.8%.
An Information-Theoretic Analysis of Hard and Soft Assignment Methods for Clustering
Feb 06, 2013
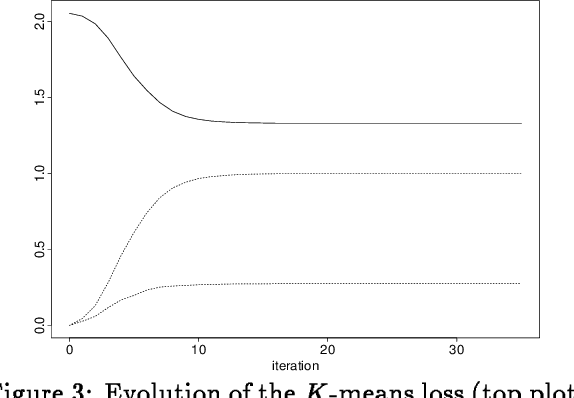
Assignment methods are at the heart of many algorithms for unsupervised learning and clustering - in particular, the well-known K-means and Expectation-Maximization (EM) algorithms. In this work, we study several different methods of assignment, including the "hard" assignments used by K-means and the ?soft' assignments used by EM. While it is known that K-means minimizes the distortion on the data and EM maximizes the likelihood, little is known about the systematic differences of behavior between the two algorithms. Here we shed light on these differences via an information-theoretic analysis. The cornerstone of our results is a simple decomposition of the expected distortion, showing that K-means (and its extension for inferring general parametric densities from unlabeled sample data) must implicitly manage a trade-off between how similar the data assigned to each cluster are, and how the data are balanced among the clusters. How well the data are balanced is measured by the entropy of the partition defined by the hard assignments. In addition to letting us predict and verify systematic differences between K-means and EM on specific examples, the decomposition allows us to give a rather general argument showing that K ?means will consistently find densities with less "overlap" than EM. We also study a third natural assignment method that we call posterior assignment, that is close in spirit to the soft assignments of EM, but leads to a surprisingly different algorithm.