 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Visual Scenes from Touch
Sep 26, 2023An emerging line of work has sought to generate plausible imagery from touch. Existing approaches, however, tackle only narrow aspects of the visuo-tactile synthesis problem, and lag significantly behind the quality of cross-modal synthesis methods in other domains. We draw on recent advances in latent diffusion to create a model for synthesizing images from tactile signals (and vice versa) and apply it to a number of visuo-tactile synthesis tasks. Using this model, we significantly outperform prior work on the tactile-driven stylization problem, i.e., manipulating an image to match a touch signal, and we are the first to successfully generate images from touch without additional sources of information about the scene. We also successfully use our model to address two novel synthesis problems: generating images that do not contain the touch sensor or the hand holding it, and estimating an image's shading from its reflectance and touch.
Conditional Generation of Audio from Video via Foley Analogies
Apr 17, 2023The sound effects that designers add to videos are designed to convey a particular artistic effect and, thus, may be quite different from a scene's true sound. Inspired by the challenges of creating a soundtrack for a video that differs from its true sound, but that nonetheless matches the actions occurring on screen, we propose the problem of conditional Foley. We present the following contributions to address this problem. First, we propose a pretext task for training our model to predict sound for an input video clip using a conditional audio-visual clip sampled from another time within the same source video. Second, we propose a model for generating a soundtrack for a silent input video, given a user-supplied example that specifies what the video should "sound like". We show through human studies and automated evaluation metrics that our model successfully generates sound from video, while varying its output according to the content of a supplied example. Project site: https://xypb.github.io/CondFoleyGen/
Sound to Visual Scene Generation by Audio-to-Visual Latent Alignment
Mar 30, 2023



How does audio describe the world around us? In this paper, we propose a method for generating an image of a scene from sound. Our method addresses the challenges of dealing with the large gaps that often exist between sight and sound. We design a model that works by scheduling the learning procedure of each model component to associate audio-visual modalities despite their information gaps. The key idea is to enrich the audio features with visual information by learning to align audio to visual latent space. We translate the input audio to visual features, then use a pre-trained generator to produce an image. To further improve the quality of our generated images, we use sound source localization to select the audio-visual pairs that have strong cross-modal correlations. We obtain substantially better results on the VEGAS and VGGSound datasets than prior approaches. We also show that we can control our model's predictions by applying simple manipulations to the input waveform, or to the latent space.
Text2Room: Extracting Textured 3D Meshes from 2D Text-to-Image Models
Mar 21, 2023We present Text2Room, a method for generating room-scale textured 3D meshes from a given text prompt as input. To this end, we leverage pre-trained 2D text-to-image models to synthesize a sequence of images from different poses. In order to lift these outputs into a consistent 3D scene representation, we combine monocular depth estimation with a text-conditioned inpainting model. The core idea of our approach is a tailored viewpoint selection such that the content of each image can be fused into a seamless, textured 3D mesh. More specifically, we propose a continuous alignment strategy that iteratively fuses scene frames with the existing geometry to create a seamless mesh. Unlike existing works that focus on generating single objects or zoom-out trajectories from text, our method generates complete 3D scenes with multiple objects and explicit 3D geometry. We evaluate our approach using qualitative and quantitative metrics, demonstrating it as the first method to generate room-scale 3D geometry with compelling textures from only text as input.
Sound Localization from Motion: Jointly Learning Sound Direction and Camera Rotation
Mar 20, 2023The images and sounds that we perceive undergo subtle but geometrically consistent changes as we rotate our heads. In this paper, we use these cues to solve a problem we call Sound Localization from Motion (SLfM): jointly estimating camera rotation and localizing sound sources. We learn to solve these tasks solely through self-supervision. A visual model predicts camera rotation from a pair of images, while an audio model predicts the direction of sound sources from binaural sounds. We train these models to generate predictions that agree with one another. At test time, the models can be deployed independently. To obtain a feature representation that is well-suited to solving this challenging problem, we also propose a method for learning an audio-visual representation through cross-view binauralization: estimating binaural sound from one view, given images and sound from another. Our model can successfully estimate accurate rotations on both real and synthetic scenes, and localize sound sources with accuracy competitive with state-of-the-art self-supervised approaches. Project site: https://ificl.github.io/SLfM/
EXIF as Language: Learning Cross-Modal Associations Between Images and Camera Metadata
Jan 11, 2023



We learn a visual representation that captures information about the camera that recorded a given photo. To do this, we train a multimodal embedding between image patches and the EXIF metadata that cameras automatically insert into image files. Our model represents this metadata by simply converting it to text and then processing it with a transformer. The features that we learn significantly outperform other self-supervised and supervised features on downstream image forensics and calibration tasks. In particular, we successfully localize spliced image regions "zero shot" by clustering the visual embeddings for all of the patches within an image.
Self-Supervised Video Forensics by Audio-Visual Anomaly Detection
Jan 04, 2023Manipulated videos often contain subtle inconsistencies between their visual and audio signals. We propose a video forensics method, based on anomaly detection, that can identify these inconsistencies, and that can be trained solely using real, unlabeled data. We train an autoregressive model to generate sequences of audio-visual features, using feature sets that capture the temporal synchronization between video frames and sound. At test time, we then flag videos that the model assigns low probability. Despite being trained entirely on real videos, our model obtains strong performance on the task of detecting manipulated speech videos. Project site: https://cfeng16.github.io/audio-visual-forensics
Touch and Go: Learning from Human-Collected Vision and Touch
Nov 29, 2022The ability to associate touch with sight is essential for tasks that require physically interacting with objects in the world. We propose a dataset with paired visual and tactile data called Touch and Go, in which human data collectors probe objects in natural environments using tactile sensors, while simultaneously recording egocentric video. In contrast to previous efforts, which have largely been confined to lab settings or simulated environments, our dataset spans a large number of "in the wild" objects and scenes. To demonstrate our dataset's effectiveness, we successfully apply it to a variety of tasks: 1) self-supervised visuo-tactile feature learning, 2) tactile-driven image stylization, i.e., making the visual appearance of an object more consistent with a given tactile signal, and 3) predicting future frames of a tactile signal from visuo-tactile inputs.
Mix and Localize: Localizing Sound Sources in Mixtures
Nov 28, 2022



We present a method for simultaneously localizing multiple sound sources within a visual scene. This task requires a model to both group a sound mixture into individual sources, and to associate them with a visual signal. Our method jointly solves both tasks at once, using a formulation inspired by the contrastive random walk of Jabri et al. We create a graph in which images and separated sounds correspond to nodes, and train a random walker to transition between nodes from different modalities with high return probability. The transition probabilities for this walk are determined by an audio-visual similarity metric that is learned by our model. We show through experiments with musical instruments and human speech that our model can successfully localize multiple sounds, outperforming other self-supervised methods. Project site: https://hxixixh.github.io/mix-and-localize
Learning Visual Styles from Audio-Visual Associations
May 10, 2022
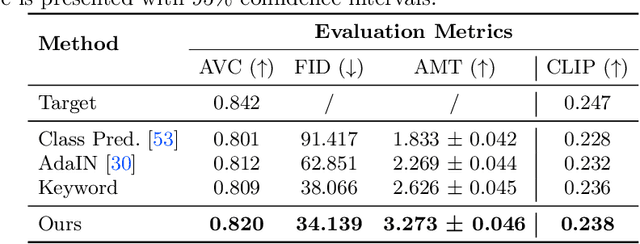

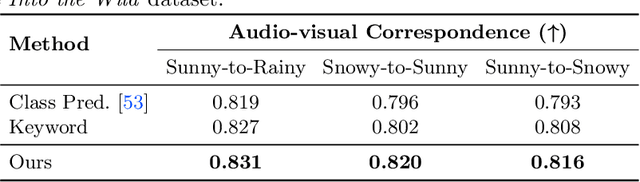
From the patter of rain to the crunch of snow, the sounds we hear often convey the visual textures that appear within a scene. In this paper, we present a method for learning visual styles from unlabeled audio-visual data. Our model learns to manipulate the texture of a scene to match a sound, a problem we term audio-driven image stylization. Given a dataset of paired audio-visual data, we learn to modify input images such that, after manipulation, they are more likely to co-occur with a given input sound. In quantitative and qualitative evaluations, our sound-based model outperforms label-based approaches. We also show that audio can be an intuitive representation for manipulating images, as adjusting a sound's volume or mixing two sounds together results in predictable changes to visual style. Project webpage: https://tinglok.netlify.app/files/avstyle