 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Sampler: Almost-Universal yet Task-Oriented Sampling for Point Clouds
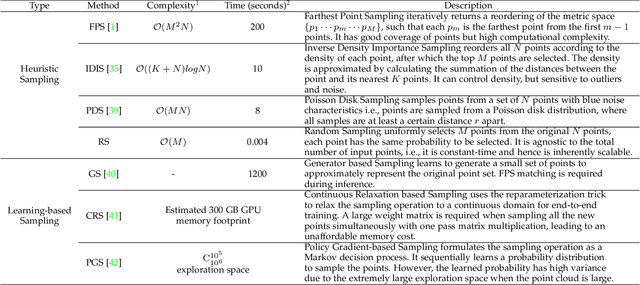
Mar 30, 2022Sampling is a key operation in point-cloud task and acts to increase computational efficiency and tractability by discarding redundant points. Universal sampling algorithms (e.g., Farthest Point Sampling) work without modification across different tasks, models, and datasets, but by their very nature are agnostic about the downstream task/model. As such, they have no implicit knowledge about which points would be best to keep and which to reject. Recent work has shown how task-specific point cloud sampling (e.g., SampleNet) can be used to outperform traditional sampling approaches by learning which points are more informative. However, these learnable samplers face two inherent issues: i) overfitting to a model rather than a task, and \ii) requiring training of the sampling network from scratch, in addition to the task network, somewhat countering the original objective of down-sampling to increase efficiency. In this work, we propose an almost-universal sampler, in our quest for a sampler that can learn to preserve the most useful points for a particular task, yet be inexpensive to adapt to different tasks, models, or datasets. We first demonstrate how training over multiple models for the same task (e.g., shape reconstruction) significantly outperforms the vanilla SampleNet in terms of accuracy by not overfitting the sample network to a particular task network. Second, we show how we can train an almost-universal meta-sampler across multiple tasks. This meta-sampler can then be rapidly fine-tuned when applied to different datasets, networks, or even different tasks, thus amortizing the initial cost of training.
No Pain, Big Gain: Classify Dynamic Point Cloud Sequences with Static Models by Fitting Feature-level Space-time Surfaces
Mar 23, 2022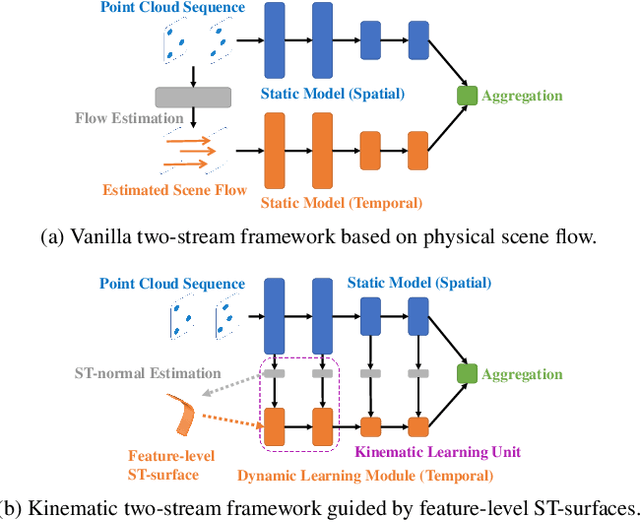
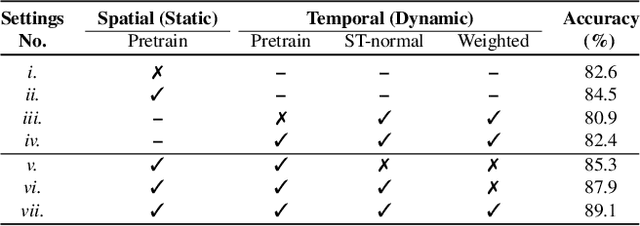
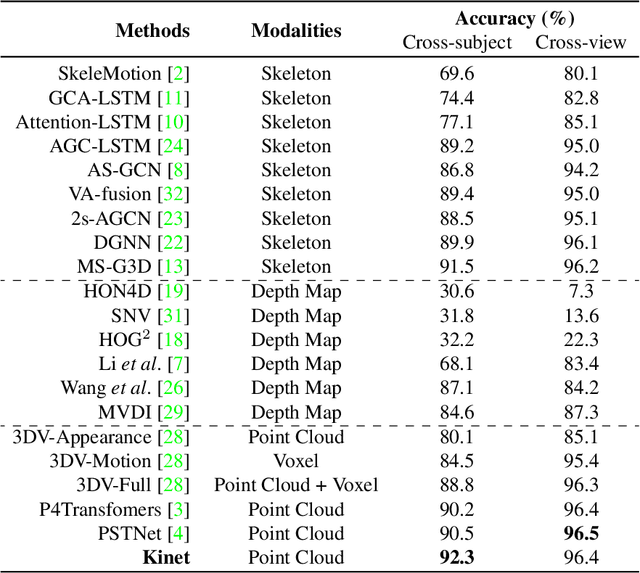
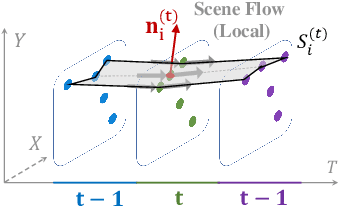
Scene flow is a powerful tool for capturing the motion field of 3D point clouds. However, it is difficult to directly apply flow-based models to dynamic point cloud classification since the unstructured points make it hard or even impossible to efficiently and effectively trace point-wise correspondences. To capture 3D motions without explicitly tracking correspondences, we propose a kinematics-inspired neural network (Kinet) by generalizing the kinematic concept of ST-surfaces to the feature space. By unrolling the normal solver of ST-surfaces in the feature space, Kinet implicitly encodes feature-level dynamics and gains advantages from the use of mature backbones for static point cloud processing. With only minor changes in network structures and low computing overhead, it is painless to jointly train and deploy our framework with a given static model. Experiments on NvGesture, SHREC'17, MSRAction-3D, and NTU-RGBD demonstrate its efficacy in performance, efficiency in both the number of parameters and computational complexity, as well as its versatility to various static backbones. Noticeably, Kinet achieves the accuracy of 93.27% on MSRAction-3D with only 3.20M parameters and 10.35G FLOPS.
Real-Time Hybrid Mapping of Populated Indoor Scenes using a Low-Cost Monocular UAV
Mar 04, 2022
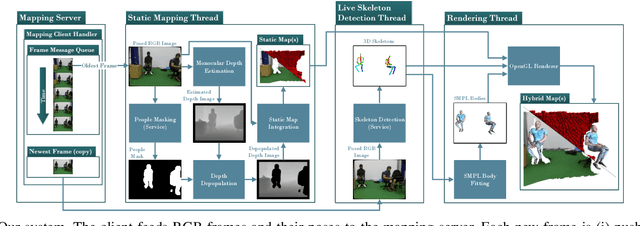
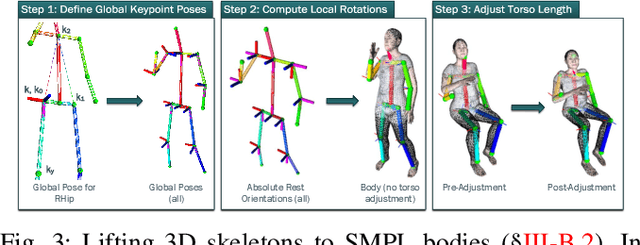
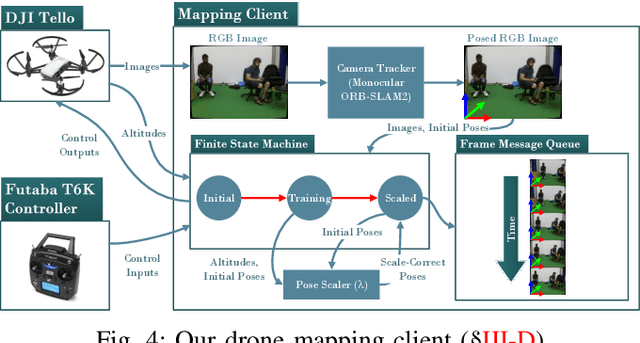
Unmanned aerial vehicles (UAVs) have been used for many applications in recent years, from urban search and rescue, to agricultural surveying, to autonomous underground mine exploration. However, deploying UAVs in tight, indoor spaces, especially close to humans, remains a challenge. One solution, when limited payload is required, is to use micro-UAVs, which pose less risk to humans and typically cost less to replace after a crash. However, micro-UAVs can only carry a limited sensor suite, e.g. a monocular camera instead of a stereo pair or LiDAR, complicating tasks like dense mapping and markerless multi-person 3D human pose estimation, which are needed to operate in tight environments around people. Monocular approaches to such tasks exist, and dense monocular mapping approaches have been successfully deployed for UAV applications. However, despite many recent works on both marker-based and markerless multi-UAV single-person motion capture, markerless single-camera multi-person 3D human pose estimation remains a much earlier-stage technology, and we are not aware of existing attempts to deploy it in an aerial context. In this paper, we present what is thus, to our knowledge, the first system to perform simultaneous mapping and multi-person 3D human pose estimation from a monocular camera mounted on a single UAV. In particular, we show how to loosely couple state-of-the-art monocular depth estimation and monocular 3D human pose estimation approaches to reconstruct a hybrid map of a populated indoor scene in real time. We validate our component-level design choices via extensive experiments on the large-scale ScanNet and GTA-IM datasets. To evaluate our system-level performance, we also construct a new Oxford Hybrid Mapping dataset of populated indoor scenes.
SensatUrban: Learning Semantics from Urban-Scale Photogrammetric Point Clouds
Jan 12, 2022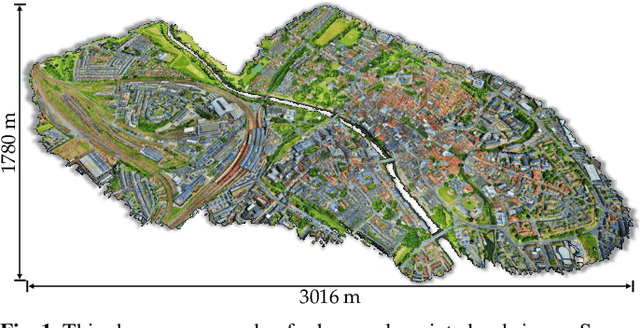
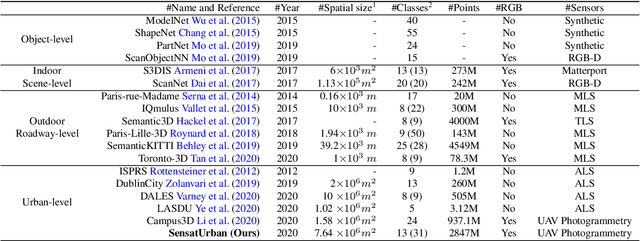

With the recent availability and affordability of commercial depth sensors and 3D scanners, an increasing number of 3D (i.e., RGBD, point cloud) datasets have been publicized to facilitate research in 3D computer vision. However, existing datasets either cover relatively small areas or have limited semantic annotations. Fine-grained understanding of urban-scale 3D scenes is still in its infancy. In this paper, we introduce SensatUrban, an urban-scale UAV photogrammetry point cloud dataset consisting of nearly three billion points collected from three UK cities, covering 7.6 km^2. Each point in the dataset has been labelled with fine-grained semantic annotations, resulting in a dataset that is three times the size of the previous existing largest photogrammetric point cloud dataset. In addition to the more commonly encountered categories such as road and vegetation, urban-level categories including rail, bridge, and river are also included in our dataset. Based on this dataset, we further build a benchmark to evaluate the performance of state-of-the-art segmentation algorithms. In particular, we provide a comprehensive analysis and identify several key challenges limiting urban-scale point cloud understanding. The dataset is available at http://point-cloud-analysis.cs.ox.ac.uk.
Deep Odometry Systems on Edge with EKF-LoRa Backend for Real-Time Positioning in Adverse Environment
Dec 10, 2021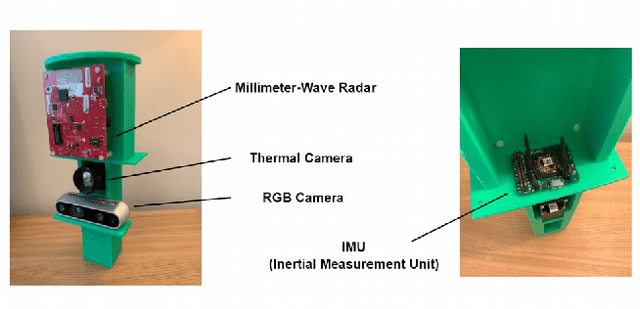
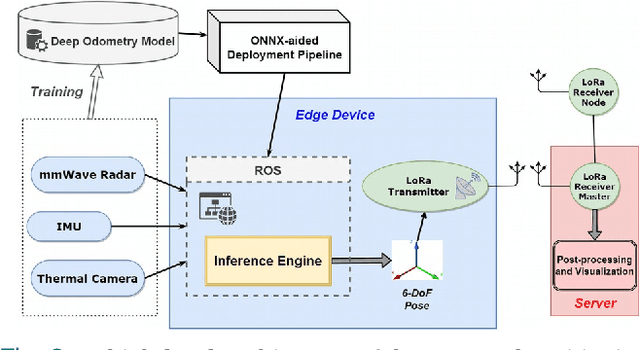
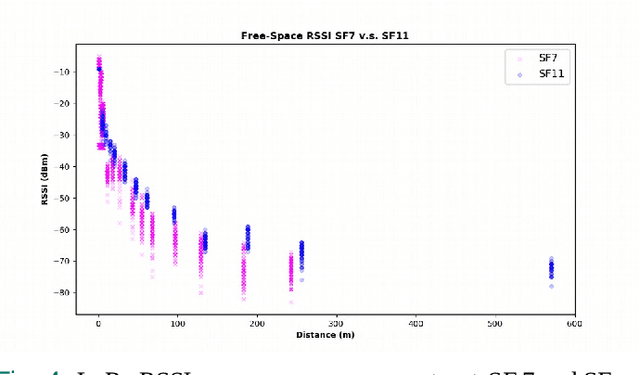
Ubiquitous positioning for pedestrian in adverse environment has served a long standing challenge. Despite dramatic progress made by Deep Learning, multi-sensor deep odometry systems yet pose a high computational cost and suffer from cumulative drifting errors over time. Thanks to the increasing computational power of edge devices, we propose a novel ubiquitous positioning solution by integrating state-of-the-art deep odometry models on edge with an EKF (Extended Kalman Filter)-LoRa backend. We carefully compare and select three sensor modalities, i.e., an Inertial Measurement Unit (IMU), a millimetre-wave (mmWave) radar, and a thermal infrared camera, and realise their deep odometry inference engines which runs in real-time. A pipeline of deploying deep odometry considering accuracy, complexity, and edge platform is proposed. We design a LoRa link for positional data backhaul and projecting aggregated positions of deep odometry into the global frame. We find that a simple EKF based fusion module is sufficient for generic positioning calibration with over 34% accuracy gains against any standalone deep odometry system. Extensive tests in different environments validate the efficiency and efficacy of our proposed positioning system.
DeepAoANet: Learning Angle of Arrival from Software Defined Radios with Deep Neural Networks
Dec 09, 2021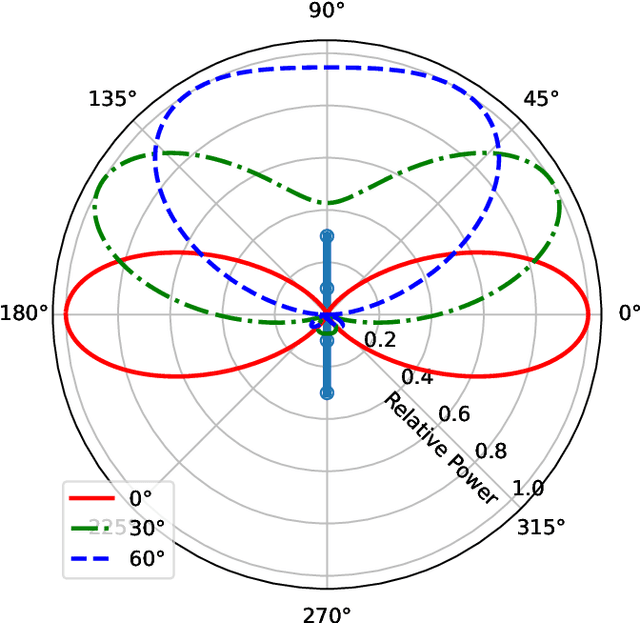
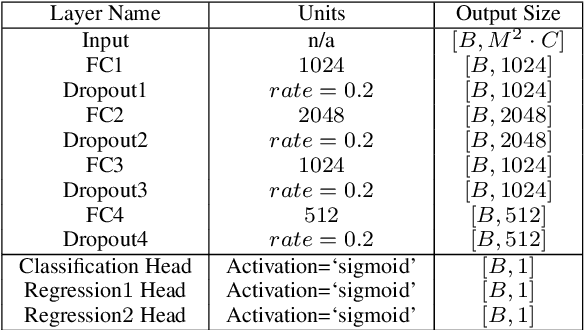
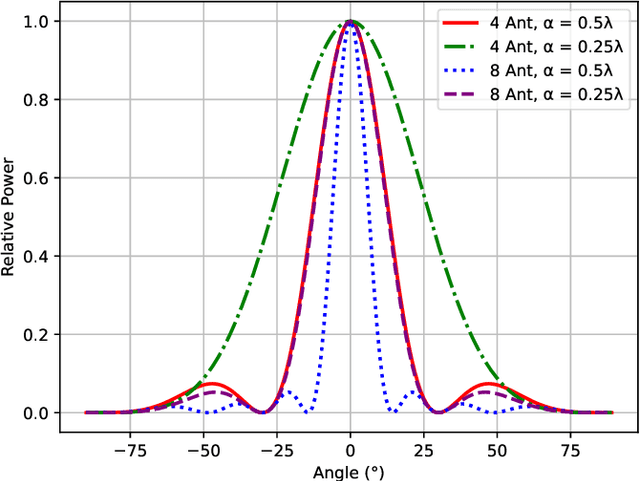
Direction finding and positioning systems based on RF signals are significantly impacted by multipath propagation, particularly in indoor environments. Existing algorithms (e.g MUSIC) perform poorly in resolving Angle of Arrival (AoA) in the presence of multipath or when operating in a weak signal regime. We note that digitally sampled RF frontends allow for the easy analysis of signals, and their delayed components. Low-cost Software-Defined Radio (SDR) modules enable Channel State Information (CSI) extraction across a wide spectrum, motivating the design of an enhanced Angle-of-Arrival (AoA) solution. We propose a Deep Learning approach to deriving AoA from a single snapshot of the SDR multichannel data. We compare and contrast deep-learning based angle classification and regression models, to estimate up to two AoAs accurately. We have implemented the inference engines on different platforms to extract AoAs in real-time, demonstrating the computational tractability of our approach. To demonstrate the utility of our approach we have collected IQ (In-phase and Quadrature components) samples from a four-element Universal Linear Array (ULA) in various Light-of-Sight (LOS) and Non-Line-of-Sight (NLOS) environments, and published the dataset. Our proposed method demonstrates excellent reliability in determining number of impinging signals and realized mean absolute AoA errors less than $2^{\circ}$.
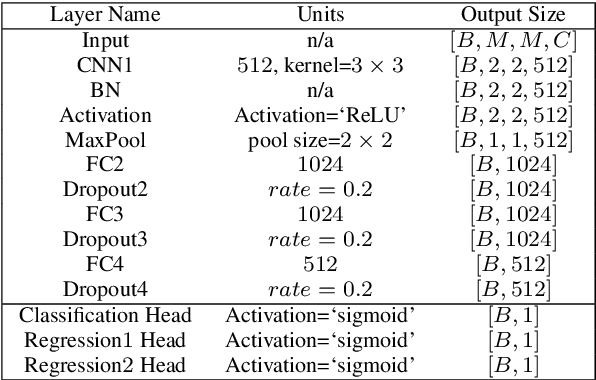
RADA: Robust Adversarial Data Augmentation for Camera Localization in Challenging Weather
Dec 05, 2021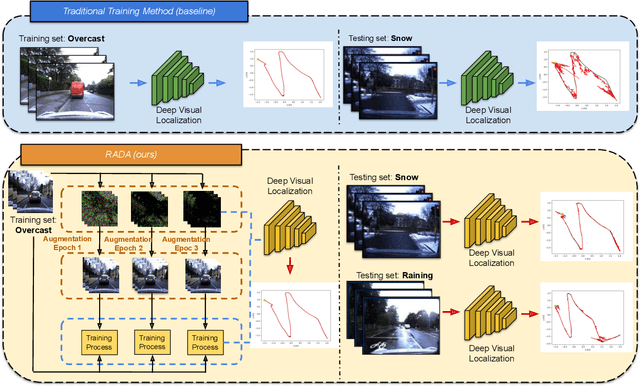
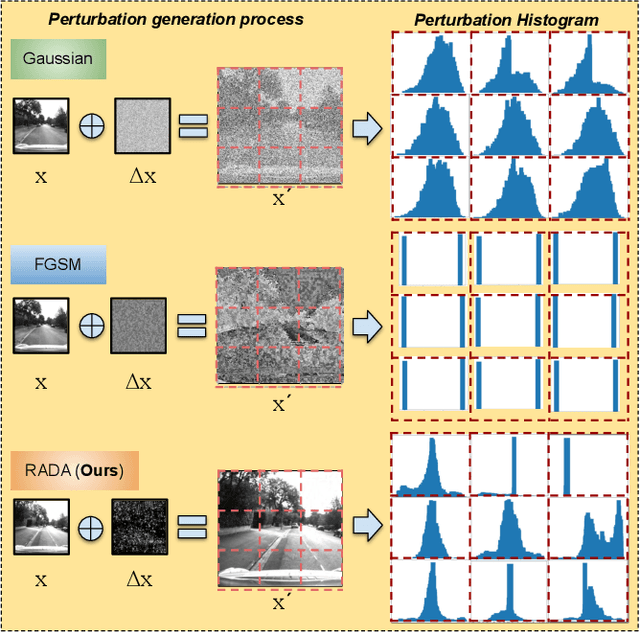
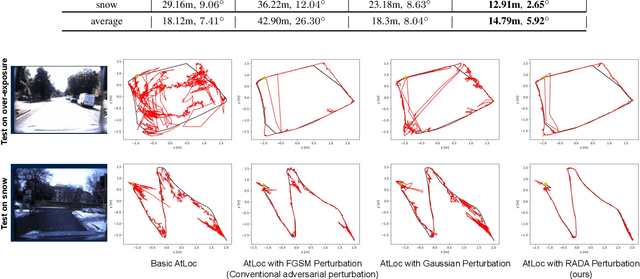

Camera localization is a fundamental and crucial problem for many robotic applications. In recent years, using deep-learning for camera-based localization has become a popular research direction. However, they lack robustness to large domain shifts, which can be caused by seasonal or illumination changes between training and testing data sets. Data augmentation is an attractive approach to tackle this problem, as it does not require additional data to be provided. However, existing augmentation methods blindly perturb all pixels and therefore cannot achieve satisfactory performance. To overcome this issue, we proposed RADA, a system whose aim is to concentrate on perturbing the geometrically informative parts of the image. As a result, it learns to generate minimal image perturbations that are still capable of perplexing the network. We show that when these examples are utilized as augmentation, it greatly improves robustness. We show that our method outperforms previous augmentation techniques and achieves up to two times higher accuracy than the SOTA localization models (e.g., AtLoc and MapNet) when tested on `unseen' challenging weather conditions.
CubeLearn: End-to-end Learning for Human Motion Recognition from Raw mmWave Radar Signals
Nov 07, 2021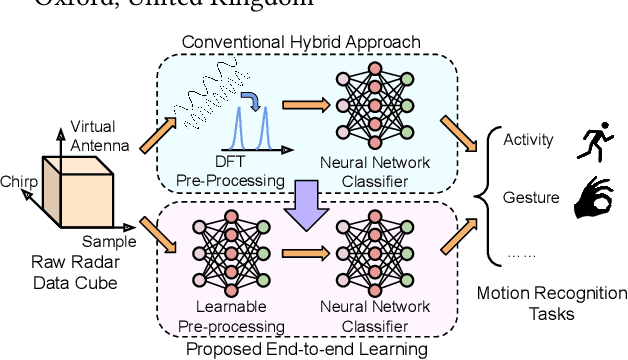

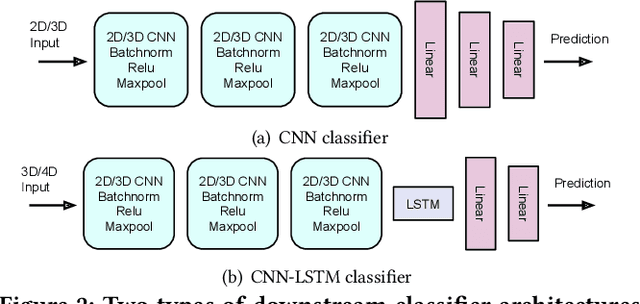

mmWave FMCW radar has attracted huge amount of research interest for human-centered applications in recent years, such as human gesture/activity recognition. Most existing pipelines are built upon conventional Discrete Fourier Transform (DFT) pre-processing and deep neural network classifier hybrid methods, with a majority of previous works focusing on designing the downstream classifier to improve overall accuracy. In this work, we take a step back and look at the pre-processing module. To avoid the drawbacks of conventional DFT pre-processing, we propose a learnable pre-processing module, named CubeLearn, to directly extract features from raw radar signal and build an end-to-end deep neural network for mmWave FMCW radar motion recognition applications. Extensive experiments show that our CubeLearn module consistently improves the classification accuracies of different pipelines, especially benefiting those previously weaker models. We provide ablation studies on initialization methods and structure of the proposed module, as well as an evaluation of the running time on PC and edge devices. This work also serves as a comparison of different approaches towards data cube slicing. Through our task agnostic design, we propose a first step towards a generic end-to-end solution for radar recognition problems.
Finite Basis Physics-Informed Neural Networks (FBPINNs): a scalable domain decomposition approach for solving differential equations
Jul 16, 2021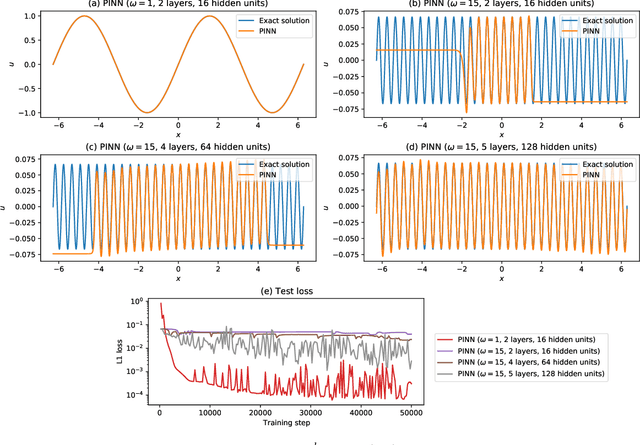
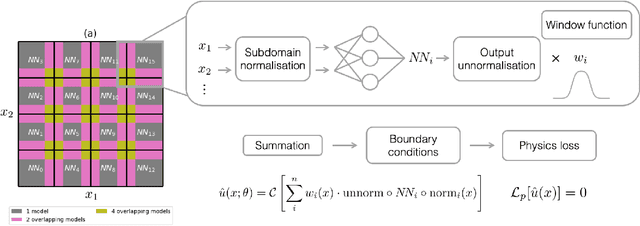
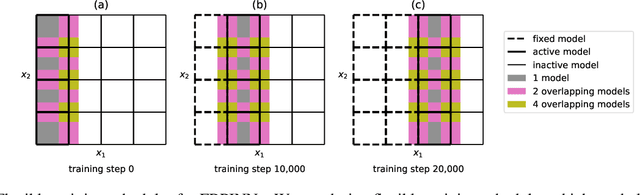

Recently, physics-informed neural networks (PINNs) have offered a powerful new paradigm for solving problems relating to differential equations. Compared to classical numerical methods PINNs have several advantages, for example their ability to provide mesh-free solutions of differential equations and their ability to carry out forward and inverse modelling within the same optimisation problem. Whilst promising, a key limitation to date is that PINNs have struggled to accurately and efficiently solve problems with large domains and/or multi-scale solutions, which is crucial for their real-world application. Multiple significant and related factors contribute to this issue, including the increasing complexity of the underlying PINN optimisation problem as the problem size grows and the spectral bias of neural networks. In this work we propose a new, scalable approach for solving large problems relating to differential equations called Finite Basis PINNs (FBPINNs). FBPINNs are inspired by classical finite element methods, where the solution of the differential equation is expressed as the sum of a finite set of basis functions with compact support. In FBPINNs neural networks are used to learn these basis functions, which are defined over small, overlapping subdomains. FBINNs are designed to address the spectral bias of neural networks by using separate input normalisation over each subdomain, and reduce the complexity of the underlying optimisation problem by using many smaller neural networks in a parallel divide-and-conquer approach. Our numerical experiments show that FBPINNs are effective in solving both small and larger, multi-scale problems, outperforming standard PINNs in both accuracy and computational resources required, potentially paving the way to the application of PINNs on large, real-world problems.
Learning Semantic Segmentation of Large-Scale Point Clouds with Random Sampling
Jul 06, 2021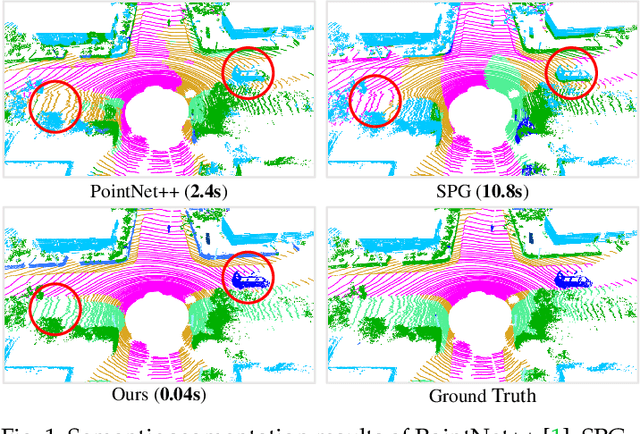
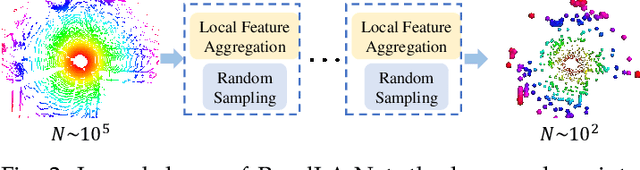
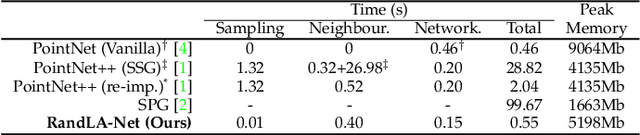
We study the problem of efficient semantic segmentation of large-scale 3D point clouds. By relying on expensive sampling techniques or computationally heavy pre/post-processing steps, most existing approaches are only able to be trained and operate over small-scale point clouds. In this paper, we introduce RandLA-Net, an efficient and lightweight neural architecture to directly infer per-point semantics for large-scale point clouds. The key to our approach is to use random point sampling instead of more complex point selection approaches. Although remarkably computation and memory efficient, random sampling can discard key features by chance. To overcome this, we introduce a novel local feature aggregation module to progressively increase the receptive field for each 3D point, thereby effectively preserving geometric details. Comparative experiments show that our RandLA-Net can process 1 million points in a single pass up to 200x faster than existing approaches. Moreover, extensive experiments on five large-scale point cloud datasets, including Semantic3D, SemanticKITTI, Toronto3D, NPM3D and S3DIS, demonstrate the state-of-the-art semantic segmentation performance of our RandLA-Net.