 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGPT's Devastated and LLaMA's Content: Emotion Representation Alignment in LLMs for Keyword-based Generation
Mar 14, 2025In controlled text generation using large language models (LLMs), gaps arise between the language model's interpretation and human expectations. We look at the problem of controlling emotions in keyword-based sentence generation for both GPT-4 and LLaMA-3. We selected four emotion representations: Words, Valence-Arousal-Dominance (VAD) dimensions expressed in both Lexical and Numeric forms, and Emojis. Our human evaluation looked at the Human-LLM alignment for each representation, as well as the accuracy and realism of the generated sentences. While representations like VAD break emotions into easy-to-compute components, our findings show that people agree more with how LLMs generate when conditioned on English words (e.g., "angry") rather than VAD scales. This difference is especially visible when comparing Numeric VAD to words. However, we found that converting the originally-numeric VAD scales to Lexical scales (e.g., +4.0 becomes "High") dramatically improved agreement. Furthermore, the perception of how much a generated sentence conveys an emotion is highly dependent on the LLM, representation type, and which emotion it is.
WHAT-IF: Exploring Branching Narratives by Meta-Prompting Large Language Models
Dec 17, 2024



WHAT-IF -- Writing a Hero's Alternate Timeline through Interactive Fiction -- is a system that uses zero-shot meta-prompting to create branching narratives from a prewritten story. Played as an interactive fiction (IF) game, WHAT-IF lets the player choose between decisions that the large language model (LLM) GPT-4 generates as possible branches in the story. Starting with an existing linear plot as input, a branch is created at each key decision taken by the main character. By meta-prompting the LLM to consider the major plot points from the story, the system produces coherent and well-structured alternate storylines. WHAT-IF stores the branching plot tree in a graph which helps it to both keep track of the story for prompting and maintain the structure for the final IF system. A video demo of our system can be found here: https://youtu.be/8vBqjqtupcc.
Bridging the Social & Technical Divide in Augmentative and Alternative Communication (AAC) Applications for Autistic Adults
Apr 26, 2024



Natural Language Processing (NLP) techniques are being used more frequently to improve high-tech Augmentative and Alternative Communication (AAC), but many of these techniques are integrated without the inclusion of the users' perspectives. As many of these tools are created with children in mind, autistic adults are often neglected in the design of AAC tools to begin with. We conducted in-depth interviews with 12 autistic adults to find the pain points of current AAC and determine what general technological advances they would find helpful. We found that in addition to technological issues, there are many societal issues as well. We found 9 different categories of themes from our interviews: input options, output options, selecting or adapting AAC for a good fit, when to start or swap AAC, benefits (of use), access (to AAC), stumbling blocks for continued use, social concerns, and lack of control. In this paper, we go through these nine categories in depth and then suggest possible guidelines for the NLP community, AAC application makers, and policy makers to improve AAC use for autistic adults.
CALYPSO: LLMs as Dungeon Masters' Assistants
Aug 15, 2023



The role of a Dungeon Master, or DM, in the game Dungeons & Dragons is to perform multiple tasks simultaneously. The DM must digest information about the game setting and monsters, synthesize scenes to present to other players, and respond to the players' interactions with the scene. Doing all of these tasks while maintaining consistency within the narrative and story world is no small feat of human cognition, making the task tiring and unapproachable to new players. Large language models (LLMs) like GPT-3 and ChatGPT have shown remarkable abilities to generate coherent natural language text. In this paper, we conduct a formative evaluation with DMs to establish the use cases of LLMs in D&D and tabletop gaming generally. We introduce CALYPSO, a system of LLM-powered interfaces that support DMs with information and inspiration specific to their own scenario. CALYPSO distills game context into bite-sized prose and helps brainstorm ideas without distracting the DM from the game. When given access to CALYPSO, DMs reported that it generated high-fidelity text suitable for direct presentation to players, and low-fidelity ideas that the DM could develop further while maintaining their creative agency. We see CALYPSO as exemplifying a paradigm of AI-augmented tools that provide synchronous creative assistance within established game worlds, and tabletop gaming more broadly.
FIREBALL: A Dataset of Dungeons and Dragons Actual-Play with Structured Game State Information
May 08, 2023Dungeons & Dragons (D&D) is a tabletop roleplaying game with complex natural language interactions between players and hidden state information. Recent work has shown that large language models (LLMs) that have access to state information can generate higher quality game turns than LLMs that use dialog history alone. However, previous work used game state information that was heuristically created and was not a true gold standard game state. We present FIREBALL, a large dataset containing nearly 25,000 unique sessions from real D&D gameplay on Discord with true game state info. We recorded game play sessions of players who used the Avrae bot, which was developed to aid people in playing D&D online, capturing language, game commands and underlying game state information. We demonstrate that FIREBALL can improve natural language generation (NLG) by using Avrae state information, improving both automated metrics and human judgments of quality. Additionally, we show that LLMs can generate executable Avrae commands, particularly after finetuning.
Human-in-the-Loop Schema Induction
Feb 25, 2023Schema induction builds a graph representation explaining how events unfold in a scenario. Existing approaches have been based on information retrieval (IR) and information extraction(IE), often with limited human curation. We demonstrate a human-in-the-loop schema induction system powered by GPT-3. We first describe the different modules of our system, including prompting to generate schematic elements, manual edit of those elements, and conversion of those into a schema graph. By qualitatively comparing our system to previous ones, we show that our system not only transfers to new domains more easily than previous approaches, but also reduces efforts of human curation thanks to our interactive interface.
Author as Character and Narrator: Deconstructing Personal Narratives from the r/AmITheAsshole Reddit Community
Jan 19, 2023



In the r/AmITheAsshole subreddit, people anonymously share first person narratives that contain some moral dilemma or conflict and ask the community to judge who is at fault (i.e., who is "the asshole"). In general, first person narratives are a unique storytelling domain where the author is the narrator (the person telling the story) but can also be a character (the person living the story) and, thus, the author has two distinct voices presented in the story. In this study, we identify linguistic and narrative features associated with the author as the character or as a narrator. We use these features to answer the following questions: (1) what makes an asshole character and (2) what makes an asshole narrator? We extract both Author-as-Character features (e.g., demographics, narrative event chain, and emotional arc) and Author-as-Narrator features (i.e., the style and emotion of the story as a whole) in order to identify which aspects of the narrative are correlated with the final moral judgment. Our work shows that "assholes" as Characters frame themselves as lacking agency with a more positive personal arc, while "assholes" as Narrators will tell emotional and opinionated stories.
CORRPUS: Detecting Story Inconsistencies via Codex-Bootstrapped Neurosymbolic Reasoning
Dec 21, 2022



Story generation and understanding -- as with all NLG/NLU tasks -- has seen a surge in neurosymbolic work. Researchers have recognized that, while large language models (LLMs) have tremendous utility, they can be augmented with symbolic means to be even better and to make up for any flaws that the neural networks might have. However, symbolic methods are extremely costly in terms of the amount of time and expertise needed to create them. In this work, we capitalize on state-of-the-art Code-LLMs, such as Codex, to bootstrap the use of symbolic methods for tracking the state of stories and aiding in story understanding. We show that our CoRRPUS system and abstracted prompting procedures can beat current state-of-the-art structured LLM techniques on pre-existing story understanding tasks (bAbI task 2 and Re^3) with minimal hand engineering. We hope that this work can help highlight the importance of symbolic representations and specialized prompting for LLMs as these models require some guidance for performing reasoning tasks properly.
Dungeons and Dragons as a Dialog Challenge for Artificial Intelligence
Oct 13, 2022


AI researchers have posited Dungeons and Dragons (D&D) as a challenge problem to test systems on various language-related capabilities. In this paper, we frame D&D specifically as a dialogue system challenge, where the tasks are to both generate the next conversational turn in the game and predict the state of the game given the dialogue history. We create a gameplay dataset consisting of nearly 900 games, with a total of 7,000 players, 800,000 dialogue turns, 500,000 dice rolls, and 58 million words. We automatically annotate the data with partial state information about the game play. We train a large language model (LM) to generate the next game turn, conditioning it on different information. The LM can respond as a particular character or as the player who runs the game--i.e., the Dungeon Master (DM). It is trained to produce dialogue that is either in-character (roleplaying in the fictional world) or out-of-character (discussing rules or strategy). We perform a human evaluation to determine what factors make the generated output plausible and interesting. We further perform an automatic evaluation to determine how well the model can predict the game state given the history and examine how well tracking the game state improves its ability to produce plausible conversational output.
CIS2: A Simplified Commonsense Inference Evaluation for Story Prose
Feb 16, 2022

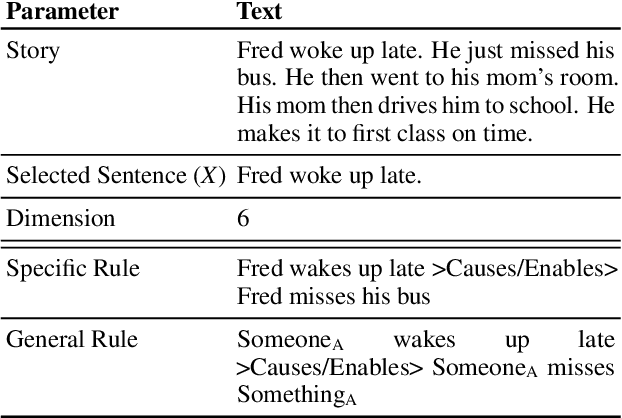
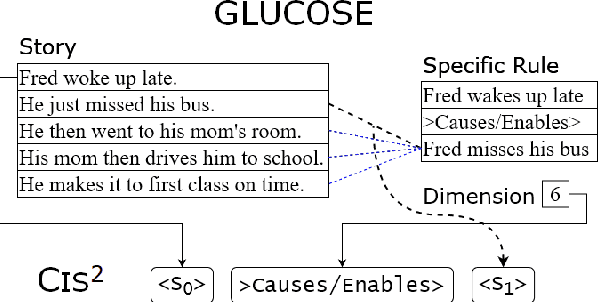
Transformers have been showing near-human performance on a variety of tasks, but they are not without their limitations. We discuss the issue of conflating results of transformers that are instructed to do multiple tasks simultaneously. In particular, we focus on the domain of commonsense reasoning within story prose, which we call contextual commonsense inference (CCI). We look at the GLUCOSE (Mostafazadeh et al 2020) dataset and task for predicting implicit commonsense inferences between story sentences. Since the GLUCOSE task simultaneously generates sentences and predicts the CCI relation, there is a conflation in the results. Is the model really measuring CCI or is its ability to generate grammatical text carrying the results? In this paper, we introduce the task contextual commonsense inference in sentence selection (CIS$^2$), a simplified task that avoids conflation by eliminating language generation altogether. Our findings emphasize the necessity of future work to disentangle language generation from the desired NLP tasks at hand.